【NLP修炼系列之Bert】Bert多分类&多标签文本分类实战(附源码下载)
引言
今天我们就要用Bert做项目实战,实现文本多分类任务和我在实际公司业务中的多标签文本分类任务。通过本篇文章,可以让想实际入手Bert的NLP学习者迅速上手Bert实战项目。
1 项目介绍
本文是Bert文本多分类和多标签文本分类实战,其中多分类项目是借鉴github中被引用次数比较多的优秀项目,多标签文本分类是我在公司业务中实际用到的线上项目,今天把两个项目都介绍给大家,其实Bert做文本分类项目都大差不差,两个项目的项目结构也都差不多,这样更容易被初学者迅速入手和理解。
1.1 数据集介绍
文本多分类任务用到的数据集是THUCNews数据集中抽取20w新闻标题,文本长度在20-30之间,一共10个类别,每个类别2万条。类别:财经、房产、股票、教育、科技、社会、时政、体育、游戏、娱乐。数据集划分:训练集18w(每个类别18000条),验证集和测试集各1w(每个类别1000条)。
多标签文本分类用到的数据集是我们自己公司的业务数据不方便提供,但是网上也有很多开源的多标签文本分类数据集,只需要在数据读取方式上稍微做处理即可,我们公司数据用到的是对话形式的json格式,做的落地应用是意图识别任务。
1.2 项目结构
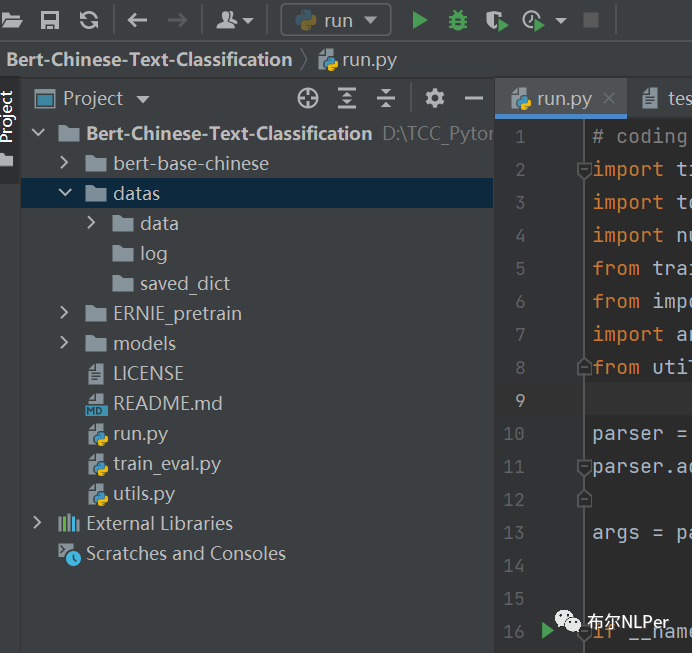
(1)bert-base-chinese:存放Bert预训练模型文件pytorch_model.bin ,config.json, vocab.txt 文件比较大,可以自己在huggingface官网下载。
(2)datas:里面data存放数据集,log存放模型训练日志,saved_dict存放训练保存好的模型。
(3)models:存放Bert模型及其超参数定义config类,其中还有Bert+CNN等混合模型文件。
(4)run.py:程序入口,运行直接训练模型。
(5)train_eval.py:模型训练,验证,测试部门代码。
(6)utils:定义数据预处理和加载的模块。
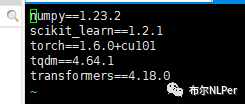
1.3 需要环境包
项目里面我生成了requirements.txt 文件,运行项目之前需要先安装环境包,python版本3.8。
pip install -r requirements.txt
2 项目流程
run.py是完整项目的入口,只需要运行run.py就可以跑通整个项目了。
2.1 项目参数
整体项目参数用到了argparse工具,配置相关参数,比如设置模型模块名称。
# 声明argparse对象 可附加说明
parser = argparse.ArgumentParser(description='Chinese Text Classification')
# 模型是必须设置的参数(required=True) 类型是字符串
parser.add_argument('--model', type=str, default="bert", help='choose a model: bert, bert_CNN,' 'bert_DPCNN,bert_RNN,bert_RCNN,ERNIE')
# 解析参数
args = parser.parse_args()
2.2 项目流程
if __name__ == '__main__':
dataset = 'datas' # 数据集路径
model_name = args.model # bert 设置的模型名称
x = import_module('models.' + model_name) # 根据所选模型名字在models包下 获取相应模块
config = x.Config(dataset) # 模型文件中的配置类
# 设置随机种子 确保每次运行的条件(模型参数初始化、数据集的切分或打乱等)是一样的
np.random.seed(1)
torch.manual_seed(1)
torch.cuda.manual_seed_all(1)
torch.backends.cudnn.deterministic = True # 保证每次结果一样
start_time = time.time()
print("Loading data...")
# 构建训练集、验证集、测试集
train_data, dev_data, test_data = build_dataset(config)
# 构建训练集、验证集、测试集迭代器
train_iter = build_iterator(train_data, config)
dev_iter = build_iterator(dev_data, config)
test_iter = build_iterator(test_data, config)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
# train
model = x.Model(config).to(config.device) # 构建模型对象
train(config, model, train_iter, dev_iter, test_iter) # 训练
3 数据处理
数据预处理阶段主要两部分,构建数据集build_dataset()和构建数据迭代器build_iterator()。这里面我们自定义数据迭代器,之所以要构建数据迭代器,是因为当数据量比较大时,无法一次性把数据全部加载到内存或显存中,此时我们可以使用数据生成器。训练时,不是把全部数据都加载到内存或显存中,而是用到哪一部分数据(某个batch),就用数据生成器生成该部分数据,只把这部分数据加载到内存或显存中,避免溢出。
3.1 构建数据集
PAD, CLS = '[PAD]', '[CLS]' # padding符号, bert中综合信息符号
def build_dataset(config):
def load_dataset(path, pad_size=32):
contents = []
with open(path, 'r', encoding='UTF-8') as f:
for line in tqdm(f):#遍历每一行
lin = line.strip()#去掉首尾空白符
if not lin:#遇到空行 跳过
continue
content, label = lin.split('\t')#text label;每一行以\t为切分,拿到文本
token = config.tokenizer.tokenize(content) #分字(汉语 character-level) bert内置的tokenizer
token = [CLS] + token #头部加入 [CLS] token
seq_len = len(token) #文本实际长度(填充或截断之前)
mask = [] #区分填充部分和非填充部分
token_ids = config.tokenizer.convert_tokens_to_ids(token) #把tokenizer转换为索引(基于下载的词表文件)
if pad_size:#长截短填
if len(token) < pad_size: #序列长度小于 填充长度
mask = [1] * len(token_ids) + [0] * (pad_size - len(token))#mask 填充部分对应0 非填充部分为1
token_ids += ([0] * (pad_size - len(token))) #用0作填充
else: #此时没有填充 序列长度大于填充长度
mask = [1] * pad_size #全部都是非填充
token_ids = token_ids[:pad_size] #截断
seq_len = pad_size #实际长度为填充长度
contents.append((token_ids, int(label), seq_len, mask)) #[([...],label,seq_len,[...])]
return contents
# 分别对训练集、验证集、测试集进行处理
train = load_dataset(config.train_path, config.pad_size)
dev = load_dataset(config.dev_path, config.pad_size)
test = load_dataset(config.test_path, config.pad_size)
# 返回预处理好的训练集、验证集、测试集
return train, dev, test
3.2 构建数据迭代器
class DatasetIterater(object):#自定义数据集迭代器
def __init__(self, batches, batch_size, device):
self.batch_size = batch_size
self.batches = batches#数据集
self.n_batches = len(batches) // batch_size #得到batch数量
self.residue = False # 记录batch数量是否为整数
if len(batches) % self.n_batches != 0:#不能整除
self.residue = True
self.index = 0
self.device = device
def _to_tensor(self, datas):
# 转换为tensor 并 to(device)
x = torch.LongTensor([_[0] for _ in datas]).to(self.device) #输入序列
y = torch.LongTensor([_[1] for _ in datas]).to(self.device) #标签
# seq_len为文本的实际长度(不包含填充的长度) 转换为tensor 并 to(device)
seq_len = torch.LongTensor([_[2] for _ in datas]).to(self.device)
#mask
mask = torch.LongTensor([_[3] for _ in datas]).to(self.device)
return (x, seq_len, mask), y
def __next__(self):
if self.residue and self.index == self.n_batches:#当数据集大小 不整除 batch_size时,构建最后一个batch
batches = self.batches[self.index * self.batch_size: len(self.batches)]
self.index += 1
batches = self._to_tensor(batches)#把最后一个batch转换为tensor 并 to(device)
return batches
elif self.index > self.n_batches:
self.index = 0
raise StopIteration
else:#构建每一个batch
batches = self.batches[self.index * self.batch_size: (self.index + 1) * self.batch_size]
self.index += 1
batches = self._to_tensor(batches)#把当前batch转换为tensor 并 to(device)
return batches
def __iter__(self):
return self
def __len__(self):
if self.residue:
return self.n_batches + 1 #不整除 batch数加1
else:
return self.n_batches def build_iterator(dataset, config):#构建数据集迭代器 iter = DatasetIterater(dataset, config.batch_size, config.device) return iter
4 模型和配置定义
模型用到预训练Bert模型,在对输入经过encoder编码后,取[CLS] token(输入序列最前面需要添加特定的[CLS] token表示序列开始)对应的最后一层编码向量(隐状态),再接全连接层进行分类,以及预训练语言模型和深度学习模型的结合,如Bert + CNN/RNN/RCNN/DPCNN,即取Bert最后一层所有的编码向量作为后续深度学习模型的输入,再进行分类。
4.1 Config配置类
这里面只展示出Bert + 全连接层,目前在我公司的业务数据集上效果最好的。
class Config(object):
"""配置参数"""
def __init__(self, dataset):
self.model_name = 'bert'
#训练集、验证集、测试集路径
self.train_path = dataset + '/data/train.txt'
self.dev_path = dataset + '/data/dev.txt'
self.test_path = dataset + '/data/test.txt'
#类别名单
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt').readlines()]
#存储模型的训练结果
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt'
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.num_epochs = 3 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-5 # 学习率
#预训练模型相关文件(模型文件.bin、配置文件.json、词表文件vocab.txt)存储路径
self.bert_path ='./bert-base-chinese'
#序列切分工具
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
#隐藏单元数
self.hidden_size = 768
4.2 模型定义类
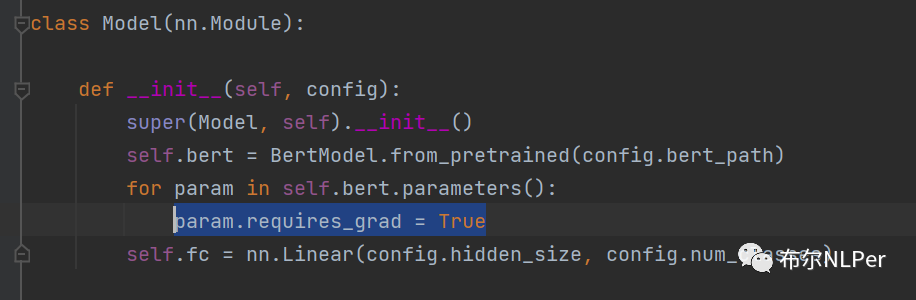
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
self.fc = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
context = x[0] # 输入的句子
mask = x[2] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
# _, pooled = self.bert(context, attention_mask=mask, output_all_encoded_layers=False)
_, pooled = self.bert(context, attention_mask=mask, token_type_ids=None, return_dict=False)
out = self.fc(pooled)
return out
5 训练,验证和测试
5.1 训练模块
def train(config, model, train_iter, dev_iter, test_iter):
start_time = time.time()
model.train()
param_optimizer = list(model.named_parameters())
no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}]
optimizer = AdamW(optimizer_grouped_parameters, lr=config.learning_rate)
total_step = len(train_iter) * config.num_epochs
num_warmup_steps = round(total_step * 0.1)
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=num_warmup_steps,
num_training_steps=total_step)
total_batch = 0 # 记录进行到多少batch
dev_best_loss = float('inf')
last_improve = 0 # 记录上次验证集loss下降的batch数
flag = False # 记录是否很久没有效果提升
model.train()
for epoch in range(config.num_epochs):
print('Epoch [{}/{}]'.format(epoch + 1, config.num_epochs))
for i, (trains, labels) in enumerate(train_iter):
outputs = model(trains)
model.zero_grad()
loss = F.cross_entropy(outputs, labels)
loss.backward()
optimizer.step()
scheduler.step()
if total_batch % 100 == 0:
# 每多少轮输出在训练集和验证集上的效果
true = labels.data.cpu()
predic = torch.max(outputs.data, 1)[1].cpu()
train_acc = metrics.accuracy_score(true, predic)
dev_acc, dev_loss = evaluate(config, model, dev_iter)
if dev_loss < dev_best_loss:
dev_best_loss = dev_loss
torch.save(model.state_dict(), config.save_path)
improve = '*'
last_improve = total_batch
else:
improve = ''
time_dif = get_time_dif(start_time)
msg = 'Iter: {0:>6}, Train Loss: {1:>5.2}, Train Acc: {2:>6.2%}, Val Loss: {3:>5.2}, Val Acc: {4:>6.2%}, Time: {5} {6}'
logger.log(msg.format(total_batch, loss.item(), train_acc, dev_loss, dev_acc, time_dif, improve))
# print(msg.format(total_batch, loss.item(), train_acc, dev_loss, dev_acc, time_dif, improve))
model.train()
total_batch += 1
if total_batch - last_improve > config.require_improvement:
# 验证集loss超过1000batch没下降,结束训练
print("No optimization for a long time, auto-stopping...")
flag = True
break
if flag:
break
test(config, model, test_iter)
5.2 验证模块
def evaluate(config, model, data_iter, test=False):
model.eval()#测试模式
loss_total = 0
predict_all = np.array([], dtype=int)#存储验证集所有batch的预测结果 labels_all = np.array([], dtype=int)#存储验证集所有batch的真实标签
with torch.no_grad():
for texts, labels in data_iter:
outputs = model(texts)
loss = F.cross_entropy(outputs, labels)
loss_total += loss
labels = labels.data.cpu().numpy()
predic = torch.max(outputs.data, 1)[1].cpu().numpy()
labels_all = np.append(labels_all, labels)
predict_all = np.append(predict_all, predic)
acc = metrics.accuracy_score(labels_all, predict_all)#计算验证集准确率
if test:#如果是测试集的话 计算一下分类报告
report = metrics.classification_report(labels_all, predict_all, target_names=config.class_list, digits=4)
confusion = metrics.confusion_matrix(labels_all, predict_all)#计算混淆矩阵 return acc, loss_total / len(data_iter), report, confusion
return acc, loss_total / len(data_iter)#返回准确率和每个batch的平均损失
5.3 测试模块
def test(config, model, test_iter):
# test
model.load_state_dict(torch.load(config.save_path))#加载使验证集损失最小的参数
model.eval()#测试模式
start_time = time.time()
test_acc, test_loss, test_report, test_confusion = evaluate(config, model, test_iter, test=True)#计算测试集准确率,每个batch的平均损失 分类报告、混淆矩阵
msg = 'Test Loss: {0:>5.2}, Test Acc: {1:>6.2%}'
print(msg.format(test_loss, test_acc))
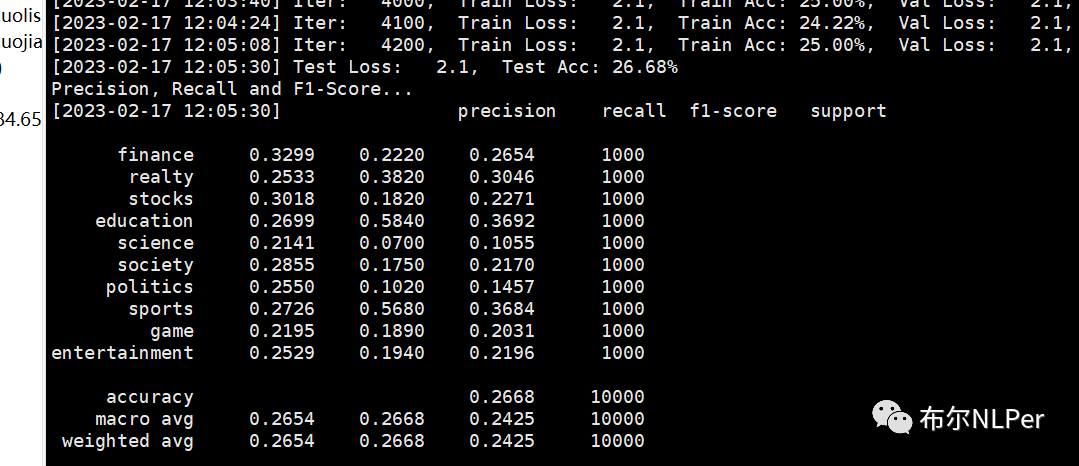
print("Precision, Recall and F1-Score...")
print(test_report)
print("Confusion Matrix...")
print(test_confusion)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
6 训练结果
实验超参数如下:
num_epochs = 3 batch_size = 128 pad_size = 32 learning_rate = 5e-5

这里需要注意的是使用Bert预训练模型接下游任务时,一定要在fine-tune情况下进行,即在定义模型类是需要设置:param.requires_grad = True(表示在微调情况下)
通过实验发现在非fine-tune情况下,实验结果非常差。
7 总结
本文主要介绍了使用Bert预训练模型做文本分类任务,在实际的公司业务中大多数情况下需要用到多标签的文本分类任务,我在以上的多分类任务的基础上实现了一版多标签文本分类任务,详细过程可以看我提供的项目代码,当然我在文章中展示的模型是原生的Bert+全连接层输出,提供的代码部分还有Bert+CNN/RNN/RCNN/DPCNN/等混合模型结构,后面我打算分别详细的带大家各个网络结构的原理和实战。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
原文地址:https://blog.csdn.net/zhishi0000/article/details/144283311
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!