动态IP黑白名单过滤的设计与实现(上篇设计思想)
需求分析
一些恶意用户(可能是黑客、爬虫、DDoS 攻击者)可能频繁请求服务器资源,导致资源占用过高。因此我们需要一定的手段实时阻止可疑或恶意的用户,减少攻击风险。
通过 IP 封禁,可以有效拉黑攻击者,防止资源被滥用,保障合法用户的正常访问。
对于我们的需求,不让拉进黑名单的 IP 访问任何接口。
方案设计
1、设计过程
其实前面讲到的 Sentinel 本身就支持请求来源的 黑白名单判断,但默认是对应用级别进行判断,需要改造来源的获取方式为获取请求客户端的 IP,可参考 这篇文章 自定义来源。
但其实引入 Sentinel 是需要一定成本的,本节主要分享更轻量的动态 IP 黑白名单过滤的常用设计和实现方法。
想要自主实现动态 IP 黑名单,主要考虑以下几点:
- IP 黑名单存储在哪里?
- 如何便捷地动态修改 IP 黑名单?
- 黑白名单的判断逻辑应在哪里处理?
- 使用何种数据结构保存黑名单?如何快速匹配用户请求的 IP 是否在黑名单中?
下面分别设计:
1)IP 黑名单存储在哪里?
最简单的方式就是存储在内存中,但一般 IP 黑名单是动态增加的、需要持久化保存。常见的持久化方式包括数据库、配置文件或分布式存储系统(如 Redis),可以根据需要选择。
2)如何便捷地动态修改 IP 黑名单?
为了方便动态修改 IP 黑名单,通常会提供一个管理页面,供管理员进行增删改查操作。
许多企业会将配置统一放入 配置中心,通过配置中心的管理页面,开发人员可以便捷地动态修改黑名单规则。Java 项目中,常用的配置中心是 Nacos。
3)黑白名单的判断逻辑应在哪里处理?
黑白名单逻辑通常部署在高性能的网关或 CDN 上,能够更早地拦截非法请求,减轻后端压力。在小型项目中,也可以直接在应用程序的过滤器中处理。
4)使用何种结构保存黑名单?如何快速匹配?
为了高效判断每个用户请求的 IP 是否在黑名单中,首先建议将 IP 黑名单从持久化存储同步到本地缓存中,避免频繁查询远程数据源。对于黑名单数据较小的场景,可以使用简单的 Set 数据结构存储。而对于大规模黑名单,推荐使用 布隆过滤器或 DFA 来存储和过滤黑名单,可以节约内存空间、提高检测效率。
2、最终方案
总结一下最终方案:
1)使用 Nacos 配置中心存储和管理 IP 黑名单
2)后端服务利用 Web 过滤器判断每个用户请求的 IP
3)后端服务利用布隆过滤器过滤 IP 黑名单
3、扩展知识 - 布隆过滤器
Bloom Filter 是一种高效的、基于概率的数据结构,用于判断一个元素是否存在于集合中。
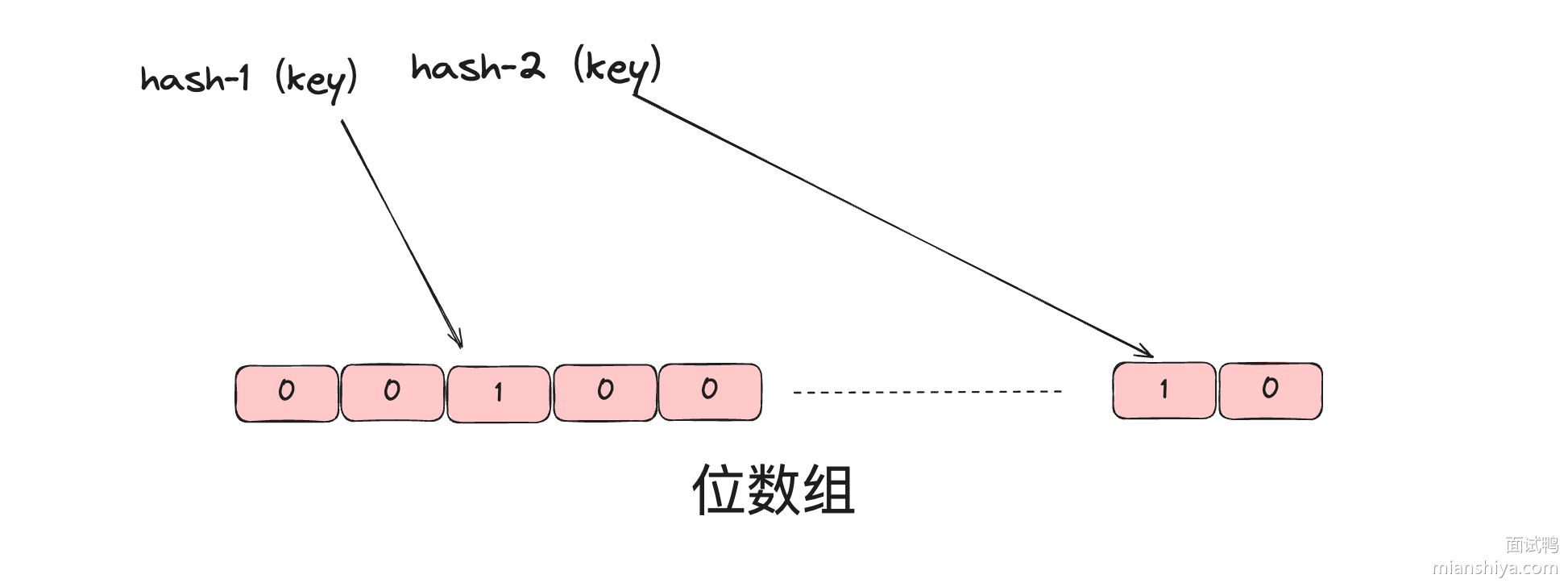
原理是利用多个哈希函数将元素映射到固定的点位上(位数组中),因此面对海量数据它占据的空间也非常小。
例如某个 key 通过 hash-1 和 hash-2 两个哈希函数,定位到数组中的值都为 1,则说明它存在。
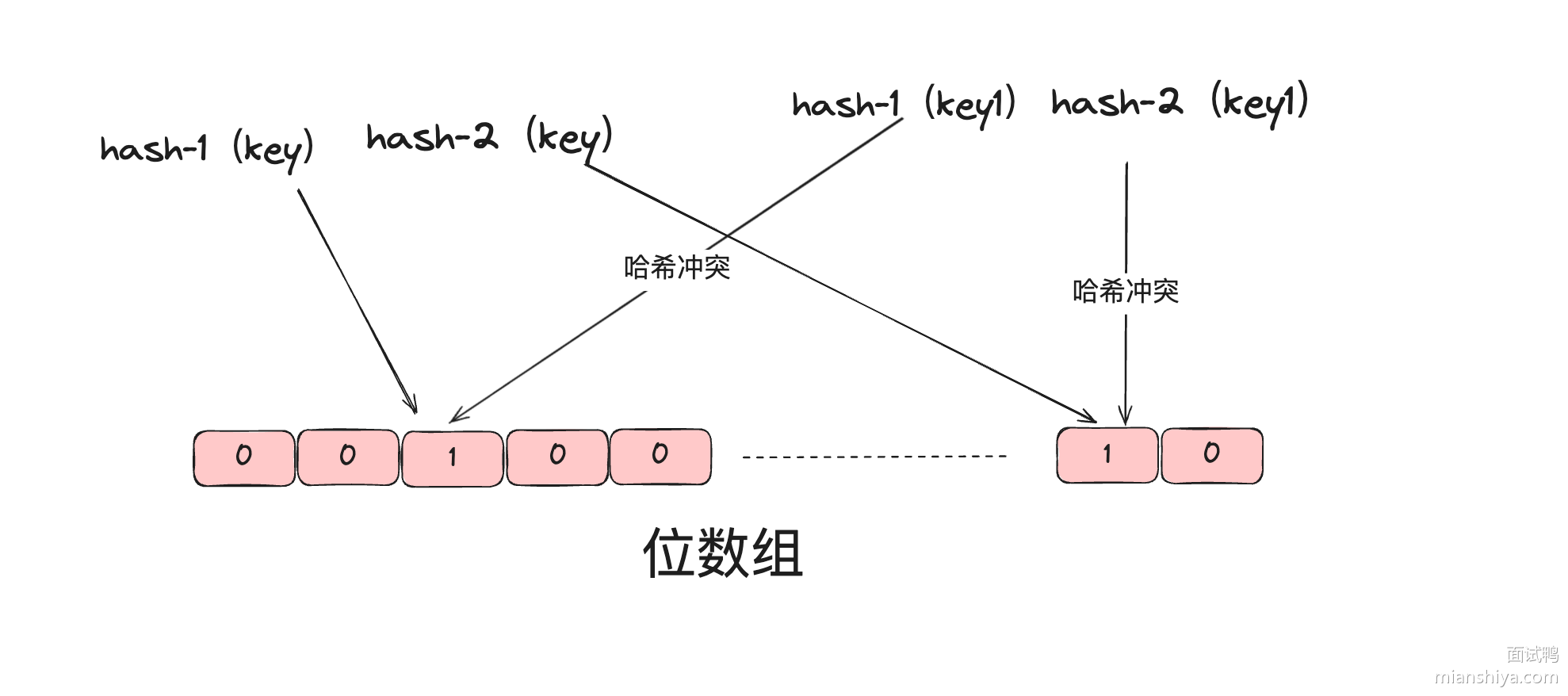
如果布隆过滤器判断一个元素不存在集合中,那么这个元素一定不在集合中,如果判断元素存在集合中则不一定是真的,因为哈希可能会存在冲突。因此布隆过滤器 有误判的概率 。
而且它不好删除元素,只能新增,如果想要删除,只能重建。
显然,它的主要特点包括:
- 空间效率高:相比于传统的数据结构(如哈希表),Bloom Filter 能用较少的空间存储大量的数据。
- 时间复杂度低:查询操作非常快速,通常是常数时间复杂度
O(1)。 - 允许误判:Bloom Filter 允许假阳性,即有时候会错误地判断某个元素在集合中,而实际该元素并不在集合中。不过,它不允许假阴性,也就是说,如果 Bloom Filter 判断某个元素不存在,那么它一定是不存在的。比如对于我们的需求,Bloom Filter 可能错误地判断一个不在黑名单中的元素为在黑名单中,导致误封。
Bloom Filter 的误判率与以下因素有关:
- 位数组的大小:位数组越大,误判率越低,但空间开销会增大。(值会更离散)
- 哈希函数的个数:哈希函数越多,误判率越低,但计算成本会增加。(Hash 一次冲突,那我就多 Hash 几次,减少冲突概率)
- 元素数量:存入的元素越多,误判率会增加。
通过 合理设计位数组的大小和哈希函数的个数,可以控制 Bloom Filter 的误判率在一个可接受的范围内。例如,在很多实际场景中,可以将误判率控制在 1% 或更低。
- 假设场景 1:存储 1000 个元素,位数组大小为 10000 位,哈希函数数量为 7。误判率大约为 0.8%。
- 假设场景 2:存储 100000 个元素,位数组大小为 1,000,000 位,哈希函数数量为 7。误判率大约为 1%。
- 假设场景 3:存储 1,000,000 个元素,位数组大小为 10,000,000 位,哈希函数数量为 7。误判率大约为 1%。
如果误判的代价较高,但仍想使用 Bloom Filter,可以采取一些补救措施:
- 双层验证:在 Bloom Filter 判断元素在黑名单中后,进一步查验实际的黑名单(例如,查数据库中的黑名单详细记录)。
- 结合其他数据结构:可以使用 Bloom Filter 进行初步筛选,如果 Bloom Filter 判断为在黑名单中,再用哈希表等精确的数据结构进行最终确认。
但这两种方式都无法处理攻击 IP 的大量请求,个人也不建议采用。
因此,布隆过滤器适用于对准确性要求不高的、大规模数据量匹配的场景,比如垃圾邮件过滤、爬虫 URL 去重、缓存穿透防护等。
原文地址:https://blog.csdn.net/qq_57473444/article/details/143896857
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!