FPGA学习笔记#7 Vitis HLS 数组优化和函数优化
本笔记使用的Vitis HLS版本为2022.2,在windows11下运行,仿真part为xcku15p_CIV-ffva1156-2LV-e,主要根据教程:跟Xilinx SAE 学HLS系列视频讲座-高亚军进行学习
学习笔记:《FPGA学习笔记》索引
FPGA学习笔记#1 HLS简介及相关概念
FPGA学习笔记#2 基本组件——CLB、SLICE、LUT、MUX、进位链、DRAM、存储单元、BRAM
FPGA学习笔记#3 Vitis HLS编程规范、数据类型、基本运算
FPGA学习笔记#4 Vitis HLS 入门的第一个工程
FPGA学习笔记#5 Vitis HLS For循环的优化(1)
FPGA学习笔记#6 Vitis HLS For循环的优化(2)
FPGA学习笔记#7 Vitis HLS 数组优化和函数优化
FPGA学习笔记#8 Vitis HLS优化总结和案例程序的优化
目录
- 1.数组优化
- 1.1.双端口内存
- 1.2.数组分割
- 1.2.1.一维数组分割
- 1.2.2.多维数组分割
- 1.3.数组合并
- 1.3.1.横向合并
- 1.3.2.纵向合并
- 1.3.3.数组分割和数组合并的结合使用
- 1.4.数组转换(reshape)
- 1.5.数组分割、合并和转换的对比
- 1.6.其他数组优化
- 1.6.1.定义ROM
- 1.6.2.数组初始化
- 1.6.3.FPGA的复位(一定要知道!)
- 2.函数优化
- 2.1.数据类型优化
- 2.2.inline
- 2.3.Allocation
- 2.4.DATAFLOW
1.数组优化
数组的优化对程序性能的提升是非常重要的,一个合理的内存结构可以提高程序的并行度,我们要找到资源和性能的权衡点,最大化FPGA使用率。
如果数组为top函数传入的参数,会表现为外部memory;如果设计在内部,则会用内部RAM、LUTRAM、UltraRAM、寄存器等形式表示。
1.1.双端口内存
考虑如下图所示的例程,top函数接收一个输入数组mem[N](N=4),将每三个连续数据求和,输出到sum[N-2]数组中,共2轮循环。
很明显,在每一次循环中需要读取mem数组三次,写入sum数组一次,可以看到右侧的时序图,完成一次写操作需要3个时钟周期。

对于这样输出只用一次、输入使用多次,我们可以使用RESOURCE directive配置为双端口内存,提高对内存的读取效率:
#pragma HLS RESOURCE variable=mem core=RAM_2P_BRAM
并同时对loop进行UNROOL:
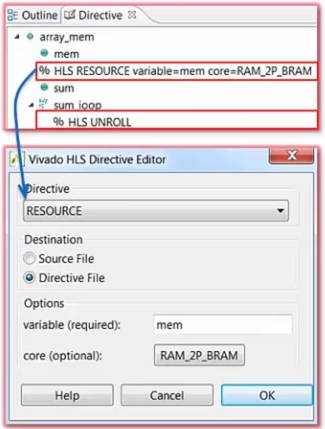
对应的资源消耗和时序如下,现在一个时钟周期可以读取2个数据,UNROLL出的2组电路在4个时钟周期便完成计算。

1.2.数组分割
1.2.1.一维数组分割
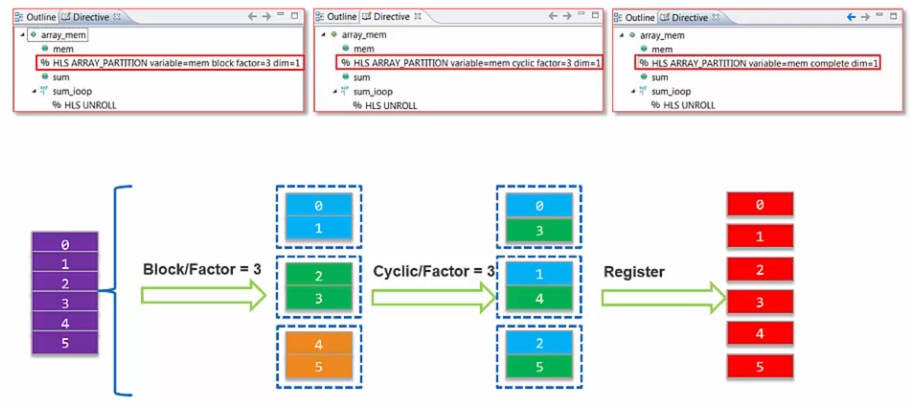
如下图是对于一个6长度数组的不同memory分配,这三种方式分别对应了一个数组对连续块进行处理(常见的可以考虑前一半和后一半分别有不同的处理,block/factor=2)、一个数组对间隔数据进行处理(常见的可以考虑奇偶数据,cyclic/factor=2)、最高效率并发处理。
Block/Factor=3方式分割:数组等分成三份,相邻2数据为1组
#pragma HLS ARRAY_PARTITION variable=mem block factor=3 dim=1
Cyclic/Factor=3方式分割:数组等分为三份,03一组14一组25一组
#pragma HLS ARRAY_PARTITION variable=mem cyclic factor=3 dim=1
Register方式分割:数组等分为6份,一个数据一组(占一个寄存器)
#pragma HLS ARRAY_PARTITION variable=mem complete dim=1
不同分割方法的时序如下:
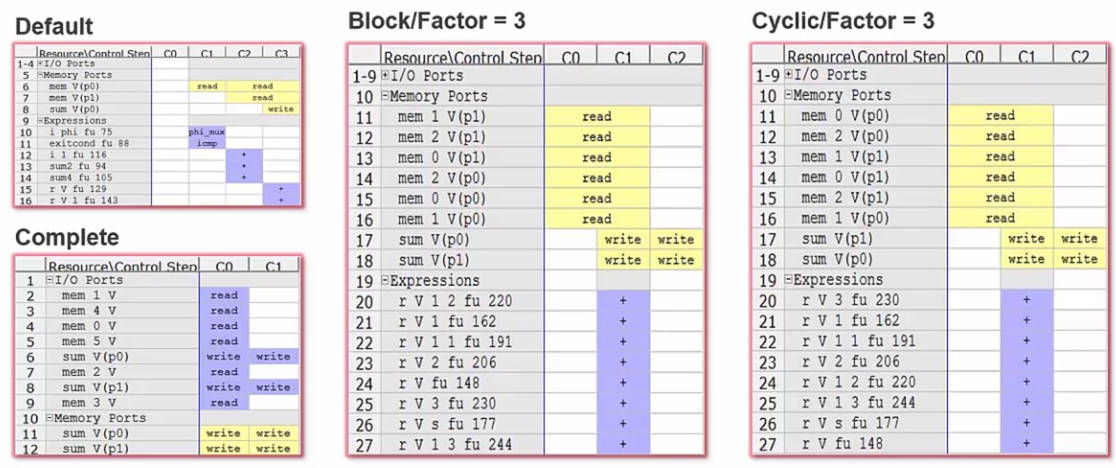
对于上面例程中的1输出-3输入运算关系,使用Block/Factor=2,分为2个数组,再使用双端口RAM,一次最多可以读取4数据,完全够用,无需开到Factor=3。
1.2.2.多维数组分割
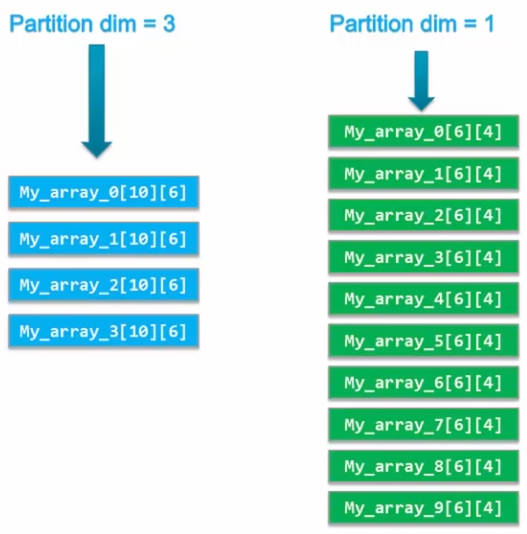
以多维数组My_array[10][6][4]为例,10是一维,6是二维,4是三维,使用的约束和一维数组的一样,只需要改变dim的值:
#pragma HLS ARRAY_PARTITION variable=mem block factor=3 dim=?
#pragma HLS ARRAY_PARTITION variable=mem cyclic factor=3 dim=?
#pragma HLS ARRAY_PARTITION variable=mem complete dim=?
对于指定不同dim,HLS会对不同的数组进行整体分割,如图为dim=3和dim=1所针对的数据,如果对dim3使用block/factor=2,则My_array_0和1一组,2和3一组进行分配。
我们以矩阵加法为例,如图有两个4*5矩阵mat_a和mat_b,其相加后结果存储在sum矩阵中:

我们可以三个数组采用单端口BRAM存储,均对第一维使用Block/Factor=4的分割,即每个矩阵分割为4个长度为5的一维数组,并对循环添加PIPELINE、UNROLL约束来进行优化:
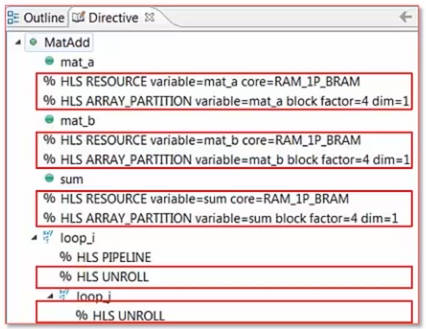
我们看一下Factor=4和2的情况,当Factor<该维数据个数时,会将对应数据依次拼接,总之一定会将一个N维数组变为一个N-1维数组。
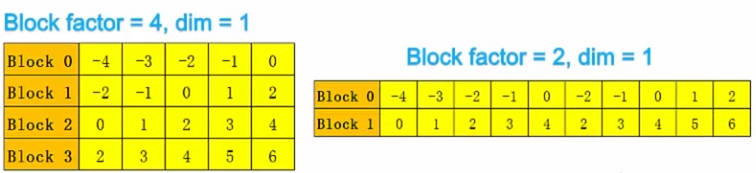
不同factor的时序图如下,可以通过地址线确定其在内存中也是顺序排列:
1.3.数组合并
将多个小数组合并为一个大数组不仅可以减少资源用量,在合理使用下也能提高性能。
数组合并使用的约束是ARRAY_MAP,其分为横向和纵向。
1.3.1.横向合并
横向/水平方向合并(Horizontal mapping)使用的约束语句如下,其扩展数组长度,而不扩展数组位宽。
#pragma ARRAY_MAP variable=A instance=ab_array horizontal
#pragma ARRAY_MAP variable=B instance=ab_array horizontal
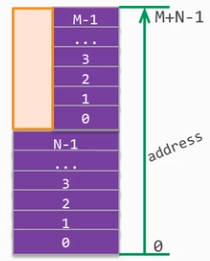
如下图,有数组A[N]和B[M],使用该约束后会合并为AB[N+M],低地址为0 ~ N-1,高地址为N ~ N+M-1。
这一操作会扩展B(数据位宽较小者)的位宽,拼接后的数组以所有数组中最大位宽为准,长度为各个数组相加。
可以看出,这一操作所针对的场景和数组分割中的Block相似。

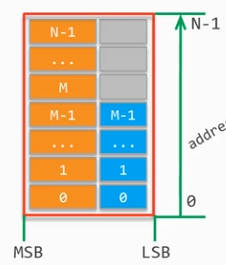
得到的数组的内存分配如下:
1.3.2.纵向合并
纵向/垂直方向合并(Vertical mapping)的依赖语句如下:
#pragma ARRAY_MAP variable=A instance=ab_array vertical
#pragma ARRAY_MAP variable=B instance=ab_array vertical
如下图中,N>M,则扩展A数组的位宽为sizeof(A[0])+sizeof(B[0]),将B数组的对应数据和A数组对应数据拼接,A数组的长度不变。
这一操作针对的场景和数组分割中的cyclic相似。
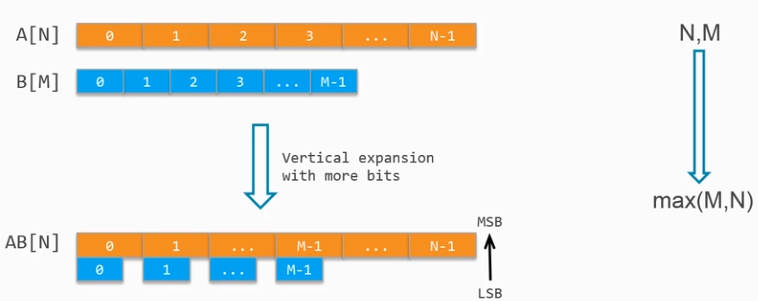
数组合并后的内存分配如下:
1.3.3.数组分割和数组合并的结合使用
ARRAY_PARTITION和ARRAY_MAP是可以结合使用的,考虑如下例子:
对于2个数组m_accum和v_accum,我们在一个循环中分别使用其奇数下标的数据,在另一个循环中分别使用其偶数下标的数据。
这是我们从单个数组角度上,我们需要使用cyclic进行数据分割;从2个循环的角度上,我们需要将奇数据和奇数据水平拼接,偶数据和偶数据水平拼接,我们就可以使用如下的约束语句:
#pragma HLS ARRAY_PARTITION variable=m_accum cyclic factor=2 dim=1
#pragma HLS ARRAY_PARTITION variable=v_accum cyclic factor=2 dim=1
#pragma HLS ARRAY_MAP variable=m_accum[0] instance=mv_accum horizontal
#pragma HLS ARRAY_MAP variable=v_accum[0] instance=mv_accum horizontal
#pragma HLS ARRAY_MAP variable=m_accum[1] instance=mv_accum_1 horizontal
#pragma HLS ARRAY_MAP variable=v_accum[1] instance=mv_accum_1 horizontal
1.4.数组转换(reshape)
对于单个数组,如果我们想让其从数据上仍为一个数组,但从结构上改变其数据排布,那么可以使用ARRAY_RESHAPE约束进行数组的reshape。
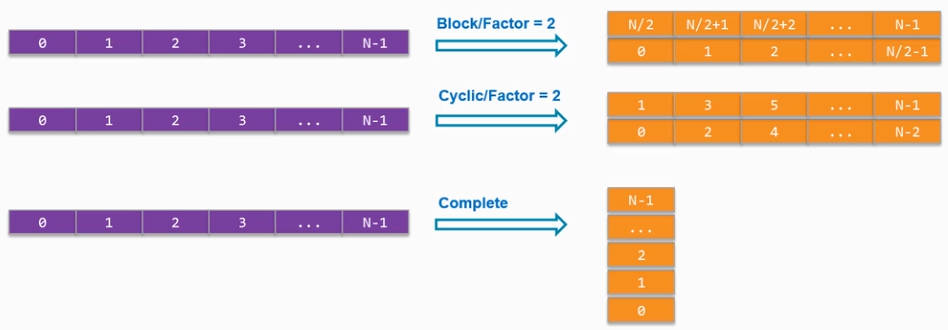
以一维数组为例,如下是3种reshape方法:
Block/Factor=2:将数组一分为二,然后进行拼接,长度减半,数据位宽翻倍
#pragma HLS ARRAY_RESHAPE dim=1 factor=2 type=block variable=arr
Cyclic/Factor=2:将数据奇偶分组(对2取模为组号)进行拼接,长度减半,位宽翻倍
#pragma HLS ARRAY_RESHAPE dim=1 factor=2 type=cyclicvariable=arr
Complete:将所有数据拼到一个数据中,长度最短,位宽最长
#pragma HLS ARRAY_RESHAPE dim=1 type=complete variable=arr
其内存中的数据分配如下图:
1.5.数组分割、合并和转换的对比
有例程如下图,数组A[N] B[M],第一个循环分别处理A数组的奇偶数据,第二个循环分别处理B数组的前半、后半数据,第三、四个循环分别依次读取A、B,并写入到pa、pb

可以发现,第一个循环更适合对A启用cyclic/factor=2,第二个循环更适合对B启用block/factor=2。
我们对A和B尝试以下这几种约束,分别将A和B横向ARRAY_MAP拼接、将A和B纵向ARRAY_MAP拼接、对A启用ARRAY_RESHAPE cyclic/factor=2并对B启用ARRAY_RESHAPE block/factor=2。
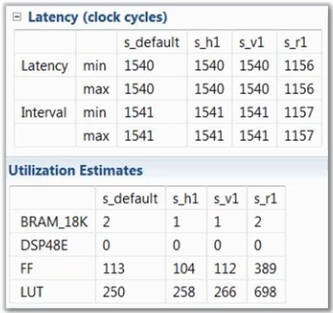
因此,我们分别指定如下约束,其中最右侧为我们刚才分析的约束:

最终得到结果如下,可以看到,使用RESHAPE的性能最高,但资源消耗也远超其他约束。
1.6.其他数组优化
1.6.1.定义ROM
方法1:使用const + 初始化值
缺点:初始值较多时较繁琐,代码管理不便

方法2:使用头文件,将初始值放在文件中,代码/工程管理较方便
该头文件内结构应如下所示:
1,
2,
3,
4,
5
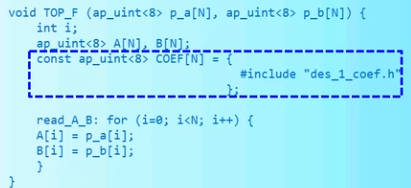
需要注意的是使用下面的方式是不行的,因为这种方法是使用了#include展开文件到声明位置的原理,#include "xxx.h"必须是所在行唯一的语句。

方法3:如果一个数据的value是通过数学计算得到的,并且在程序中不被更新,Vitis HLS会自动将其定义为ROM,如下图的sin_table:

默认情况下ROM的输出latency是2,我们可以在RESOURCE directive中将其配置为自定义值。
1.6.2.数组初始化
如果想要将数组映射为RTL的memory,那么需要加static进行修饰,这样既可以保证数组映射为memory,而且还能节省初始化的时间。
如果想要将数组映射为ROM,就需要用到上面的三种定义ROM的方式。
1.6.3.FPGA的复位(一定要知道!)
这一点在第一篇笔记中提到过,这里讲到了静态变量,所以再说一遍。
在 HLS 中,所有静态和全局变量都会被初始化为零(如果给定了初始化值,则初始化为其他值)。这包括 RAM,其中每个元素都被清除为零。
然而,这种初始化只发生在 FPGA 首次编程时。任何后续处理器复位都不会触发初始化过程。
如果需要清除设备的内部状态,那么应该包含某种复位协议(根据复位状态处理所需要的程序)。
2.函数优化
2.1.数据类型优化
对于参数等数据使用的数据类型,如果可以提前确认某一个值的上限,使用ap_int<>等类型可以有效减少资源的使用量,如下图:

2.2.inline
HLS中有INLINE约束,给函数添加INLINE约束后,在编译时会自动将inline修饰的函数展开到调用位置(硬件层面上),可以减少调用函数带来的开销。
#pragma HLS INLINE

如下图,启用INLINE后最终只产生了一个模块:

同时,可以在directive中关闭inline:
#pragma INLINE off
2.3.Allocation
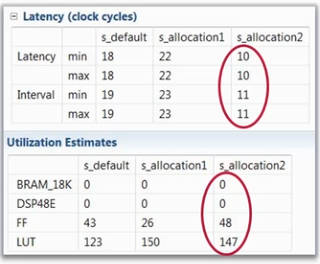
在上篇笔记中有过介绍,使用ALLOCATION约束将Accumulator函数实例化2次
#pragma ALLOCATION instances=Accumulator limit=2 function
对默认、limit=1、limit=2的情形进行了测试,可以看到limit=2带来了更高的性能,但会消耗更多资源:
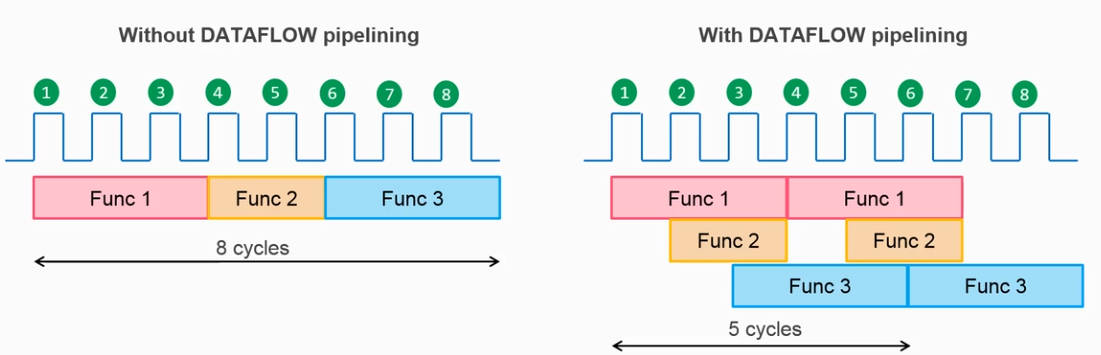
2.4.DATAFLOW
应用于函数的DATAFLOW,可以将多个调用间的依赖关系形成流水线并行执行
原文地址:https://blog.csdn.net/qq_38876396/article/details/143673251
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!