创建mapreduce项目使用maven
目录
3:编写代码,注意该项目的类名为IntegarSort,需要与项目名称一样,不然会有报错。如果在运行时报告输入参数错误,直接把输入路径直接给出。
4:
1:首先给出本次文章的项目要求
编写程序实现对输入文件的排序
现在有多个输入文件,每个文件中的每行内容均为一个整数。要求读取所有文件中的整数,进行升序排序后,输出到一个新的文件中,输出的数据格式为每行两个整数,第一个数字为第二个整数的排序位次,第二个整数为原待排列的整数。下面是输入文件和输出文件的一个样例供参考。
输入文件1的样例如下:
| 33 37 12 40 |
输入文件2的样例如下:
| 4 16 39 5 |
输入文件3的样例如下:
| 1 45 25 |
根据输入文件1、2和3得到的输出文件如下:
| 1 1 2 4 3 5 4 12 5 16 6 25 7 33 8 37 9 39 10 40 11 45 |
2:配置maven项目,建议去maven官网中,可以参考我这个,配置,需要注意里面的版本信息,我的是Hadoop3.1.3,其中我的build中的mainClass,需要给出你的主类路径,我的包结构如下,所以路径就是类名,该类名要相同,否则在运行hadoop时会报错:无法找到主类。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.niit.hdfs</groupId>
<artifactId>untitled</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.1.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.3</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-yarn-api -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-api</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.3.0</version> <!-- 使用最新版本 -->
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<mainClass>FileMergeAndDeduplicate</mainClass> <!-- 替换为你的主类全名 -->
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
</project>3:编写代码,注意该项目的类名为IntegarSort,需要与项目名称一样,不然会有报错。如果在运行时报告输入参数错误,直接把输入路径直接给出。
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class IntegerSort {
public static class IntegerMapper extends Mapper<LongWritable, Text, IntWritable, IntWritable> {
private IntWritable number = new IntWritable();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
number.set(Integer.parseInt(value.toString()));
context.write(number, new IntWritable(1));
}
}
public static class IntegerReducer extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable> {
private int rank = 1;
public void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
for (IntWritable val : values) {
context.write(new IntWritable(rank++), key);
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "integer sort");
job.setJarByClass(IntegerSort.class);
job.setMapperClass(IntegerMapper.class);
job.setReducerClass(IntegerReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}4:打包为jar包,按照步骤进行
得到jar包

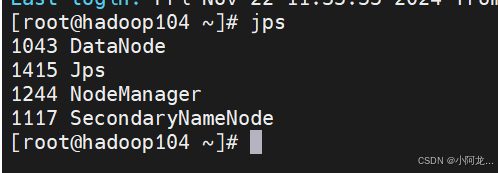
5:启动Hadoop集群
6:先将文件上传到Hadoop集群中,使用hadoop dfs -put (你的文件)(集群路径)
需要上传才能进行运行,因为是基于hdfs
![]()
7:运行jar包,使用命令hadoop jar (你的jar包名) (起那面的主类名)注意Hadoop的输出的是路径且不能存在自己会创建
![]()
8:有提示没事,和我这个图一样。


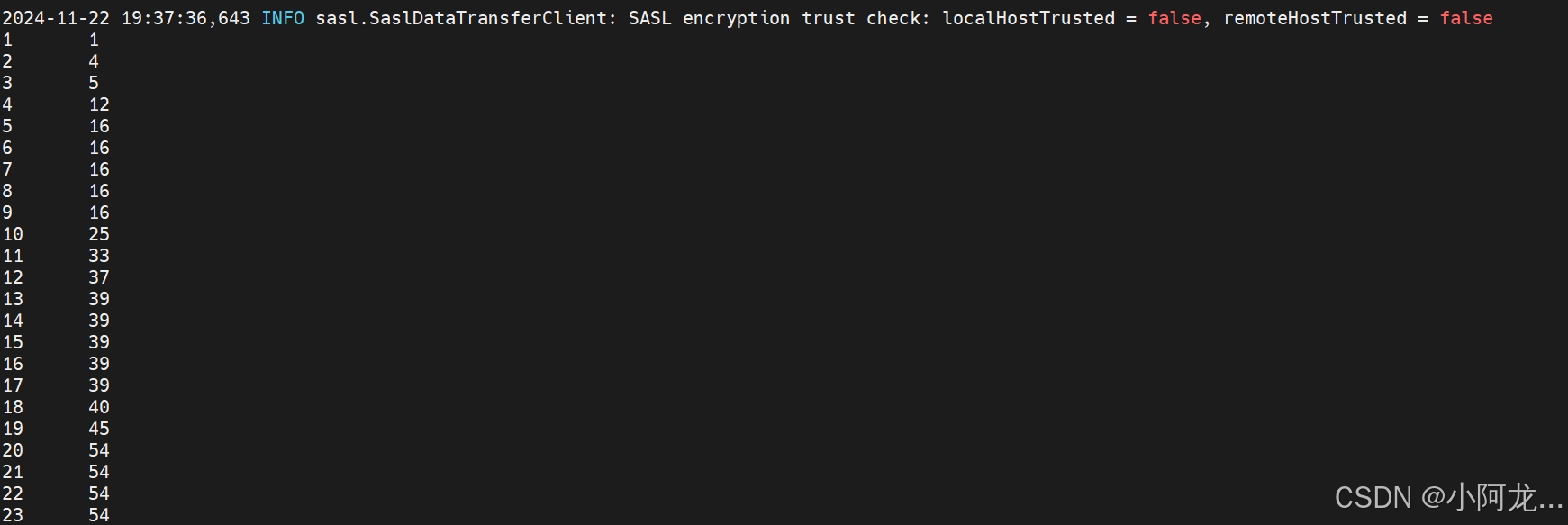
9: 使用命令查看结果
![]()
10:运行结果有点错误,以后再修改
原文地址:https://blog.csdn.net/2203_75850613/article/details/143985232
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!