CTR之行为序列建模用户兴趣:Temporal Interest Network(WWW‘2024)
最近连续介绍了几篇关于多场景多任务建模的论文,感兴趣的同学可以往前翻翻,后面会继续更新这个系列。
但最近先插入介绍下腾讯在2024年的几篇同样关于推荐系统的论文,实用性很高,并且是可以串联起来的。今天第一篇是关于序列建模用户兴趣的主题,前面也有相关主题的几篇文章:
1. 概述
Temporal Interest Network for User Response Prediction
WWW’2024:https://arxiv.org/abs/2308.08487
用户行为几乎是推荐系统中最为关键的特征,许多工作已经揭示了用户的行为可以反应出其对候选item的兴趣,归因于它们的语义或者时序相关性。
然而,这些文献尚未结合起来去分析这两种相关性,即语义-时序相关性。论文通过实验来衡量这种相关性,并观察到了直接而健硕的模型,但是主流的用户兴趣模型都无法很好地学习到这种相关性。
因此,为了填充这个gap,论文提出了Temporal Interest Network (TIN)来同时捕获用户行为与target之间的时序-语义相关性,通过引入target-aware的时序编码和语义编码来表征行为和target,具体一点,论文采用了4阶的交互方式:behavior semantics, target semantics, behavior temporal, target temporal:
- 其中,论文提出Target-aware Temporal Encoding (TTE)来编码时序信息,包含行为和target。TTE采用了每一个行为相对于target的相关位置或时间间隔;
- 接着,再引入Target-aware Attention (TA)和Target-aware Representation (TR)来实现行为与target的语义交互
2. 语义-时序相关性
上述提到主流的用户兴趣模型都未能很好地学习到语义-时序相关性,比如DIN没有考虑到任务关于行为的时序信息,SASRec和Bert4Rec利用位置编码去建模行为序列,但它们的位置是target不感知的(target-agnostic),导致无法充分地建模target-aware的时序建模,BST采用行为和target的自注意力建模,但仅实现了3阶的显示建模。
然而,问题来了,如何衡量语义-时序相关性?如何通过实验来佐证这些模型的不充分建模?论文使用了Amazon数据集来分析这种相关性。
论文采用CTC(Category-wise Target-aware Correlation)指标来衡量语义-时序相关性。CTC是指发生在位置p且分类为 c i c_i ci的行为( X C ( X ) = c i ∧ P ( X ) = p \cal{X}_{C(X)=c_i \wedge P(X)=p} XC(X)=ci∧P(X)=p)与对于分类为 c t c_t ct的target item的用户真实反馈(user response label, y C ( Y ) = c t \cal{y}_{C(Y)=c_t} yC(Y)=ct)之间的交互信息(MI,mutual information):

-
C ( ⋅ ) , P ( ⋅ ) C(\cdot),P(\cdot) C(⋅),P(⋅) 分别表示行为或者target的分类和位置
-
由于Amazon数据只有用户对target item的正反馈数据,论文通过随机替换target item来生成负反馈数据
-
使用分类作为行为和target的特征来计算MI,是因为分类的基数是中等大小的,比较合适
两个特征之间的MI计算公式在FwFM论文中出现过:
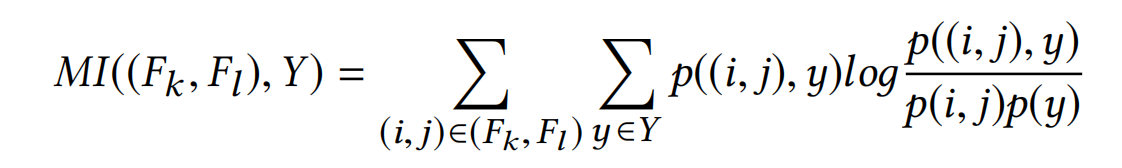
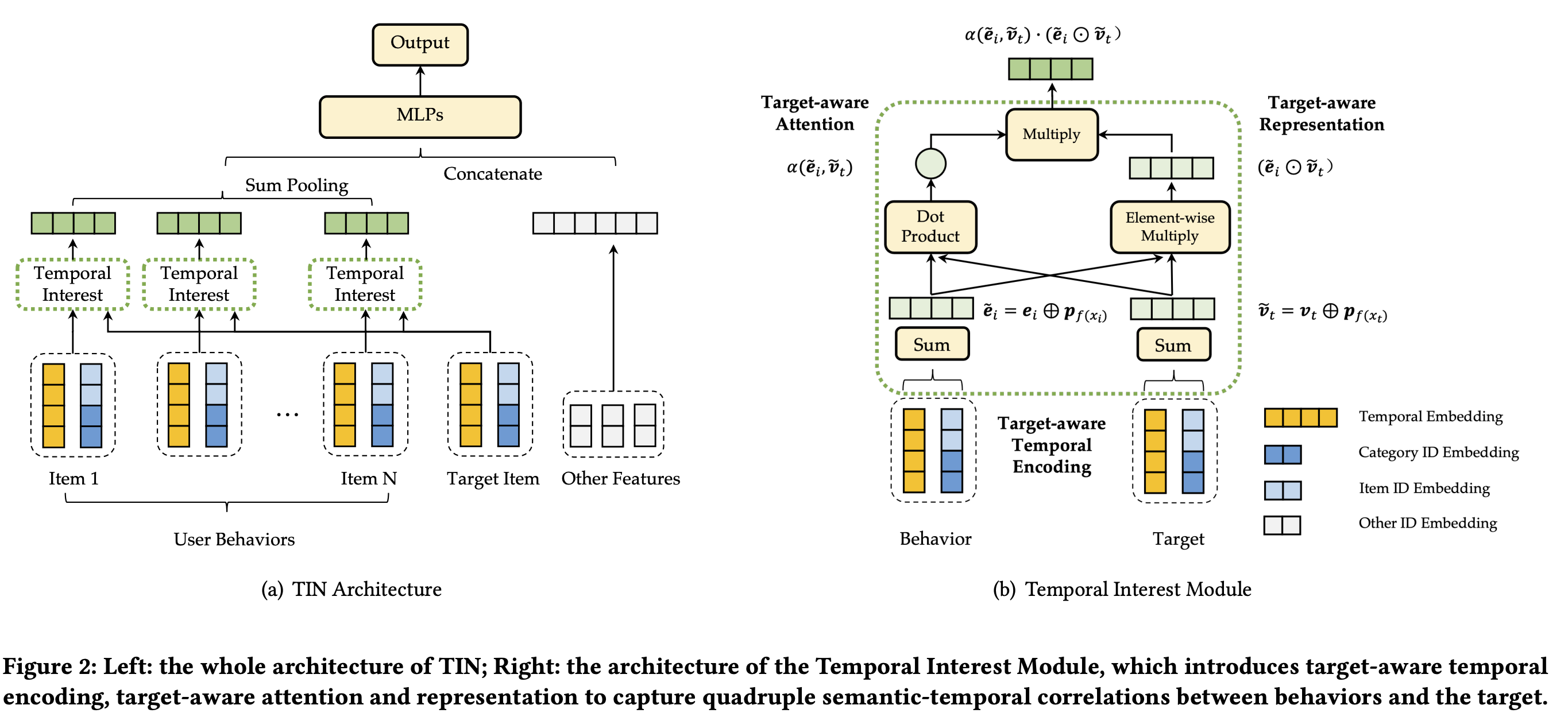
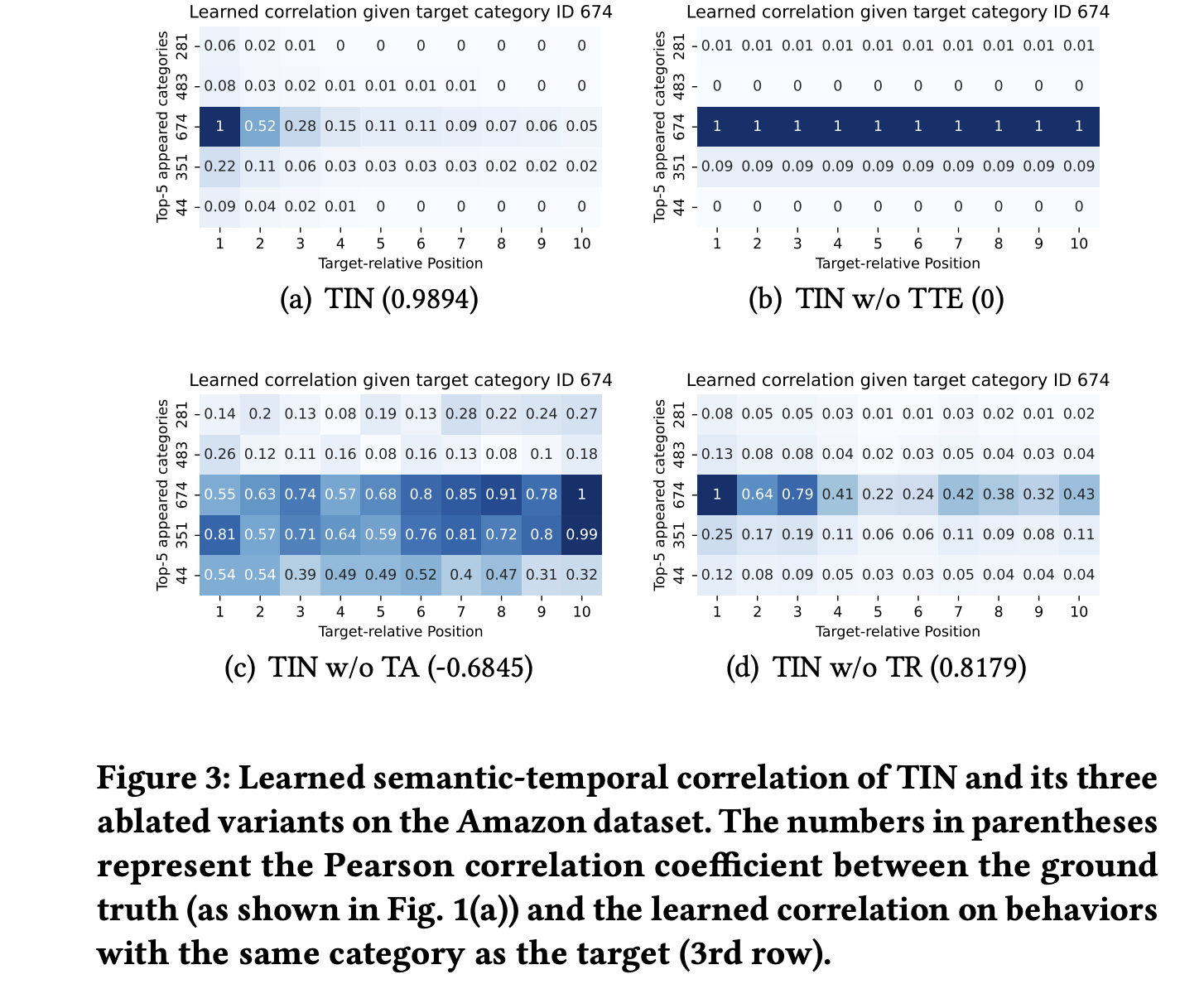
如下图[a]是top-5分类的行为与target不同的相对位置和分类 c t c_t ct为674的target的CTC真实指标,我们可以得到以下现象:
- 匹配分类之间的语义模式:与target相同分类的行为(第3行)存在着更高程度的相关性,相对比其他分类的行为
- 时序递减模式:在语义相关的行为(第3行)之中,从最近的一个行为到最远的,存在着高可信度的相关性递减
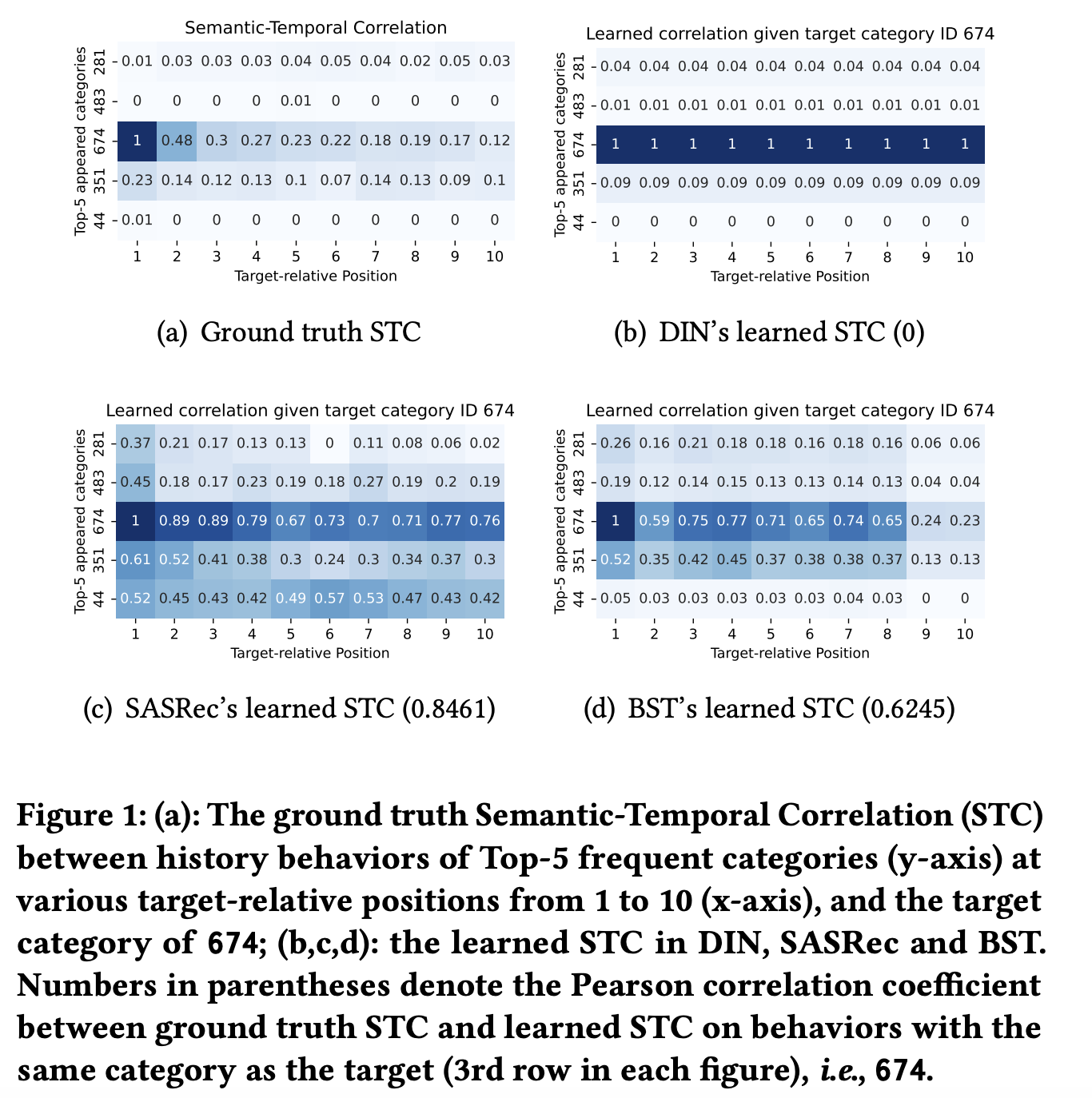
再看看与真实数据指标相比,上图[b-d]其他模型的表现:
- DIN完全没有捕获到任何时序模式,正如上图[b]第3行,缺少了位置之间的递减
- SASRec和BST展示了在学习时序相关性上的不足,正如上图[c-d]第3行的位置之间的轻微递减;并且它们还存在捕获语义相关性的缺陷,因为它们还学习到了与其他分类之间(target分类674之外的分类)的强相关性。
真实的CTC指标即STC,根据上述公式很好理解,但上图[b-d]中模型学习到的STC又如何理解?是如何计算的?有兴趣的可以留到最后再详细介绍吧。
3. TIN
论文提出的TIN(Temporal Interest Network)模型仍然是遵循主流的Embedding&MLP的范式:
- 最开始的底层,全部特征包括用户侧、item侧和上下文侧的,全部通过Embedding Layer转化为embeddings
- 其中,对用户行为特征通过时序兴趣模块(Temporal Interest Module,TIM)生成固定长度的用户兴趣表征
- 接着,TIM的输出与其他特征进行拼接,进入到多层感知器即MLP
- 最后的输出通过sigmoid函数转化为预估概率分数
TIN的整体结构如下图:

3.1 时序兴趣模块
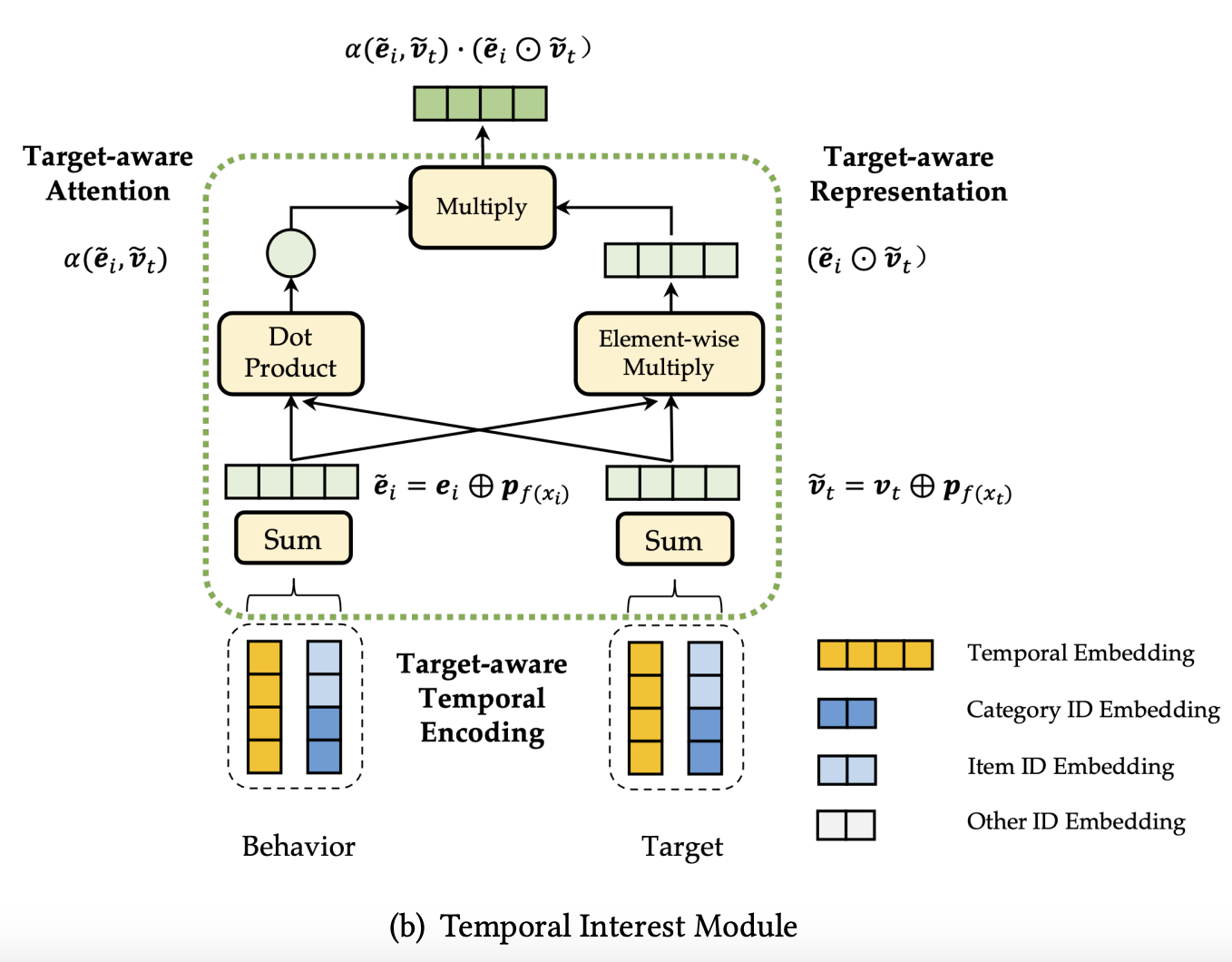
第1小节我们提到TIN使用了4阶的交互方式(behavior semantics, target semantics, behavior temporal, target temporal )来捕获语义-时序相关性,为了实现这4阶的交互,时序兴趣模块(Temporal Interest Module,TIM)引入以下几个组件,整体结构如上图:
- target感知的时序编码:Target-aware Temporal Encoding (TTE)。TTE保留行为相对于target的时序信息,再结合语义的ID Embedding,这样就实现了行为和target的时序和语义信息的捕获
- target感知的注意力和表征:Target-aware Attention (TA) and Target-aware Representation (TR)。每一种都采用了2阶的行为-target的交互
最后,将TA和TR的输出进行相乘,这样便得到了4阶的交互,如下式:
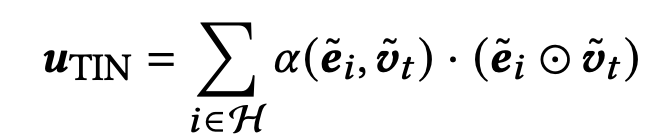
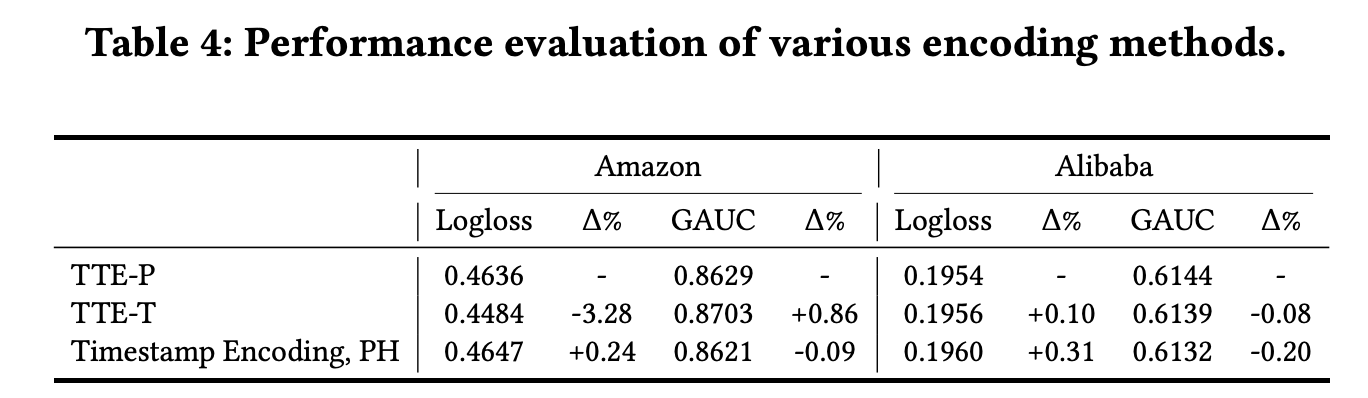
3.1.1 Target-aware Temporal Encoding (TTE)
除了将每一个行为的ID特征编码为embedding e i ∈ R e_i \in \mathbb{R} ei∈R 来捕获语义信息之外,论文还引入了行为的时序信息,聚焦于target-aware的时序方面。论文提出了两种不同的TTE方法来实现:
-
基于相对位置的时序编码(TTE-P,Target-aware Temporal Encoding based-on Position):首先将历史点击items和target按照时间排序组成序列 { X 1 , . . . , X H , X t } \{X_1,...,X_H,X_t\} {X1,...,XH,Xt}。TTE-P会将第i个行为的时序信息编码为 H − i + 1 H-i+1 H−i+1,时序embedding计算为: p f T T E − P ( X i ) ∈ R d p_{f_{TTE-P}(X_i)} \in \cal{R}^d pfTTE−P(Xi)∈Rd。而target的TTE-P值会设为0,代表着序列的起点,即target的时序embedding为: p f T T E − P ( X t ) = p 0 p_{f_{TTE-P}(X_t)} = p_0 pfTTE−P(Xt)=p0
-
基于时间间隔的时序编码(TTE-T,Target-aware Temporal Encoding based-on Time interval):TTE-T通过第i个行为与target的时间间隔来编码其对应的时序信息。记第i个行为和target的时间戳分别为 T S i TS_i TSi 和 T S t TS_t TSt,它们的时间间隔为 τ i = T S t − T S i \tau_i=TS_t-TS_i τi=TSt−TSi。与常规的连续型特征处理方法,论文同样会对其进行分箱操作 b ( ⋅ ) b(\cdot) b(⋅),更具体的是等频分箱。因此,第i个行为的TTE-T embedding则为 p f T T E − P ( X i ) = p b ( τ i ) p_{f_{TTE-P}(X_i)} = p_{b(\tau_i)} pfTTE−P(Xi)=pb(τi),而target的处理方式与TTE-P一样。
有了时序编码 p f ( X i ) p_{f(X_i)} pf(Xi),再与其语义embedding进行元素位的相加( element-wise summation),则变成了第i个行为最终的embedding: e ~ i = e i ⊕ p f ( X i ) \tilde{e}_i=e_i \oplus p_{f(X_i)} e~i=ei⊕pf(Xi)。同理,target最终的embedding也变为: v ~ t = v t ⊕ p f ( X t ) \tilde{v}_t=v_t \oplus p_{f(X_t)} v~t=vt⊕pf(Xt)。通过结合语义和时序的embeddings,进一步丰富了行为和target的表征,引入了固有的语义,以及行为和target的时序上下文。
3.1.2 TTE v.s. 按时间顺序编码
按时间顺序编码(COE,Chronological Order Encoding)是一个比较常用的添加时序/位置信息的方法,也即按照时间顺序,第i个item直接编码为i: f C O E ( X i ) = i f_{COE}(X_i)=i fCOE(Xi)=i,这在以前的NLP(比如BERT)也是普遍使用的。
论文解释了TTE与COE的区别,COE是无法做到target感知的,与target相对位置不同的行为可能会分配一样的权重。举个例子,两个长度分别10和100的序列,对于第1个行为,COE的编码都是1,即 f C O E ( X 1 ) = 1 f_{COE}(X_1)=1 fCOE(X1)=1;然而它们与target的相对位置却是有着显著差异的,COE无视了它们的不同重要性。
3.1.3 Target-aware Attention and Target-aware Representation
注意力Target-aware Attention(TA)这一块就没有提出创新的方法了,论文没有使用DIN系列的注意力方法,而是使用了transformer那一套的Scaled Dot-Product(论文只是列出了一个TA的范式公式,其中 < v t ~ , e i ~ > <\tilde{v_t},\tilde{e_i}> <vt~,ei~>可以根据数据情况换成别的注意力机制):
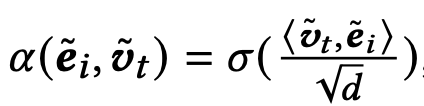
Scaled Dot-Product公式如下:
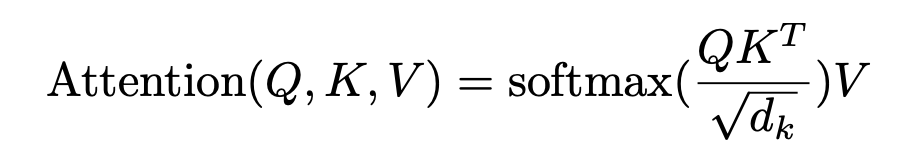
受FM系列模型的启发,论文为每个行为的行为注入了target的信息,成为了相对于target的2阶表征,也即Target-aware Representation(TR): e i ~ ⊙ v t ~ \tilde{e_i} \odot \tilde{v_t} ei~⊙vt~,最后与其他注意力机制一样,每个行为表征乘上注意力权重,即上述提到的TA乘上TR。到这里,TIN也就实现了前面提到的4阶交互:behavior semantics, target semantics, behavior temporal, target temporal。
PS:这一节,作者还提出了其他论文提及的MLP存在的问题:难以有效学习点积( dot product)和显式交互,主要是指关键的行为与target的点积/交互,这限制了模型只能或者说必须采用类似于自注意力方法实现的3阶显式交互,而TIN的4阶交互显然也能应对MLP存在的问题。
3.2 与其他模型的对比
在这里继续阐述下第2节留下的问题,模型学习到的语义-时序相关是如何计算的,位置为 f ( X i ) f(X_i) f(Xi)的行为 X i X_i Xi与target X t X_t Xt的相关性定义如下:

- z z z 是attention logit, r r r 是embedding表征
比如,TIN学习到语义-时序相关性如下式:
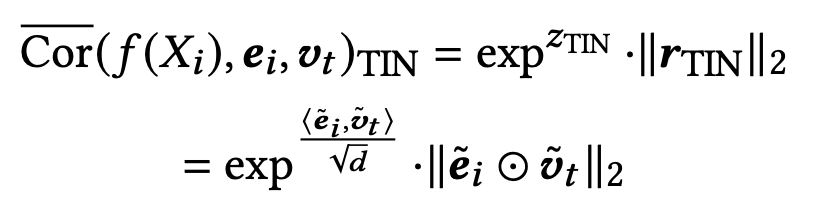
论文选择这个计算形式是能够将两个变量的交互信息和交互的参数化输出(中间输出)关联起来。
对比TIN的三个组件TTP、TA和TR:
- DIN模型包含和TA和TR,但缺少了时序编码(论文提到DIN的表征是target-aware( e i ⊙ v t e_i \odot v_t ei⊙vt,加上target的点乘),但DIN的论文看到是没考虑到target的);
- SASRec模型缺少了TA,因为它对行为使用的self-attention,那么它学习到的语义-时序相关性使用表征来衡量,即加上COE编码embedding的行为和target的element-wise product
- BST模型引入了COE和TA来捕获语义-时序相关性,但它的表征是target无关的,因为它没有行为和target的显式交互
具体的,每个模型学习到的语义-时序相关性的衡量方式如下图:

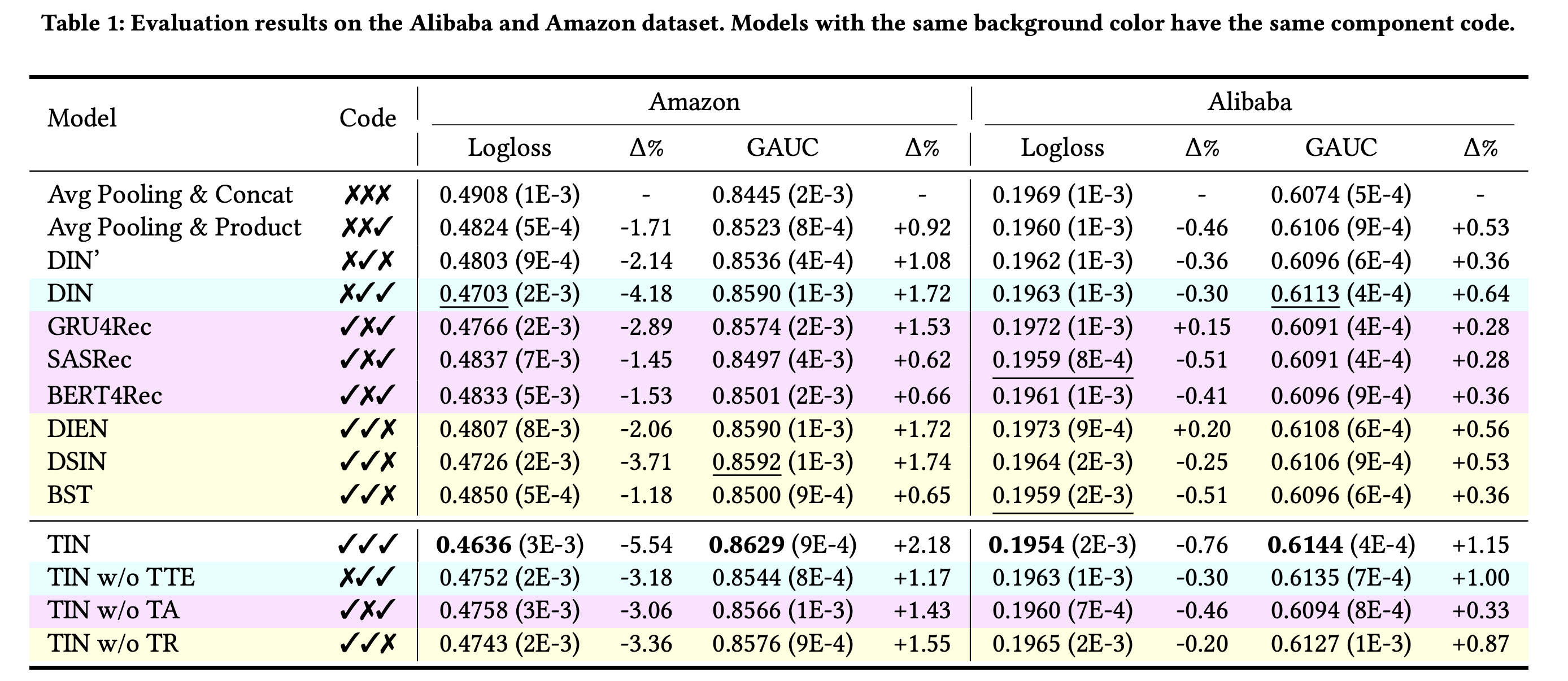
4. 实验结果
Code表示模型是否存在或者缺失时序信息(TI)、TA和TR:
总结
腾讯提出的TIN(Temporal Interest Network)模型结构其实比较简单明了,很容易接入到自己的模型中,主要就是引入新的交互模块TIM(Temporal Interest Module),包含三个关键组件:
- Target-aware Temporal Encoding (TTE):基于相对位置或者时间间隔的时序编码,提供了更为准确的相对位置信息;
- Target-aware Attention(TA):常规的attention注意力,使用了transformer模型的Scaled Dot-Product;
- Target-aware Representation(TR):行为的表征加入target的信息,加强了行为的表征能力。
然后,论文中关于语义-时序相关性的实验也比较有趣,引出了这三个组件的必要性。
代码实现
tensorflow 2.x:recsys/rank/tin.py
tensorflow 1.x:recommendation/rank/tin.py
原文地址:https://blog.csdn.net/sgyuanshi/article/details/143925069
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!