基于Python实现文本聚类的提取与量化
基于文本聚类的招聘信息技能要求提取与量化
一、研究背景与目的
网上对爬取招聘网站并对爬取的数据进行分析的技术博客多如牛毛,但对爬取的数据进行分析仅集中在分析薪资与地域、学历要求、工作年限、行业、公司规模等十分容易量化因素的关系,从职位描述中提取对应聘者的技能要求等少之又少,但技能因素是求职者评估自己是否能胜任一个岗位的重要因素,与其求职的准备、选择息息相关。
本文通过爬取实习僧网站“数据分析”一职的实习信息,对“职位描述”的文本进行预处理、分句,使用文本聚类的方式提取每条实习信息中其中的描述专业技能的句子,并对其描述的专业技能进行量化,从而探究专业技能对薪资的影响。本文所述的方法还可用于提取其他岗位、其他要求等,为大学生提供最直接、最真实的岗位信息,从而使他们对感兴趣的职业有所了解,对他们的学习方向提 供建议,使其和能更明确地为求职作准备。
二、实习招聘信息数据的获取与说明
本文选择实习僧网站中的招聘信息进行数据的抓取。目前国内市场上的招聘平台虽多,垂直于实习领域的却只有“实习僧”一个代表性产品。实习僧网站作为近几年大学生找实习的热门平台,各大公司在上面发布的实习信息更多更全。在本次抓取中,一共抓取了实习僧上所有职位名称包含“数据分析”的实习信息 351条,数据的主体为文本形式的数据。数据抓取的方式为使用python的request 库获取具体实习信息的网页源代码,通过 re 模块使用正则表达式匹配出需要的信息。爬取的数据简介如下表 1 所示:

三、文本聚类提取技能要求
本部分通过对招聘信息中“职位描述”的文本进行预处理、分句,利用 kmeans、GMM、NMF 三种文本聚类方法提取出其中与专业技能有关的句子,为后面量化专业技能作准备。
3.1 职位描述文本的预处理
由于职位描述是掺杂着标点,特殊符号,及对文本含义无意义的语助词和语气词的完整中文语句,不能直接被计算机理解,在做分析前需进行文本预处理。
文本预处理主要分为分句,分词,删除停用词,删除低频词,文本向量化处理。
3.1.1 分句
由于招聘信息中的“职位描述”是大多按序号列出对应聘者的多条要求,技能要求一般包含在其中的某一句或某几句,因此首先要对每条“职位描述”的文本进行分句,分割的符号为句号、分号、冒号、换行符等。
3.1.2 分词
文本分词是指将文章或语句中的词语按照一定标准进行划分的过程。相对于英语文本而言,汉语由于文本之间没有天然的分隔,处理其有一定的难度。将较长的语句或文章转化成较短的单词或词组,这一过程即中文分词。本研究中,采用基于统计的分词方法,通过隐马尔可夫(HMM)模型的 Viterbi 算法得到分词结果,具体分词过程是通过 Python 中 jieba 分词包实现。另外,由于数据分析领域存在不少专有词汇,如果只用 jieba 包默认的词典进行分析,则会无法识别这些专有词汇,因此在 jieba 包添加了自定义词典。
除本人对数据分析的了解而添加的词汇外,大部分词汇是通过统计 bigram 词频从而发现被误分的词组而添加的。
添加的部分词汇如表 3 所示:

3.1.3 去除停用词和特殊字符
去除停用词指过滤文本中的特殊字符和对文本含义无意义的词语。例如 “的”,“啊”一类的语气语助词,对文本情感倾向判定无意义,却在文本向量 表示时由于占据较大比重而对后续分析造成干扰,降低情感分类的准确性。同时,根据分词文本主题不同,停词表需要进行针对性地修改来提高准确性。因此,研究中用到的停词表在《哈工大停用词表》的基础上,根据帖子文本特点进行了修改。
3.1.4 去除超高频词与低频词
去除停用词后先做词频统计,发现词频极高的词,如“数据分析”、“职位描 述”、“工作职责”、“负责”“工作”等不能体现具体岗位要求的词,因此删除前 10 个超高频词。 由于存在大量无意义的低频词(本文定义出现的频率仅为 1 次的为低频词) 可能会降低分类精度,因此对去除停用词后的文本再删除低频词。
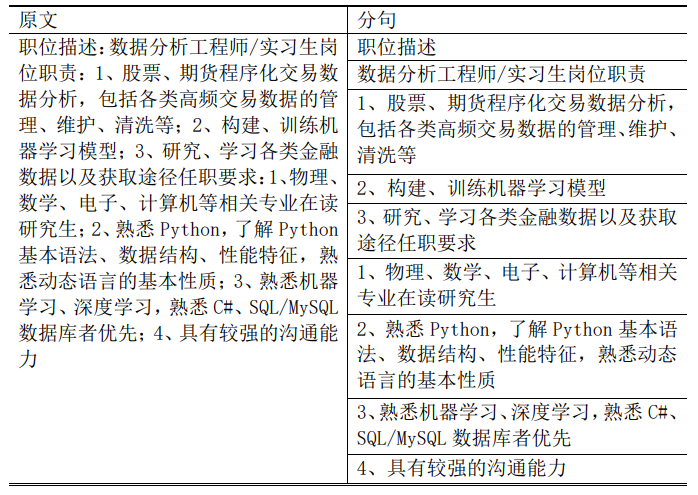
3.2 文本预处理效果
文本预处理后的文本如表 4 所示,可以看到,每一句职位描述都有大致能看出其明确的类别,日常工作任务描述通常包含“整理”“录入”“搜集”这些动词;用人单位对应聘者专业的要求通常会指定具体专业和年级,如“大三”、“大四”、 “研一”、“研二”、“统计学”、“数学”等;专业技能的描述则会指定应聘者需要掌握什么软件,如“excel”、“sql”等;通用技能、品质描述一般是要求应聘者 “具有良好职业道德”、“细心”、“认真”等;实习时间描述一般是要求应聘者能保证实习“三个月”、“六个月”等,每周到岗“三天”、“四天”等。
由此可以预见,之后的文本聚类将会取得良好效果。
3.3 文本聚类
因为计算机并不认识中文,因此需要将中文词转特征向量,本研究中文本向量化采用 tf-idf,用稀疏方式储存词-文档矩阵。矩阵维度为 tn,t 代表句子 个数,n 代表词语个数。本文预处理后的词汇有 1793 个,句子 2817 条,提取 1000 个 tf-idf 特征,得到 28171000 的文档词频矩阵。下面将用三种聚类方法 对“职位描述”中的句子进行聚类,根据聚类结果的解释性选择聚类数目。
3.3.1 Kmeans 聚类
Kmeans 是一种基于相似度的聚类方法。在聚类之前,需要用户显式地定义 一个相似度函数。聚类算法根据相似度的计算结果将相似的文本分在同一个组。在这种聚类模式下,每个文本只能属于一个组,这种聚类方法也叫“硬聚类”。 K-Means 方法是 MacQueen1967 年提出的,原理是给定一个数据集合 X 和一个整 数 K(K<n), K-Means 方法将 X 分成 K 个聚类并使得在每个聚类中所有值与该聚 类中心距离的总和最小。
经过多次尝试不同的聚类个数,发现把聚类个数定为 6 类时,能取得较好的聚类效果,即各个类别的文本能表达清晰明确的共同含义。图 1 中六个词云图展示了 kmeans 聚类的每个聚类中心的关键词,关键词大小与 kmeans 输出的权重大小有关。可以看到,前最上方的两张词云图都是描述日常工作任务,权重大的词有“整理”、“研究”、“相关”、“用户”、“数据处理”,“完成”、“项目”、“整理”、 “收集”。中间左图中,权重大的词有“接收”、“暑期实习”、“每周”、“四天” 等,可以看出这个类别的句子是跟实习时间有关。
中间右图中出现了很多数据分析常用的软件,如“python”、“excel”、“sql”、 “spss”、“sas”,说明这个类别的句子是描述专业技能的,从中可以看出,office 软件仍然是最为基础的要求,同时也要求应聘者能熟练掌握 sql 语言、使用数据库,当 python、R 软件等编程软件兴起时,像 sas、spss 等传统的统计分析软件仍然占据半壁江山,另外还有些数据分析实习要求掌握大数据相关的软件如 hadoop、hive 等。
最下方左图中权重大词有“逻辑思维”、“沟通”、“责任心”、“团队精神”、 “细心”等,说明这些品质是数据分析岗最为看重的。最下方右图则是对应聘者的学历、专业的要求描述,要求最多的专业是“统计学”、“数学”。
3.3.2 GMM 聚类
GMM 聚类是一种基于模型的聚类方法,它并不要求每个文本只属于一个组,而是给出一个文本属于不同组的概率。这种聚类方法也叫“软聚类”。这类方法通常假设数据满足一定的概率分布,聚类的过程就是要尽力找到数据与模型之间的拟合点。GMM 假设数据服从高斯混合分布(Gaussian Mixture Distribution),GMM 中的 k 个组件对应于 k 个族,所以 GMM 聚类的过程实际上是以似然函数作为评分函数,求使得似然函数最大化的 k 组参数。
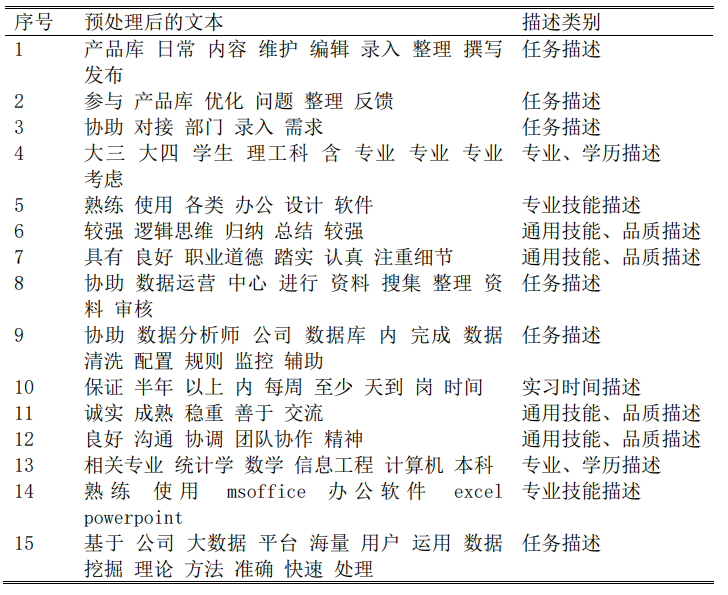
由于文本聚类的稀疏性,且本文所使用句子都有明显的特征,因此 GMM 聚类后给出的每个句子的概率都十分接近 0 或 1,相当于 kmeans 的效果。经过多次尝试不同的聚类个数,发现把聚类个数定为 8 类时,能取得较好的聚类效果,各个类别的关键词能体现明确的文本摘要。
表 5 展示了每个聚类中心的关键词。从类别的样本分布可以看出,除类别 3 有 1000 多条样本外,其他类别样本分布均匀。说明职位描述中,篇幅最大的是 日常工作任务描述。



从表中关键词可以看出,第 1、6 类是专业技能描述,第 2、 3、 8 类是任 务描述,第 4 类是实习时间描述,第 5 类是专业、学历描述,第 7 类是通用技能、品质描述。另外,尽管第 1、6 类是专业技能描述,但却略有不同,第 1 类 出现的软件为 python、java、hive、hadoop,还出现了算法、数据挖掘、机器学习等词,说明此类职位描述的对编程、对分布式、算法要求更高些,而第 6 类则只是要求应聘者会 office 办公软件,以及传统的 sas、spss 统计分析软件,也 要求 python。这说明数据分析岗仍可以往下细分为普通统计分析和偏向算法工程师的数据分析。
3.3.3 NMF 聚类
NMF 是一种非线性降维方法,降维后的矩阵相当于对原文档词频矩阵进行了特征提取,过滤噪声特征项,因此提取的特征更能反映样本的局部特征,聚类效 果更好。用 NMF 进行文档聚类的原理为,给定一个文档语料库,首先构造一个 n × p的文档-词频矩阵 X,其中 n 代表单词个数,p 代表文档个数。使用 NMF 分解矩阵Xnxp,聚类个数即为 k,得到分解矩阵Unxk和 VTkpxp。
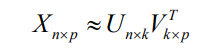
对 Unxk、Vpxk 归一化后, Vpxk 中的元素Vij 表示第 i 篇文档属于第 j 个类别的概率,因此,如果第 i 篇文档属于类别 m,则Vim在Vpxk中将取最大值,同时Vpxk 第 i 行剩下的元素的值将会很小。
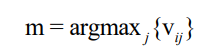
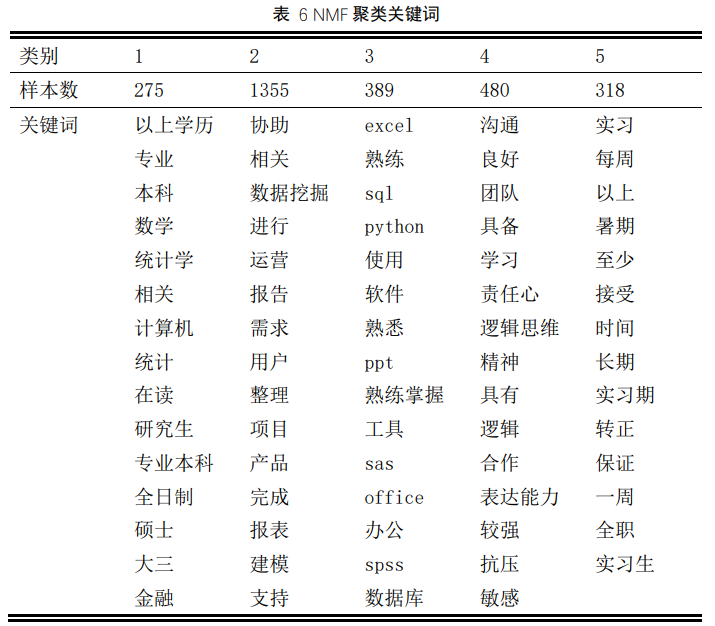
NMF 聚类的结果如表 6 所示,可以看到 NMF 仅聚成 5 个类别,即可使每个类别的文本有清晰明确的文本摘要。
3.4 聚类方法的比较
3.4.1 聚类效果
从以上展示的聚类效果来看,NMF 的聚类类别最少,仅 5 类就可以使得每个类别具有明确清晰的,符合预先设想的文本摘要。
从聚类算法运行速度来看,同样都是从 python 中 sklearn 调用的函数,NMF 最快,仅需要 0.46s;kmeans 与之相差无几,需 0.56s, GMM 最慢,需要 16.78s 才能运行完毕。
3.4.2 兰德指数
兰德指数是一种基于聚类相似度的评价指标,它通过观察一对样本点 xi,yi 在两种聚类方法中是否被分在同一个类别来判断两种聚类方法的相似性。从表 7 可以看出,GMM、kmeans 与 NMF 的聚类效果相似度低,兰德指数少于 0.3;kmeans 和 GMM 的聚类效果较相似,两者的兰德指数为 0.43,说明两者中有 43% 对样本点是分在了同一个类别或不在同一个类别。这可能是因为 GMM 是 k-Means 方法的概率变种,其基本算法框架和 k-Means 类似,都是通过多次迭代逐步改进聚类结果的质量。

四、文本聚类量化技能要求
4.1 专业技能关键词与薪资的关系
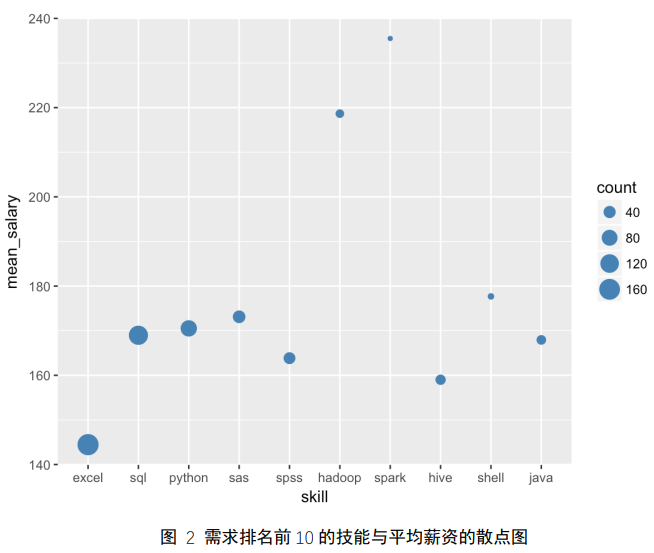
从职位描述的文本中提取专业技能关键词,并对需求频率最高的前 10 个技 能进行统计计算,得出每一个技能对应的平均薪酬水平,如图 2 所示,点的大小代表该技能需求量的多少。
在前 10 项技能中,excel 需求最大,但平均薪资最低,仅为 144 元,因为 excel 是数据分析工作最应该掌握的工具;Hadoop,Spark 这两者需求少,但平均薪酬水平最高,超过 200 元,并且相对其他技能来说有比较大的差异,因为 Hadoop, Spark 都是应用于分布式数据处理;其他软件对应得平均薪资在 160200 之间。因此专业技能对薪资有明显影响。
4.2 文本聚类量化技能要求
通过 GMM 聚类可以看出,专业技能描述也有高低之分,从前面的分析也可看出,要求应聘者掌握 hadoop、spark 等大数据分析相关技能的实习工资更高些, 但仅通过从文本中提取技能关键词来衡量技能与薪资的关系,一来需要预先知道有哪些重要技能,二来提取的技能太多会使得技能因素分散在每个技能变量上,因此每个技能变量包含的信息较少,使得这种方法更为繁琐,缺乏普适性,且不利于分析技能与薪资的关系。
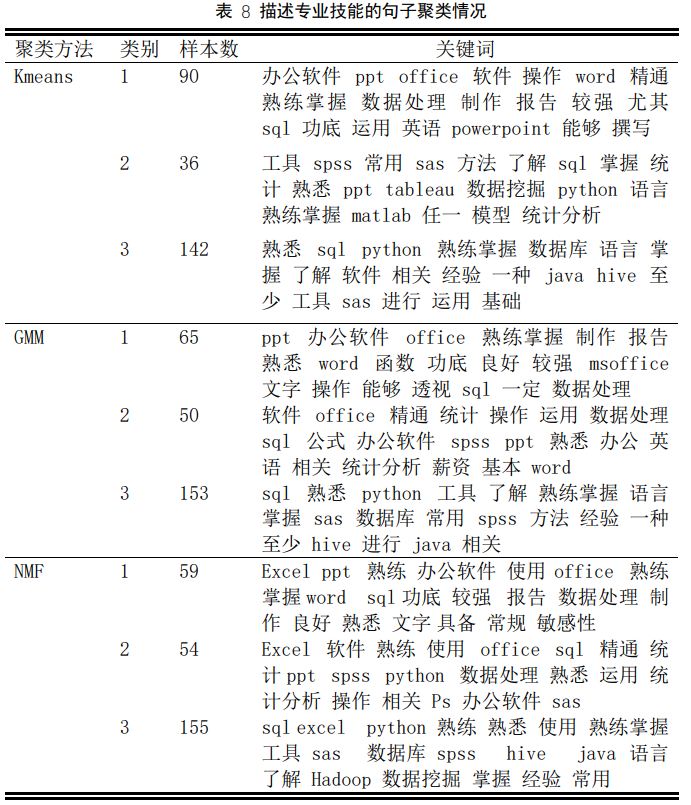
因此可以将每条样本的职位描述中专业技能描述的句子挑出来再进行聚类,使用聚类方法为句子所述的技能进行评分,这样无需一个个提取技能关键词,且把句子中的关键词综合考量。考虑到以上三种聚类算法的相似度并不高,因此将以上几种聚类方法挑出的描述专业技能的句子取并集,构成小型专业技能描述句子语料库,对该语料库再次进行聚类,使用以上三种方法的聚类效果表 8 所示。
从关键词一栏可以看到,三种聚类方法均能把描述专业技能的句子聚成三种相似的类别。第一种仅要求应聘者掌握 msoffice 软件和 SQL 查询语言,第二种除了要求掌握 msoffice 和 SQL 查询语言以外,还要求掌握其他统计分析软件, 如 sas、spss、python 等,而第 3 种则还要求应聘者会应用与大数据、计算机有关的软件,如 hive、hadoop、Java 等。
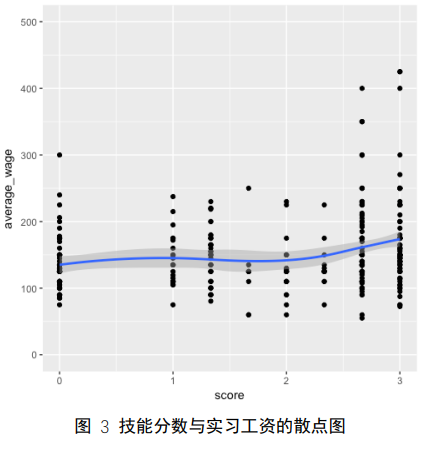
将每种方法聚出的这三类分别打分为 1 分、2 分、3 分,该职位的技能要求分数取三种方法打分的平均值,从而量化职位的技能要求。图 3 散点图显示了技能分数与平均工资的关系,可以看出大部分实习工资集中在 100-200 之间,而当技能分数超过 2.5 时,有一些实习的工资能超过 300,从 loess 拟合的回归曲线可以看出轻微渐升的趋势,说明技能要求越高,公司愿意支付的工资越多。
五、技能与薪资的回归分析
实习工资的高低还跟很多因素有关,如地域、行业等,因此接下来把这些因素考虑进去,以实习工资为因变量进行回归分析,重点观察技能分数对实习工资的影响。
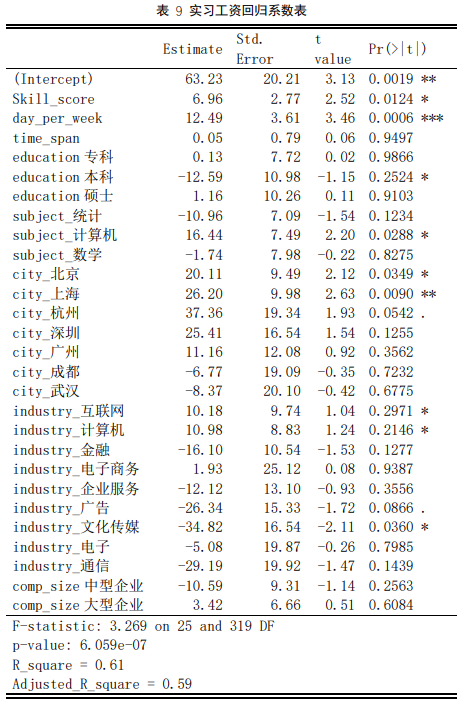
从表 9 可以看出,技能分数对实习工资有显著影响,实习分数每多一分,即多掌握一门常用统计软件甚至多掌握一门大数据分析相关软件,则平均实习工资涨约 7 元。因为仅仅是实习而不是正式员工,不同的实习,日实习工资几乎只在 100-200 内浮动,因此技能对工资上涨影响不太大。
其他方面,从实习时间上看,要求一周实习天数越多,说明公司越需人数,愿意开出的实习工资越高;从学历要求上看,要求学历是本科生的实习工资比不限专业的工资低 12.59 元;从专业要求上看,要求专业是计算机的实习工资比专业要求为其他的实习工资高 16.44,计算机专业出身的学生仍是就业市场中的热点需求;从实习地点上看,北上广深杭的实习工资比其他城市多 20 元以上,其中杭州的实习比其他城市的实习高 37 元,而成都、武汉则比其他城市少 5 元以 上;从公司行业上看,互联网、计算机行业的公司更为大方些,开出的实习工资更高;从公司规模上看,中型企业比小型企业开出的实习工资少 10 元,而大型企业则比小型企业多 3 元,工资条件仍是大公司吸引就业者的优势。
在该回归方程中,F 检验显著,R 方仅为 0.6,说明自变量对实习工资的波动仅解释了 60%,另外实习工资还跟具体公司规定,市场行情有关。
六、结论
本文通过爬取实习僧网站“数据分析”一职的实习信息,对“职位描述”的文本进行预处理、分句,使用文本聚类的方式提取其中的描述专业技能的句子, 并对这些句子再一次进行聚类,区分不同层次的技能要求,并对职位的技能要求进行打分,从而实现岗位信息中技能要求的量化,使得技能与薪酬的关系能更深 入地分析。通过以上分析,可以得出以下三个结论:
- 第一,数据分析师需求频率排在前列的技能有:SQL,Excel, SAS,SPSS, Python, Hadoop 和 MySQL 等,其中 SQL 和 Excel 简直可以说是必备技能
- 第二,海量数据、分布式处理框架是走向高薪的正确方向
- 第三,SQL 语言和传统的 SAS,SPSS 两大数据分析软件,能够让你在保证中等收入的条件下,能够适应更多企业的要求,也就意味着更多的工作机会
本文仅以实习僧网站的数据分析实习岗为例,阐述如何通过文本聚类的方法提取并量化职位描述中的专业技能要求,因此数据量比较小,代表性不够好,另外结果适合于实习方面的数据分析岗而不是正式工作。另外本次分析主要针对工 具型的技能进行了分析。但实际上数据分析师所需要具备的素质远不止这些,还需要有扎实的数学、统计学基础,良好的数据敏感度,开拓但严谨的思维等。
原文地址:https://blog.csdn.net/s1t16/article/details/144076274
免责声明:本站文章内容转载自网络资源,如侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!