【LLM】RedisSearch 向量相似性搜索在 SpringBoot 中的实现
目录
1. 前言
写这篇文章挺不容易的,网络上对于 SpringBoot 实现 Redis 向量相似性搜索的文章总体来说篇幅较少,并且这些文章很多都写得很粗糙,或者不是我想要的实现方式,所以我不得不阅读大量官方文档,边试错,边修改,这花费了不少时间,不过好在结果还不错。
话不多说,下面说下这篇文章。这篇文章将介绍两种实现方式,
第一种为使用 Jedis 中的 UnifiedJedis 类实现,
第二种为使用 SpringAI 中的 VectorStore 实现。通过这边文章你将收获,如何使用阿里百炼 Embedding 模型实现文本向量化,如何通过连接池获取 UnifiedJedis 对象,如何在 SpringBoot 中实现向量数据的存储以及使用 fTSearch 进行向量相似性搜索,如何使用 SpringAI 的 VecotStore。
2. 前提条件
- 已安装 Redis Stack ,如何安装请参考 docker compose 安装 Redis Stack 。
- 已对 Redis 作为向量库有了解,如不了解请参考 Redis 作为向量库入门指南。
- 项目中引入了 Spring AI Alibaba ,如何引入请参考 Spring AI Alibaba 的简单使用 。
-
项目中引入了 Redis ,如何引入请参考 SpringBoot 引入 redis 。
3. 使用 UnifiedJedis 实现
注:这个方式需要你先创建向量索引,如果不了解请参考
Redis 作为向量库入门指南 。需要注意的是这个方式基于创建的索引数据类型为
Hash 。
3.1 引入依赖
我的 SpringBoot 版本为3.2.4,spring-ai-alibaba-starter 版本升级为了
1.0.0-M3.2,jdk 版本为17。
注:需要注意我之前文章使用的 Redis 客户端为 lettuce,但因其对 RedisSearch 语法支持较差,所以我改为使用 Jedis。Jedis 中的 UnifiedJedis 类对 RedisSeach 语法有很好的支持。
3.1.1 引入 Redis 客户端
我们使用 spring-boot-starter-data-redis 来集成和管理 Redis, 使用 Jedis 作为 Java 中 Redis 的客户端,注意 SpringBoot2.0 默认使用 lettuce 作为客户端,需要排除 lettuce-core 包。
我的 spring-boot-starter-data-redis 版本为
3.2.4,jedis 的版本为
5.2.0。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
注:建议引入 spring-boot-starter-parent 用来管理 SpringBoot 项目的依赖版本和构建配置。
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.4</version>
</parent>3.1.2 引入 Spring AI Alibaba
这个实现方式中,项目中引入 spring-ai-alibaba 主要是为了调用阿里百炼 Embedding 模型实现文本向量化,如果你有其它的文本向量化包,可以改为引用其它的。
我使用的版本是 1.0.0-M3.2,对应 Spring AI 的版本为 1.0.0-M3。
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter</artifactId>
</dependency>3.2 添加配置
3.2.1 添加 redis 配置
application.yml 文件中添加redis相关配置,包含 host、port、password、连接池信息等。
spring:
data:
redis:
database: 0
host: 127.0.0.1
port: 6379
password: gusy1234
jedis:
pool:
# 连接池最大连接数
max-active: 8
# 连接池最大空闲连接数
max-idle: 8
# 连接池最大阻塞等待时间,负值表示没有限制
max-wait: 0
# 连接池最小空闲连接数
min-idle: 2
# 连接超时时间(毫秒)
timeout: 10003.3 配置连接池
3.3.1 使用自定连接池
这个是我读 Jedis 代码摸索出来的,也用了一些时间琢磨,在此做个记录吧,更推荐使用
第二种。使用自定义连接池管理 UnifiedJedis:
@Bean
public UnifiedJedis unifiedJedis() {
HostAndPort hostAndPort = new HostAndPort(host, port);
// 设置 Jedis 客户端配置
DefaultJedisClientConfig jedisClientConfig = DefaultJedisClientConfig.builder()
.password(password)
.database(database)
.build();
// 设置连接池参数
ConnectionPoolConfig poolConfig = new ConnectionPoolConfig();
poolConfig.setMaxTotal(maxActive);
poolConfig.setMaxIdle(maxIdle);
poolConfig.setMinIdle(minIdle);
PooledConnectionProvider provider = new PooledConnectionProvider(hostAndPort, jedisClientConfig, poolConfig);
return new UnifiedJedis(provider);
}3.3.2 (推荐)使用 JedisPooled
比较意外的是,在尝试使用 Spring AI 的 Redis VectorStore 实现时,阅读源码,发现了一个更好的创建 UnifiedJedis 连接池的方式,并且是 Redis 推荐的方式(
Redis 官方文档),就是使用 JedidsPooled。
JedisPooled 继承自
UnifiedJedis。JedisPooled 在 Jedis 版本
4.0.0 中添加,提供了
类似于
JedisPool 的功能,但具有更直接的 API。相比于 JedisPool ,JedisPooled 作为连接池更为简单,其不需要为每个命令添加一个
try-with-resources 块。
@Bean
public JedisPooled jedisPooled() throws URISyntaxException {
ConnectionPoolConfig poolConfig = new ConnectionPoolConfig();
// 池中最大活跃连接数,默认 8
poolConfig.setMaxTotal(maxActive);
// 池中最大空闲连接数,默认 8
poolConfig.setMaxIdle(maxIdle);
// 池中的最小空闲连接数,默认 0
poolConfig.setMinIdle(minIdle);
// 启用等待连接变为可用
poolConfig.setBlockWhenExhausted(true);
// 等待连接变为可用的最大秒数,jdk17 以上支持,低版本可用 setMaxWaitMillis
poolConfig.setMaxWait(Duration.ofSeconds(1));
// 控制检查池中空闲连接的间隔时间,jdk17 以上支持,低版本可用 setTimeBetweenEvictionRunsMillis
poolConfig.setTimeBetweenEvictionRuns(Duration.ofSeconds(1));
return new JedisPooled(poolConfig, new URI(redisUri));
}3.4 Text Embedding
3.4.1 调用百炼 Embedding Model
使用百炼 Embedding 模型实现将文本转成向量数组,并且自定义了使用的 模型和向量维度等参数。
public List<Embedding> textEmbedding(List<String> texts) {
// 调用百炼 Embedding 模型
EmbeddingResponse embeddingResponse = dashScopeEmbeddingModel.call(
new EmbeddingRequest(texts,
DashScopeEmbeddingOptions.builder()
.withModel(DashScopeApi.EmbeddingModel.EMBEDDING_V3.getValue()) // 设置使用的模型
.withTextType(DashScopeApi.DEFAULT_EMBEDDING_TEXT_TYPE) // 设置文本类型
.withDimensions(1024) // 设置向量维度,可选768、1024、1536
.build()));
List<Embedding> results = embeddingResponse.getResults();
// 打印向量
// if (CollectionUtils.isEmpty(results)) {
// int tempSize = results.size();
// for (int i = 0; i < tempSize; i++) {
// float[] embeddingValue = results.get(i).getOutput();
// log.info("embeddingValue:{}", embeddingValue.toString());
// }
// }
return results;
}3.5 向量数据入库
3.5.1 主要代码
向量数据入库,存入
Hash 类型数据。
@Autowired
private RedisTemplate redisTemplate;
/**
* 存入向量信息
*
* @param key redis KEY
* @param vectorField 向量存储字段名
* @param vectorValue 向量值
* @param contentField 向量文本内容存储字段名
* @param content 向量文本内容,增加存储文本内容,方便查看向量的内容
*/
public void addDocument(String key, String vectorField, float[] vectorValue, String contentField, String content) {
// 将向量值转为二进制
byte[] vectorByte = CommonUtil.floatArrayToByteArray(vectorValue);
// 组装字段map
Map<String, Object> fieldMap = new LinkedMap<>();
fieldMap.put(contentField, content.getBytes(StandardCharsets.UTF_8));
fieldMap.put(vectorField, vectorByte);
// 入库
redisTemplate.opsForHash().putAll(key, fieldMap);
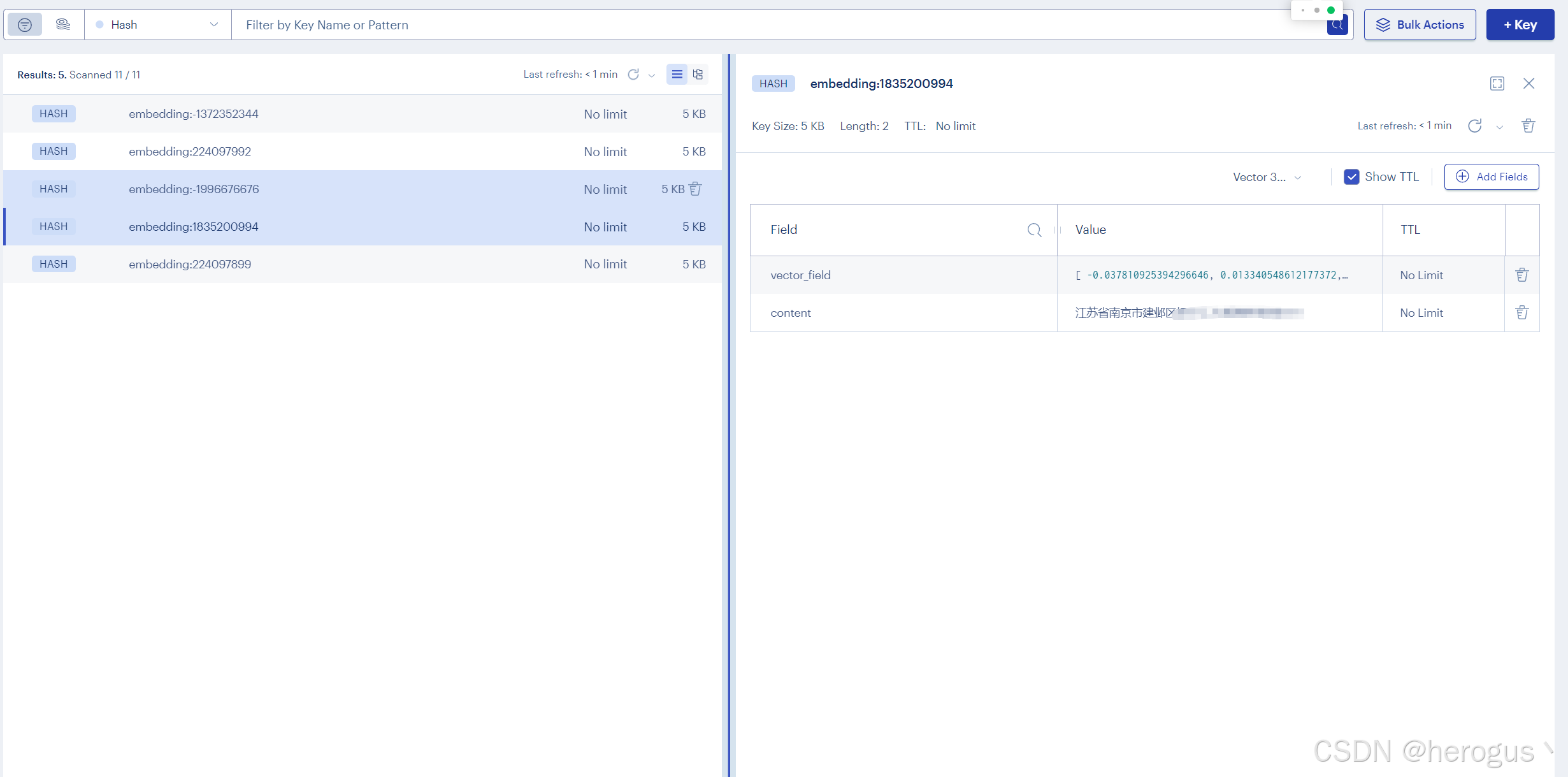
}3.5.2 存储数据展示
可以看到存储的数据类型为
Hash ,其中
vector_filed 为存储的向量值,
content 为向量文本内容。
3.6 查询相似度
3.6.1 主要代码
执行
FT.SEARCH 查询相似度,基于 KNN 算法(k 近邻算法),并且使用余弦相似度度量法作为 KNN 的距离度量方式。
@Autowired
private JedisPooled jedisPooled;
/**
* 相似度搜索
*
* @param queryVector 查询的向量内容
* @param k 返回 k 个最相似内容
* @param indexName 索引名称
* @param vectorField 向量存储字段名
* @return
*/
public SearchResult similaritySearch(float[] queryVector, int k, String indexName, String vectorField) {
// 组装查询
// 同:FT.SEARCH embedding_index "* => [KNN 3 @vector_field $query_vector AS distance]"
// PARAMS 2 query_vector "\x12\xa9\xf5\x6c"
// SORTBY distance
// DIALECT 4
Query q = new Query("*=>[KNN $K @" + vectorField + " $query_vector AS distance]").
returnFields("content", "distance").
addParam("K", k).
addParam("query_vector", CommonUtil.floatArrayToByteArray(queryVector)).
setSortBy("distance", true).
dialect(4);
// 使用 UnifiedJedis 执行 FT.SEARCH 语句
try {
SearchResult result = jedisPooled.ftSearch(indexName, q);
log.info("redis相似度搜索,result:{}", JSONObject.toJSONString(result));
return result;
}
catch (Exception e) {
log.warn("redis相似度搜索,异常:", e);
throw new ErrorCodeException(e.getMessage());
}
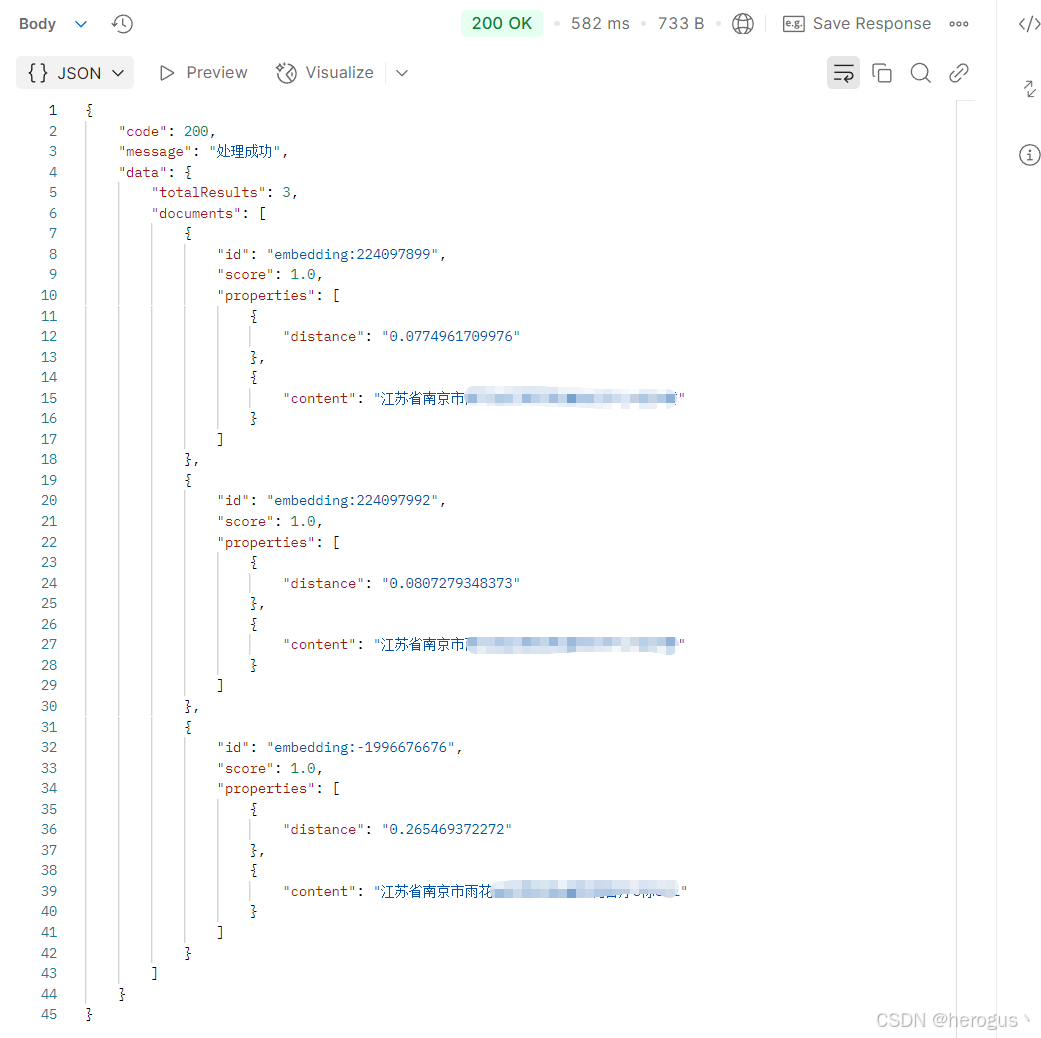
}3.6.2 查询结果展示
其中
distance 为两向量的距离。
3.7 工具方法
3.7.1 float[] 转二进制
/**
* float[] 转二进制
*
* @param floats
* @return
*/
public static byte[] floatArrayToByteArray(float[] floats) {
byte[] bytes = new byte[Float.BYTES * floats.length];
ByteBuffer.wrap(bytes).order(ByteOrder.LITTLE_ENDIAN).asFloatBuffer().put(floats);
return bytes;
}4 SpringAI VectorStore 实现
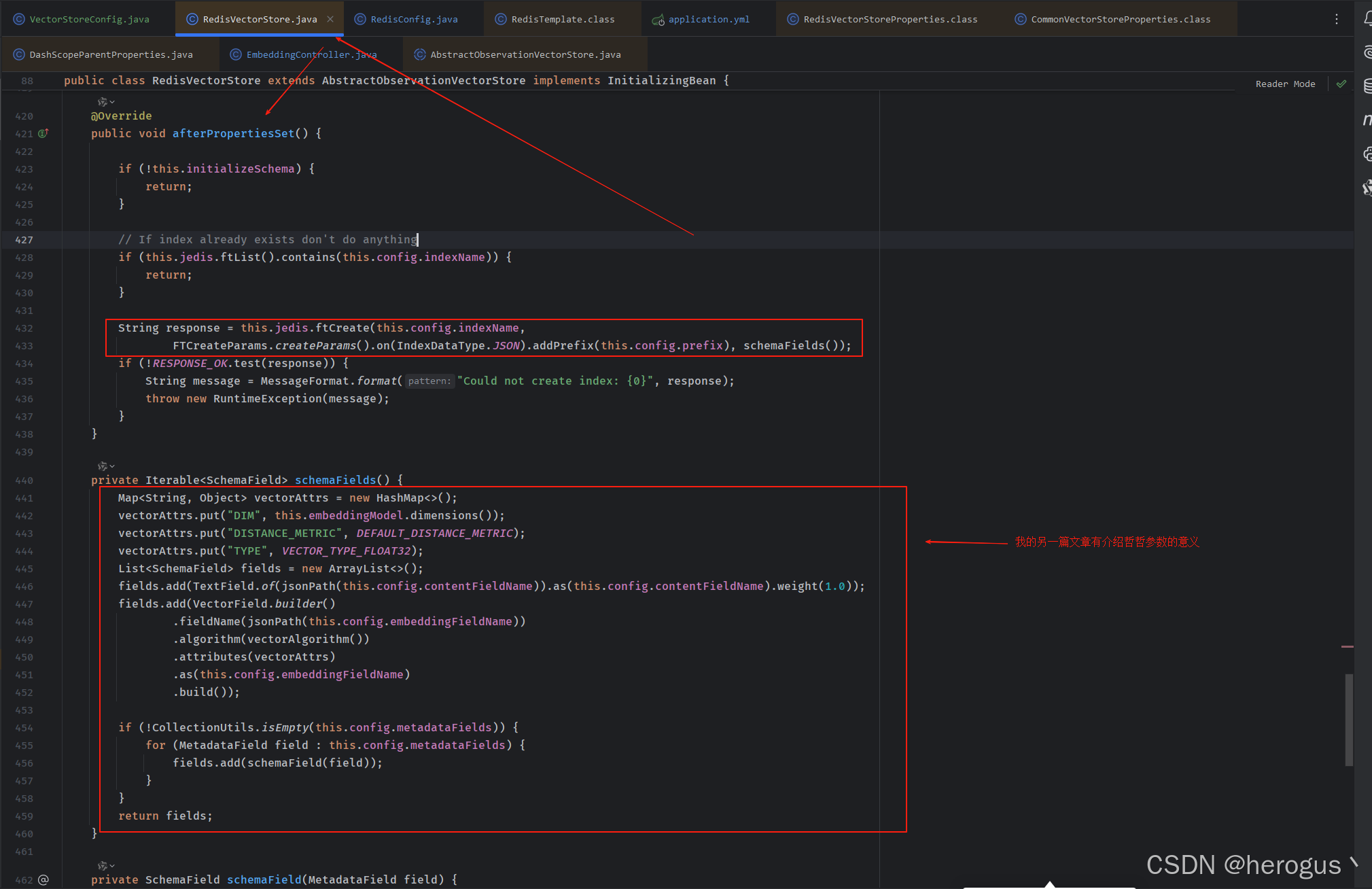
Spring AI VectorStore 的实现跟我上面的实现逻辑差不多,只不过 Spring AI 将向量入库和查询都封装成通用的,减少代码量,并且其它向量库的 jar 也都实现了上述接口,可已更方便快捷的切换向量库。
如果配置文件中
initialize-schema 值为
true,索引将在配置初始化的时候自动被创建。
其代码位置( RedisVectorStore. afterPropertiesSet),可以看到其创建的索引数据类型为 JSON,使用余弦计算相似度,下面的 schemaFields() 在我的另一篇文章
Redis 作为向量库入门指南 中有介绍。
4.1 引入依赖
4.1.1 引入 Spring AI Alibaba
我使用的版本是 1.0.0-M3.2,对应 Spring AI 的版本为 1.0.0-M3。
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter</artifactId>
</dependency>4.1.2 引入 Spring Ai Redis Store
这是 SpringAI 中 Redis 作为 VectorStore 的包,由 spring 提供,跟 SpringAI 版本相同。
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-redis-store-spring-boot-starter</artifactId>
</dependency>4.2 添加配置
4.2.1 添加 Spring Ai Alibaba 配置
application.yml 中添加:
spring:
ai:
dashscope:
# 阿里百炼平台申请的 api_key -->
api-key: your api_key
chat:
client:
enabled: true4.2.2 添加 Spring AI Redis Store 配置
这里我使用了手动配置,与 Spring AI 中 自动配置的参数稍有区别,请甄别(
Spring AI Redis VectorStore 使用), application.yml 中添加:
spring:
data:
redis:
# uri 为 spring ai 中使用 redis 作为 Vector Store 的配置
uri: redis://:gusy1234@127.0.0.1:6379/0
ai:
# 这里我多包了一层 mine ,因为如果多加一层,spring 会自动装配
mine:
# redis 作为向量库的配置
vectorstore:
redis:
# 是否初始化索引信息
initialize-schema: true
# 索引名称,默认 spring-ai-index
index-name: spring-ai-index
# 向量字段 key 的前缀,默认 embedding:
prefix: 'embedding-ai:'
# 文档批处理计算嵌入的策略。选项为 TOKEN_COUNT 或 FIXED_SIZE
batching-strategy: TOKEN_COUNT4.3 配置 JedisPooled 连接池
同
3.3.2 。
4.4 配置 VectorSotre
新增
VectorStoreConfig 配置类,
VectorSotre 配置之前你需要先配置 EmbeddingModel 和 JedisPooled 。
注:官网文档中的代码已过时,这是最新的实现方式。
@Resource
private DashScopeEmbeddingModel dashScopeEmbeddingModel;
@Resource
private JedisPooled jedisPooled;
@Bean("vectorStoreWithDashScope")
public VectorStore vectorStore() {
return new RedisVectorStore(RedisVectorStore.RedisVectorStoreConfig.builder()
.withIndexName(indexName)
.withPrefix(prefix)
// .withEmbeddingFieldName("embedding") // 向量字段名,默认 embedding
// .withContentFieldName("content") // 文本字段名,默认 content
.build(), embeddingModel, jedisPooled, initializeSchema); // initializeSchema 为是否初始化索引配置信息
}4.5 向量数据入库
4.5.1 主要代码
@Autowired
@Qualifier("vectorStoreWithDashScope")
private VectorStore vectorStore;
// 向量入库主要代码
List<String> inputInfos = List.of("文本1","文本2");
List<Document> documentList = new ArrayList<>();
inputInfos.forEach(text -> {
documentList.add(new Document(text));
});
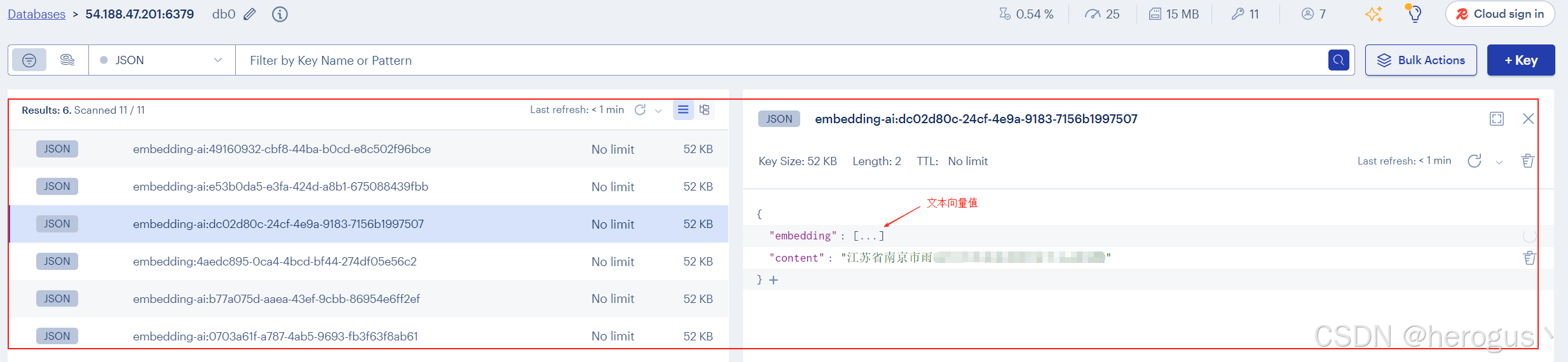
vectorStore.add(documentList);4.5.2 存储数据展示
可以看到 Spring AI 存储的向量为
JSON 格式,其 Redis 库中的内容如下,其中
embedding 为向量内容,
content 为向量文本:
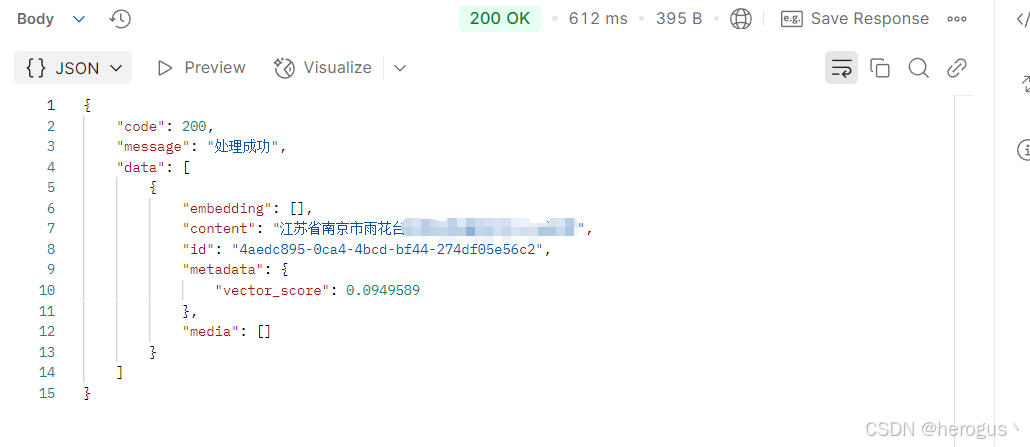
4.6 查询相似度
4.6.1 主要代码
可以看到代码实现很简单,参数也都是熟悉的,这里不再赘述。
// 相似度查询主要代码
List<Document> result = vectorStore.similaritySearch(org.springframework.ai.vectorstore.SearchRequest.defaults()
.withQuery(inputInfos.get(0)) // 查询的内容
.withTopK(3)
// 一个值从 0 到 1 的双精度数,接近1的值表示更高的相似性。默认为为0.75。
.withSimilarityThreshold(0.6)
);4.6.2 查询结果展示
5. 参考文档
原文地址:https://blog.csdn.net/u013176571/article/details/145235761
免责声明:本站文章内容转载自网络资源,如侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!