PgSQL汇总
SQL==
sql执行顺序
1.from
2.on
3.join
4.where
5.group by(开始使用select中的别名,后面的语句中都可以使用)
6. avg,sum..
7.having
8.select
9.distinct
10.order by
11.limit
⭐流程控制语句
CASE
写法一:
CASE case_value
WHEN when_value THEN
statement_list
ELSE
statement_list
END CASE;
写法二:
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
...
ELSE result_default
END
举例:
"GoodQty1" =CASE WHEN T1."U_QuantityType" = '良品' THENT1."Quantity" ELSE TT."GoodQty1" END,
"BadQty1" = CASE WHEN T1."U_QuantityType" = '不良' THENT1."Quantity" ELSE TT."BadQty1" END,
FOR
FOR var IN query LOOP
statement_list
END LOOP;
var是一个变量,用于存储每次循环迭代中的当前值。query是一个SELECT语句,返回一个结果集。statements是在每次迭代中执行的 SQL 或 PL/pgSQL 语句块
-- 示例
DO $$
DECLARE
rec RECORD;
BEGIN
FOR rec IN SELECT id, name FROM users WHERE active = true LOOP
RAISE NOTICE 'Active user: id=%, name=%', rec.id, rec.name;
END LOOP;
END $$;
IF…ELSE
IF search_condition THEN
statement_list
ELSE
statement_list
END IF;
LOOP
LOOP
statement_list
IF exit_condition THEN
EXIT;
END IF;
END LOOP;
WHILE
WHILE search_condition LOOP
statement_list
END LOOP;
$单据状态显示
一般不用下面代码,窗口设置——数据源——自定义项 就好了。
SELECT
"DocStatus",
CASE
WHEN "DocStatus" = 'O' THEN '未清'
WHEN "DocStatus" = 'Q' THEN '已取消'
WHEN "DocStatus" = 'C' THEN '已清'
ELSE '未知状态'
END AS status_description
FROM
"U_AAB_OCDB";
或者这样写:
select
case "Sex"
when '1' then '男'
when '2' then '女'
end as sex
from "U_AAB_OSTU"
$总金额
select @Price*@Num AS "Total"
$自定义下拉类型数据
SELECT '水果' AS type
UNION ALL
SELECT '家具' AS type
UNION ALL
SELECT '电器' AS type;
$日期
$查询周内数据
-- 一周内
AND "Date" >= TO_CHAR(CURRENT_DATE - INTERVAL '7 days', 'YYYYMMDD')
AND "Date" <= TO_CHAR(CURRENT_DATE, 'YYYYMMDD')
-- 本周内(右侧日期为text类型)
LEFT("TestTime", 8) >= TO_CHAR(DATE_TRUNC('week', CURRENT_DATE), 'YYYYMMDD')
AND LEFT("TestTime", 8) < TO_CHAR(DATE_TRUNC('week', CURRENT_DATE) + INTERVAL '1 week', 'YYYYMMDD')
-- 本周内(右侧日期为TIMESTAM写法)
AND "DateTime" >= TO_TIMESTAMP(TO_CHAR(DATE_TRUNC('week', CURRENT_DATE), 'YYYYMMDD'), 'YYYYMMDD')
AND "DateTime" < TO_TIMESTAMP(TO_CHAR(DATE_TRUNC('week', CURRENT_DATE) + INTERVAL '1 week', 'YYYYMMDD'), 'YYYYMMDD')
-- 本周内(右侧日期为Date类型)
AND t0."Time" >= DATE_TRUNC('week', CURRENT_DATE)
AND t0."Time" < DATE_TRUNC('week', CURRENT_DATE) + INTERVAL '1 week'
$近一周近一月
--根据下次计划审核日期来,增加一个筛选,近一周,近一个月这种筛选
AND (
( @TimeFilter = '近一周' AND t1."NextDate" <= CURRENT_DATE + INTERVAL '7 days' )
OR ( @TimeFilter = '近一个月' AND t1."NextDate" <= CURRENT_DATE + INTERVAL '1 month' )
OR ( @TimeFilter IS NULL OR @TimeFilter = '' ) -- 添加默认情况
)
$格式化日期
获取天数差
select '2024-11-18 12:11:33'::date - '2024-11-13 12:11:33'::date
获取小时差
-- 小时差 = 24h内的小时差 + 天数差*24h
SELECT EXTRACT(HOUR FROM age('2024-11-14 12:11:33'::timestamp, '2024-11-13 9:11:33'::timestamp)) -- 获取24h内的小时差
+ EXTRACT(DAY FROM age('2024-11-14 12:11:33'::timestamp, '2024-11-13 9:11:33'::timestamp)) * 24; -- 获取天数差*24h
date_trunc()
date_trunc(unit, timestamp)
其中,参数解释如下:
unit:指定截断的单位,可以是以下之一:
'microseconds','milliseconds','second','minute','hour','day','week','month','quarter','year'
timestamp:要截断的日期或时间戳。示例用法:
截断到天:
SELECT date_trunc('day', TIMESTAMP '2024-06-26 14:30:45'); -- 结果: 2024-06-26 00:00:00截断到月:
SELECT date_trunc('month', TIMESTAMP '2024-06-26 14:30:45'); -- 结果: 2024-06-01 00:00:00截断到年:
SELECT date_trunc('year', TIMESTAMP '2024-06-26 14:30:45'); -- 结果: 2024-01-01 00:00:00截断到小时:
SELECT date_trunc('hour', TIMESTAMP '2024-06-26 14:30:45'); -- 结果: 2024-06-26 14:00:00通过
date_trunc()函数,可以方便地将日期或时间戳按照指定精度截断,返回一个新的日期或时间戳。
SELECT
"StartTime",
"EndTime",
"Place"
FROM
"U_ALF_OARR1"
WHERE
"StartTime" > date_trunc ( 'day', CURRENT_DATE )
AND "StartTime" < date_trunc ('day',CURRENT_DATE + INTERVAL '2 day')
TO_CHAR ()
要将日期格式化为“年月日时分秒”,但是结果是字符类型。
TO_CHAR(T1."CreatDate", 'YYYY.MM.DD HH24:MI:SS')
TO_CHAR ( "CreatDate", 'YYYY.MM.DD' )
SELECT
*,
TO_CHAR ( "CreatDate", 'YYYY.MM.DD' ) AS FormattedCreatDate
FROM
"U_AAB_OCDB1" T1
WHERE
"CreatDate" BETWEEN '2023-12-01'
AND '2024-03-01';
日期格式化可以根据不同的需求和编程语言进行灵活选择。以下是一些常见的日期格式化示例:
'HH24:MI:SS':15:20:09 24小时时间制
ISO 8601 标准格式:
YYYY-MM-DD:例如 2024-06-25
YYYY-MM-DDTHH:mm:ss:带时间的ISO 8601格式,例如 2024-06-25T14:30:00
美国标准日期格式:
MM/DD/YYYY:例如 06/25/2024
MM/DD/YYYY HH:mm:ss:带时间的格式,例如 06/25/2024 14:30:00
欧洲标准日期格式:
DD/MM/YYYY:例如 25/06/2024
DD/MM/YYYY HH:mm:ss:带时间的格式,例如 25/06/2024 14:30:00
RFC 2822 格式:
D, d M YYYY HH:mm:ss ZZ:例如 Tue, 25 Jun 2024 14:30:00 +0000
自定义格式(具体格式可以根据需要自由定义):
YYYY年MM月DD日 HH时mm分ss秒:例如 2024年06月25日 14时30分00秒
在实际开发中,根据不同的需求选择合适的日期格式是很重要的。大多数编程语言和数据库系统提供了丰富的日期格式化函数和工具,以满足不同的格式化需求。
$序号生成
在模板中常在表格最左侧使用“序号”字段,此时,可以借助窗口函数生成序号1,2,3,…
窗口函数
排序
核心代码:
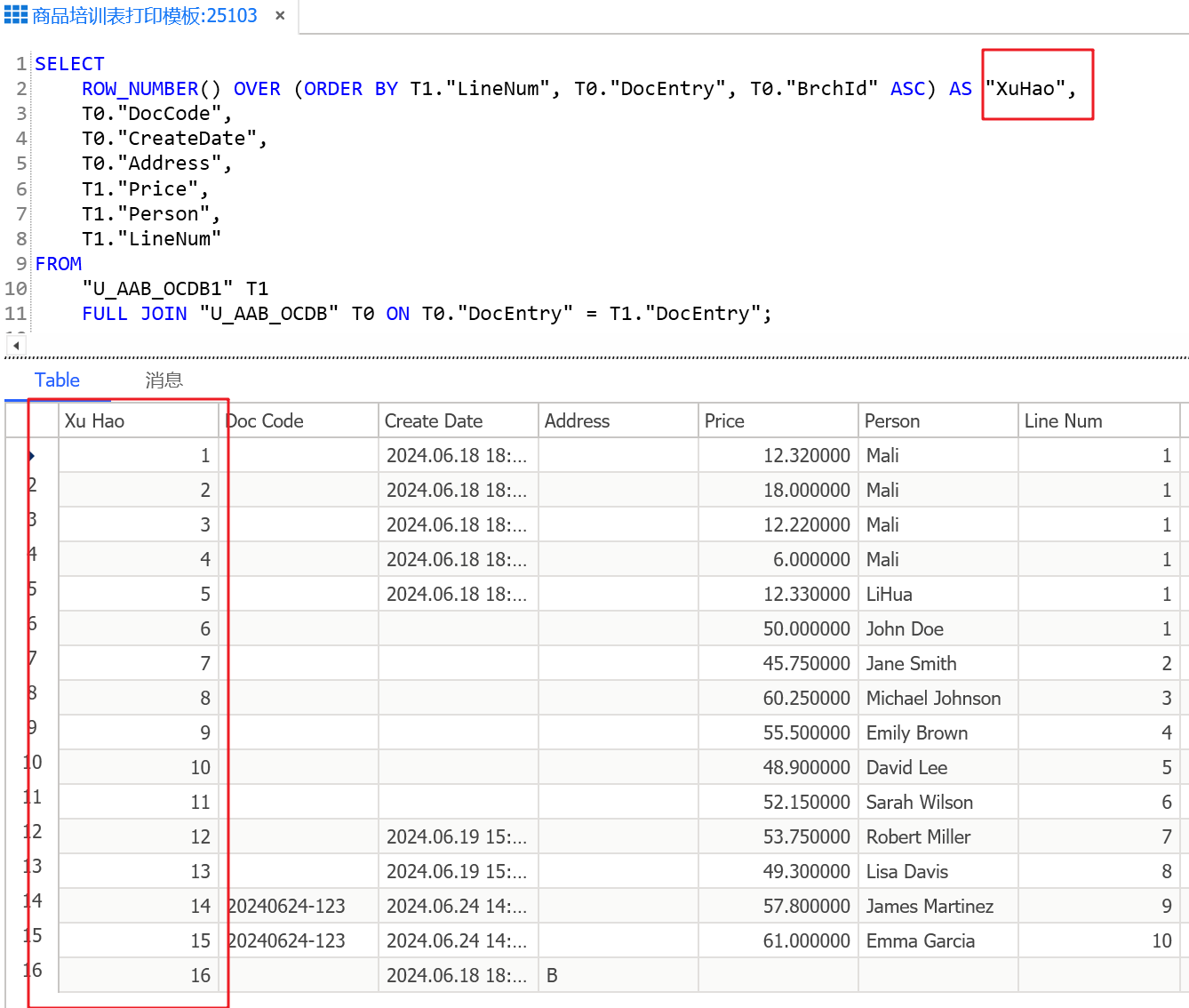
ROW_NUMBER() OVER (ORDER BY T1."LineNum", T0."DocEntry", T0."BrchId" ASC) AS "LineNum",
例如:
SELECT
ROW_NUMBER() OVER (ORDER BY T1."LineNum", T0."DocEntry", T0."BrchId" ASC) AS "LineNum",
T0."DocCode",
T0."CreateDate",
T0."Address",
T1."Price",
T1."Person",
T1."LineNum"
FROM
"U_AAB_OCDB1" T1
FULL JOIN "U_AAB_OCDB" T0 ON T0."DocEntry" = T1."DocEntry";
这段 SQL 代码使用了窗口函数
ROW_NUMBER(),并通过OVER子句定义了其作用范围和排序规则。让我来解释:
- ROW_NUMBER(): 这是一种窗口函数,用于为结果集中的每一行分配一个唯一的序号(行号),序号的分配是基于指定的排序顺序。
- OVER (ORDER BY …): 这个子句定义了
ROW_NUMBER()函数的操作范围。具体来说:
ORDER BY T1."TransType", T0."DocEntry", T0."LineNum":这部分指定了排序的顺序。首先按照T2."TransType"字段升序排列,然后按照T0."DocEntry"字段升序排列,最后按照T0."LineNum"字段升序排列。- AS “LineNum”: 这部分为通过
ROW_NUMBER()生成的行号(序号)指定了一个别名 “LineNum”。在查询的结果中,可以使用"LineNum"这个别名来引用这个生成的列。
去重
另一种作用:PARTITION BY “字段名” 。场景:select查出的内容有重复,想按照某字段去重。
ROW_NUMBER() OVER(PARTITION BY T0."DocEntry" ORDER BY T0."CreateDate" ASC) AS rn
WITH RankedPolicies AS (
SELECT
T0."DocEntry",
T0."PolicyName",
T0."CreateDate", -- 项目推送日期
T0."TransType",
ROW_NUMBER() OVER(PARTITION BY T0."DocEntry" ORDER BY T0."CreateDate" ASC) AS rn
FROM
"U_AAB_OZTS" T0
LEFT JOIN "U_AAB_OZTS1" T1 ON T0."DocEntry" = T1."DocEntry"
LEFT JOIN "U_AAB_OZTS2" T2 ON T1."DocEntry" = T2."DocEntry"
WHERE
(T0."PolicyName" LIKE '%' || @PolicyName || '%' OR @PolicyName IS NULL)
AND (T0."CreateDate" >= @CreateDate OR @CreateDate IS NULL)
)
SELECT
"DocEntry",
"PolicyName",
"CreateDate",
"TransType"
FROM
RankedPolicies
WHERE
rn = 1
ORDER BY
"CreateDate" ASC;
WITH RankedPolicies AS (...):定义一个临时表RankedPolicies,其中包含从表U_AAB_OZTS、U_AAB_OZTS1和U_AAB_OZTS2中检索的数据。ROW_NUMBER() OVER(PARTITION BY T0."DocEntry" ORDER BY T0."CreateDate" ASC) AS rn:使用窗口函数ROW_NUMBER(),按照T0."DocEntry"分区,并按T0."CreateDate"升序排序,为每个分区内的行分配一个序号。这个序号被命名为rn。- 从临时表
RankedPolicies中选择数据,条件是rn = 1,即选择每个T0."DocEntry"分区中CreateDate最早的记录。
WITH语句
WITH Temp_test AS ( -- 创建临时表,保存结果集
SELECT 1 "code", '成功' "mes"
)
SELECT
*
FROM
Temp_test -- 查询临时表
排名窗口函数

聚合窗口函数
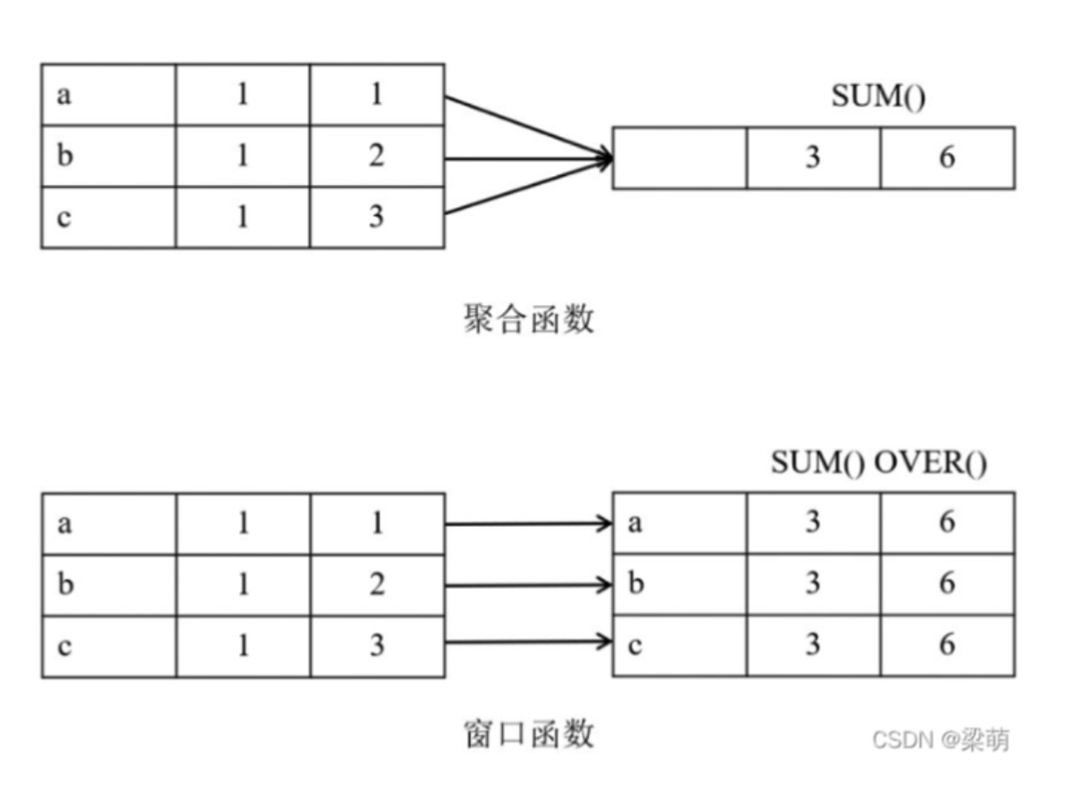
取值窗口函数

$自动计算
1 编码连续(推荐)
注意修改 from表名 和 insert语句的 字段名。
目标字段必须是字符型,因此不能是DocEntry(数值),可以是DocCode(字符)。
DO
$$
DECLARE CODE VARCHAR ( 50 );
BEGIN
CODE :=(
SELECT 'C'|| COALESCE
((
SELECT RIGHT
( '000000' || CAST( CAST( MAX( RIGHT ( "CardCode", 6 )) AS INT )+ 1 AS VARCHAR ( 50 )), 6 )
FROM
"U_AAB_OCRD"
WHERE
length( "CardCode" )= 7),'000001'
));
INSERT INTO "Temp_Result" SELECT
'cardcode',CODE;
END
$$;
--select 1
DO $$
DECLARE code VARCHAR(50);
BEGIN
code:=(SELECT 'S'|| coalesce((select RIGHT('000000'||CAST(CAST(MAX(RIGHT("StuEntry",6)) AS INT)+1 AS VARCHAR(50)),6)
FROM "U_AAB_OXDA" WHERE length("StuEntry")=7),'000001'));
INSERT INTO "Temp_Result"
SELECT 'StuEntry',CODE;
END $$;
--select 1
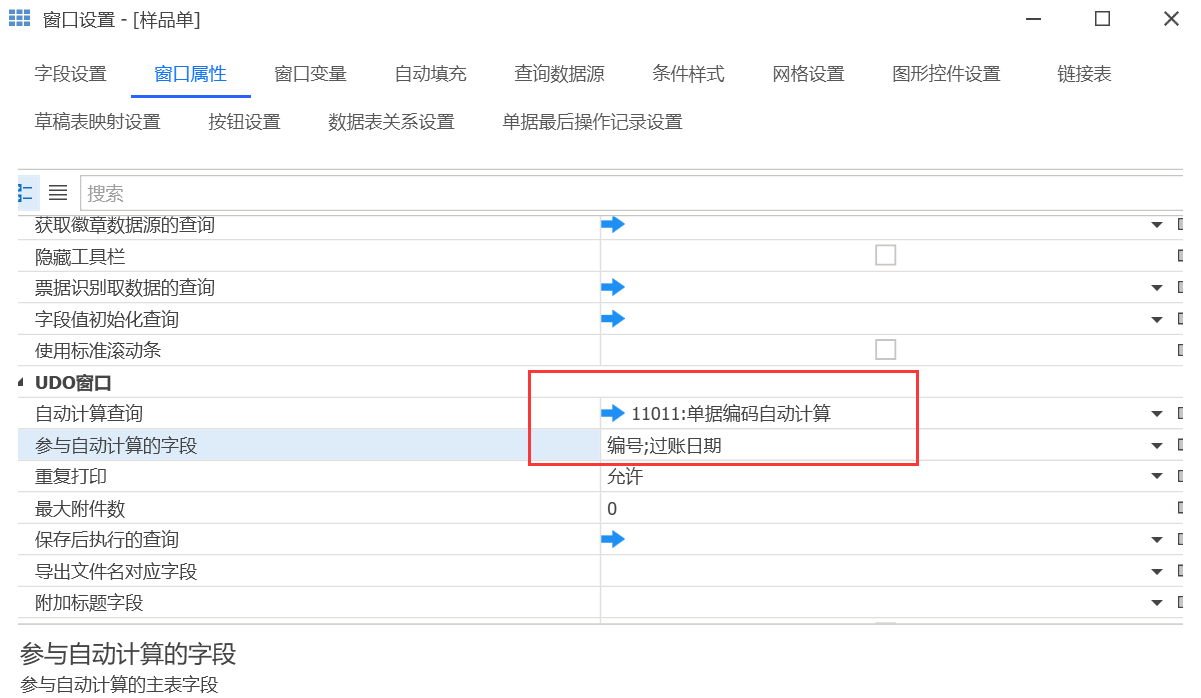
在单据窗口配置中,挂上已保存好的查询及在【参与计算的字段】勾选【过账日期】【单据编号】,如下图:
RIGHT() 函数
在 SQL 中,RIGHT() 函数用于返回一个字符串的右边指定数量的字符。其基本语法如下:
RIGHT(string, length)
string:要从右侧提取字符的源字符串。length:要返回的字符数,即从右边开始的字符数量。
示例用法:
假设有一个字符串 'Hello, World!',我们可以使用 RIGHT() 函数从右侧提取指定数量的字符。
-
基本用法:
SELECT RIGHT('Hello, World!', 6);结果为
'World!',因为从右侧开始取出了后面的 6 个字符。 -
与子查询结合使用:
SELECT RIGHT(column_name, 5) FROM table_name;这里的
column_name是表中的某个列名,table_name是表名。这样可以从表中的特定列中的每个字符串右侧提取指定数量的字符。
注意事项:
- 如果
length参数大于源字符串的长度,则RIGHT()函数返回整个字符串。 - 如果
length参数为 0 或者负数,则返回空字符串。 RIGHT()函数在不同的数据库系统中可能具有略微不同的实现或语法,因此在具体使用时需要参考对应数据库的文档。
这是一个简单但非常有用的字符串函数,特别是在处理需要截取字符串右侧一部分的情况下。
CAST()函数
在 SQL 中,CAST() 是一种用于数据类型转换的函数。它用于将一个表达式或者列的值转换为指定的数据类型。CAST() 函数的基本语法如下:
CAST(expression AS data_type)
expression:要转换的表达式或列名。data_type:目标数据类型,可以是 SQL 支持的任何有效数据类型,如VARCHAR,INTEGER,DATE,TIMESTAMP等。
示例用法:
-
将字符串转换为整数:
SELECT CAST('123' AS INTEGER);这将字符串
'123'转换为整数类型,结果为123。 -
将日期转换为字符串:
SELECT CAST(CURRENT_DATE AS VARCHAR);这将当前日期转换为字符串类型,例如
'2024-06-28'。 -
转换列的数据类型:
SELECT CAST(column_name AS DATE) FROM table_name;这里的
column_name是表中的某个列名,table_name是表名。这将该列中的每个值都转换为日期类型。
注意事项:
CAST()是标准 SQL 的一部分,因此在大多数支持 SQL 标准的数据库系统中都能使用。- 数据类型转换可能导致数据丢失或截断,例如将浮点数转换为整数会丢失小数部分。
- 某些数据库系统也提供了其他形式的类型转换函数,如 PostgreSQL 中的
::操作符或 MySQL 中的CONVERT()函数,它们与CAST()类似但语法稍有不同。
总结来说,CAST() 函数是 SQL 中用于执行数据类型转换的一种标准方法,非常有用于处理数据类型不匹配或需要进行数据类型转换的情况。
LENGTH() 函数
这段 SQL 表达式看起来是用来生成一个值,它使用了 LENGTH() 函数和一个条件表达式。
让我们逐步解释这段 SQL 表达式:
LENGTH("CardCode") = 7:LENGTH("CardCode")表示对字符串"CardCode"计算长度。= 7是一个条件,表示长度等于 7。
LENGTH("CardCode") = 7是一个布尔表达式,如果"CardCode"的长度确实等于 7,则该表达式的值为真(true),否则为假(false)。- 整个表达式的结构似乎是在某种条件下进行字符串值的选择或生成。如果
LENGTH("CardCode") = 7为真,则整个表达式的结果为'000001'。
综合起来,这段 SQL 表达式的作用可能是:当 "CardCode" 的长度为 7 时,返回 '000001' 这个固定的字符串值。如果 "CardCode" 的长度不是 7,则表达式可能会返回其他值,或者在实际 SQL 查询中,可能会与其他逻辑结合使用。
2 随意编码
1 定义
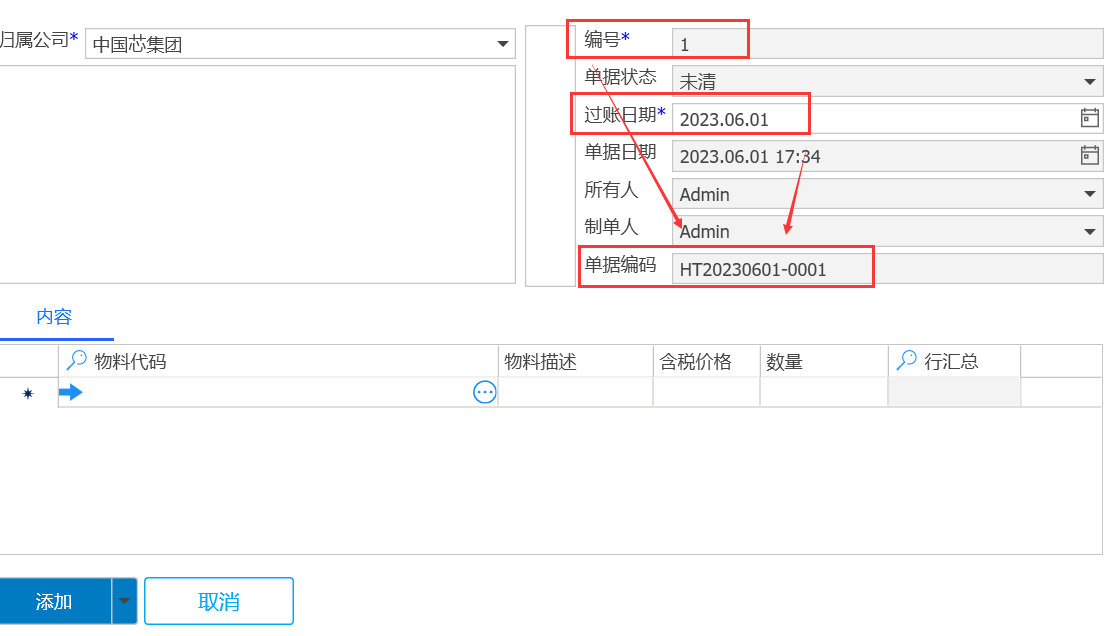
在添加单据时,可以按照用户要求的规则自动生成一个值赋予单据上的某个字段中,例如销售合同编号,格式为:HT20230601-0001,规则是年(2023)+月(06)+日(01)+流水号(0001)。
2 实现步骤
- 定义自动计算查询SQL,保存到系统相应路径下。
- CURRENT_DATE表示当前日期。可将TO_CHAR () 函数中的"DocDate"字段替换,具体TO_CHAR () 函数请搜索 格式化日期。
DO $$
DECLARE docnum varchar(100);
BEGIN
docnum:=(SELECT 'HT'||to_char("DocDate",'yyyymmdd')||'-'
||RIGHT('0000'||"DocEntry"::VARCHAR(50),4) FROM "Temp_Master");
INSERT INTO "Temp_Result"
SELECT 'DocNum',docnum; -- DocNum(目标字段名)
END $$;
SELECT TO_CHAR(FLOOR(RANDOM() * 101), 'FM000') AS random_number; -- 数字应该是三位数,不足的部分用零填充,FM000 是一种格式化字符串,用于指定数字的输出格式。
说明:
‘DocNum’(’目标字段名’):是指要填充编号值的单据上的主表字段名。
docnum(计算编号的结果):是指计算出来的编号,这里一般会用到字符串运算,其结果是字符串。
Temp_Master: 界面参与计算的字段所组成的临时表,注意,它是指单据的主表。
Temp_Result: 返回的结果集。
2.在单据窗口配置中,挂上已保存好的查询及在【参与计算的字段】勾选【过账日期】【单据编号】,如下图:
**注意:**如果不勾选“参与计算的字段”,自动计算查询将无法引用相关字段的值。
- 单据自动计算字段最终的效果如下图:
3 每天重新编码
入职考试题3:考试第17题:
消费记录自定义编号自动生成,规则CS+制单日期年月(201908)+0001 (CS2019080001)
**注意:**需要每天重新编码;
DO
$$
DECLARE
docnum VARCHAR(100);
BEGIN
-- 假设 CreateDate 和 DocEntry 是用于生成 docnum 的关键字段
-- 这里假设 CreateDate 是日期类型,DocEntry 是整数类型
-- 我们先找到最新的 CreateDate 和最大的 DocEntry
WITH RankedEntries AS (
SELECT
"CreateDate",
"DocEntry",
ROW_NUMBER() OVER (ORDER BY "CreateDate" DESC, "DocEntry" DESC) AS rn
FROM "Temp_Master"
)
SELECT
INTO docnum
'CS' || TO_CHAR(MAX("CreateDate"), 'yyyymm')
|| RIGHT('0000' || CAST(MAX("DocEntry") AS VARCHAR(50)), 4)
FROM RankedEntries
WHERE rn = 1; -- 只取排名第一的记录
-- 现在将 docnum 插入到 Temp_Result 表中
INSERT INTO "Temp_Result"
SELECT 'OwnDefineEntry',docnum; -- DocNum(目标字段名)
END
$$
;
下面是每天从0001开始。
DECLARE
docnum VARCHAR(100);
BEGIN
-- 假设 CreateDate 和 DocEntry 是用于生成 docnum 的关键字段
-- 这里假设 CreateDate 是日期类型,DocEntry 是整数类型
-- 我们先找到最新的 CreateDate
WITH RankedEntries AS (
SELECT
"CreateDate",
"DocEntry",
ROW_NUMBER() OVER (ORDER BY "CreateDate" DESC, "DocEntry" DESC) AS rn
FROM "Temp_Master"
)
SELECT
INTO docnum
'CS' || TO_CHAR(MAX("CreateDate"), 'yyyymm')
|| RIGHT('000' || CAST((ROW_NUMBER() OVER (ORDER BY "CreateDate" DESC, "DocEntry" DESC) - 1) AS VARCHAR(50)), 3)
FROM RankedEntries
WHERE rn = 1; -- 只取排名第一的记录
-- 现在将 docnum 插入到 Temp_Result 表中
INSERT INTO "Temp_Result"
SELECT 'OwnDefineEntry',docnum; -- DocNum(目标字段名)
END;
$LPAD补位函数
LPAD 是一个用于字符串处理的函数,常见于许多数据库系统,包括 PostgreSQL 和 Oracle 等。其功能是将给定的字符串填充至指定的长度,如果字符串的长度不够,会在字符串的左侧填充指定的字符(通常是 0 或空格)。
LPAD 函数的语法
LPAD(string, length, pad_string)
string:要进行填充的原始字符串。length:填充后字符串的总长度。pad_string:用来填充的字符,默认为空格。
示例
假设你有一个数字 5,并且希望将其填充为 4 位,结果为 0005,可以使用 LPAD 来实现:
SELECT LPAD('5', 4, '0');
结果:
0005
这里,'5' 被填充为 4 位,并且在它的左边补充了 3 个 0,直到总长度为 4。
在你的查询中的使用
你在原始问题中提到希望流水码从 0001 开始并逐步递增,因此可以使用 LPAD 来确保流水号始终是 4 位数字,即使序列号增加时,长度也不会变短。例如,使用如下代码:
LPAD(NEXTVAL('seq_flow_code')::TEXT, 4, '0')
这里,NEXTVAL('seq_flow_code') 返回一个数字,::TEXT 将其转换为字符串,LPAD(..., 4, '0') 则确保字符串的总长度是 4,并且用 0 来填充不足的部分。
其他例子:
-
将数字
7填充为 5 位,使用0填充:SELECT LPAD('7', 5, '0');结果:
00007 -
将文本
'AB'填充为 6 位,使用*填充:SELECT LPAD('AB', 6, '*');结果:
****AB
总结
LPAD 是一个非常有用的函数,特别适用于需要固定长度字符串的场景,如生成格式化的流水号、编号等。
$Trim() 函数去空格
在 PostgreSQL 中,可以使用 TRIM() 函数来去掉字符串的开头和结尾的空格(包括换行符、制表符等空白字符)。具体用法如下:
去掉开头和结尾的空格
SELECT TRIM(' hello ') AS trimmed_text;
这会返回 hello,去掉了字符串开头和结尾的空格。
去掉开头的空格sql
如果只需要去掉字符串开头的空格,可以使用 LTRIM() 函数:
SELECT LTRIM(' hello ') AS left_trimmed_text;
这会返回 hello ,只去掉了字符串开头的空格。
去掉结尾的空格
如果只需要去掉字符串结尾的空格,可以使用 RTRIM() 函数:
SELECT RTRIM(' hello ') AS right_trimmed_text;
这会返回 hello,只去掉了字符串结尾的空格。
处理列中的空格
如果需要处理表中某列中的空格,可以直接在 UPDATE 或者 SELECT 语句中使用 TRIM() 函数。例如:
UPDATE table_name
SET column_name = TRIM(column_name);
或者
SELECT TRIM(column_name) AS trimmed_column
FROM table_name;
这些操作可以有效地去掉字符串中不需要的空格。
中间的空格或其他字符
处理字符串中间的空格或其他字符,可以使用 PostgreSQL 中的正则表达式函数来替换或移除特定的字符。以下是一些常用的函数和方法:
- 使用
REGEXP_REPLACE()函数
REGEXP_REPLACE() 函数可以根据正则表达式替换字符串中的部分内容。例如,假设你想要移除所有空格,包括字符串中间的空格:
SELECT REGEXP_REPLACE('你 好 啊', '\s+', '', 'g');
这将返回 “你好啊”,将所有空格移除。
\s+是一个正则表达式模式,匹配一个或多个空白字符(包括空格、制表符、换行符等)。''是替换为空的字符串,即移除匹配到的内容。'g'表示全局匹配,确保所有匹配的部分都被替换。
- 使用
TRANSLATE()函数
TRANSLATE() 函数可以将一个字符集中的字符替换为另一个字符集中的字符。这对于简单的替换非常有用。例如,将空格替换为空:
SELECT TRANSLATE('你 好 啊', ' ', ''); -- 被处理字符串,'被替换内容','替换内容'
这将返回 “你好啊”,将所有空格移除。
- 手动处理字符串
如果需要更复杂的逻辑或多步处理,可以使用 PostgreSQL 的字符串函数和运算符来实现。例如,结合 POSITION() 函数和 SUBSTRING() 函数来找到和移除特定位置的字符。
例子:
假设你有一个字符串 “你 好 啊”,想要移除中间的空格,只保留开头和结尾的空格。你可以使用如下方法:
SELECT TRIM(BOTH ' ' FROM REGEXP_REPLACE('你 好 啊', '(^\s+|\s+$)', ''));
REGEXP_REPLACE('你 好 啊', '(^\s+|\s+$)', '')使用正则表达式移除开头和结尾的空格,但保留中间的空格。TRIM(BOTH ' ' FROM ...)去除结果中开头和结尾的空格。
这将返回 “你 好 啊”,只移除了开头和结尾的空格,中间的空格保留。
通过这些方法,你可以根据具体的需求来处理字符串中间的空格或其他字符。
$内置函数进行加密
如果你使用 PostgreSQL(通常简称为 pgsql),你可以利用 PostgreSQL 提供的内置函数或者通过数据库客户端应用程序来实现对公司名称的加密,并将加密结果作为唯一标识的公司编号。
使用 PostgreSQL 内置函数进行加密
PostgreSQL 提供了多种加密相关的函数,你可以选择适合你需求的加密方法。以下是一些常见的方法:
MD5 加密:
PostgreSQL 提供了
md5函数,可以对输入进行 MD5 加密。SELECT md5('明日科技有限公司');这将返回一个 32 位的十六进制字符串,作为公司的加密后编号。
SHA-256 加密:
如果需要更安全的加密算法,可以使用
pgcrypto扩展中的digest函数。首先确保pgcrypto扩展已经被正确安装和启用。CREATE EXTENSION IF NOT EXISTS pgcrypto; SELECT encode(digest('明日科技有限公司', 'sha256'), 'hex');这会返回一个 SHA-256 加密的十六进制字符串作为公司的唯一标识。
存储加密后的公司编号
无论你选择哪种加密方法,都可以将加密后的结果作为公司的唯一标识存储在 PostgreSQL 数据库中的相应表格中。
CREATE TABLE companies ( company_id TEXT PRIMARY KEY, company_name TEXT ); INSERT INTO companies (company_id, company_name) VALUES (md5('明日科技有限公司'), '明日科技有限公司');在这个例子中,
company_id列用于存储加密后的公司编号,company_name列则存储原始的公司名称。注意事项
- 数据安全性: 加密后的结果通常是不可逆的,这意味着不能从加密后的编号恢复出原始的公司名称。因此,确保在需要时能够准确匹配和处理加密后的标识。
- 加密算法的选择: 根据安全性需求选择合适的加密算法。MD5 虽然简单,但不如 SHA-256 等更安全的算法。如果安全性对你很重要,建议使用更强的算法。
通过以上方法,你可以在 PostgreSQL 中实现对公司名称的加密,并将加密结果作为唯一标识的公司编号,以满足你的需求。
$自定义函数
在系统中函数的参数可以在括号里指定,不需要在上方添加参数。
-- 创建 加法函数
CREATE OR REPLACE FUNCTION testfun ( parm1 INTEGER, parm2 INTEGER )
RETURNS INTEGER
LANGUAGE plpgsql
AS $$
DECLAREfun_sum INTEGER; -- 声明变量
BEGIN
fun_sum := parm1 + parm2;
RETURN fun_sum;
END; $$;
-- 调用函数
SELECT
testfun ( 1, 2 )
基本语法
CREATE [ OR REPLACE ] FUNCTION function_name ( [ parameter_name parameter_type [, ...] ] )
RETURNS return_type
LANGUAGE plpgsql -- 或其他支持的语言(如 SQL、Python 等)
AS $$
DECLARE
-- 可选的变量声明
BEGIN
-- 函数体:包含 SQL 语句、控制结构(IF、FOR 循环等)等
END $$;
CREATE FUNCTION: 创建一个新函数或替换现有的同名函数(使用OR REPLACE)。function_name: 函数名,用于在调用时标识和执行函数。parameter_name parameter_type: 函数的输入参数,可以有多个参数,每个参数由名称和类型定义。RETURNS return_type: 函数返回的数据类型。LANGUAGE: 指定函数使用的编程语言,常见的是plpgsql(PostgreSQL 的内置过程化语言)、sql(仅包含 SQL 语句的函数)、plpythonu(Python 函数,需安装插件支持)等。AS $$ ... $$: 函数体的开始和结束标记,$$之间是函数的实际代码部分。
表变量
在 PostgreSQL 中,如果你希望创建一个函数,接受多个表作为参数并返回一个表,你可以使用 TABLE 类型来定义返回值。你可以定义一个复合类型,或直接返回一个表的查询结果。
下面是一个示例,展示如何接受三个表作为参数,并返回一个结果表:
示例
假设你有三个表 table1、table2 和 table3,每个表都有一个 value 列。你希望通过一个函数将这些表中的值合并到一个结果表中。
首先,你需要创建一个复合类型来定义返回的表结构:
-- 创建复合类型
CREATE TYPE result_type AS (
value INTEGER
);
然后,创建函数以接受表作为参数并返回结果表:
-- 创建函数
CREATE OR REPLACE FUNCTION testfun(
param1 TABLE(value INTEGER),
param2 TABLE(value INTEGER),
param3 TABLE(value INTEGER)
)
RETURNS TABLE(value INTEGER)
LANGUAGE plpgsql
AS $$
BEGIN
RETURN QUERY
SELECT value FROM param1
UNION ALL
SELECT value FROM param2
UNION ALL
SELECT value FROM param3;
END;
$$;
调用函数
你可以通过以下方式调用这个函数:
SELECT * FROM testfun((SELECT value FROM table1), (SELECT value FROM table2), (SELECT value FROM table3));
注意事项
- 输入参数:在 PostgreSQL 中,不能直接将表作为参数传递。通常使用
TABLE来定义输入类型,但实际上你可能需要通过其他方式处理(如使用临时表或数组)。 - 返回类型:函数返回值使用
RETURNS TABLE来定义返回表的结构。
表变量示例
1、创建函数
-- 创建 加法函数
CREATE OR REPLACE FUNCTION testfun ( param1 INTEGER )
RETURNS TABLE(docentry INTEGER,transtype varchar(20))
LANGUAGE plpgsql
AS $$
--DECLAREfun_res INTEGER; -- 声明变量
BEGIN
RETURN QUERY
select "DocEntry","TransType" from "T_OPOR" where "DocEntry"=param1;
END; $$;
-- 调用函数
/*SELECT
testfun ( 1)*/
-- DROP FUNCTION testfun(INTEGER);
2、调用函数
select * from testfun(2)
高阶一点:
传参时候来自多个表。
-- 创建 加法函数
CREATE OR REPLACE FUNCTION testfun ( param1 INTEGER,param2 INTEGER )
RETURNS TABLE(docentry INTEGER,transtype varchar(20))
LANGUAGE plpgsql
AS $$
--DECLAREfun_res INTEGER; -- 声明变量
BEGIN
RETURN QUERY
select "DocEntry","TransType" from "T_OPOR" where "DocEntry" in (param1,param2);
END; $$;
-- 调用函数
/*SELECT
testfun ( 1)*/
-- DROP FUNCTION testfun(INTEGER,integer);
select * from testfun((select 1),(select 2))
$创建存储过程
在 PostgreSQL 中,编写一个存储过程(Stored Procedure)以执行查询并返回结果,你需要使用 PL/pgSQL 语言,这是 PostgreSQL 的过程语言。然而,需要注意的是,传统的存储过程(如在某些其他数据库系统中)通常不直接返回查询结果给调用者,而是执行操作(如更新、插入、删除等)并可能通过 OUT 参数或返回值来传递状态信息。
基本语法
CREATE [ OR REPLACE ] PROCEDURE procedure_name ( [ parameter_list ] )
[ RETURNS return_type ] -- 可选,指定返回类型
LANGUAGE plpgsql -- 或其他支持的语言
AS $$
DECLARE
-- 可选的变量声明
BEGIN
-- 存储过程体:包含 SQL 语句、控制结构(IF、FOR 循环等)等
END $$;
CREATE PROCEDURE: 创建一个新的存储过程或替换现有的同名存储过程(使用OR REPLACE)。- OR REPLACE: 如果指定的对象已经存在,则替换它。这意味着如果同名的存储过程已经存在,那么将使用新定义的存储过程体来替换旧的定义。
procedure_name: 存储过程的名称,用于在调用时标识和执行存储过程。parameter_list: 可选的输入参数列表,每个参数包括名称和类型。RETURNS return_type: 可选的返回类型声明,如果存储过程需要返回结果,则指定返回类型。LANGUAGE: 指定存储过程使用的编程语言,常用的是plpgsql,还可以是sql(仅包含 SQL 语句的存储过程)或其他支持的语言。AS $$ ... $$: 存储过程体的开始和结束标记,$$之间是实际的存储过程代码部分。
示例
1. 简单的存储过程
CREATE OR REPLACE PROCEDURE update_employee_salary()
LANGUAGE plpgsql
AS
$$
BEGIN
-- 假设我们要将所有员工的薪水增加 10%
UPDATE employees SET salary = salary * 1.1;
-- 这里可以添加更多的 SQL 语句
END;
$$
;
这个存储过程名为 update_employee_salary,不接受任何参数,每次调用该存储过程执行一次其中的update语句。
2. 带参数的存储过程
CREATE OR REPLACE PROCEDURE update_employee_salary_by_id(emp_id INT, new_salary NUMERIC)
LANGUAGE plpgsql
AS
$$
BEGIN
-- 更新指定员工的薪水
UPDATE employees SET salary = new_salary WHERE id = emp_id;
-- 这里可以添加错误处理或检查逻辑
END;
$$
;
这个存储过程名为 update_employee_salary_by_id,接受两个数值类型的参数 emp_id 和 new_salary,根据id更新字段。
调用存储过程
调用存储过程与调用函数类似,使用 CALL 关键字:
-- 调用存储过程 update_employee_salary
CALL update_employee_salary();
-- 调用存储过程 update_employee_salary_by_id
CALL update_employee_salary_by_id(1, 50000);
在 PostgreSQL 中,存储过程与函数一样,可以包含复杂的逻辑、变量声明、条件控制等,使得数据库应用能够更加灵活和高效地进行数据处理和业务逻辑实现。
$创建临时表
CREATE TEMP TABLE TP0 ON COMMIT DROP AS SELECT
'OK' "Code",
'修改成功' "Message";
CREATE TEMP TABLE TP0: 这部分指示要创建一个临时表,并且表名为TP0。临时表在会话结束时会自动销毁,或者在当前事务结束时(如果使用了事务)会被删除。
ON COMMIT DROP: 这是 PostgreSQL 中的一个选项,在CREATE TEMP TABLE语句中使用。它指示当事务提交时自动删除这个临时表。换句话说,一旦当前事务结束并且提交成功,临时表TP0就会被清除。
AS: 这是CREATE TABLE AS的一部分,表示接下来是一个查询语句,它将查询的结果作为新表TP0的内容。
SELECT 'OK' "Code", '修改成功' "Message";: 这是实际的查询语句,它选取了一个结果集并将其插入到临时表TP0中。具体来说:
'OK' "Code"是一个列名为Code的常量值'OK'。'修改成功' "Message"是一个列名为Message的常量值'修改成功'。因此,这个查询语句将会在临时表
TP0中创建一行,该行有两列:Code和Message,分别包含'OK'和'修改成功'。总结:整条 SQL 查询的作用是在 PostgreSQL 中创建一个临时表
TP0,并向其插入一行数据'OK'和'修改成功'。这个临时表在当前事务结束并且成功提交后会自动删除。
/*
在界面点击录入快递单号时触发,返回Code和Msg字段
Code字段的值:0 通过、1 - 不允许、2 - 弹出对话框确认
Msg的值:Code 为1时为错误描述、Code为2时为对话框内容
*/
CREATE TEMP TABLE temp_result
(
"Code" INTEGER,/*标记值,0表示成功、1表示错误、2表示需要弹框选择*/
"Msg" CHARACTER VARYING(200)/*消息文本,根据Code值来使用,Code = 0时不需要、Code = 1时为错误描述、Code = 2时为弹框内容*/
) ON COMMIT DROP;
/*逻辑处理 开始*/
/*逻辑处理 结束*/
SELECT * FROM temp_result;
DROP TABLE temp_result;
mysql写法
CREATE TEMPORARY TABLE res
SELECT * FROM person;
-- SELECT * FROM res WHERE age>19 ;
CREATE TEMPORARY TABLE res1
SELECT * FROM res;
SELECT * FROM res1 WHERE age>19;
DROP TEMPORARY TABLE IF EXISTS res;
DROP TEMPORARY TABLE IF EXISTS res1;
$Between and
在 PostgreSQL 中,BETWEEN 和 AND 条件用于指定一个范围。这个范围包含指定的起始值和结束值。具体来说:
- 如果你使用
x BETWEEN low AND high,那么这个条件会匹配x在low和high之间的所有值,包括low和high的值本身。
x BETWEEN low AND high
$ in 和 any
在 PostgreSQL 中,ANY 和 IN 都用于比较值集合,但它们的用法和语义有一些区别。
IN
-
用途:
IN用于检查某个值是否在指定的列表或子查询结果中。 -
语法:
value IN (value1, value2, value3)或者使用子查询:
value IN (SELECT column FROM table WHERE condition) -
示例:
SELECT * FROM employees WHERE department_id IN (1, 2, 3);
ANY
==注意:==any (数组)。
-
用途:
ANY用于比较一个值与一组值(通常是子查询的结果),并检查该值是否与集合中的任何一个值匹配。 -
语法:
value operator ANY (array | subquery)operator可以是=,<,>,<=,>=,<>等。
-
示例:
SELECT * FROM employees WHERE salary > ANY (SELECT salary FROM employees WHERE department_id = 1);
主要区别
- 语法和使用场景:
IN主要用于匹配一个值是否在给定列表中。ANY用于与运算符结合,比较一个值与集合中任意一个值的关系。
- 比较逻辑:
IN检查是否完全匹配。ANY根据运算符的不同,检查是否满足某种条件。
示例对比
-
使用
IN:SELECT * FROM products WHERE category_id IN (1, 2, 3); -
使用
ANY:SELECT * FROM products WHERE price < ANY (SELECT price FROM products WHERE category_id = 1);
总结来说,选择 IN 还是 ANY 取决于你想要实现的比较逻辑。如果只是简单的匹配,IN 更加直观;如果需要进行更复杂的比较,ANY 则更为灵活。
$ Select 中的子查询
select
T0."ApplyTel",
T1."ExpenseName" ,
T1."ExpenseMoney",
(SELECT "Name" FROM "U_AAB_OFLX" WHERE "Code" = T1."ExpenseType"::INT) AS "ExpenseType"
from "U_AAB_OFSQ" T0
INNER JOIN "U_AAB_OFSQ1" T1 ON T1."DocEntry" = T0."DocEntry"
$DISTINCT ON去重
DISTINCT ON 是 PostgreSQL 中特有的用法,用于从结果集中选择唯一的记录。它与普通的 DISTINCT 有所不同,因为它允许你指定一组列,在这组列的值相同的情况下,只返回第一条记录。
使用方法:
-
语法结构:
SELECT DISTINCT ON (expression_list) expression_list, column_list FROM tables WHERE conditions ORDER BY expression_list, column_list;expression_list:是一个或多个列或表达式,用来确定唯一性。column_list:是要查询的实际列名。tables:是要查询的表。conditions:可选的筛选条件。ORDER BY:必须包含在DISTINCT ON查询中,用来指定哪些列用于唯一化以及记录的排序方式。
-
工作原理:
DISTINCT ON根据ORDER BY子句指定的列排序记录,并根据DISTINCT ON子句中指定的列或表达式的唯一性来选择记录。在排序后,对于每组具有相同DISTINCT ON列值的记录,只会返回第一条记录。
-
示例说明:
假设有一个表
students包含学生的姓名、班级和分数。要找出每个班级中分数最高的学生,可以使用DISTINCT ON:SELECT DISTINCT ON (class) class, student_name, score FROM students ORDER BY class, score DESC;- 这个查询按班级和分数降序排序学生记录,然后对每个班级应用
DISTINCT ON (class),以便只返回每个班级中分数最高的学生记录。
- 这个查询按班级和分数降序排序学生记录,然后对每个班级应用
-
注意事项:
DISTINCT ON要求ORDER BY子句中指定的列与DISTINCT ON子句中的列或表达式相同,以确保结果的一致性和预期行为。- 如果你只想简单地去重所有列,应该使用
DISTINCT而不是DISTINCT ON。
-
常见错误:
- 如果
ORDER BY子句没有正确指定,或者没有在DISTINCT ON子句中使用相同的列或表达式,可能会导致意外的结果或错误。
- 如果
通过理解和正确使用 DISTINCT ON,可以更精确地控制结果集,适用于需要按特定条件选择唯一记录的复杂查询场景。
@字符部分
1. 字符串连接
||:字符串拼接运算符。
SELECT 'Hello, ' || 'World!' AS greeting; -- Output: 'Hello, World!'
2. 字符串长度
length(string):返回字符串的长度。
SELECT length('Hello') AS len; -- Output: 5
3. 提取子字符串
substring(string, start, length):提取子字符串。
SELECT substring('Hello, World!' FROM 1 FOR 5) AS part; -- Output: 'Hello'
left(string, length):从左侧提取字符。
SELECT left('Hello, World!', 5) AS left_part; -- Output: 'Hello'
right(string, length):从右侧提取字符。
SELECT right('Hello, World!', 6) AS right_part; -- Output: 'World!'
4. 字符串替换
replace(string, from_substring, to_substring):替换字符串中的子字符串。
SELECT replace('Hello, World!', 'World', 'PostgreSQL') AS new_string; -- Output: 'Hello, PostgreSQL!'
5. 字符串查找
position(substring IN string):查找子字符串在字符串中的位置。
SELECT position('World' IN 'Hello, World!') AS pos; -- Output: 8
6. 字符串分割
string_to_array(string, delimiter):将字符串分割为数组。
SELECT string_to_array('a,b,c', ',') AS arr; -- Output: {'a','b','c'}
7. 字符串聚合
string_agg(expression, delimiter):将多个行的字符串合并为一个字符串。
SELECT string_agg(name, ', ') FROM users; -- 合并用户名称
8. 大小写转换
upper(string):将字符串转换为大写。
SELECT upper('Hello') AS upper_case; -- Output: 'HELLO'
lower(string):将字符串转换为小写。
SELECT lower('Hello') AS lower_case; -- Output: 'hello'
initcap(string):将字符串的每个单词首字母转换为大写。
SELECT initcap('hello world') AS title_case; -- Output: 'Hello World'
9. 去除空格(部分/所有)
trim([leading|trailing|both] string):去除字符串两端的空格。
SELECT trim(both ' ' FROM ' Hello ') AS trimmed; -- Output: 'Hello'
SELECT replace('He llo, Wor ld!', ' ', '') AS new_string; -- Output: 'Hello,World!'
10. 转换为 JSON
to_json 和 jsonb:将字符串转换为 JSON 类型。
11. 其他函数
concat(string1, string2, ...):连接多个字符串。
SELECT concat('Hello', ', ', 'World!') AS greeting; -- Output: 'Hello, World!'
示例:
SELECT (STRING_TO_ARRAY('value1,value2,value3', ','))[1]
SELECT UNNEST(STRING_TO_ARRAY('value1,value2,value3', ','))
$STRING_AGG拼接字符
将所有记录的UserName字段汇总到一条记录中。
将字符串以逗号分隔获取:结合使用 STRING_TO_ARRAY 和 unnest 函数。unnest 函数用于展开数组为多行。
SELECT
STRING_AGG(T0."UserName", ';') AS AllUserNames,
STRING_AGG(T0."Phone", ';') AS AllPhones
FROM "U_AAB_OUSE" T0
WHERE T0."UserCode" IN (
SELECT unnest(STRING_TO_ARRAY(@Recipient, ','))
);
$STRING_TO_ARRAY拆分字符串
SELECT STRING_TO_ARRAY('value1,value2,value3', ',')
SELECT
T0."DocEntry",
T0."UserCode",
T0."UserName",
T0."Phone",
T0."MemberType",
T0."CardName"
FROM "U_AAB_OUSE" T0
WHERE T0."UserCode" IN (
SELECT unnest(STRING_TO_ARRAY(@Recipient, ','))
);
$替换指定子串
AND ((REPLACE ( T1."U_ItemName", ' ', '' )) ILIKE ( '%' || REPLACE ( @ItemName, ' ', '' )|| '%' ) OR @ItemName IS NULL)
在 PostgreSQL 中,REPLACE 函数用于替换字符串中的指定子串。它的基本语法如下:
REPLACE(string, from_substring, to_substring)
参数说明
- string: 要进行替换的原始字符串。
- from_substring: 要被替换的子串。
- to_substring: 用于替换的子串。
示例用法
-
基本替换:
假设你有一个表
products,其中有一个字段description,你想将其中的 “old” 替换为 “new”:SELECT REPLACE(description, 'old', 'new') AS updated_description FROM products; -
更新表中的数据:
如果你想直接在表中更新这些值,可以使用以下语句:
UPDATE products SET description = REPLACE(description, 'old', 'new');
注意事项
REPLACE函数会替换字符串中所有出现的from_substring,如果from_substring不存在,原字符串将保持不变。- 该函数是大小写敏感的。
REPLACE 函数非常适合处理文本数据时的批量替换需求。
$截取字符串中最后一个"-"后面的子串
在 PostgreSQL 中,可以使用
substring函数结合正则表达式来截取字符串中最后一个-后面的部分。下面是一个示例 SQL 查询,演示如何实现这一点:SELECT substring(your_column FROM '.*-([^ -]+)$') AS result FROM your_table;在这个查询中,
your_column是你要处理的列,your_table是你的表名。正则表达式.*-([^ -]+)$的含义如下:
.*-:匹配字符串中最后一个-之前的所有字符。([^ -]+)$:捕获最后一个-后面的所有字符,直到字符串结束。示例
假设有以下数据:
CREATE TABLE example (id SERIAL PRIMARY KEY, name TEXT); INSERT INTO example (name) VALUES ('abc-def-ghi'), ('jkl-mno-pqr-stu');可以使用如下查询来获取每个
name字段中最后一个-后的部分:SELECT name, substring(name FROM '.*-([^ -]+)$') AS last_part FROM example;结果
执行上面的查询后,结果会是:
name | last_part ----------------+----------- abc-def-ghi | ghi jkl-mno-pqr-stu| stu这样就可以成功提取出最后一个
-后面的字符串了!
$LIMIT分页
在 PostgreSQL 中,LIMIT 子句用于限制查询结果返回的行数。它通常与 SELECT 语句一起使用。下面是基本的用法和一些示例:
基本语法
SELECT column1, column2
FROM table_name
WHERE condition
LIMIT number;
示例
-
返回前 10 行:
SELECT * FROM employees LIMIT 10; -
结合
ORDER BY使用:SELECT * FROM employees ORDER BY salary DESC LIMIT 5;这个查询将返回薪资最高的 5 位员工。
-
用于分页: 在分页查询中,可以结合
OFFSET来指定从哪一行开始返回数据。SELECT * FROM employees ORDER BY id LIMIT 10 OFFSET 20;这个查询将跳过前 20 行,并返回接下来的 10 行。
注意事项
LIMIT的值必须是一个非负整数。- 如果不使用
ORDER BY,返回的行可能是任意的,因为没有明确的顺序。通过使用
LIMIT,你可以有效地控制查询返回的数据量,适用于处理大数据集时的性能优化。
@数字部分
$ROUND保留小数位数
1.从名为 your_table 的表中选择 Price 列的数据,并且对每个价格值进行四舍五入保留两位小数。
SELECT ROUND("Price", 2) AS rounded_price
FROM your_table;
$CAST类型转换
2.截取小数点后两位而不进行四舍五入,可以使用 TRUNC 函数结合 CAST 进行实现。
SELECT CAST("Price" AS numeric(10, 2)) AS truncated_price
FROM your_table;
这里假设
"Price"是你表中的列名,numeric(10, 2)是类型转换的一种方式,它将"Price"列的每个值转换为保留两位小数的数值类型,同时截取小数点后的值而不是四舍五入。
numeric(10, 2)中的10表示总共的数字长度,包括小数点前后的位数。2表示保留的小数位数。CAST函数在 SQL 中用于将一个数据类型转换为另一个数据类型。在你的例子中,CAST("Price" AS numeric(10, 2))的作用是将Price列的值转换为numeric类型,具体为numeric(10, 2)。这种方法会截取小数点后的值,而不会进行四舍五入。
注意:
要写成:
SELECT
T0."Code",
T0."Name",
CAST(T0."ExpenseMoney" AS numeric(10, 2)) AS "ExpenseMoney"
FROM
"U_AAB_OFYM" T0;
不要写成:下面这样不起效果
SELECT
"Code",
"Name",
CAST("ExpenseMoney" AS numeric(10, 2)) AS "ExpenseMoney"
FROM
"U_AAB_OFYM";
$Random随机数
SELECT TO_CHAR(FLOOR(RANDOM() * 101), 'FM000') AS random_number; -- 数字应该是三位数,不足的部分用零填充,FM000 是一种格式化字符串,用于指定数字的输出格式。
$CEIL天花板函数
向上取整
在 SQL 中,天花板函数通常指的是 CEIL 或 CEILING 函数。这两个函数的作用是返回大于或等于给定数字的最小整数。
SELECT CEIL(column_name) AS ceiling_value
FROM your_table;
$FLOOR地板函数
向下取整
与天花板函数 CEIL 或 CEILING 对应的函数是 地板函数,通常在 SQL 中表示为 FLOOR。地板函数返回小于或等于给定数字的最大整数。
SELECT FLOOR(column_name) AS floor_value
FROM your_table;
$GREATEST最大最小值限制
SELECT GREATEST(4 - 3, 0) AS AdjustedQuantity -- 限制最小为0
在 PostgreSQL(pgsql)中,GREATEST 函数用于返回一组表达式中的最大值。相应地,用于限制最大值的函数是 LEAST。LEAST 函数返回一组表达式中的最小值,但如果你想要确保一个值不超过某个最大值,你可以使用 LEAST 函数来限制它。
例如,如果你有一个值 x,并且你想要确保它不超过 100,你可以这样做:
SELECT LEAST(x, 100) AS limited_value; -- 限制最大为100
这将返回 x 的值,但如果 x 大于 100,则返回 100。
这里是一个具体的例子:
SELECT LEAST(150, 100) AS result; -- 结果将是 100
SELECT LEAST(50, 100) AS result; -- 结果将是 50
所以,虽然 LEAST 函数的直接作用是返回最小值,但你可以利用它来限制一个值不超过某个最大值。
$LOWER忽略大小写
使用 LOWER(email) 创建的索引可以有效地支持对电子邮件地址进行大小写不敏感的查询。例如:
SELECT * FROM users WHERE LOWER(email) = 'example@example.com';
在 PostgreSQL 中,转换为大写的函数是 UPPER。你可以使用这个函数将字符串转换为大写。例如:
SELECT UPPER('hello world'); -- 结果是 'HELLO WORLD'
$Left Join Lateral横向
LEFT JOIN LATERAL 是一种 SQL 连接方式,主要用于在连接时允许右侧的查询根据左侧的每一行动态生成结果。这在某些情况下可以提高灵活性和性能。
原文地址:https://blog.csdn.net/m0_63615119/article/details/143868643
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!