Zookeeper概览
个人博客地址:Zookeeper概览 | 一张假钞的真实世界
设计目标
- 简单的:方便使用以实现复杂的业务应用。
- 复制式的:跟Zookeeper协调的分布式进程一样,它也是在一组服务器上复制的。集群的每个节点间互相知道。它们维护一个状态数据在内存中的镜像、一个事务日志和持久存储的快照。只要集群的多数节点可用则Zookeeper服务可用。客户端连接到一个Zookeeper服务器。客户端维持一个TCP连接来发送请求、获取响应、获取监听事件、发送心跳。如果这个TCP连接中断,则客户端会连接另外一个服务器。
- 顺序的:Zookeeper赋予每次更新操作一个数字戳以标明事务的顺序。其后的操作可以用这个顺序实现高级别的抽象,例如同步原语。
- 快速的:在读取操作占优势的场景尤其快速。Zookeeper应用运行在上千台机器上,在读操作比写操作常见的情况下很高效,通常读写比例为10:1。
保障
- 顺序一致性:顺序应用客户端发送的更新操作。
- 原子性:更新操作要么成功要么失败,没有不完整的结果。
- 单一系统镜像:不管客户端连接到哪个服务器都会看到相同系统视图。例如,客户端使用同一个Session连接永远不会看到系统旧的视图,即使客户端失败后重连到另外一个服务器。
- 可靠性:一旦一个更新被应用,它就在这一刻被保持直到一个客户端覆盖这次更新。
- 时效性:系统的客户端视图保证在一定的时间范围内变为最新。
性能
ZooKeeper被设计为高性能的。真的是吗?Yahoo ZooKeeper开发团队的研究表明是的。尤其是在读远多于写的应用程序中。因为写会涉及所有服务器的同步。
读远多于写是协调服务典型的使用场景。
下图是ZooKeeper吞吐量随读写比率的变化而变化:
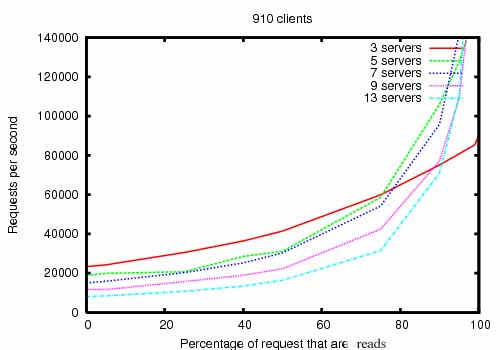
上图是ZooKeeper 3.2运行在拥有双2Ghz Xeon和两个SATA 15K RPM驱动器的服务器上的吞吐量图。一个驱动专用于ZooKeeper日志。快照写到OS的驱动。写和读都是1K的数据。“Servers”是ZooKeeper集群的规模。大概30台另外的服务器模拟客户端。ZooKeeper集群配置leaders不允许客户端连接。
3.2版本比3.1版本读写效率提升2倍以上。
基准测试也表明它是可靠的。“存在错误时的可靠性”图展示了如何响应各种失败。图中标注的事件如下:
- 一个follower的失败恢复
- 另外一个follower的失败恢复
- leader失败
- 两个follower的失败恢复
- 另外一个leader失败
可靠性
为了显示系统故障随时间变化的行为,我们运行了一个由7台机器组成的ZooKeeper服务。我们运行了与之前相同的饱和基准测试,但这次我们将写入百分比保持在30%,这是我们预期工作负载的比例。
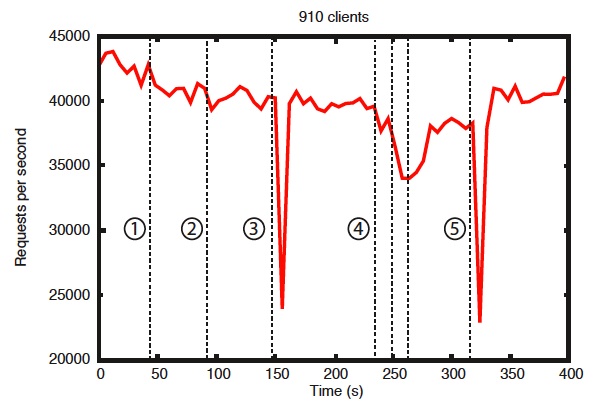
从这张图中可以看出一些重要的观察结果。首先,如果follower失败并快速恢复,那么即使出现故障,ZooKeeper也能够维持高吞吐量。但也许更重要的是,领导者选举算法允许系统足够快地恢复以防止吞吐量大幅下降。在我们的观察中,ZooKeeper花费不到200毫秒的时间来选举一个新的领导者。第三,随着follower的恢复,一旦他们开始处理请求,ZooKeeper能够再次提高吞吐量。
原文地址:https://blog.csdn.net/weixin_46161645/article/details/145125941
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!