兼顾高性能与低成本,浅析 Apache Doris 异步物化视图原理及典型场景
在现代化的数据分析场景中,数据量以指数级速度快速膨胀,分析维度在不断扩展,查询逻辑的复杂度也在日益增加。从性能角度考虑,在承担高并发查询的压力下,秒级别甚至更快的响应速度已成为基本需求。同时,面对有限的计算资源,成本及性能如何平衡,严格的资源管控也显得尤为重要。
物化视图作为一种有效的解决方案,兼顾了视图的灵活性和物理表的高性能。它可以预先计算并存储查询结果集,从而在查询请求到达时直接从物化视图中获取结果,而无需重新执行查询语句。这种机制有效提升了查询性能,降低了重复执行查询的开销,成为企业加速数据处理、精细控制成本关键策略之一。
Apache Doris 物化视图进行了支持。早期版本中,Doris 支持同步物化视图;从 2.1 版本开始,正式引入异步物化视图,并在 3.0 版本中完善了这一功能。 正文开始之前,我们先了解同步和异步物化视图的区别:
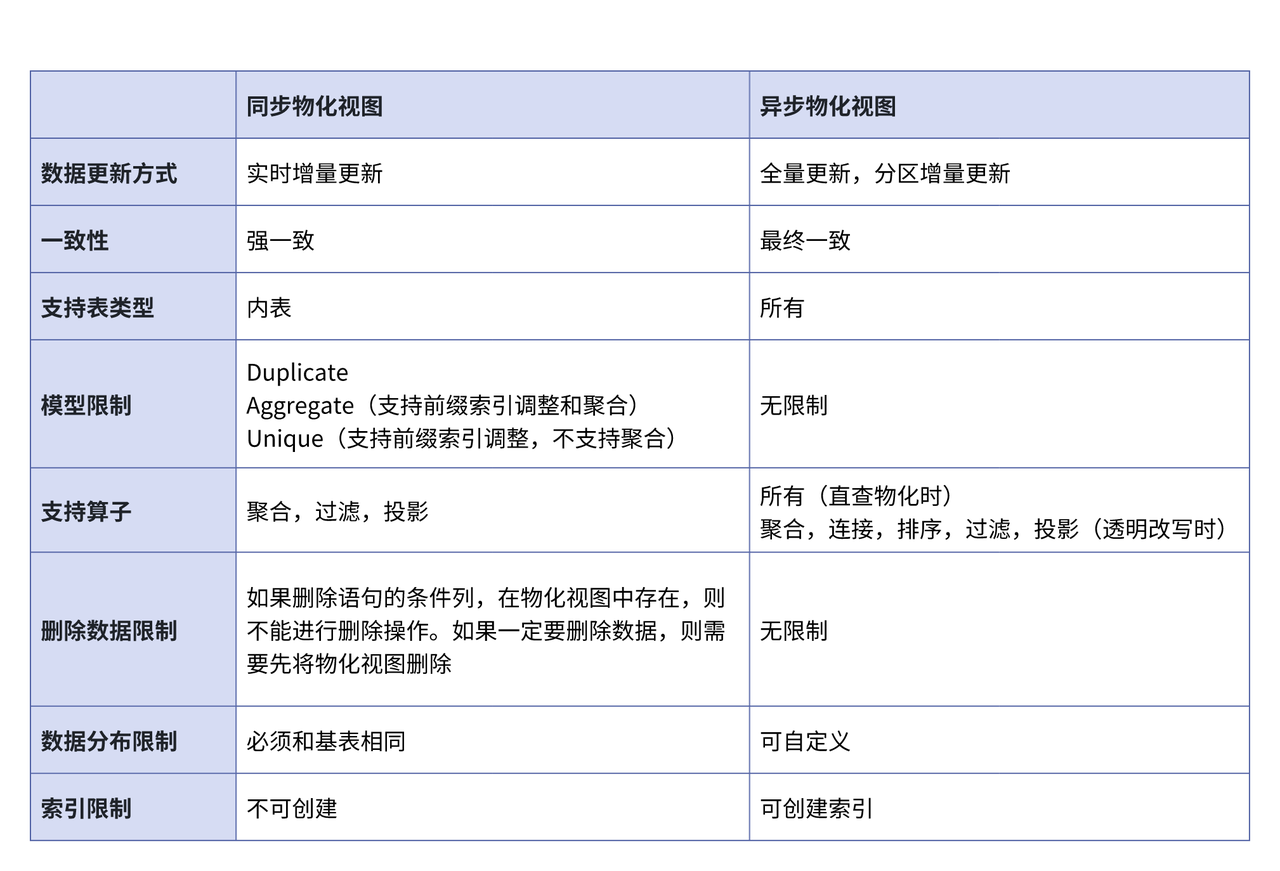
用户在使用 Apach Doris 过程中,可以根据场景需求选择适合的物化视图。同步物化视图更适合对查询延迟敏感的场景,而异步物化视图则更适合以批量方式进行分析的场景。具体来说:
- 同步物化视图:当基础表更新时,物化视图会实时同步更新,保证查询结果的即时准确性,适用于数据更新较少、对查询响应要求较高的场景。
- 异步物化视图:当基础表更新时,物化视图通过定期更新保持数据最终一致,可减少频繁更新带来的性能影响,适用于更新不频繁、批量更新或对实时性要求不高的分析场景。
通过前文,我们已基本了解同步及异步物化视图的区别及适配场景。本文将重点介绍 Doris 异步物化视图的特性及应用。
同步物化视图的使用可参考官网文档
异步物化视图原理浅析
01 支持全量和分区增量刷新
不同于同步物化视图的实时增量刷新机制,异步物化视图支持全量刷新和分区增量刷新两种机制,以保证数据的最终一致性:
- 全量刷新:计算并刷新物化视图定义 SQL 的所有数据。适合在数据量较小或数据架构发生变化时使用,在对实时性要求不高的场景下可进行定期刷新。
- 分区增量刷新:当物化视图的基表分区数据发生变化时,可以识别并仅刷新变化的分区,无需刷新整个物化视图,相比全量/实时刷新显著减少了计算和存储开销。刷新时会先计算要需要刷新的分区列表,然后拆分成多个 Insert Overwrite 语句顺序执行,可指定每次 Insert Overwrite 刷新的分区数量。该方式适用于大数据量场景,尤其是分区表频繁变化且对实时性要求较高的场景。
02 支持资源管控与可观测性
物化视图的构建及刷新是一个计算密集型的过程,因此,对该过程进行资源管控和监测至关重要。这可以效避免资源竞争,从而提升查询速度、优化系统性能及稳定性。
在资源管控上, Apache Doris 支持通过workload_group进行资源管理。通过配置workload_group以限制物化视图构建或刷新能够使用的最大系统资源。比如,在创建物化视图时,支持设置workload_group属性,以确保物化视图构建仅使用对应的系统资源,不会影响正常的查询操作。
在可观测性上, Doris 不仅支持查看物化视图元数据信息,也支持查看物化视图刷新任务的 Job 配置详情、物化视图刷新进度以及对应workload_group资源消耗情况,帮助用户更好的理解和管理物化视图。
当物化视图进行刷新时,系统会根据 Job 配置自动启动一个任务 Task 实例。可执行下方命令,实时查看和监控这一任务的状态。
select * from tasks("type"="mv") where MvName = 'mv_name' order by CreateTime desc;
参考文档:
Doris 支持通过 Workload 系统表对集群工作负载进行分析,详情见工作负载分析
03 支持全面的透明改写能力
透明改写指在处理查询时,可自动对用户的 SQL 进行优化及改写,提高查询性能及执行效率,降低计算成本。改写通常对用户不可见,无需干预改写过程。
Doris 异步物化视图采用基于 SPJG(SELECT-PROJECT-JOIN-GROUP-BY)模式的透明改写算法。该算法能够分析 SQL 的结构信息,自动寻找合适的物化视图进行透明改写,并选择最优的物化视图来响应查询 SQL。
Doris 提供了丰富且全面的透明改写能力:
- 支持 Join 类型的改写,并支持 Join 衍生改写。当查询和物化视图的 Join 的类型不一致时,可以通过在 Join 外部添加补偿
where条件来实现透明的改写。 - 支持聚合改写,包括多维聚合函数 GROUPING SETS、ROLLUP、CUBE 的改写,并支持查询包含聚合、物化不包含聚合的改写。
- 支持嵌套物化视图的改写,在复杂的查询加速场景下,可以借助嵌套物化视图进行极致加速。
- 支持分区补偿改写,当分区物化视图部分分区失效,可通过 Union All 基表补全数据。
目前,仅新优化器支持物化视图的透明改写。从 2.1.5 版本开始,透明改写默认开启,2.1.5 前的版本使用透明改写能力,需要手动开启如下开关。
-- 开启透明改写,默认不开启,自2.1.5开始,默认开启
SET enable_materialized_view_rewrite = true;
透明改写能力详情见文档
异步物化视图典型使用场景
01 查询加速,提高并发,减少资源消耗
在 BI 报表场景或其他加速场景中,用户对于查询响应时间较为敏感,通常要求能够秒级别返回结果。而查询通常涉及多张表先进行 Join 计算、再聚合计算,该过程会消耗大量计算资源,并且有时难以保证时效性。对此,异步物化视图能够很好应对,它不仅支持直接查询,也支持透明改写,优化器会依据改写算法和代价模型,自动选择最优的物化视图来响应请求。
未使用物化视图的原始查询:
如下所示对每个月各地区和国家的订单数量和利润进行分析。由于涉及多表连接,该查询消耗了大量资源,并且查询延迟较高。
SELECT
n_name,
r_name,
date_trunc(o.o_orderdate, 'month') as month,
count(distinct o.o_orderkey) as order_count,
sum(l.l_extendedprice * (1 - l.l_discount)) as revenue
FROM orders o
JOIN lineitem l ON o.o_orderkey = l.l_orderkey
JOIN customer c ON o.o_custkey = c.c_custkey
JOIN nation n ON c.c_nationkey = n.n_nationkey
JOIN region r ON n.n_regionkey = r.r_regionkey
GROUP BY n_name, r_name, month;
使用异步物化视图进行查询加速:
1)构建如下物化视图,对用户、月份、地区、国家进行初步聚合
CREATE MATERIALIZED VIEW sales_agg_mv
BUILD IMMEDIATE REFRESH AUTO ON MANUAL
DISTRIBUTED BY RANDOM BUCKETS 12
PROPERTIES ('replication_num' = '1')
AS
SELECT
n_name,
r_name,
date_trunc(o_orderdate, 'month') as month,
bitmap_union(to_bitmap(o_orderkey)) as order_count,
sum(l_extendedprice * (1 - l_discount)) as net_revenue,
sum(l_quantity) as total_quantity
FROM orders o
JOIN lineitem l ON o.o_orderkey = l.l_orderkey
JOIN customer c ON o.o_custkey = c.c_custkey
JOIN nation n ON c.c_nationkey = n.n_nationkey
JOIN region r ON n.n_regionkey = r.r_regionkey
GROUP BY n_name, r_name, month;
2)通过透明改写,原始查询将被优化器自动改写为以下语句:
SELECT
n_name,
r_name,
month,
bitmap_union_count(order_count) as order_count,
sum(net_revenue) as revenue
FROM sales_agg_mv
GROUP BY
n_name, r_name, month;
由此可见,用户在不修改原 SQL 的情况下,Doris 会自动选择最优的物化视图来响应查询,这极大提高了查询性能,减少了资源消耗,并提升了并发处理能力。
为更直观展示加速效果,我们以 TPCH 数据的 Schema 为例,测试物化视图加速效果。
- 数据规模:总数据量是 100G
- 节点:FE 和 BE 为单节点
- CPU : 至强 E5-2686V4,36C
- 内存:128G DDR3
- 硬盘:SSD 固态 2T
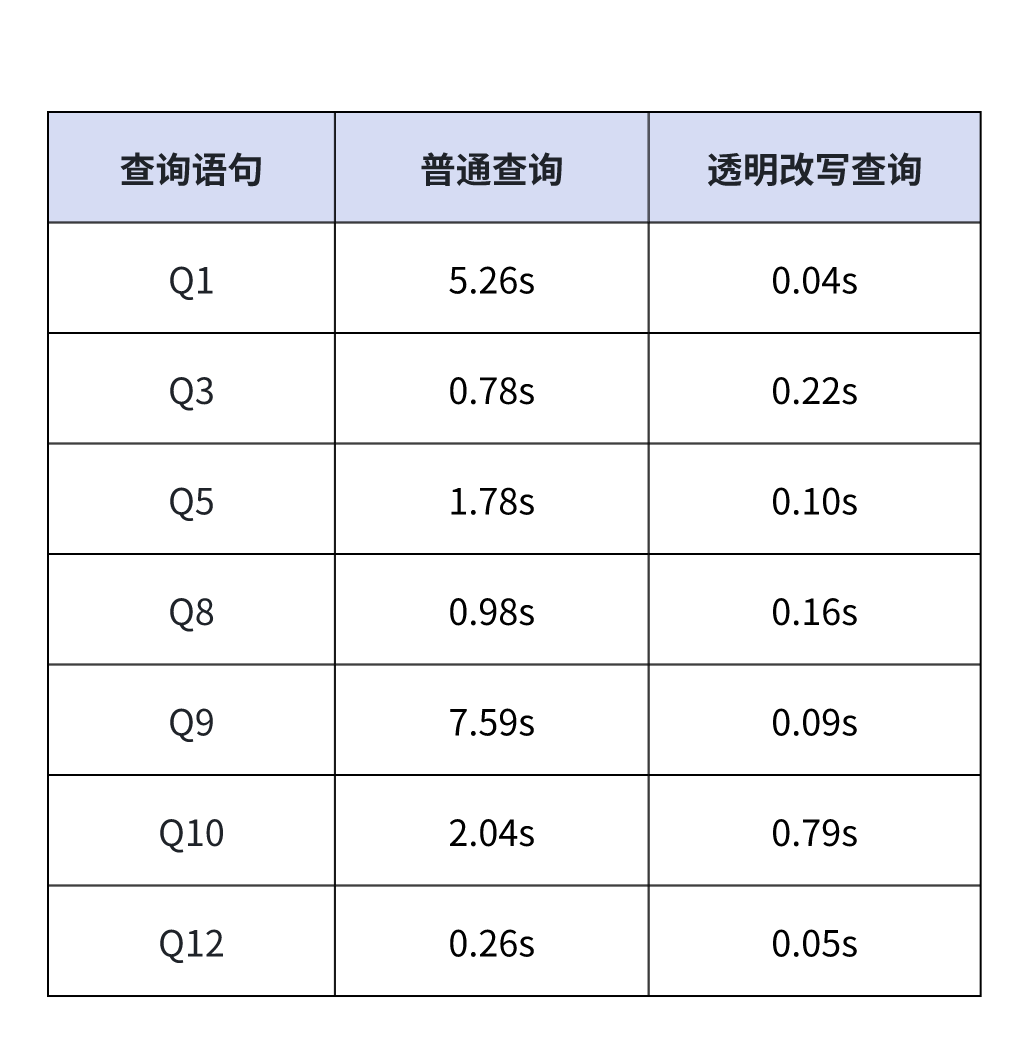
从性能对比结果可知,透明改写查询相比普通查询能够显著提升查询性能。在大多数查询场景中,透明改写查询响应时间较普通查询降低了 99%。
02 简化 ETL 流程,提升开发效率
数据分析工作往往需要对多表进行连接和聚合,这一过程通常涉及复杂且频繁重复的查询。这类查询可能引发查询延迟高或资源消耗大的问题。然而,如果采用异步物化视图构建数据分层模型,则可以很好避免该问题。
接下来,通过 TPC-H 数据集说明异步物化视图在数据建模中的应用,以分析每月各地区和国家的订单数量和利润为例:
原始查询(未使用物化视图):
SELECT
n_name,
date_trunc(o.o_orderdate, 'month') as month,
count(distinct o.o_orderkey) as order_count,
sum(l.l_extendedprice * (1 - l.l_discount)) as revenue
FROM orders o
JOIN lineitem l ON o.o_orderkey = l.l_orderkey
JOIN customer c ON o.o_custkey = c.c_custkey
JOIN nation n ON c.c_nationkey = n.n_nationkey
JOIN region r ON n.n_regionkey = r.r_regionkey
GROUP BY n_name, month;
使用异步物化视图分层建模:
1)构建 DWD 层(明细数据),处理订单明细宽表
CREATE MATERIALIZED VIEW dwd_order_detail
BUILD IMMEDIATE REFRESH AUTO ON COMMIT
DISTRIBUTED BY RANDOM BUCKETS 16
PROPERTIES ('replication_num' = '1')
AS
select
o.o_orderkey,
o.o_custkey,
o.o_orderstatus,
o.o_totalprice,
o.o_orderdate,
c.c_name,
c.c_nationkey,
n.n_name as nation_name,
r.r_name as region_name,
l.l_partkey,
l.l_quantity,
l.l_extendedprice,
l.l_discount,
l.l_tax
from orders o
join customer c on o.o_custkey = c.c_custkey
join nation n on c.c_nationkey = n.n_nationkey
join region r on n.n_regionkey = r.r_regionkey
join lineitem l on o.o_orderkey = l.l_orderkey;
2)构建 DWS 层(汇总数据),进行每日订单汇总
CREATE MATERIALIZED VIEW dws_daily_sales
BUILD IMMEDIATE REFRESH AUTO ON COMMIT
DISTRIBUTED BY RANDOM BUCKETS 16
PROPERTIES ('replication_num' = '1')
AS
select
date_trunc(o_orderdate, 'month') as month,
nation_name,
region_name,
bitmap_union(to_bitmap(o_orderkey)) as order_count,
sum(l_extendedprice * (1 - l_discount)) as net_revenue
from dwd_order_detail
group by
date_trunc(o_orderdate, 'month'),
nation_name,
region_name;
3)使用物化视图优化查询如下:
SELECT
nation_name,
month,
bitmap_union_count(order_count),
sum(net_revenue) as revenue
FROM dws_daily_sales
GROUP BY nation_name, month;
从上可知,异步物化视图运用在数据分层建模之后,查询语句变得更加简洁,响应耗时从几十秒缩短至秒级别:
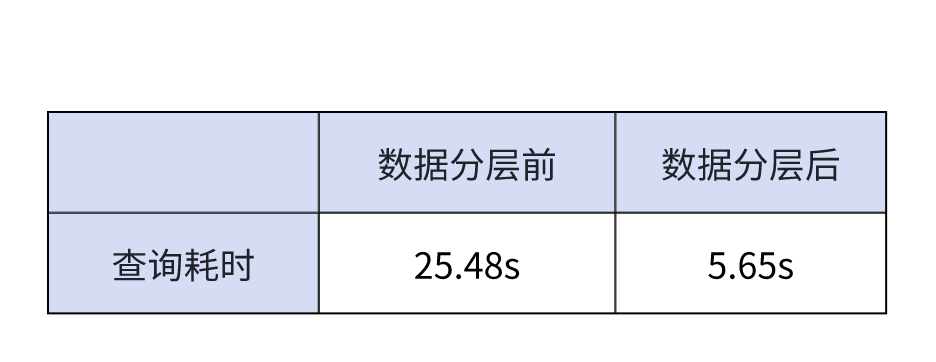
在 DWD 和 DWS 层的构建中,物化视图通过自动化的数据调度和刷新机制,简化了传统 ETL 的复杂性,显著提升了整体数据开发效率;同时,它支持触发式调度,提供更高的建模时效性和数据可见性。此外,基于物化视图分层建模,可大幅简化复杂查询逻辑,减少因重复计算带来的额外开销,从而有效提升系统整体吞吐量。
03 结合湖仓一体,加速外表查询
在现代化的数据架构中,企业通常会采用湖仓一体设计,以平衡数据的存储成本与查询性能。在这种架构下,经常会遇到两个关键挑战:
- 查询性能受限:频繁查询数据湖中的数据时,可能会受到网络延迟和第三方服务的影响,从而导致查询延迟,进而影响用户体验。
- 数据分层建模的复杂性:在数据湖到实时数仓的数据流转和转换过程中,通常需要复杂的 ETL 流程,这增加了维护成本和开发难度
使用 Doris 异步物化视图,可以很好的应对上述挑战:
- 透明改写加速查询:将常用的数据湖查询结果物化到 Doris 内部存储,采用透明改写可有效提升查询性能。
- 简化分层建模:支持基于数据湖中的表创建物化视图,实现从数据湖到实时数仓的便捷转换,极大简化了数据建模流程。
如下,以 Hive 示例说明:
1)基于 Hive 创建 Catalog,使用 TPC-H 数据集
CREATE CATALOG hive_catalog PROPERTIES (
'type'='hms',
-- hive meta store 地址
'hive.metastore.uris' = 'thrift://172.21.0.1:7004'
);
2)基于 Hive Catalog 创建物化视图
-- 物化视图只能在 internal 的 catalog 上创建, 切换到内部 catalog
switch internal;
create database hive_mv_db;
use hive_mv_db;
CREATE MATERIALIZED VIEW external_hive_mv
BUILD IMMEDIATE REFRESH AUTO ON MANUAL
DISTRIBUTED BY RANDOM BUCKETS 12
PROPERTIES ('replication_num' = '1')
AS
SELECT
n_name,
o_orderdate,
sum(l_extendedprice * (1 - l_discount)) AS revenue
FROM
customer,
orders,
lineitem,
supplier,
nation,
region
WHERE
c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND l_suppkey = s_suppkey
AND c_nationkey = s_nationkey
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'ASIA'
GROUP BY
n_name,
o_orderdate;
3)运行如下的查询,通过透明改写自动使用物化视图加速查询。
SELECT
n_name,
sum(l_extendedprice * (1 - l_discount)) AS revenue
FROM
customer,
orders,
lineitem,
supplier,
nation,
region
WHERE
c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND l_suppkey = s_suppkey
AND c_nationkey = s_nationkey
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'ASIA'
AND o_orderdate >= DATE '1994-01-01'
AND o_orderdate < DATE '1994-01-01' + INTERVAL '1' YEAR
GROUP BY
n_name
ORDER BY
revenue DESC;
使用注意:Doris 暂无法感知除 Hive 外的其他外表数据变更。当外表数据不一致时,使用物化视图可能出现数据不一致的情况。以下开关表示:参与透明改写的物化视图是否允许包含外表,默认false。如接受数据不一致或者通过定时刷新来保证外表数据一致性,可以将此开关设置成true。
-- 设置包含外表的物化视图是否可用于透明改写,默认不允许,如果可以接受数据不一致或者可以自行保证数据一致,
-- 可以开启
SET materialized_view_rewrite_enable_contain_external_table = true;
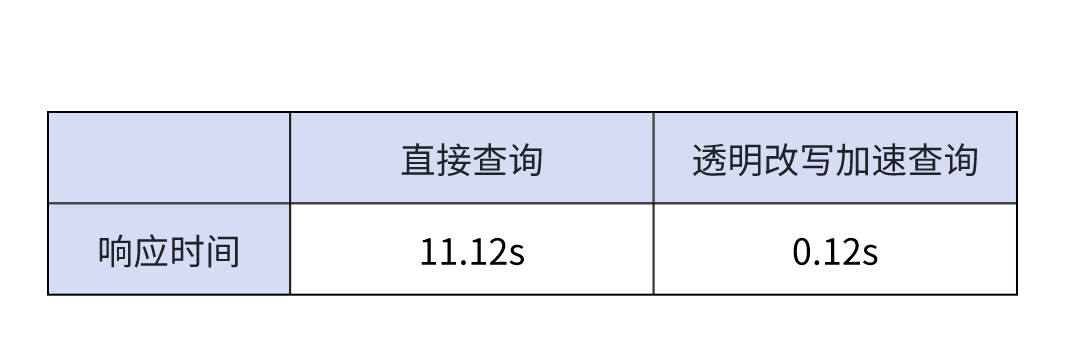
下表为使用异步物化视图前后的性能差异,使用透明改写之后,查询速度较之前提升约 93 倍。
04 提升写入效率,减少资源竞争
1. 灵活刷新策略,避免资源竞争
在高吞吐的数据写入的场景中,系统性能的稳定性与数据处理的高效性同样重要。通过异步物化视图灵活的刷新策略,用户可以根据具体场景选择合适的刷新方式,从而降低写入压力,避免资源争抢。
使用同步物化视图时,由于刷新策略的限制,通常只能进行高频的实时更新。虽然能够保障时效性,但面对高频、大规模的导入操作时,极易出现系统资源持续占用,影响数据处理性能。
相比之下,异步物化视图提供了手动触发、触发式、周期性触发三种灵活的刷新策略。用户可以根据场景需求差异,选择合适的刷新策略。当基表数据变更时,不会立即触发物化视图刷新,延迟刷新有利于降低资源压力,有效避免写入资源争抢。
如下所示,选择的刷新方式为定时刷新,每 2 小时刷新一次。当orders 和 lineitem 导入数据时,不会立即触发物化视图刷新。
CREATE MATERIALIZED VIEW common_schedule_join_mv
BUILD IMMEDIATE REFRESH AUTO ON SCHEDULE EVERY 2 HOUR
DISTRIBUTED BY RANDOM BUCKETS 16
PROPERTIES ('replication_num' = '1')
AS
SELECT
l_linestatus,
l_extendedprice * (1 - l_discount),
o_orderdate,
o_shippriority
FROM
orders
LEFT JOIN lineitem ON l_orderkey = o_orderkey;
2. 透明改写导入 SQL,提升导入效率
透明改写能够对查询 SQL 的改写,实现了查询加速,同时也能对导入 SQL 进行改写,从而提升导入效率。
从 2.1.6 版本开始,当物化视图和基表数据强一致时,可对 DML 操作如 Insert Into 或者 Insert Overwrite 进行透明改写,这对于数据导入场景的性能提升有显著效果。
A. 创建 Insert Into 数据的目标表
CREATE TABLE IF NOT EXISTS target_table (
orderdate DATE NOT NULL,
shippriority INTEGER NOT NULL,
linestatus CHAR(1) NOT NULL,
sale DECIMALV3(15,2) NOT NULL
)
DUPLICATE KEY(orderdate, shippriority)
DISTRIBUTED BY HASH(shippriority) BUCKETS 3
PROPERTIES (
"replication_num" = "1"
);
B. common_schedule_join_mv:
CREATE MATERIALIZED VIEW common_schedule_join_mv
BUILD IMMEDIATE REFRESH AUTO ON SCHEDULE EVERY 2 HOUR
DISTRIBUTED BY RANDOM BUCKETS 16
PROPERTIES ('replication_num' = '1')
AS
SELECT
l_linestatus,
l_extendedprice * (1 - l_discount),
o_orderdate,
o_shippriority
FROM
orders
LEFT JOIN lineitem ON l_orderkey = o_orderkey;
未经改写的导入语句如下:
INSERT INTO target_table
SELECT
o_orderdate,
o_shippriority,
l_linestatus,
l_extendedprice * (1 - l_discount)
FROM
orders
LEFT JOIN lineitem ON l_orderkey = o_orderkey;
经过透明改写后,语句如下:
INSERT INTO target_table
SELECT *
FROM common_schedule_join_mv;
需要注意的是:如果 DML 操作的是无法感知数据变更的外表,透明改写可能导致基表最新数据无法实时导入目标表。如果用户可以接受数据不一致或能够自行保证数据一致性,可以打开如下开关
-- DML 时,当物化视图存在无法实时感知数据的外表时,是否开启基于结构信息的物化视图透明改写,默认关闭
SET enable_dml_materialized_view_rewrite_when_base_table_unawareness = true;
最佳使用实践
01 高效复用物化视图,平衡查询与构建成本
查询加速需权衡物化视图的构建成本与查询性能。物化视图越通用,透明改写后的性能提升效果越低;而越符合需求的定制化物化视图,性能提升效果越好,但定制化物化视图很难被复用。这有违于高性能、低成本的基本原则。
那么,如何复用物化视图,能够更好的平衡查询与构建成本?为便于大家提高工作效率,我们整理了一些构建物化视图的基本原则:
- Join:提取查询中使用的公共表连接模式构建物化视图,以节省连接计算。
- Aggregate:尽量使用低基数字段作为维度,确保聚合后的数据量小于原查询。
- Filter:若查询中频繁对同一字段进行过滤,可在物化视图中添加相应的 Filter。
- Calculate Expressions :对于性能消耗较大的表达式(如复杂的
CASE WHEN和字符串处理函数),可在物化视图中定义这些表达式。 - 固定查询:如果查询语句固定且对性能要求极高,可以直接使用原查询语句构建物化视图。
举例说明,以如下查询为例,我们分别创建不同的物化视图:
SELECT
l_linestatus,
sum(
l_extendedprice * (1 - l_discount)
) AS revenue,
o_orderdate,
o_shippriority
FROM
orders
LEFT JOIN lineitem ON l_orderkey = o_orderkey
WHERE
o_orderdate <= DATE '1997-05-01'
AND o_orderdate >= DATE '1996-05-15'
GROUP BY
l_linestatus,
o_orderdate,
o_shippriority;
common_join_mv:
CREATE MATERIALIZED VIEW common_join_mv
BUILD IMMEDIATE REFRESH AUTO ON MANUAL
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES ('replication_num' = '1')
AS
SELECT
l_linestatus,
l_extendedprice * (1 - l_discount),
o_orderdate,
o_shippriority
FROM
orders
LEFT JOIN lineitem ON l_orderkey = o_orderkey;
target_agg_mv:
CREATE MATERIALIZED VIEW target_agg_mv
BUILD IMMEDIATE REFRESH AUTO ON MANUAL
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES ('replication_num' = '1')
AS
SELECT
l_linestatus,
sum(
l_extendedprice * (1 - l_discount)
) AS revenue,
o_orderdate,
o_shippriority
FROM
orders
LEFT JOIN lineitem ON l_orderkey = o_orderkey
GROUP BY
l_linestatus,
o_orderdate,
o_shippriority;
以上两个物化视图均可进行透明改写。从通用性来看,common_join_mv 更具优势,适用于更广泛的透明改写场景。然而,在透明改写后的性能表现上,target_agg_mv 则表现更佳,原因是其能够提前对部分数据进行聚合。
因此,在性能要求较高的场景中,建议构建定制的物化视图;而在性能要求不那么严格的情况下,可以选择构建更通用的物化视图。
02 支持分区物化视图,节省刷新资源
从前文介绍可知,异步物化视图提供了全量和分区增量的刷新策略。因此,当物化视图基表的分区数据发生变化时,使用分区增量刷新可自动识别出物化视图对应变化的分区,并仅刷新这些分区,从而实现分区增量刷新,而无需刷新整个物化视图,节省刷新资源。
当满足以下条件时,可以创建分区物化视图:
- 物化视图的基表数据量较大,并且基表为分区表
- 除分区表外,物化视图使用的其他表不经常发生变化
- 物化视图的定义 SQL 和分区字段符合分区推导的要求,即满足分区增量更新的条件。详细要求可参考:CREATE-ASYNC-MATERIALIZED-VIEW
- 物化视图的分区数不超过 1000
以下方示例:
CREATE TABLE IF NOT EXISTS lineitem (
l_orderkey INTEGER NOT NULL,
l_partkey INTEGER NOT NULL,
l_suppkey INTEGER NOT NULL,
l_linenumber INTEGER NOT NULL,
l_ordertime DATETIME NOT NULL,
l_quantity DECIMALV3(15, 2) NOT NULL,
l_extendedprice DECIMALV3(15, 2) NOT NULL,
l_discount DECIMALV3(15, 2) NOT NULL,
l_tax DECIMALV3(15, 2) NOT NULL,
l_returnflag CHAR(1) NOT NULL,
l_linestatus CHAR(1) NOT NULL,
l_shipdate DATE NOT NULL,
l_commitdate DATE NOT NULL,
l_receiptdate DATE NOT NULL,
l_shipinstruct CHAR(25) NOT NULL,
l_shipmode CHAR(10) NOT NULL,
l_comment VARCHAR(44) NOT NULL
) DUPLICATE KEY(
l_orderkey, l_partkey, l_suppkey,
l_linenumber
) PARTITION BY RANGE(l_ordertime) (
FROM
('2024-05-01') TO ('2024-06-30') INTERVAL 1 DAY
) DISTRIBUTED BY HASH(l_orderkey) BUCKETS 3 PROPERTIES ("replication_num" = "1");
insert into lineitem values
(1, 2, 3, 4, '2024-05-01 01:45:05', 5.5, 6.5, 0.1, 8.5, 'o', 'k', '2024-05-01', '2024-05-01', '2024-05-01', 'a', 'b', 'yyyyyyyyy'),
(1, 2, 3, 4, '2024-05-15 02:35:05', 5.5, 6.5, 0.15, 8.5, 'o', 'k', '2024-05-15', '2024-05-15', '2024-05-15', 'a', 'b', 'yyyyyyyyy'),
(2, 2, 3, 5, '2024-05-25 08:30:06', 5.5, 6.5, 0.2, 8.5, 'o', 'k', '2024-05-25', '2024-05-25', '2024-05-25', 'a', 'b', 'yyyyyyyyy'),
(3, 4, 3, 6, '2024-06-02 09:25:07', 5.5, 6.5, 0.3, 8.5, 'o', 'k', '2024-06-02', '2024-06-02', '2024-06-02', 'a', 'b', 'yyyyyyyyy'),
(4, 4, 3, 7, '2024-06-15 13:20:09', 5.5, 6.5, 0, 8.5, 'o', 'k', '2024-06-15', '2024-06-15', '2024-06-15', 'a', 'b', 'yyyyyyyyy'),
(5, 5, 6, 8, '2024-06-25 15:15:36', 5.5, 6.5, 0.12, 8.5, 'o', 'k', '2024-06-25', '2024-06-25', '2024-06-25', 'a', 'b', 'yyyyyyyyy'),
(5, 5, 6, 9, '2024-06-29 21:10:52', 5.5, 6.5, 0.1, 8.5, 'o', 'k', '2024-06-30', '2024-06-30', '2024-06-30', 'a', 'b', 'yyyyyyyyy'),
(5, 6, 5, 10, '2024-06-03 22:05:50', 7.5, 8.5, 0.1, 10.5, 'k', 'o', '2024-06-03', '2024-06-03', '2024-06-03', 'c', 'd', 'xxxxxxxxx');
CREATE TABLE IF NOT EXISTS partsupp (
ps_partkey INTEGER NOT NULL,
ps_suppkey INTEGER NOT NULL,
ps_availqty INTEGER NOT NULL,
ps_supplycost DECIMALV3(15, 2) NOT NULL,
ps_comment VARCHAR(199) NOT NULL
) DUPLICATE KEY(ps_partkey, ps_suppkey) DISTRIBUTED BY HASH(ps_partkey) BUCKETS 3 PROPERTIES ("replication_num" = "1");
insert into partsupp values
(2, 3, 9, 10.01, 'supply1'),
(4, 3, 9, 10.01, 'supply2'),
(5, 6, 9, 10.01, 'supply3'),
(6, 5, 10, 11.01, 'supply4');
orders 表的 o_ordertime 字段为分区字段,类型为 DATETIME,按照天进行分区。以下查询基于“天”粒度进行,查询粒度较粗。
SELECT
l_linestatus,
sum(
l_extendedprice * (1 - l_discount)
) AS revenue,
ps_partkey
FROM
lineitem
LEFT JOIN partsupp ON l_partkey = ps_partkey
and l_suppkey = ps_suppkey
WHERE
date_trunc(l_ordertime, 'day') <= DATE '2024-05-25'
AND date_trunc(l_ordertime, 'day') >= DATE '2024-05-05'
GROUP BY
l_linestatus,
ps_partkey;
为避免物化视图每次刷新时分区数量过多而消耗过多资源,物化视图的分区粒度可以与基表 orders 一致,按“天”进行分区。物化视图的定义如下,以上查询可以通过透明改写命中此物化视图。
CREATE MATERIALIZED VIEW rollup_partition_mv
BUILD IMMEDIATE REFRESH AUTO ON MANUAL
partition by(order_date)
DISTRIBUTED BY RANDOM BUCKETS 2
PROPERTIES ('replication_num' = '1')
AS
SELECT
l_linestatus,
sum(
l_extendedprice * (1 - l_discount)
) AS revenue,
ps_partkey,
date_trunc(l_ordertime, 'day') as order_date
FROM
lineitem
LEFT JOIN partsupp ON l_partkey = ps_partkey
and l_suppkey = ps_suppkey
GROUP BY
l_linestatus,
ps_partkey,
date_trunc(l_ordertime, 'day');
注意:如果用户修改的数据涉及多个分区,物化视图的刷新将会影响到多个分区,这可能导致刷新性能下降,类似于全量刷新的效果。
结束语
以上就是对 Apache Doris 异步物化视图的详细介绍。其功能强大,支持全量及分区增量刷新机制,具备资源管控与可观测性,透明改写能力更加全面。在查询加速、数据建模、高吞吐写入、湖仓一体等典型场景中,使用异步物化视图均有显著的性能及资源利用率提升。
未来,我们将不断完善物化视图的构建,提升透明改写的稳定性与准确性,实施精细化的资源控制,并增强构建和刷新的监控手段。同时,计划扩展透明改写的功能,逐步支持物化视图的智能管理,降低用户使用物化视图的成本,为用户提供更优质的使用体验。
原文地址:https://blog.csdn.net/SelectDB_Fly/article/details/143904388
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!