Redis基础篇
1.Redis的引入
我们的这个redis就是对于这个内存数据进行存储的,和我们的这个变量的这个性质是一样的,但是我们的这个redis主要是应用于这个分布式的这个系统上面的,如果仅仅是这个单机的程序,我们使用变量对于这个数据进行存储,这个是更优的选择;
但是我们的这个redis主要是做什么的呢?我们知道因为这个进程的隔离性,我们的这个不同的进程之间如果想要进行通信,这个时候只能借助于我们的这个网络,我们的这个redis就是基于这个网络,把存储在这个内存上面的数据给自己所在的这个主机上面的其他的进程,或者是其他的主机的其他进程,都是可以的;
我们的这个mysql也是对于这个数据进行存储和管理的,这个方面而言,我们的两个东西是由异曲同工之妙的,但是两者是各自有自己的这个应用的场景,我i们的这个redis最开始诞生的时候,定位就是一个消息的中间件,但是随着大家的这个使用,我们把这个redis当成了在这个内存里面存储数据的这个介质,但是这个并不意味着我们的这个数据库没用;
主要是我们的这个数据库是从这个硬盘上面读取数据,操作数据,我们的这个redis是在这个内存上面存储数据和操作数据,这个时候我们两者的这个速度就是不一样的,因为我们从这个内存上面读取数据的这个速度就会更快一些;但是这个毕竟是内存,因此这个空间容量方面没有我们的这个数据库的容量大,因此两者通常是结合使用,我们把这个热点数据使用这个redis进行存储,提高这个效率,其他的这个数据使用这个数据库存储就可以了,两者的结合使用发挥更大的作用;
2.单机和分布式
单机就是只有一个服务器,这个服务器负责这个所有的工作,我们现在的这个很多的这个公司里面的这个产品都是使用的这个单机架构;
如果我们的这个业务数据,用户量,数据量进一步增加,这个时候哦我们呢就会考虑引入更多的这个主机,引入更多的这个硬件资源;
因为我们的这个应用服务器比较吃这个CPU和硬件资源,因此这个数据量很大的时候我们的这个单个的应用服务器可能会撑不住,这个时候我们使用这个复杂均衡进行控制,合理的对于这个多台应用服务器进行调度;
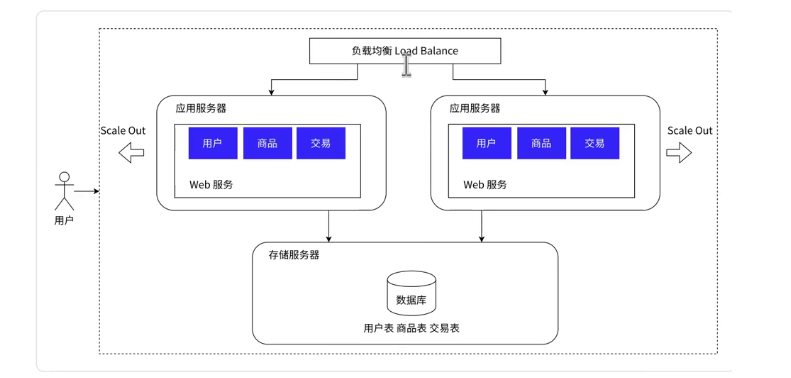
3.读写分离
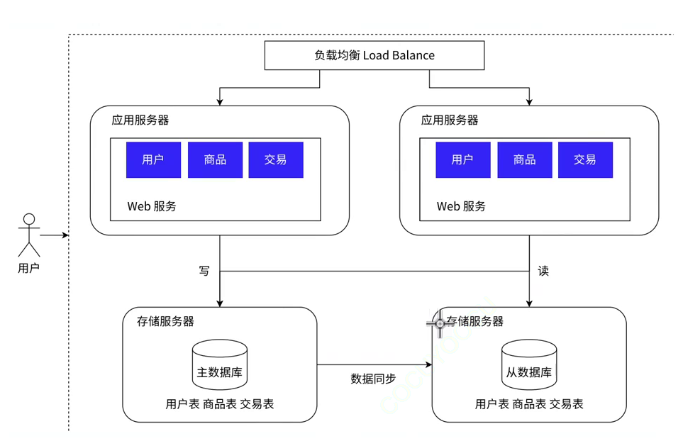
因为我们的这个应用服务器无论是几个,我们的这个数据库服务器只有一个的话,这个数据的处理的效率也是会大打折扣的,因此这个时候我们提出了这个读写分离的这个思路;
就是我们的这个数据库服务器根据这个职能的不同,吧这个服务器划分为我们的这个主数据库和从数据库,我们的这个主数据库就是负责这个数据的写,例如我们的这个增删查改,我们的这个从数据库就是进行这个数据的读,也就是我们的这个select语句;
4.缓存服务器
我们的这个缓存服务器的引入有两个很重要的作用:
1)缓解我们的这个其他的这个存储服务器的压力;
2)提高这个数据读取的效率(我们的这个缓存服务器相当于是这个普通的服务器的读取速度快一些,因此这个时候我们的这个缓存服务器就会把这个热点数据存储在自己的这个里面)我们的这个应用服务器进行这个数据读取的时候先到这个缓存服务器读取,如果这个服务器上面不存在,我们考虑从其他的这个存储服务器进行读取;

5.微服务
把我们原来的这个服务器拆分成很多个这个功能更加细致的这个更小的服务器,这个就是我们熟知的这个微服务的概念,这个时候我们的这个服务器的类型和数量就会增加;
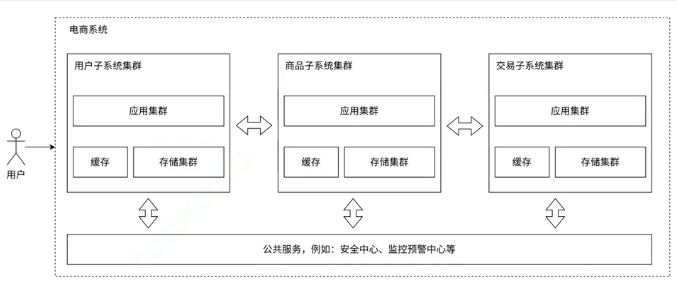
引入这个微服务,我们的这个需要付出的代价就是:
系统的性能下降,因为我们进行这个功能的拆分之后,我们的这个不同功能的这个服务器之间使用这个网络进行通信,这个时候速度会进一步下降;
原文地址:https://blog.csdn.net/binhyun/article/details/143839488
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!