视觉表征与多模态
视觉表征与多模态
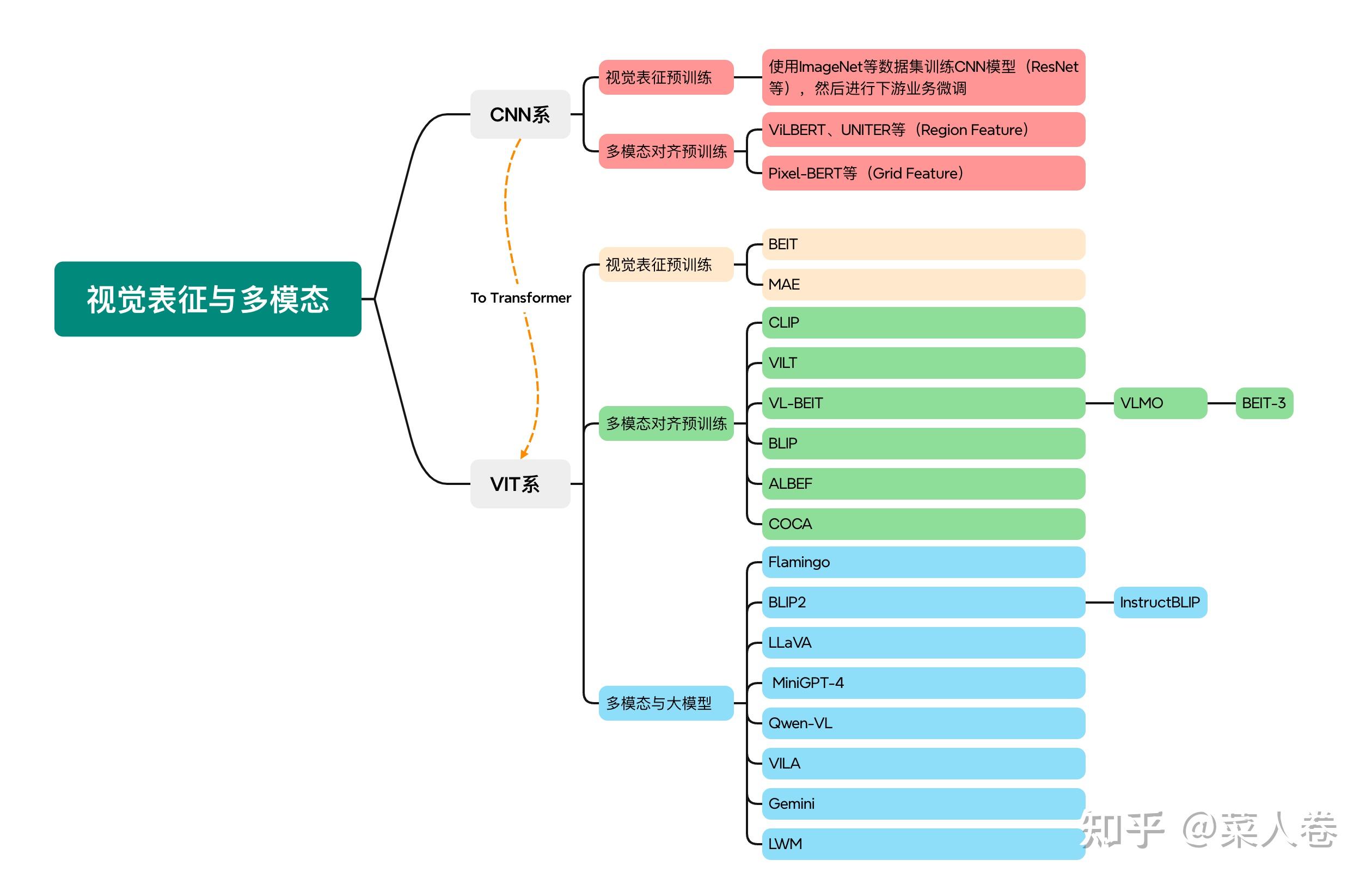
腾讯综述
https://blog.csdn.net/python12345_/article/details/140143009
多模态大模型脱胎于大模型的发展,传统的多模态模型面临着巨大的计算开销,而 LLMs 在大量训练后掌握了关于世界的“先验知识”,因而一种自然的想法就是使用 LLMs 作为多模态大模型的先验知识与认知推动力,来加强多模态模型的性能并且降低其计算开销,从而多模态大模型这一“新领域”应运而生。
作为在语言模态上得到了良好训练的 LLMs,MM LLMs 面对的主要任务是如何有效的将 LLMs 与其他模态的信息进行结合,使其可以综合多模态的信息进行协作推理,并且最终使得 MM LLMs 的输出与人类价值观保持一致。
多模态大模型的整体架构可以被归类为如下图的五个部分,整个多模态大模型的训练可以被分为多模态理解与多模态生成两个步骤。多模态理解包含多模态编码器,输入投影与大模型主干三个部分,而多模态生成则包含输出投影与多模态生成器两个部分,通常而言,在训练过程中,多模态的编码器、生成器与大模型的参数一般都固定不变,不用于训练,主要优化的重点将落在输入投影与输出投影之中,而这两部分一般参数量仅占总体参数的 2%。

多模态编码器
如果用公式表示,多模态编码器(ME)完成的任务是编码输入的多模态信息 ,将其映射到特征空间中获得 :
这里 用来表示如图像、视频、音频、3D 等的不同多模态信息。不同的模态对应有不同的模态编码器,对于图像,常用的编码器有 NFNet-F6、ViT、CLIP ViT 以及 Eva-CLIP ViT。其中 NFNet-F6 是一种抛弃了 Batch Norm 的 ResNet 变体,而后面三种都基于 Vision Transformer 方法。
对于音频而言,常用的编码器是 CFormer、HuBERT、BEATs 与 Whisper。对于三维点云数据而言,编码器有 ULIP-2,PointBERT 等。而对于视频而言,常用的方法是将视频均匀采样五帧,再进行与图像相同的输入编码。此外,还有类似 ImageBind 这类 any to ang one 的涵盖六种模态的统一编码器可以使用。
输入投影
输入投影主要用于将编码器编码得到的特征向量对齐到大模型擅长的文本模态空间 之中。具体而言:
其中, 一般指输入的 Prompt,为了训练输入投影,其目标是给定多模态数据集{,},最小化其文本生成 Loss:
通常,输入投影可以直接使用多层感知器 MLP,或者也可以使用更加复杂的如 Crossattention、Q-Former、PFormer 等。
大模型主干
作为多模态大模型的核心,大模型主干主要用于参与模式的表示、语义理解、推理与决策输出,一般而言,在MM LLMs,大模型主干主要产生直接的文本输出 与指导多模态生成器生成多模态信息的信号 ,即:
MM LLMs 中常用的大模型主干有 Flan-T5,ChatGLM,UL2,Qwen、Chinchilla、OPT、PaLM、LLaMA、LLaMA-2 和 Vicuna。
多模态生成器
多模式生成器(MG)的任务是生成不同模态的输出,通常使用潜在扩散模型(Latent Diffusion Models,LDMs) 实现,例如非常有名的用于图像生成的 Stable Diffusion,以及用于视频合成的 Zeroscope、用于音频生成的 AudioLDM-2 等。
在训练过程中,首先将真实标题通过 VAE 获得潜在特征 ,通过给 添加噪音 构建噪音潜在特征 ,使用一个预训练的 Unet 计算条件 LDM 损失 同时优化输入投影与输出投影:
多模态大模型综述
从这些大模型之中,作者也归纳总结了 MM LLMs 的发展趋势与方向:
- 从具体的某一模态发展到任意到任意模型的转换(MiniGPT-4 → MiniGPT-5 → NExT-GPT)
- 从有监督微调到基于人类反馈的强化学习(BLIP-2 → InstructBLIP → DRESS)
- 多样化模态扩展(BLIP-2 → X-LLM,InstructBLIP → X-InstructBLIP)
- 更高质量的数据集(LLaVA → LLaVA1.5)
- 更高效的模型架构
这里提一下 MiniGPT-5
介绍完多模态大模型的架构,那么多模态大模型哪家强呢?这篇综述总结了 26 种大模型的核心贡献与其发展趋势,归纳成一个表如下:
| Model | I→O | Modality Encoder | Input Projector | LLM Backbone | Output Projector | Modality Generator | #.PT | #.IT |
|---|---|---|---|---|---|---|---|---|
| Flamingo | I+T→T | I: ViT NFNet-F6 | Cross-attention | Chinchilla-14B/7B/70B | - | - | - | - |
| BLIP-2 | I+T→T | I/EVA: CLIP/EVA ViT@224 | Q-Former w/ Linear Projector | Flan-T5/OPT/Vicuna | - | - | 129M | - |
| LLaVA | I→T | I: CLIP ViT-L/14 | Q-Former | Vicuna-7B/13B | - | - | - | - |
| MiniGPT-4 | I+T→T | I: EVA-CLIP ViT-G/14 | Q-Former w/ Linear Projector | Vicuna-13B | - | - | - | - |
| mPLUG-Owl | I+T→T | I: CLIP ViT-L/14 | Q-Former w/ Linear Projector | LLaMA-7B | - | - | - | - |
| Otter | I+T→T | I: CLIP ViT-L/14 | Cross-attention | LLaMA-2-13B | - | - | - | - |
| X-LXMERT | I+T→T | I: ViT; A: G-Former | Cross-attention | ChatGLM-6B | - | - | - | - |
| X-LMV | I+T→T | I: ViT/G; A: G-Former | Q-Former w/ Linear Projector | Flan-T5/OPT/Vicuna | - | - | 129M | 1.2M |
| VideoChat | I+V+T→T | I/V: I/EVA ViT-G/14@224 | Q-Former w/ Linear Projector | Vicuna | - | - | - | - |
| InstructBLIP | I+V+T→T | I: ViT-L/14@224 | Cross-attention | OPT-6.7B | Tiny Transformer | I: Stable Diffusion-1.5 | - | - |
| PandaGPT | I+T→T | I: CLIP ViT-L/14 | Linear Projector | UL2-32B | - | - | - | - |
| GILL | I+T→T | I: CLIP ViT-L | Linear Projector | Vicuna-1.5-7B/13B | - | - | - | - |
| PaLI-X | I+T→T | I/V: ViT-G/14 | Cross-attention | LLaMA | - | - | - | - |
| Video-LLaMA | I+V+A+T→T | I/V: Eva-CLIP ViT-G/14 | A: ImageBind | Vicuna/LLaMA | - | - | - | - |
| Video-ChatGPT | I+V+T→T | I: CLIP ViT-L/14 | Linear Projector | Vicuna-v1.1 | - | - | - | - |
| Shikra | I+T→T+B | I: CLIP ViT-L/14@224 | Cross-attention | Vicuna-7B/13B | - | - | - | - |
| LLaVAR | I+T→T | I: CLIP ViT-L/14@224 | Q-Former w/ Linear Projector | Vicuna-13B | - | - | 600K | 5.5M |
| mPLUG-DocOwl | IoPT→T | I: CLIP ViT-L/14&336 | Cross-attention | LLaMA-7B | - | - | - | - |
| Lynx | I+V+T→T | I/V: Eva-CLIP ViT-B | Cross-attention | LLaMA-13B | MLP | I: Stable Diffusion-1.5 | - | - |
| Emu | I+V+T→T | I/V: Eva-CLIP ViT-B | Cross-attention | OPT/Flan-T5 | - | - | - | - |
| DLP | I+T→T | I: CLIP/Eva-CLIP ViT; A: ImageBind | Q-&P-Former w/ Linear Projector | Vicuna | - | - | - | - |
| BuboGPT | I+T→T | I: CLIP/Eva-CLIP ViT | Q-Former w/ Linear Projector | LLaMA | - | - | - | - |
| ChatSpot | I+T→T | I: CLIP ViT-L/14 | Linear Projector | Vicuna-7B/LLaMA | - | - | - | - |
| IDEFICS | I+T→T | I: OpenCLIP | Cross-attention | LLaMA | - | - | - | - |
| Qwen-VL-(Chat) | I+T→T | I: ViT@448 initialized | Cross-attention | Qwen-7B | - | - | 1.4B† | 50M† |
| LaviPT | I→T | I: OpenCLIP’s ViT-bigG | Cross-attention | LLaMA-7B | - | - | - | - |
| Next-GPT | I+V+A+T→T+V | I/V/A: ImageBind | Linear Projector | Vicuna-7B | Tiny Transformer | I: Stable Diffusion; V: Zeroscope; A: AudioLDM | - | - |
| DreamLLM | I+T→T | I: CLIP ViT-L | Linear Projector | LLaMA-2 | MLP | I: Stable Diffusion | - | - |
| AnyMAL | I+V+A+T→T | I: CLIP ViT/L/14@224 | I/V: Cross-attention | LLaMA-2 | - | I: Stable Diffusion-2 | 0.6M | 0.7M |
| MiniGPT-5 | I+T→T | I: EVA-CLIP ViT-G/14 | Q-Former w/ Linear Projector | Vicuna-v1.5-7B | Tiny Transformer | - | - | - |
| LLaVA-1.5 | I+T→T | I: CLIP ViT-G/14@224 | Q-Former w/ Linear Projector | Vicuna-v1.5-7B/13B | - | - | - | - |
| MiniGPT-v2 | I+T→T | I: EVA-CLIP ViT@448 | Linear Projector | LLaMA-2-Chat-7B | - | - | - | - |
| Cog VLM | I+T→T | I: EVA-CLIP ViT | Cross-attention | Vicuna-v1.5-13B | - | - | - | - |
| Qwen-Audio | I+T→T | A: Whisper-L-v2 | Linear Projector | Qwen-7B | - | - | - | - |
| DRESS | I+T→T | I: EVA-CLIP ViT-G/14 | Q-Former w/ Linear Projector | Vicuna-v1.5-13B | - | - | - | - |
| X-InstructBLIP | I/V+A+T→T | I/V: EVA-CLIP ViT-G/14 | A: BEATs-3D; 3D: ULIP-2 | - | - | I: Stable Diffusion-2.1; V: Zeroscope-v2; A: AudioLDM-2 | - | - |
| CoDi-2 | I+V+A+T→T+V+A | I/V/A: ImageBind | Linear Projector | LLaMA-2-Chat-7B | MLP | - | - | - |
| RLHF-V | I+T→T | I: BEiT-3 | Linear Projector | Vicuna-v1-13B | - | - | - | - |
| Silike | I+T→T | ViT initialized from OpenCLIP’s ViT-bigG | Linear Projector | Qwen-7B | - | - | - | - |
| Lyrics | I→T | I: CLIP ViT-L/14&Grounding-DINO-T &SAM-HQ&ViT-H&RAM++ | MQ-Former w/ Linear Projector | Vicuna-13B | - | - | - | - |
| VILA | I→T | I: ViT@336 | Cross-attention | LLaMA-2-7B/13B | - | - | - | - |
| InternVL | I+V+T→T | I/V: InternViT-6B; T: LLaMA-7B | Cross-attention w/ MLP | QLLaMA-8B & Vicuna-13B | - | - | - | - |
| ModVerse | I+V+T→T | I: CLIP ViT-L/14 | Linear Projector | LLaMA-2 | MLP | I: Stable Diffusion; V: Videofusion; A: AudioLDM | - | - |
| NovelAudio | I+V+T→T | I/V: ViT-L/14 | Tiny Transformer | Vicuna-13B | - | - | 50M | 1M |
在这张表中,I——>O表示输入到输出模态,其中 I 表示图像,V 表示视频,A 表示音频,3D 表示点云,而 T 表示文字。整体各个模型详细的归纳整理了多模态大模型架构各个部分使用的各个组件,其中 #.PT 与 #.IT 指代表MM PT 与MM IT 的训练数据集规模。
LLaVA 系列(视觉指令微调)
论文名称:Visual Instruction Tuning
论文链接:https://arxiv.org/pdf/2304.08485
知乎:https://zhuanlan.zhihu.com/p/692398098

模型结构:
- **Vision Encoder:**pre-trained CLIP visual encoder ViT-L/14
- **LLM:**Vicuna
- **Projection:**a simple linear layer to connect image features into the word embedding space。不同于Flamingo的gated cross-attention,和BLIP-2的Q-former,LLaVA的映射层比较简单,好处是可以方便迭代以数据为中心的实验。
训练方法:
-
阶段一:特征对齐的预训练(Pre-training for Feature Alignment)。
-
- 冻结视觉编码器和LLM,只训练Projection层。
- 从CC3M中过滤了595K的图文对。这些图文对被改造为指令跟随数据(instruction-following data)
- 每个样本是一个单轮对话。
- 预测结果是图像的原始描述文本。
- 通过这一步,视觉编码器输出的图像特征可以和预训练的LLM的词向量对齐。这个阶段可以理解为为冻结的LLM训练一个兼容的visual tokenizer。
- 在CC-595K过滤后的子数据集上训练,epoch数量为1,学习率2e-3,batch_size为128。
-
阶段二:端到端微调(Fine-tuning End-to-End)。
-
-
冻结视觉编码器,训练Projection层和LLM。
-
两个实验设置
-
- 多模态对话机器人:利用158K语言-图像指令跟随数据对Chatbot进行了微调开发。在这三种类型的回答中,对话型是多轮交互式的,而其他两种则是单轮交互式。在训练过程中,这些样本被均匀地采样使用。
- ScienceQA数据集:ScienceQA [34] 包含了21,000个多模态多项选择题,这些问题涵盖了广泛的领域多样性,涉及3个学科、26个主题、127个类别和379项技能。这个基准数据集被划分为训练、验证和测试三个部分,分别包含12,726个、4,241个和4,241个样本。
-
在提出的LLaVA-Instruct-158K数据集上训练,epoch数量为3,学习率2e-5,batch_size为32。
-
指令数据

图像的简短描述指令

图像的详细描述指令
MiniGPT-5
我感觉最主要的创新时 Generative Vokens,用于指导图像生成 Stable diffusion 的条件输入。
https://zhuanlan.zhihu.com/p/664902742
MiniGPT-5模型主要有3大创新点:
1)利用多模态编码器提取文本和图像特征,代表了一种全新的文本与图像对齐技术,效果优于直接利用大语言模型生成视觉token的方法。
2)提出了无需完整图像描述的双阶段训练策略:第一阶段,专注文本与图像的简单对齐;第二阶段,进行多模态细粒度特征学习。
3)在训练中引入了“无分类器指导”技术,可有效提升多模态生成的内容质量。主要模块架构如下。
Generative Vokens
MiniGPT-5的核心创新就是提出了“Generative Vokens”技术概念,实现了大语言模型与图像生成模型的无缝对接。
具体来说,研究人员向模型的词表中加入了8个特殊的Voken词元[IMG1]-[IMG8]。这些Voken在模型训练时作为图像的占位符使用。
在输入端,图像特征会与Voken的词向量拼接,组成序列输入。在输出端,模型会预测这些Voken的位置,对应的隐状态h_voken用于表示图像内容。

然后,h_voken通过一个特征映射模块,转换为与Stable Diffusion文本编码器输出对齐的图像条件特征ˆh_voken。
在Stable Diffusion中,ˆh_voken作为指导图像生成的条件输入。整个pipeline实现了从图像到语言模型再到图像生成的对接。
这种通过Voken实现对齐的方式,比逆向计算要直接,也比利用图像描述更为通用。简单来说,Generative Vokens就像是一座“桥梁”,使不同模型域之间信息传递更顺畅。
Qwen-vl
Inputs and Outputs
Image Input: Images are processed through the visual encoder and adapter, yielding fixed-length sequences of image features. ( and )
Bounding Box Input and Output: <box> (Xtoplef t, Ytoplef t),(Xbottomright, Ybottomright) </box> 这种作为 Bounding Box 输入输出。此外,为了适当地将边界框与其相应的描述性单词或句子关联起来,还引入了另一组特殊标记(和),标记边界框所引用的内容。具体看下面 Caption with Grounding
预训练 finetune 具体怎么做,以 qwen-vl 为例。
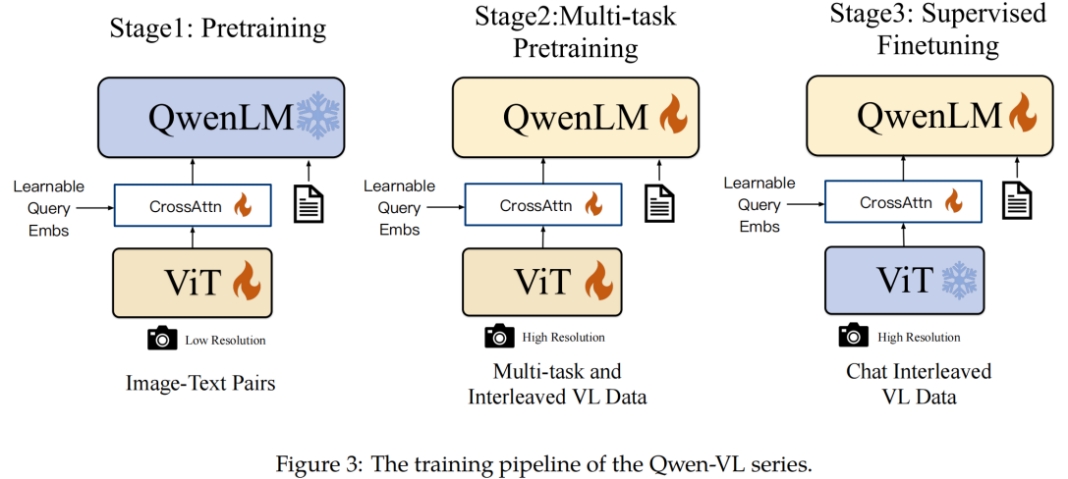
首先需要三个模块:ViT, Cross-attn adapter, LLM。训练分为三个步骤,包括两阶段 pre-train 和一阶段 Supervised Finetune 。
3.1 预训练(第一阶段)
- 数据集:使用大规模、弱标注的网络爬虫图像-文本对,包括多个公开可访问的来源和一些内部数据。
- 数据清洗:原始数据集包含50亿图像-文本对,清洗后剩余14亿数据,其中77.3%为英文数据,22.7%为中文数据。
- 模型组件:在此阶段,大语言模型(LLM)参数被冻结,只优化视觉编码器(ViT)和视觉-语言适配器(VL Adapter)。
- 输入图像尺寸:输入图像被调整至224×224分辨率。
- 训练目标:最小化文本令牌的交叉熵。
- 学习率:最大学习率为2e-4。
- 训练步骤:整个预训练阶段持续50,000步,使用30720的批次大小处理大约15亿图像-文本样本。
3.2 多任务预训练(第二阶段)
- 数据集:引入高质量、细粒度的视觉语言注释数据,并使用更高的输入分辨率和交错的图像-文本数据。
- 任务:同时训练Qwen-VL模型在7个任务上,包括图像字幕、视觉问答(VQA)、文本生成、文本定向的视觉问答、视觉定位、基于参考的定位和基于参考的字幕。
- 输入图像尺寸:视觉编码器的输入分辨率从224×224增加到448×448,以减少图像下采样造成的信息损失。
- 模型组件:解锁大语言模型,训练整个模型。
- 训练目标:与预训练阶段相同。
3.3 指令微调(第三阶段)
- 目的:通过指令微调来增强Qwen-VL预训练模型的指令跟随和对话能力,产生交互式的Qwen-VL-Chat模型。
- 数据:多模态指令调整数据主要来自通过LLM自指令生成的字幕数据或对话数据,以及通过手动注释、模型生成和策略串联构建的额外对话数据集。
- 模型组件:在这个阶段,冻结视觉编码器,优化语言模型和适配器模块。
- 数据量:指令调整数据量达到350k。
- 训练目标:确保模型在对话能力上的通用性,通过在训练中混合多模态和纯文本对话数据。
3.4 训练细节
- 优化器:在所有训练阶段中,使用AdamW优化器,具有特定的β1、β2和ε参数。
- 学习率调度:采用余弦衰减学习率计划。
- 权重衰减:设置为0.05。
- 梯度裁剪:应用1.0的梯度裁剪。
- 批次大小和梯度累积:根据训练阶段调整批次大小和梯度累积。
- 数值精度:使用bfloat16数值精度。
- 模型并行性:在第二阶段使用模型并行性技术。
- 第一阶段预训练,使用 weakly-labeled, large scale image-text pairs. 冻结 LLM 部分,只训练 Cross-attention 和 ViT 部分。这一阶段的目的是让 crossAttn 模块输入的 query token 和 text token 粗对齐。作者也进行了数据清洗,。。。
- 第二阶段预训练,使用 high quanlity and fine-grained VL annotation 数据。全部参数都进行训练,进一步增强模型 visual 和 text 对齐能力。Vit 图片分辨率增加到 448*448。任务有7个,Caption, VQA, Grounding, Grounded cap, OCR, Pure-text Auto regression (保持LLM 语言生成能力).
| Image Captioning |
|---|
<img>cc3m/01581435.jpg</img>Generate the caption in English: the beautiful flowers for design.<eos> |
冒号后是需要预测的。
| Vision Question Answering |
|---|
<img>VG_100K_2/1.jpg</img> Does the bandage have a different color than the wrist band? Answer: No, both the bandage and the wrist band are white.<eos> |
Answer 后是需要预测的。
| OCR VQA |
|---|
<img>ocr_vqa/1.jpg</img> What is the title of this book? Answer: Asi Se Dice!, Volume 2: Workbook And Audio Activities (Glencoe Spanish) (Spanish Edition)<eos> |
| Caption with Grounding |
|---|
<img>coyo700m/1.jpg</img>Generate the caption in English with grounding: Beautiful shot of <ref>bees</ref><box>(661,612), (833,812)</box> gathering nectars from <ref>an apricot flower</ref><box>(224,13), (399,313)</box><eos> |
| Referring Grounding |
|---|
<img>VG_100K_2/3.jpg</img><ref>the ear on a giraffe</ref><box>(176,106), (232,160)</box><eos> |
| Grounded Captioning |
|---|
<img>VG_100K_2/4.jpg</img><ref>This</ref><box>(360,542), (476,705)</box> is Yellow cross country ski racing gloves<eos> |
| OCR |
|---|
<img>synthdog/1.jpg</img>OCR with grounding: <ref>It is managed</ref> <quad>(568,121), (625,131), (624,182), (567,172)</quad>...<eos> |
- 第三阶段SFT,人工构造指令微调数据,目的是得到交互的 Chat 模型。之前训练的 VLLM 通常只对单个图像进行一次理解。我们构造数据让模型具有定位某一张图和多图理解能力。冻结 VIT,因为认为 visual text 已经对齐了。
这里通过 <im_start> <im_end> 来监督多轮对话。
<im_start>user
Picture 1: <img>vg/VG_100K_2/649.jpg</img> What is the sign in the picture? <im_end>
<im_start>assistant
The sign is a road closure with an orange rhombus. <im_end>
<im_start>user
How is the weather in the picture? <im_end>
<im_start>assistant
The shape of the road closure sign is an orange rhombus. <im_end>
模型结构就类似 BLIP-2,使用 Cross-attn 对 visual token 进行处理,256 个 query token 提取一张图片的信息,所有图片都被转换到 448*448 维度。Qwen 最多输入token数量2048。
Qwen2-VL
Naive Dynamic Resolution 动态分辨率:通过修改 Vit 中的 绝对位置嵌入,引入 2D-RoPE。此外,减少每个图像的视觉标记,一个简单的MLP层使用后改变压缩相邻2×2 token 成一个 token
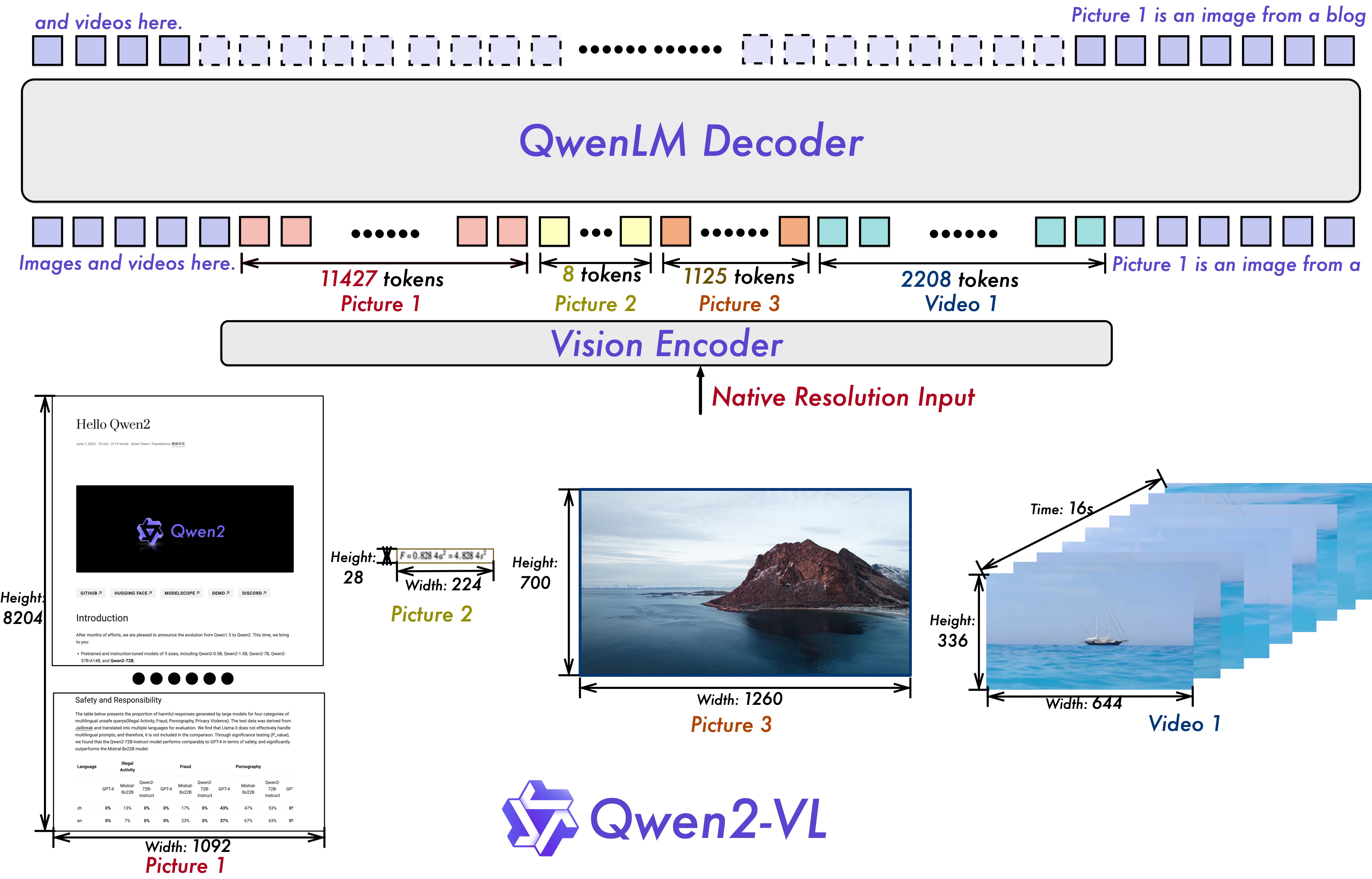
Multimodal Rotary Position Embedding (M-ROPE)

使用三个方向的 position ids,对视频进行编码。但是没有具体说公式。
Xcomposer 1.0
书生 浦语 系列
-
训练框架、流程和 BLIP-2 很相似,但是在预训练和 finetune 过程中都不冻结 LLM。
-
图文交错创作: 浦语·灵笔可以为用户打造图文并貌的文章,具体是提供文章生成和配图选择的功能。这一能力由以下步骤实现:
- 理解用户指令,创作符合要求的文章。
- 智能分析文章,自动规划插图的理想位置,确定图像内容需求。
- 基于以文搜图服务,从图库中检索出对应图片。
这些能力都是通过添加特定的指令微调数据实现。
模型结构
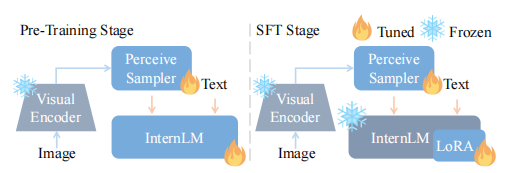
模型由三个组件构成
- 视觉编码器:EVA-CLIP (CLIP的一个改进变种,通过掩码图像建模能力增强,以有效捕捉输入图像的视觉细微差异)。输入 224x224,以 stride 14 分为小 patch 后输入 transformer
- 感知采样器(Perceive Sampler):InternLM-XComposer 中的感知采样器作为一种专注的池化机制,旨在将初始的 257个 图像嵌入压缩为 64 个经过优化的嵌入。这些优化的嵌入随后会与大型语言模型理解的知识结构相匹配。与 BLIP2 类似,使用带有交叉注意力层的 BERTbase 作为感知采样器。
- LLM:InternLM-XComposer 以 InternLM 作为其基础的大型语言模型。使用公开可用的 InternLM-Chat-7B 作为大型语言模型。
训练
InternLM-XComposer的训练过程分为 A 阶段和 B 阶段。A 阶段作为预训练阶段,利用大量数据训练基座模型。B阶段是监督微调,先做多任务训练,再做指令微调。在多任务训练后得到InternLM-XComposer-VL模型,在指令微调得到InternLM-XComposer模型。
1. Pre-training阶段:预训练基座视觉语言模型阶段利用了大量的图像-文本对(网络爬取)和交错的图像-文本数据。这些数据包括中英文两种语言的多模态数据。为了保持大型语言模型的语言能力,在 InternLM 预训练阶段使用的部分文本数据也在 InternLM-XComposer 的预训练阶段中使用。

在预训练阶段,视觉编码器参数固定,主要对感知采样器和大型语言模型进行优化。感知采样器和大型语言模型的初始权重分别来自BLIP2和InternLM。由于大型语言模型天然缺乏对图像embeddings的理解,因此在多模态预训练框架内做优化有助于提高理解这些embeddings的能力。模型的训练目标集中在下一个token预测上,使用交叉熵损失作为损失函数。采用的优化算法是 AdamW,超参数设置如下:β1=0.9,β2=0.95,eps=1e-8。感知采样器和大型语言模型的最大学习速率分别设置为 2e-4 和 4e-5,采用余弦学习率衰减策略,最小学习率设置为1e-5。此外,在最初的 200 步中使用线性预热。训练过程一个batch size中约 1570 万个token,并进行 8000 次迭代。使用如此大的batch size有助于稳定训练,同时也有助于维持InternLM的固有能力。
**2. 监督微调阶段:**在预训练阶段,图像embeddings与文本表征对齐,使大型语言模型具有初步具备理解图像内容的能力。为进一步指导模型在恰当时机使用图像信息的能力,引入了各种视觉-语言任务。所以,整个监督微调阶段,其实由多任务训练和指令微调组成。
多任务训练。多任务训练数据集如Table 2 所示,这些任务包括场景理解(例如 COCO Caption,SUB)、位置理解(例如 Visual Spatial Reasoning 数据集)、光学字符识别OCR(例如 OCR-VQA)以及开放式回答(例如 VQAv2 ,GQA)等。

交错的图像文本组合
- 为了实现交错的图像-文本组合的目标,初始步骤涉及生成以文本为中心的文章。随后,在文本内容内合适的位置插入相关图像,从而丰富整体叙述并增强读者的参与感。
文本生成

在这里,{Title}充当文章标题的占位符,而[para1]和[paraN]分别表示第一个和最后一个段落。
为了增强生成的以文本为中心的文章的视觉吸引力和参与度,需要加入与上下文相关的适当图像。为了实现这一目标,建立了一个数据库,作为图像选择的候选池。整个过程分为两个主要组成部分:
- 图像定位,用于识别文本内图像集成的合适位置
- 图像选择,旨在选择最具上下文意义的图像。图像选择的基本策略涉及总结前面的文本内容,并从可用的图像池中检索与之最相关的图像。
Image Spotting and Captioning(图像定位和生成 caption)
构造下面的训练数据

在这里,[seg1] 充当索引标记,用于确定特定段落的索引。占位符 {x1} 和 {xk} 分别代表第一个和最后一个图像位置的位置。相应地,{cap1} 和 {capk}作为与这些图像位置相关的生成字幕。
Image Retrieval and Selection(图像检索和选择)
获得了图像字幕后,就可以使用各种文本-图像检索方法。在这项工作中,我们选择了 CLIP 模型,充分利用了它在零样本分类任务中已被证明有效的能力。我们计算生成的字幕与候选池中的每个图像之间的相似性分数。基于这些相似性分数,选择前 m 个图像,以构成候选池以供进一步处理。为了确保文章中散布的图像在主题或概念上具有一致性,我们使用 Xcomposer 来执行最终的图像选择。在选择要与第 j 段一起显示的图像时,训练数据的结构如下:

参考
https://zhuanlan.zhihu.com/p/661465576
https://blog.csdn.net/ljp1919/article/details/134085575
Xcomposer 2.0
提出 Partial LoRA,预训练阶段不训练 LLM text token,训练 LLM visual token.
使用更精细的数据。
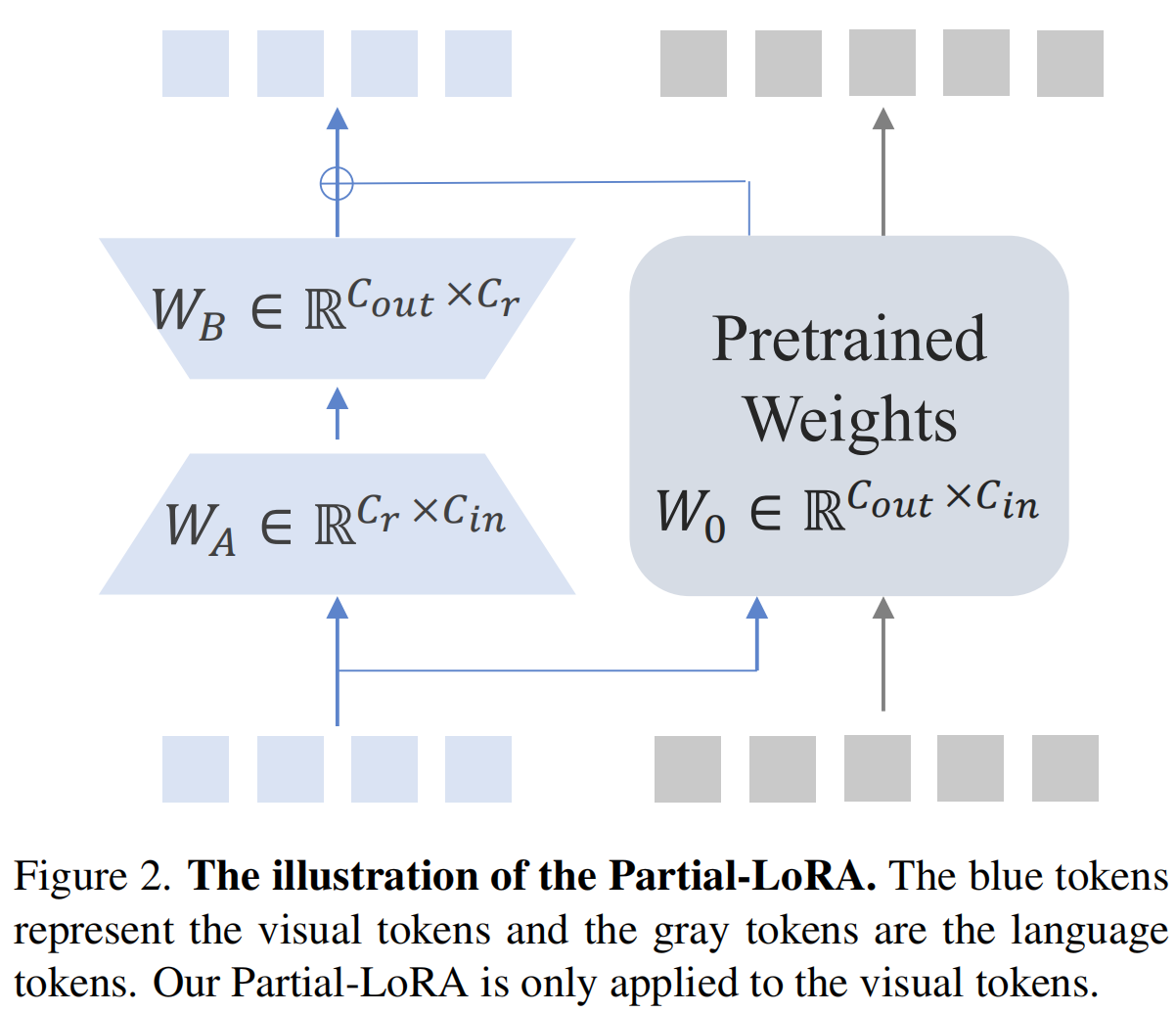
- 感觉这里也没写清楚,难道就是直接 visual token 进去,visual token 出来,模型预训练阶段任务是啥,翻译吗?
- 又读了论文,感觉是类似 BLIP-2 中的 grounding,根据 visual 预测文本,最后传梯度也只传 visual tokens?
训练
During the pre-training phase, the LLM remains constant while both the vision encoder and Partial LoRA are finetuned to align the visual tokens with the LLM。
During finetune stage, we jointly finetune the vision encoder, LLM, and Partial LoRA.
微软 202405 综述
https://blog.csdn.net/python1234_/article/details/138602341
多模态表示、融合、对齐
首先,对齐确保了不同模态间的相互关联性;
接着,融合策略决定了如何整合多模态信息;
最后,表示的好坏直接影响了最终学习任务的效果。
表示
表示涉及如何将多模态数据编码成适合机器学习任务的形式。良好的表示能够捕捉数据的内在特征和结构,对于提高学习效率和性能至关重要。
融合
有单流和多流,都是首先不同模态提取特征,区别就是在网络深层中,两种模态是否相互作用。如果提取特征后两个模态拼接,或者使用 self-attention 进行交互,那么就是单流,如果不在网络深层进行交互,就是多流。
- 早期融合(Early Fusion):在特征层面进行融合,将不同模态的特征早早地合并,以充分利用各模态的互补信息。
- 晚期融合(Late Fusion):在决策层面进行融合,即在模型输出后再结合不同模态的结果,这有助于在最终决策时综合考虑各模态的见解。
- 混合融合(Hybrid Fusion):结合早期和晚期融合的优点,可能在多个层面进行特征和决策的结合,以实现更灵活的信息整合。
对齐
- 对齐的目的总的来说,就是实现不同模态数据(如图像、文本、音频等)在特征、语义或表示层面上的匹配与对应。我从 loss, 数据, 模型 三个方面回答.
- 模型结构:
- 共同嵌入空间,将不同模态数据映射到共享的嵌入空间,使得语意相近的向量距离相近。这适用于跨模态检索。
- 注意力机制,利用注意力机制在不同模态之间建立关联。比如说模型关注图像的不同区域生成相对应文本描述。
- 跨模态 Transformer,直接将文本和视觉信息进行融合,在内部对齐。比如 BLIP-2 的 Q-former,能同时输入图片和文本 token。
- 数据的话,我们需要准备配对的数据用来训练。
- Loss 有多模态预训练任务最初常用的就是MLM、MRM和ITM,经过两年左右时间的发展,不仅MLM有不同的版本,还可以用LM和IMC(对比损失函数)。
- MLM 与bert 的MLM一致,即将文本随机mask一部分(15%),利用输入的多模态特征进行预测。
- ITM:由于输入的数据是图像-文本pair对,那么对于多模态编码器而言,输入的特征对可以是匹配的pair,也可以是不匹配的pair,这样可以再最终输出的特征层面增加一个分类器判断图像、文本是否匹配。在我的实际应用中,ITM 对效果的提升很微弱。
- MRM(Mask region modeling):MRM与MLM 类似,是对输入的图像块(可以是检测框,也可以是直接图像分块)对一部分进行mask,然后利用输入的多模态特征进行预测。MRM有不同的实现方式,对于有目标检测器的方案而言,由于有检测器的类别信息,所以可以直接利用分类器进行分类,对于没有目标检测器的方案来说,可以直接回归特征或者计算预测特征与真实特征之间的kl散度。未采用目标检测器,无论是重构特征还是计算kl散度,效果提升都很小。最近,也有人利用d-VAE首先对图像块进行编码,得到一个one-hot特征(其实就是label),而后在MRM中即使没有目标检测器的情况下也可以预测类别,猜测这种实现方式效果可能会好一些。
- LM:与GPT中的LM一致,只不过在输入的时候多了图像特征。
- IMC:对比损失函数在图像无监督领域内用得已经很广泛了,其中最著名的要属Moco系列和Simclr系列了。在多模态领域中,CLIP论文可以说是将对比损失函数成功应用了起来,并且取得了相当炸裂的效果(当然跟亿级别训练数据也有关系)。IMC其实实现起来也比较简单,即计算图像特征与文本特征的cosine相似距离,正样本对label为1,负样本对lable为0。比如ALBEF用的loss就用到了IMC,个人感觉这个loss的贡献要高于ITM和MRM。
参考:
https://cloud.baidu.com/article/3326504 多模态学习核心技术:对齐、融合与表示
多模态模型
从视觉表征到多模态大模型:https://github.com/wdndev/mllm_interview_note/blob/main/02.mllm%E8%AE%BA%E6%96%87/0.%E4%BB%8E%E8%A7%86%E8%A7%89%E8%A1%A8%E5%BE%81%E5%88%B0%E5%A4%9A%E6%A8%A1%E6%80%81%E5%A4%A7%E6%A8%A1%E5%9E%8B.md#%E4%BB%8E%E8%A7%86%E8%A7%89%E8%A1%A8%E5%BE%81%E5%88%B0%E5%A4%9A%E6%A8%A1%E6%80%81%E5%A4%A7%E6%A8%A1%E5%9E%8B
最开始大家都在做CNN,一个比较好的主干网络。
后来 Vit 出来后,证明了 Transformer 的有效性;在小规模数据上,CNN 由于具有偏置,平移不变等,性能可能相对好,但是 Transformer 的大规模预训练,之后的通用性能要远高于 CNN 系列。
CLIP
CLIP模型是OpenAI 2021发布的多模态对齐方法。与OpenAI的许多工作类似,CLIP强调强大的通用性和Zero-Shot能力,也因此至今仍有很强的生命力,相关技术被广泛应用。
CLIP 之前的模型都是预训练,然后再做分类,物体识别这些,但是 CLIP 通过预训练期间跨模态对齐,显示出很好的通用性。
一些面试题
对于非常大的图片,如何去处理?
高分辨图片,如何进行处理?
- 我回答第一种是类似 qwen-vl M-ROPE 进行编码处理;这样可以原生支持任意分辨率的图片。
- 第二种就是很多工作尝试,全局和局部信息,大图片首先分成多个小图片,然后提取小图片的信息作为局部表征,同时也对大图片压缩,提取压缩后的大图片特征,作为全局表示。
- 第三种就是,直接进行划分,然后小图片信息进行融合。
Qwen-vl
Mini-CPM 2.5
总的来说,就是把图片进行切分,然后让切分得到的 image block 最好和 448*448 比较接近,这样放到 Vit 中处理
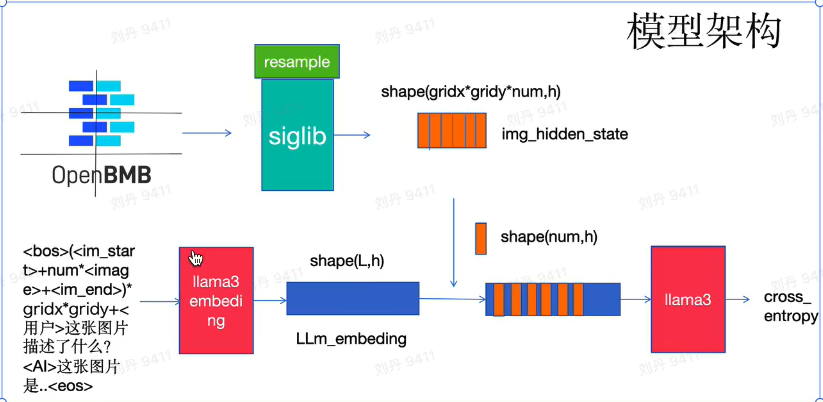
算法原理与流程
-
首先将图像像素 (
w*h) 规模以448*448,估算大致切分次数。 -
根据原始图像的高宽比,确定 patch_size(patch_size 为切分后的子图的长宽,尽量与预训练长宽比差不多)和切分次数 num_slice,原始图像要进行线性插值的缩放以保证接上目前的 patch_size,能够进行完整的切分(后期开新切分)。
-
将图像进行切分,并且每一个 patch 进行位置标记后编号,并且加上特殊字符:
<im_start> + <unk_token> + num + <im_end>
其中 num 代表一张子图在最终的语言模型中使用多少个 token 进行表示,
<unk_token>代表占位符号,后期将被图像特征替换。
<im_start>、<im_end>分别为图像边界起始和末尾分隔 token。

以上图片被切分为六次后,将会变成 6 个连续的 <im_start> + <unk_token> + query_nums + <im_end>,并且六个子图都会作为 patch 保存在下。
-
将文字按照一般 llm 的拼接成文本,如下样本:
问:这张图片描述了什么?
答:这张图片是 openbmb 的 logo,openbmb 是面壁智能和清华 thunlp 实验室的联合实验室。
处理成:
<用户>这张图片描述了什么?<AI>这张图片是 openbmb 的 logo,openbmb 是面壁智能和清华 thunlp 实验室的联合实验室。 -
将以上文本转为 id 和之前的图像 id 们进行拼接,获得最终输入:
im_text_hold_id = bos_id + (<im_start> + <unk_token> * num + <im_end>) * num_slice + tokenizer.encode('<用户>这张图片描述了什么?<AI>这张图片是 openbmb...实验室') + eos_id以
im_text_hold_id形式就是最终输入语言模型的 token_id,其中 bos_id 和 eos_id 分别代表语言模型的文字起始符和结束符。num 表示一张子图(patch)占用多少个 token。
-
将
im_text_hold_id输入语言模型 LLM 的 embedding 层,获得 llm_embedding: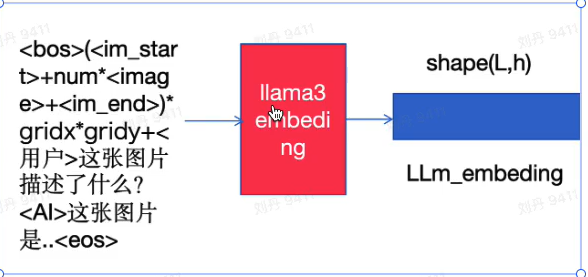
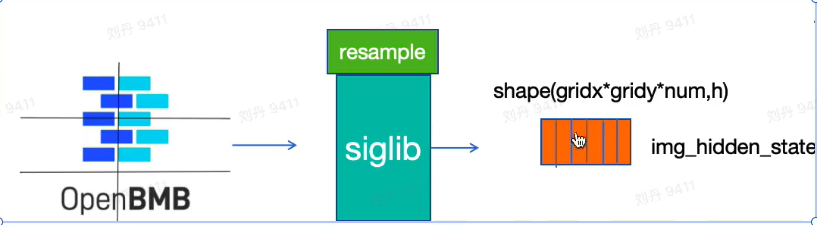
7.将所有子图patch按照顺序放入 siglip 和 resample 模块提取特征img_hidden_state:
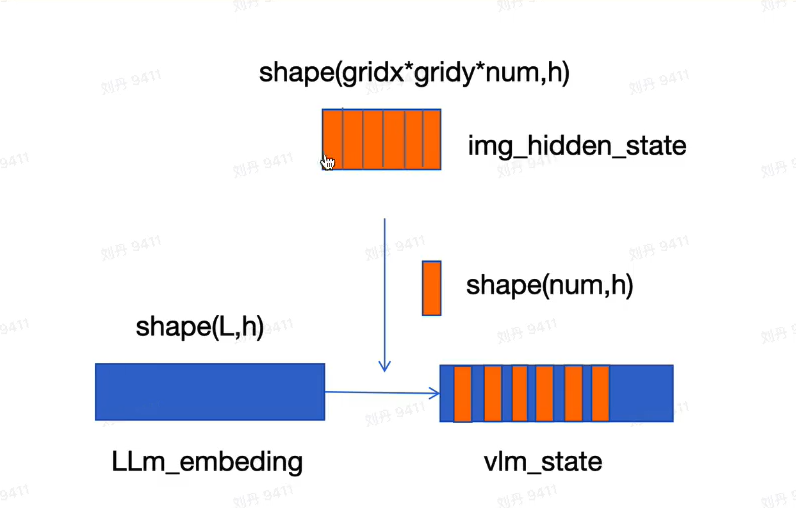
8.将img_hidden_state替换掉LLm_embeding中unk_token对应位置的向量,融合图像特征,获得vlm_state
9.进行前向传播以及反向传播,最终架构图如图所示
参考:https://www.bilibili.com/video/BV1rz421z7dT
对于视频采样帧,如何处理?
最开始是密集采样,一个两分钟的视频能够采样120帧。
后来使用 稀疏采样,首先对视频划分片段,然后每个片段选取一帧,以及相应的光流信息。
如何对图像进行聚合?
说我过去可能主要是做多模态大模型的视频处理部分,如何对图片进行聚合。我感觉可以介绍一下之前的一些之前的一些工作。
- 最简单的就是把每个视频帧输入MLLM.
- 可以尝试 GVT (mm23 chinaopen),使用一个 visual token reduction,只选取前后片段的所有 token,中间帧都用 cls token。
原文地址:https://blog.csdn.net/qq_44761480/article/details/143814829
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!