【Selenium】基于 WebDriverWait 爬取带有懒加载的静态页面
0x00 前言
朋友做标书,需要用到每日温度,他的老板让在这个网页手动复制做一个长期表出来:http://www.tianqihoubao.com/lishi/nanjing/month/202412.html
想着帮个忙,做个爬虫脚本吧,忽然发现这个页面很有意思:
- 简单的 BeautifulSoup4 只能爬到主要信息还没有加载时的页面内容
- 网页返回信息的时间上下限非常久,快则3秒慢则30秒
- 流式一行一行渲染,简单 wait 会很容易只获取一半就截断了
0x01 驱动准备
我的 Chrome 是 133.x 版本的,由于 114.x 之后的版本就不在原先的页面更新了,还挺难找的。
现在的 ChromeDriver 可以到这里下载:
https://googlechromelabs.github.io/chrome-for-testing/#stable
0x02 源码分享
# coding: utf-8
# ==========================================================================
# Copyright (C) since 2024 All rights reserved.
#
# filename : web_spider_eye_selenium.py
# author : chendian / okcd00@qq.com
# date : 2024/12/08 00:33:33
# desc : Download the driver in https://googlechromelabs.github.io/chrome-for-testing/#stable
#
# ==========================================================================
import time
import json
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class WebSpiderSelenium():
def __init__(self):
self.options = Options()
self.options.headless = True # 设置无头模式(不弹出浏览器窗口)
# 设置 ChromeDriver 路径
driver_path = './chromedriver_131.exe' # 修改为你自己的 ChromeDriver 路径
service = Service(driver_path)
# 初始化 WebDriver
self.driver = webdriver.Chrome(service=service, options=self.options)
def scrape_table_content_with_selenium(self, url, css_selector):
try:
self.driver.get(url)
# time.sleep(5) # 可以根据实际情况调整等待时间
# 等待目标元素加载完成(最长等待10秒)
target_element = WebDriverWait(self.driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, css_selector))
)
return target_element.text.strip()
except Exception as e:
return f"发生错误: {e}"
def scrape_table_content_with_selenium_wait(self, url, css_selector):
# 配置 ChromeOptions
try:
# 打开网页
self.driver.get(url)
# 等待页面加载完成
time.sleep(5) # 可以根据实际情况调整等待时间
# 使用选择器定位到目标元素
target_element = self.driver.find_element(By.CSS_SELECTOR, css_selector)
# 获取并返回目标元素的文本内容
return target_element.text.strip()
except Exception as e:
return f"发生错误: {e}"
def crawl_weather():
# 示例
results = {}
css_selector = "#content > table > tbody" # 指定选择器
wss = WebSpiderSelenium()
# for date in ['202308', '202309', '202406', '202408']:
for year in ['2023', '2024']:
for month in [f"{i:02d}" for i in range(1, 13)]:
date = f"{year}{month}"
url = f"http://www.tianqihoubao.com/lishi/nanjing/month/{date}.html" # 替换为实际的目标 URL
result = wss.scrape_table_content_with_selenium(url, css_selector)
results[date] = str(result)
json.dump(results, open('./南京近两年天气.v2.json', 'w'), ensure_ascii=False, indent=1)
def analysis_results():
results = json.load(open('./南京近两年天气.v2.json', 'r'))
import pandas as pd
ret = []
for month, text in results.items():
lines = text.split('\n')[1:]
for line in lines:
items = line.split()
date, l, h = items[0], items[3], items[5]
ret.append({"日期": date, "最低温度": l, "最高温度": h})
pd.DataFrame(ret).to_excel("./南京近两年温度情况.xlsx")
if __name__ == "__main__":
crawl_weather()
analysis_results()
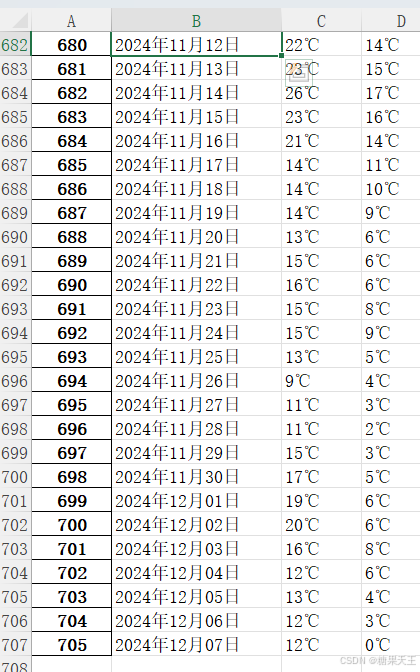
0x03 效果展示
朋友只需要温度信息,如果需要更多,在 items 里拼就行
欢迎大家举一反三用于其它爬虫场景。
原文地址:https://blog.csdn.net/okcd00/article/details/144320084
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!