AutoMQ 如何在 AWS 上避免 Kafka 跨 AZ 网络传输费用
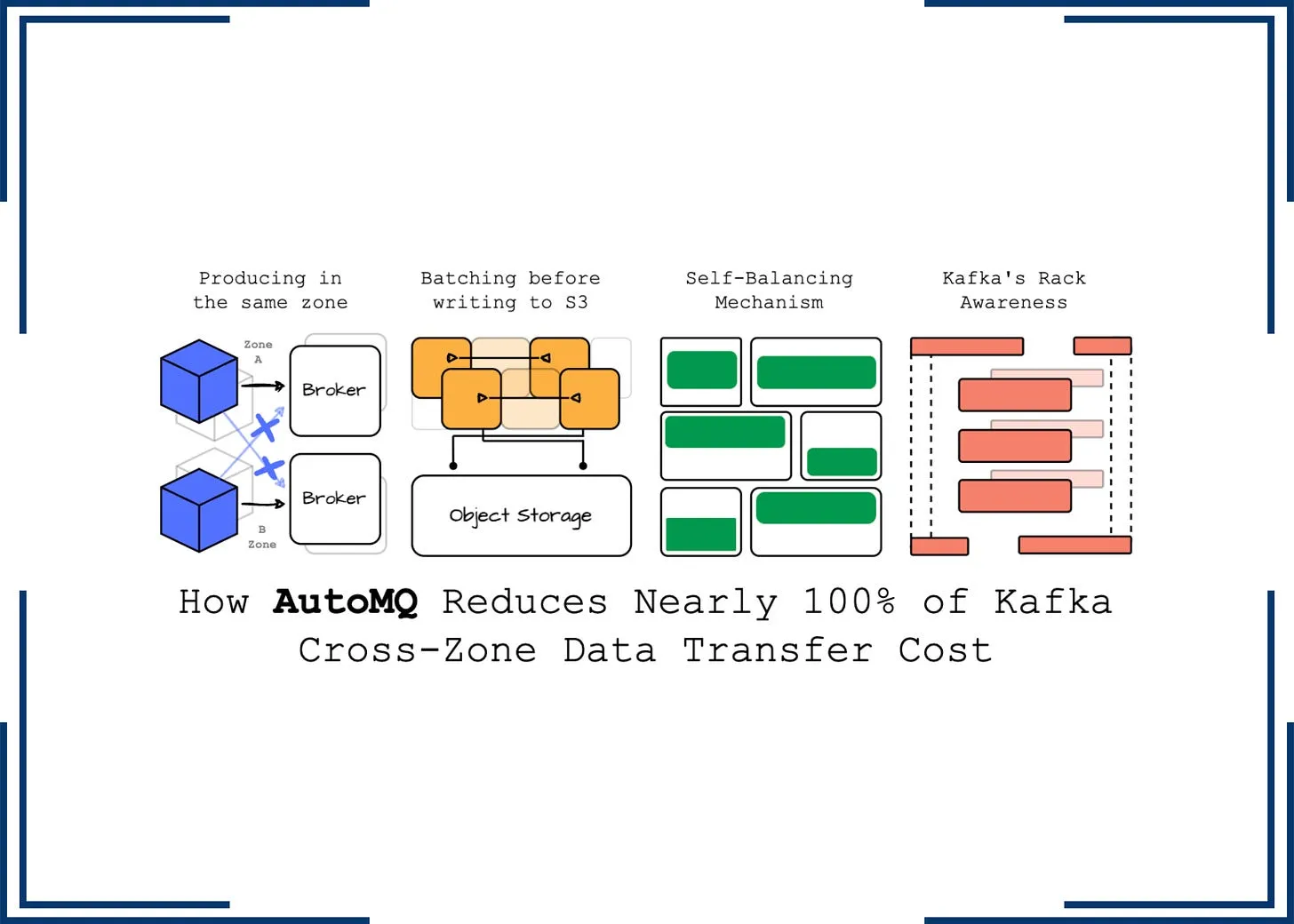
文章导读:AutoMQ与海外开发者一起深入剖析了关于 Apache Kafka 在云计算环境下的操作和挑战,特别是在跨可用区(AZ)传输中的高成本问题。分析了 AutoMQ 如何通过优化服务发现,确保客户端始终与同一 AZ 的 broker 通信,从而有效避免跨 AZ 的传输成本;利用 Kafka 代码库进行协议处理并重新设计存储层,优化了 Kafka 在云环境中的使用成本。
介绍
Apache Kafka,作为一种广泛使用的消息或流系统,已经成为很多技术人员的关注焦点。其多功能性和可扩展性使其在各种公司的基础设施中占据一席之地。然而,也有用户反映在使用 Kafka,特别是在云计算环境下,会遇到操作困难等问题。当将 Apache Kafka 部署到云环境时,Replication Factor (RF) 会导致数据在不同可用区(AZ)之间分发,这可能会导致计算和存储成本的增加。根据 Confluent 的数据,跨 AZ 的传输成本可能占据总费用的 50% 以上。然而,最近发布的 WarpStream 文章指出,通过优化服务发现,WarpStream 能保证客户端始终与同一 AZ 的 broker 通信,从而有效地避免了跨 AZ 的传输成本。WarpStream 对 Kafka 协议的优化起到了关键作用。
本文将深入探讨 AutoMQ,这是一个 100% 兼容 Kafka 的替代产品,它能有效地降低跨 AZ 数据传输成本。AutoMQ 利用 Kafka 代码库进行协议处理,并重新设计了存储层,有效地将数据卸载到包含 WAL 的对象存储,从而优化了 Kafka 在云环境中的运行效率。本文将从以下几个方面进行深入讨论:首先,我们会回顾 Confluent 对 Apache Kafka 的理解;其次,我们会概述 AutoMQ 的特性;最后,我们会探讨 AutoMQ 如何帮助降低数据传输成本。
Cross AZ cost
Apache Kafka 最初是为满足 LinkedIn 大规模日志处理需求而诞生的。通过优化以利用页面缓存和磁盘顺序访问模式,Kafka 实现了高吞吐量同时保持了系统的简洁性。这主要是因为系统将大部分与存储相关的工作交给了操作系统。Kafka 通过数据复制来实现持久化,一旦消息被写入 leader 分区,就会被复制到跟随者分区。初始阶段,Kafka 运行在自托管的数据中心,基础设施团队并未考虑到向各数据中心的跟随者分区复制消息时的网络成本。然而,当 Kafka 迁移到云端时,复制过程的复杂性增加了。leader 需要将数据复制到不同可用区的跟随者,以应对可能的故障并确保数据可用性,这导致了跨区数据传输的额外费用。根据 Confluent 的观察,自我管理 Apache Kafka 的基础设施成本中,跨可用区数据传输成本可能占比超过 50%,这可能比预期的还要高。
考虑一个位于三个可用区的 Kafka 集群示例。假设一可用区的 broker 发生故障,其余两个 broker 仍可保持服务运行。在优化良好的集群配置中,应均匀地在三个可用区分配分区 leader,以确保大约有三分之二的时间,生产者将数据写入其他可用区的 leader。
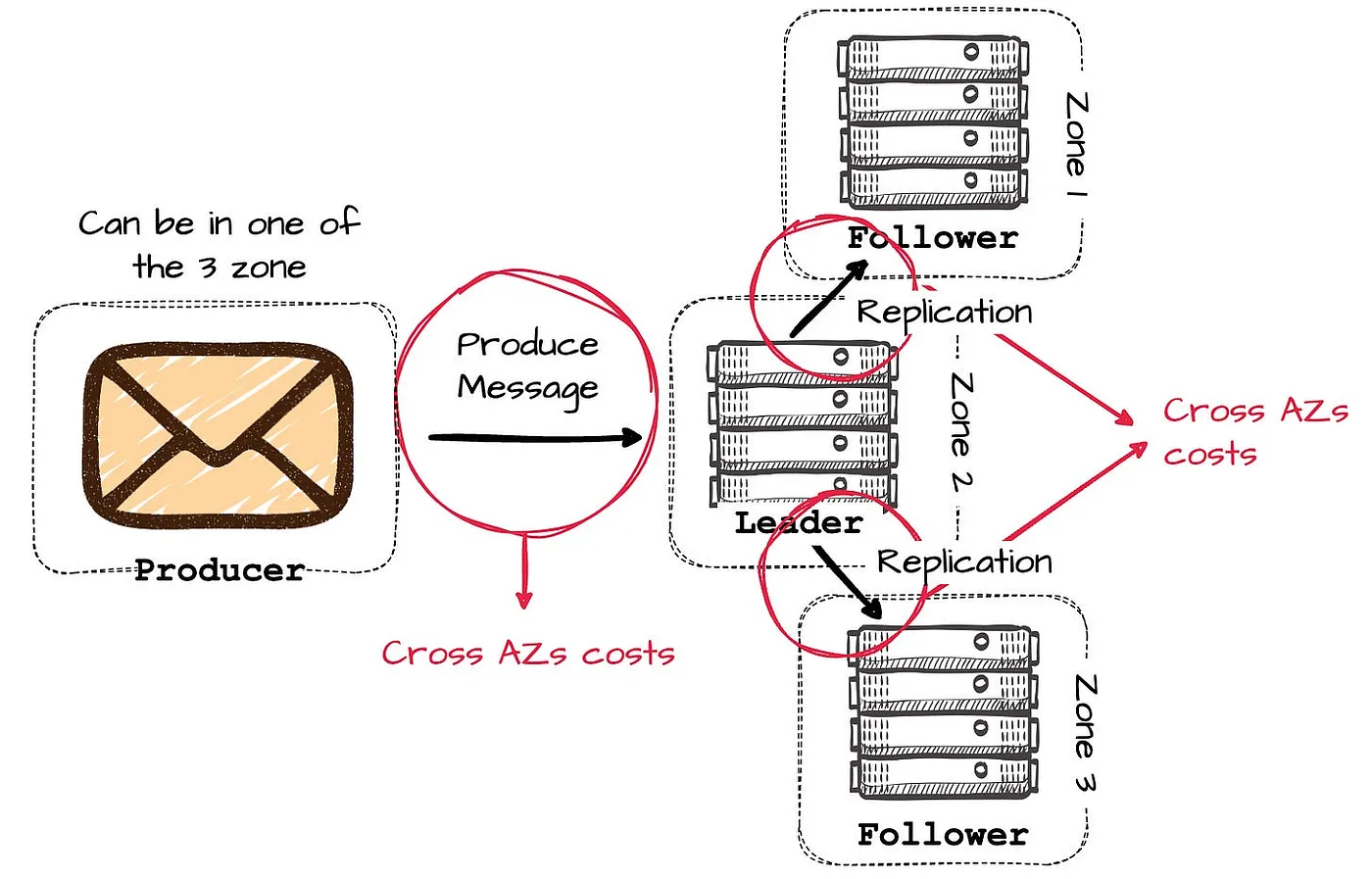
接收消息的 leader 将数据复制到其它可用区的 broker,以保证数据可靠性,这将使初始生产请求的跨可用区流量翻倍。
Apache Kafka 的多可用区(AZ)部署模型在 AWS 中,将产生至少(2/3 + 2)倍的跨 AZ 数据流量费用,其中每 GB 数据流入和流出的费用分别为 $0.01。
计算过程中未纳入消费者跨可用区(AZ)的成本因素。
采用三个 r6i.large(2 核心 - 16GB RAM)broker,可实现 30MiB/s 的写入吞吐量。在此设定下,Apache Kafka 的每月跨可用区(AZ)流量费用可通过如下方式计算:
30 \ 60 * 60 * 24 * 30 / 1024 * (2 / 3 + 2) * 0.02 = $4050*
相比之下,虚拟机的成本仅为 3 * 0.126 $/h(r6i.large 单价)* 24 * 30 = $272,仅占跨可用区流量成本的 6.7%。
接下来,我们将深度探讨 AutoMQ 在降低跨可用区(AZ)成本方面的实践。首先,让我们快速了解一下 AutoMQ 的基础概念。
AutoMQ 概述
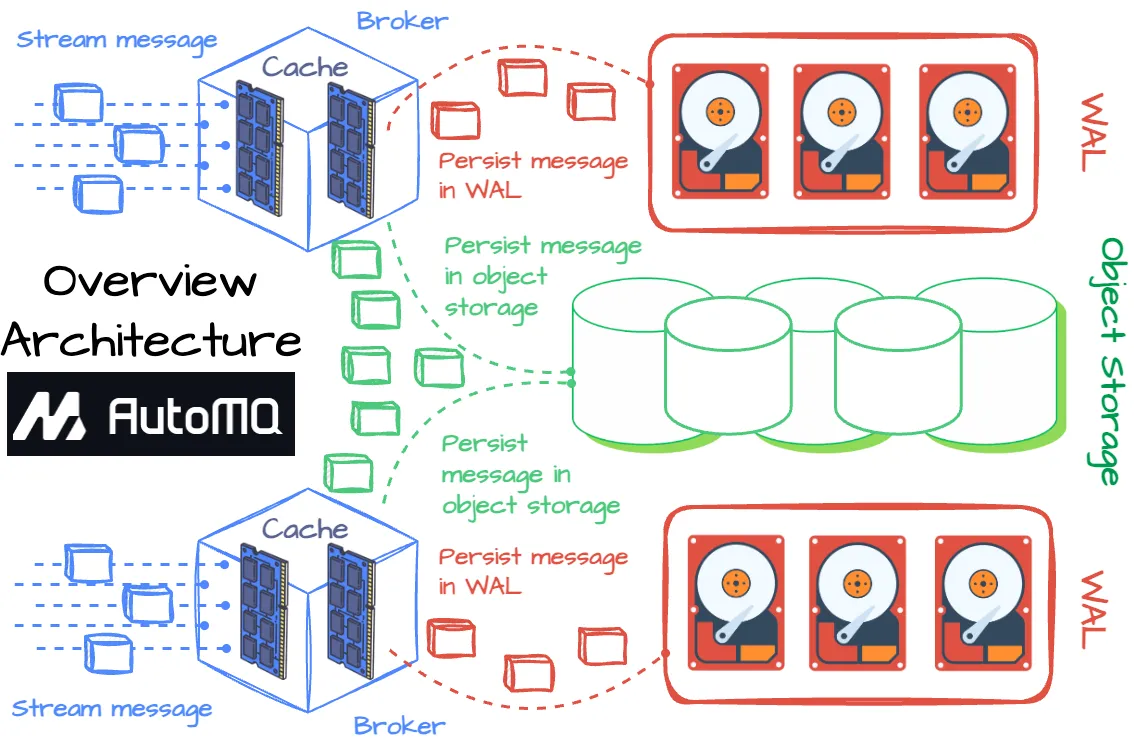
AutoMQ 目标是提高 Kafka 的效率和弹性,通过将所有消息持久化到对象存储,同时确保性能不受影响。
AutoMQ 实现目标的方式是整合 Apache Kafka 的计算和协议代码,并采用共享存储架构取代 Kafka broker 的本地磁盘。精简来说,AutoMQ broker 先将消息写入内存缓存,随后,为确保数据持久性,需要在异步向对象存储传输消息前,将数据录入 WAL 存储。
Write-ahead log (WAL) 是一种 append-only 磁盘结构,专为系统崩溃和事务恢复设计。在更新数据库前,先在 WAL 中记录变更,从而确保数据的一致性和可靠性。
AutoMQ 利用堆外缓存内存层处理所有消息读写,以确保实时性能。EBS 设备作为 AutoMQ 的 WAL,在接收消息后,消息将被写入内存缓存,只有在消息成功持久化到 WAL 后,确认才会被返回。若 broker 发生故障,EBS 将用于数据恢复。
AutoMQ 的所有数据均存储于 AWS S3 或 Google GCS 的对象存储中。该系统的 broker 会异步地将日志缓存中的数据写入对象存储。在元数据管理方面,AutoMQ 采用了 Kafka 的草稿模式。
AutoMQ 的 WAL 提供了显著的灵活性,允许根据特定应用场景选择适合的存储方案。例如,随着 AWS 推出新一代磁盘设备,用户能够顺畅迁移至新的存储方案,从而优化 AutoMQ 性能。
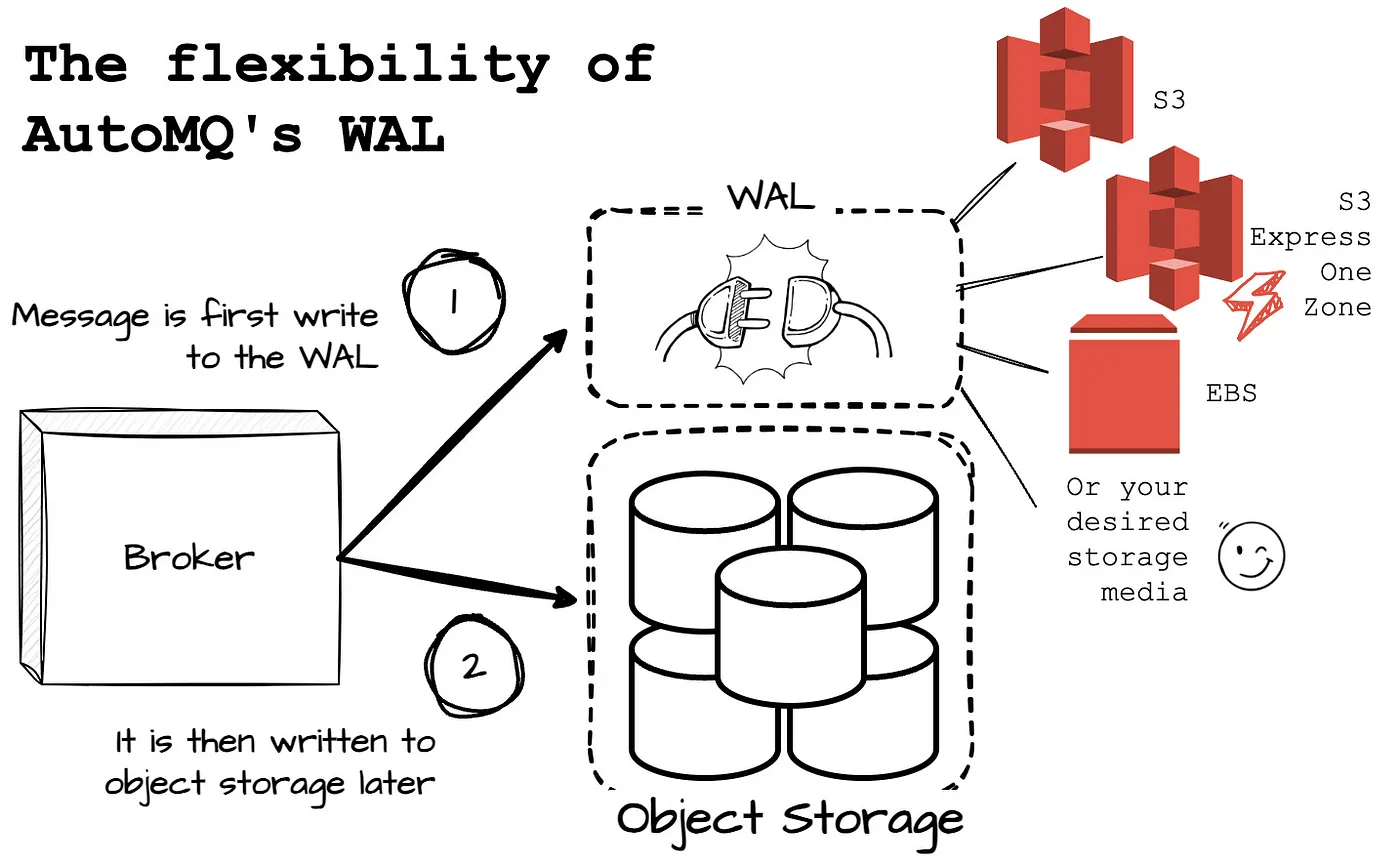
接下来,将详述 AutoMQ 如何利用 S3 作为 WAL,实现了一种创新的解决方案,成功将跨 AZ 成本减少了近 100%。
优化跨 AZ 流量成本
写入过程
利用 EBS WAL,虽然跨 AZ 数据传输的成本无法完全避免,但由于 AutoMQ 在 S3 中持久化数据,从而省去了 Broker 间的复制操作,大大降低了网络成本。然而,若生产者向主分区推送消息,仍需要承担跨 AZ 数据传输的费用。
AutoMQ 提供的解决方案通过利用 S3 实现 WAL,消除了跨可用区(AZ)的数据传输成本。此方案允许 broker 直接写入数据至 S3,而不需先落地到 EBS,确保生产者只需发送消息至同一可用区的 broker。
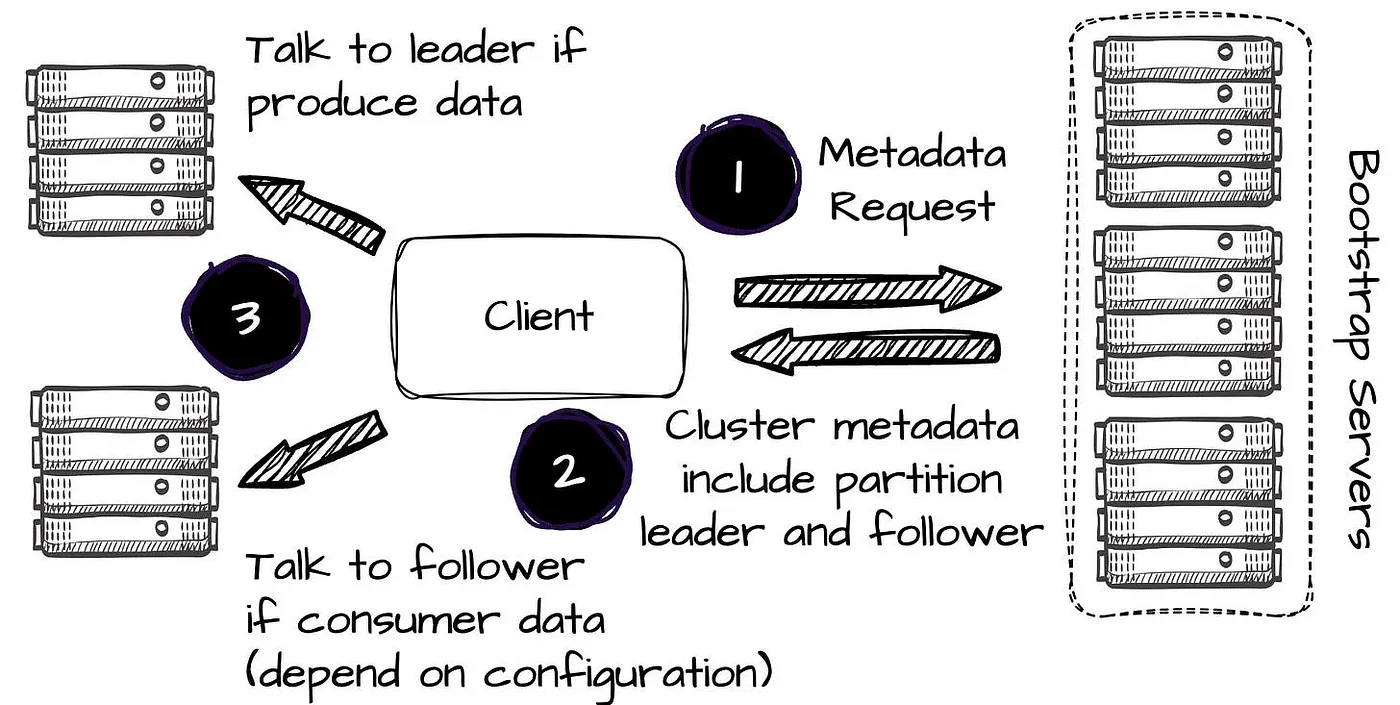
在 Kafka 中,生产者通过发送元数据请求至引导服务器,获取包含分区 leader broker 等元数据,进而传输消息。在数据生产过程中,客户端始终尝试与指定 topic partition leader 进行通信。
在 Kafka 中,所有写操作均由 leader 执行。
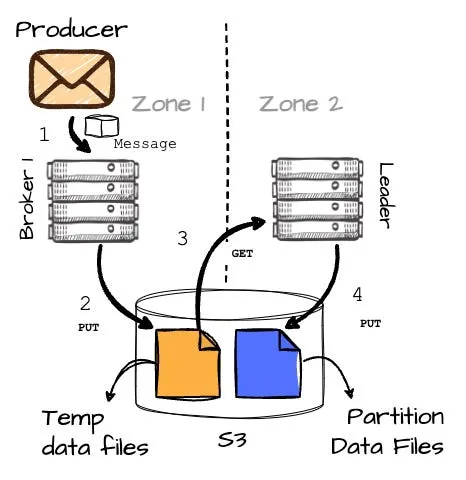
在 AutoMQ 的 S3 WAL 中,流程略有变化。设想这样一个场景:生产者位于 AZ1,而分区 2(P2)的 broker(B2)在 AZ2,同时 AZ1 也存在一个 broker 1(B1)。下面来详细探讨该模式下的消息生产过程。
在生产者尝试向 P2 写入时,首先会向一组 bootstrap brokers 发送元数据请求。这个过程中,生产者需要包含其所在可用区(AZ)的信息,此例中为 AZ1。
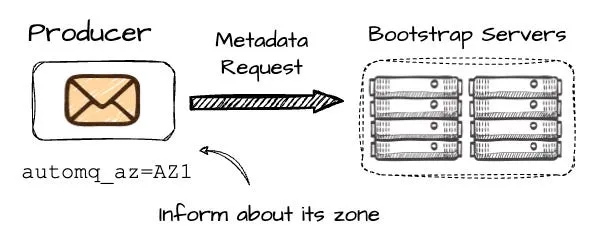
在 Kafka 中,一旦生产者发出元数据请求,可能接收到位于不同 AZ 的 broker B2 的信息,可能引发跨 AZ 的额外费用。AutoMQ 的设计目标则是规避此类情况。
- 在 AutoMQ 中,broker 通过一致性哈希算法映射到不同的 AZ。例如,假设 AutoMQ 映射 AZ2 的 B2 到 AZ1 的 B1。当 AutoMQ 确定生产者 Pr1 在 AZ1(基于元数据请求),它返回 B1 的信息。若生产者与 B2 同在一个 AZ,AutoMQ 返回 B2 的信息。这样,生产者始终与同一 AZ 的 broker 通信,从而有效地避免了跨 AZ 通信。
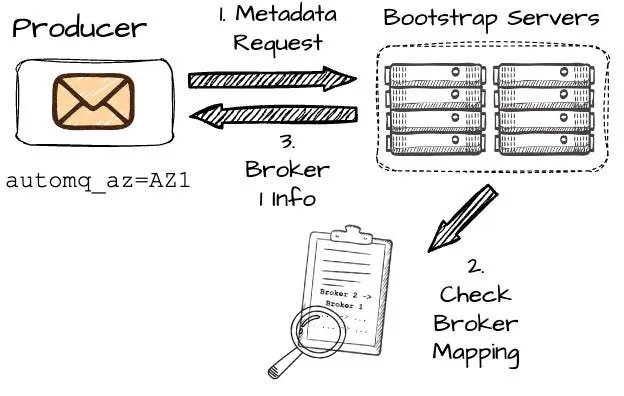
一旦接收到关于 Broker B1 的信息(请注意,B1 并非所需分区的主管),生产者将开始向 B1 传送消息。
B1 将消息在内存中进行缓存,当累计到 8MB 或超过 250ms 时,会将这些缓存的数据写入对象存储,作为临时文件。

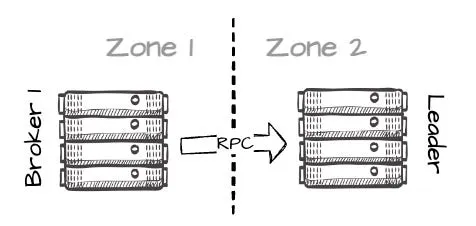
- 在成功写入 S3 消息后,情况进一步演变:B1 发起 RPC 请求至 B2(分区的主导者),传递临时数据信息,包括其位置。这将在不同 AZ 间的 leader 之间产生有限的跨 AZ 流量。
- B2 读取临时数据并追加至目标分区(P2)。完成分区数据写入后,B2 对 B1 进行响应,最后 B1 向生产者发送确认消息。
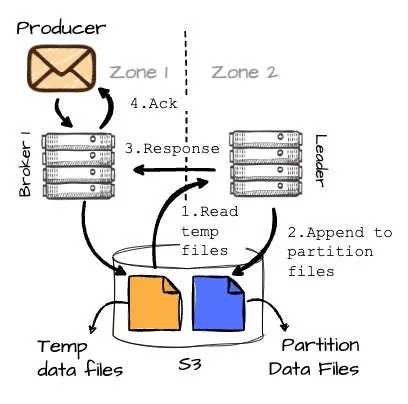
以下图解有助于理解整个流程:

此方法彻底削减了跨 AZ 的数据传输成本,但需要配置比 EBS WAL 更多的虚拟机实例(broker)。这与云中的虚拟机和网络吞吐量限制直接相关。相较于 EBS WAL,必须从 S3 中获取更多的数据,进而占用虚拟机的网络带宽。换言之,S3 WAL 需要更多的虚拟机以处理额外的网络吞吐量,以保证与 EBS WAL 相等的读写性能。
消费路径
在消费路径上,AutoMQ 与 Kafka 的流程高度同步。由于具有完全的 Kafka 兼容性,AutoMQ 消费者可以利用 Kafka 的机架感知功能来消费数据,确保数据从同一可用区的 broker 获取。AutoMQ 利用其内部自我平衡机制,通过机架感知分区调度功能来平衡不同可用区(AZ)broker 之间的分区分布,这是消除跨 AZ 成本的关键元素之一。虽然 Apache Kafka 提供机架感知功能,但仍无法完全避免跨 AZ 数据流量。为了减少跨 AZ 流量费用,Apache Kafka 在所有操作,如扩容、分区迁移等,都需要保持跨 AZ 分区的均衡。AutoMQ 的自我平衡机制可以自动管理这些操作,保证流量均衡,且在系统故障时可自我恢复,这对于减少跨 AZ 流量费用至关重要。
观察发现
针对不同场景,选择最适宜的 WAL 实现方案。例如,在延迟敏感应用如反欺诈、金融交易或实时数据分析中,EBS WAL 是首选。对于延迟非首要关注的应用,S3 WAL 能有效降低成本。WAL 在 AutoMQ 中发挥关键作用,其可插拔设计让用户无缝集成如 S3 Express One Zone 等先进云存储选项。这让 AutoMQ 能充分利用各类云存储解决方案,适应多元化场景。利用 WAL 抽象化,AutoMQ 高效地利用云存储媒介优势,体现了其"适应所有"的核心理念。
总结
本文探讨了在云环境下运行 Apache Kafka 可能导致跨多个可用区的高成本问题,主要来源于生产者到各可用区域 leader 的流量及 broker 间数据复制需求。感谢阅读。
参考资料
[1] With the help of Kaiming Wan, Director of Solutions Architect & Lead Evangelist @ AutoMQ
[2] AutoMQ official documentation
[3] AutoMQ blog
原文地址:https://blog.csdn.net/AutoMQ/article/details/144406421
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!