大语言模型与图结构的融合: 推荐系统中的新兴范式
LLMs与图结构的融合:推荐系统中的新兴范式
一、简介
随着大语言模型(LLMs)的不断发展,如何进一步利用LLMs来增强推荐效果成为了一大研究热点。传统推荐系统生成用户/项目嵌入表示主要依赖用户行为数据,可能会忽略与用户和项目相关的丰富文本信息。本文从如何有效利用用户/项目的文本属性出发聚焦于两项最新工作:RLMRec和GacLLM,展示了如何利用LLMs来理解并优化文本信息和去噪。
二、Representation Learning with Large Language Models for Recommendation(WWW 2024)
大多数传统的基于图的推荐系统仍然依赖于ID数据,而往往忽略了用户和项目的文本信息。此外,许多推荐系统使用隐性反馈数据,这可能会引入噪声和偏差,影响用户偏好学习的准确性。针对上述挑战,RLMRec框架提出了一种新的推荐范式,将LLMs的语义表示能力与传统ID推荐系统结合。首先生成用户和项目的文本画像和协同关系表示,之后通过互信息最大化方法,对齐LLMs的语义空间与协同关系表示,减弱噪声干扰,提升表征质量。
2.1 基于推理的画像生成模块
该模块用于为用户和项目生成画像。首先,系统会设计一个系统提示(System prompt),其中详细定义生成用户或项目画像的目标。这种提示引导大语言模型在生成画像时展示推理过程,避免“幻觉”现象。
项目画像生成:从项目的文本信息中提取内容,如项目标题、原始描述以及用户评论。根据是否存在描述文本,系统会组织相应的输入格式,若缺失,则随机选取用户评论的子集作为描述文本输入。
用户画像生成:借助用户与项目的交互记录,通过已经生成的项目画像来推断用户的偏好。具体来说,首先从用户交互的项目中抽样,然后将这些项目的文本属性和用户对这些项目的评论整合到一个特定格式的输入里面,让LLMs生成一个包含用户真实的偏好表达的用户画像。
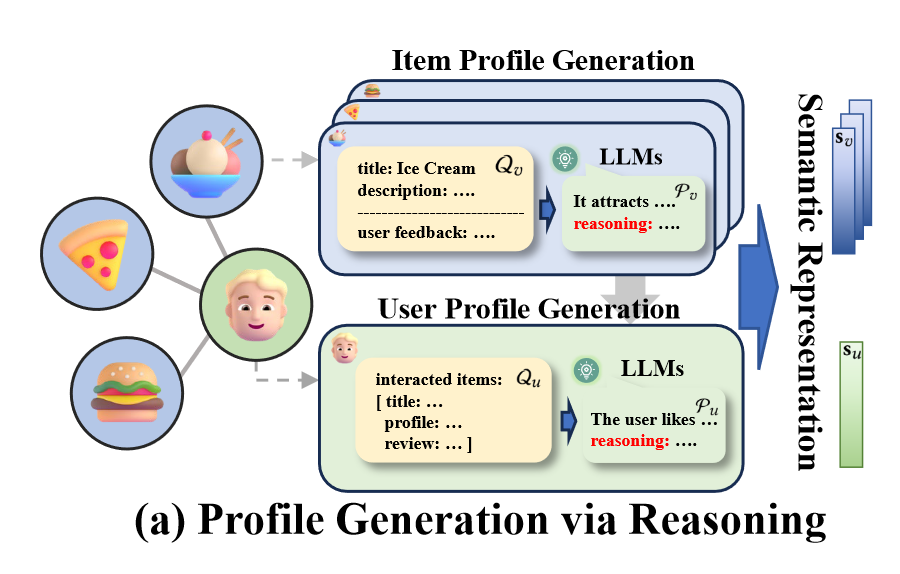
图1. 基于推理的画像生成模块
其中,和分别是项目和用户的文本信息,和代表了项目画像和用户画像,和代表了用户画像嵌入和项目画像嵌入。
2.2 对比对齐模块
对比对齐模块的核心是通过对比学习来对齐LLMs生成的语义表示和协同过滤模型的协同关系表示,确保在不同视角下学习到一致的用户和项目嵌入。
具体实现上,定义一个相似度函数(余弦相似度)来度量LLMs生成的语义嵌入与协同过滤模型嵌入的相似性。然后,通过引入对比损失,鼓励正样本对,即实际交互的用户和项目的表示在嵌入空间中更接近,而负样本对则被拉远。本文研究目标即找到满足在先验信念z和文本信息条件下联合概率期望最高的协作嵌入。
其中为协同嵌入,为文本嵌入,为先验信念(通过引入隐藏的先验信念z从而帮助模型结合外部知识识别真实的用户兴趣样本,减少噪声的影响)。
之后问题经过公式推导,将找到使得联合概率期望最高的嵌入e问题转化为如何得到如何最大化互信息度I的问题
再通过寻找互信息度下限并使之最大化,再将问题转化为寻找用于衡量两个不同表征之间的相似度的密度比f(s,e)的最大值问题。
其中为用户/项目i的协同嵌入,为用户/项目i的文本嵌入,为用户/项目i对应的负样本对,即未产生交互记录的项目/用户,密度比f(s,e),函数 sim(·) 表示余弦相似度,而 σ↓ 表示将语义表示映射到的特征空间。
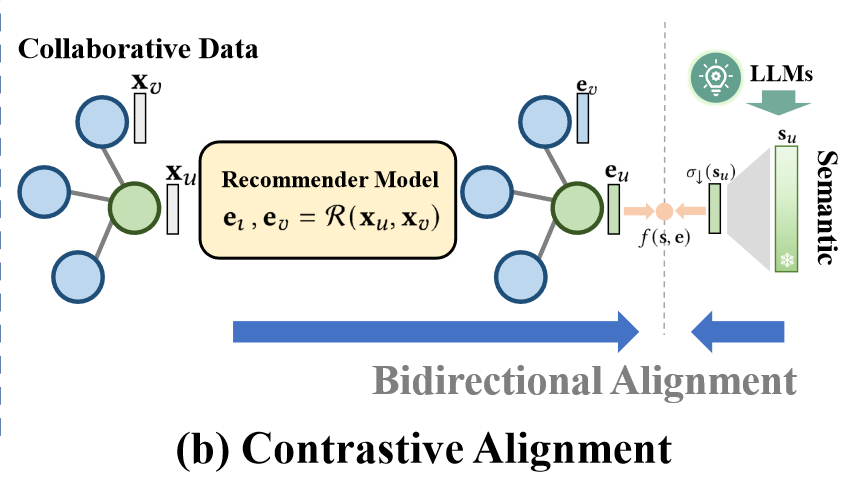
图2. 对比对齐模块
其中和是用户和项目的初始特征表示,和是用户和项目的协作关系表示,f(s,e)代表密度比。
2.3 生成对齐模块
生成对齐模块的核心在于通过单向的重构过程,将推荐模型生成的协同关系表示与大语言模型(LLMs)生成的语义表示对齐,从而在语义和协同关系两个视角下获得一致的用户和项目嵌入。
具体实现上,首先对一部分节点进行掩码操作,屏蔽掉节点的初始特征表示,再通过协同过滤方法生成用户和项目的嵌入表示,之后将协同关系表示与语义表示进行对齐,最大化密度比f(s,e),学习语义空间中的丰富知识,最后对屏蔽的节点进行重建。
其中代表文本嵌入,代表未被屏蔽的协同嵌入,𝜎↑代表将协同嵌入映射到的特征空间。
通过这种生成对齐机制,模型在协同表示的基础上融入了语义层面的信息,确保嵌入空间内的用户和项目表示在语义上保持一致性。
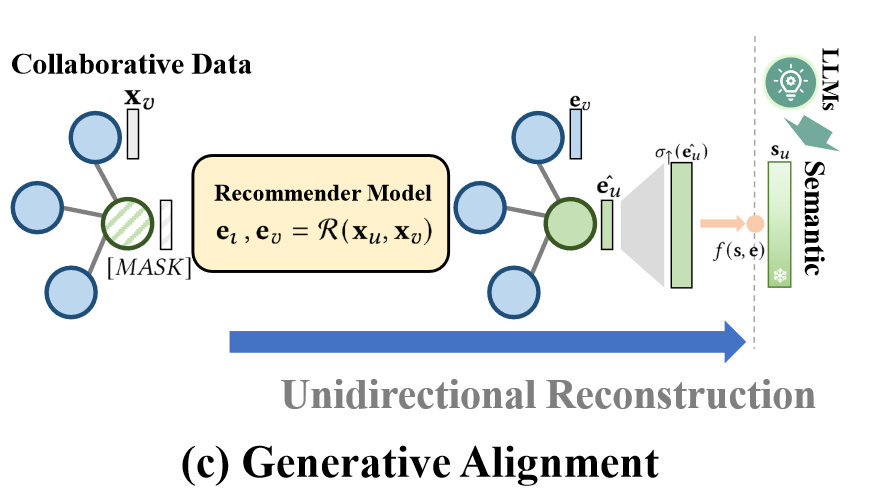
图3. 生成对齐模块
实验效果
RLMRec在Amazon-book、Yelp、Steam等数据集上相对于其他方法有更好的效果
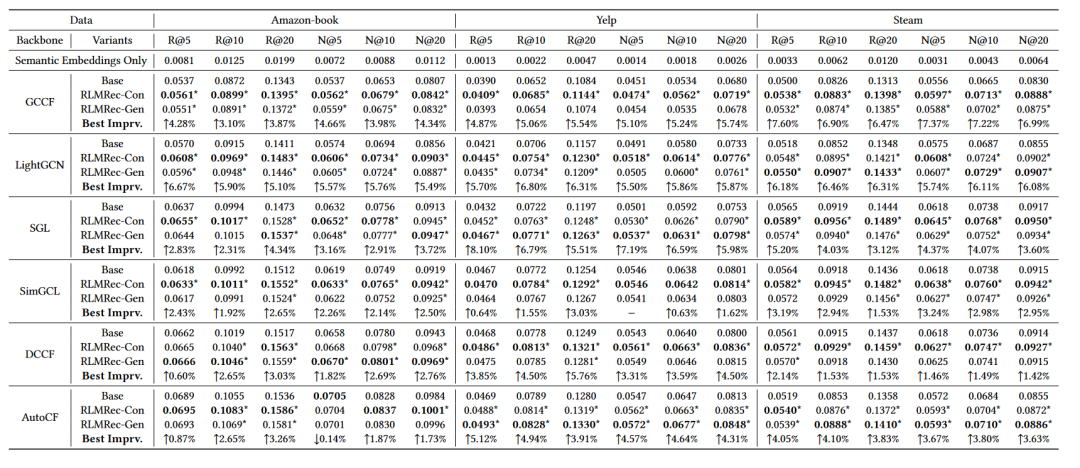
图4. 不同backbone在多数据集上的表现
三、Large Language Model with Graph Convolution for Recommendation
传统的推荐系统主要依赖于协同过滤或基于内容的推荐技术,但在捕捉用户与项目之间的复杂关系时存在一定的局限性。此外,用户和项目的文本描述信息往往被忽略,导致推荐模型在表征用户偏好时缺乏语义层面的细节。针对这一问题,论文提出了一种结合LLMs和GCN的推荐方法。该方法利用LLMs生成的语义嵌入来增强推荐模型的表达能力,同时通过图卷积捕捉用户和项目之间的交互结构。这种结合的目标是解决传统推荐系统中无法充分利用文本信息的问题,从而提升用户与项目匹配的精确度。
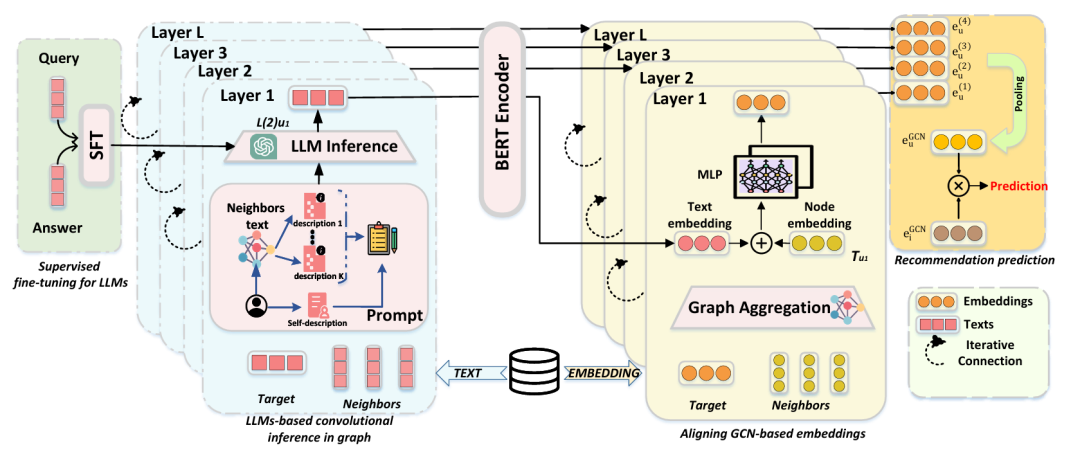
图5. GaCLLM模型图
3.1 基于大语言模型的图卷积推理模块
此模块旨在通过卷积推理辅助大语言模型(LLM)感知用户-项目图结构,并基于提示学习生成更高质量的文本描述。
具体而言,该模块中的卷积模块负责对图结构进行建模,将目标节点及其邻居节点的文本描述进行逐层聚合,再将这些聚合后的信息传递给LLMs。LLMs根据提示学习策略,利用项目的文本描述和原始的用户描述,通过预设的提示词来生成优化后的用户描述,并将其拼接到已有的用户描述之后。
这一流程中的关键策略是逐层推理机制:每次仅聚合一阶邻居的文本描述,随着模型层数的增加,逐步捕获高阶邻居的信息。这种逐层推理不仅提高了计算效率,还使得LLM在生成用户描述时能够更有效地利用图结构信息,这是借鉴GCN提供的辅助优势之一。
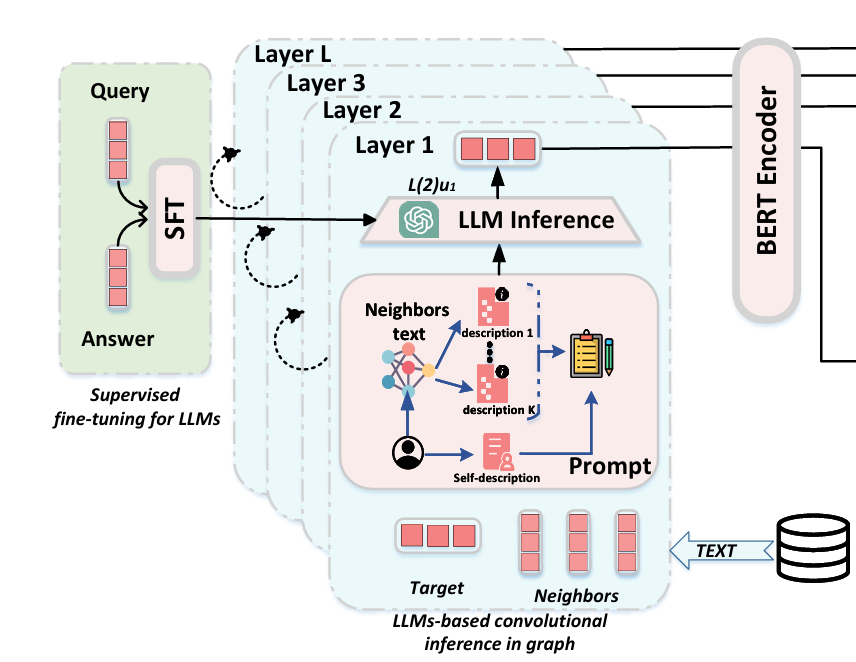
图6. 基于大语言模型的图卷积推理模块
3.2 基于GCN的嵌入对齐模块
此模块旨在将经过GCN生成的目标节点的嵌入与目标节点的文本嵌入进行元素级相加再经过多层感知机MLP捕捉用户和项目嵌入之间的非线性关系,并处理来自不同来源的特征,将它们组合起来,生成更有效的特征表示。
其中为用户的嵌入表示,为项目的嵌入表示,表示第l层的变换映射矩阵,为和分别为用户和项目的邻居节点,和分别为用户和项目的文本嵌入。
为了对齐后的嵌入更好地为推荐任务服务,论文提出了内积匹配的方法,计算用户和项目的最终嵌入之间的内积,作为推荐评分。
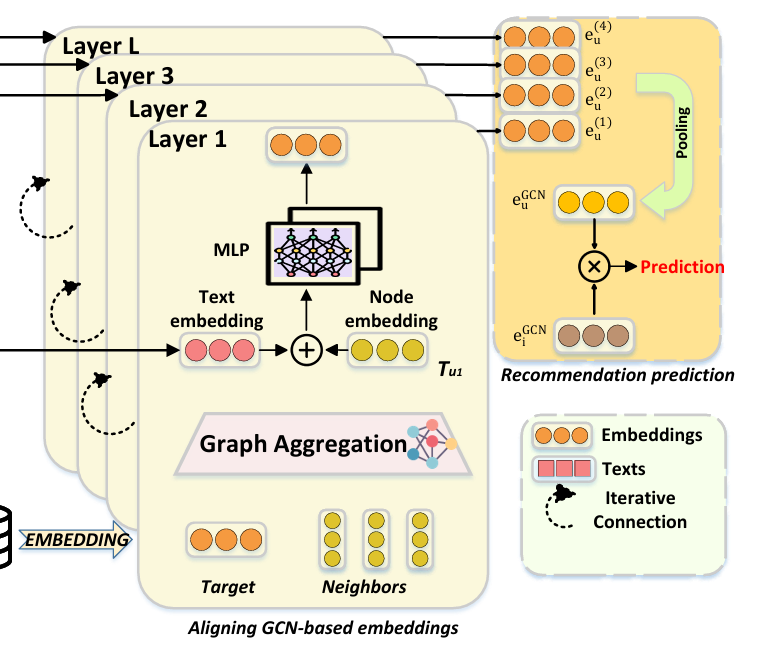
图7. 基于GCN的嵌入对齐模块
3.3.实验效果
GaCLLM在4个数据集上相对于其他方法均取得了较好效果。
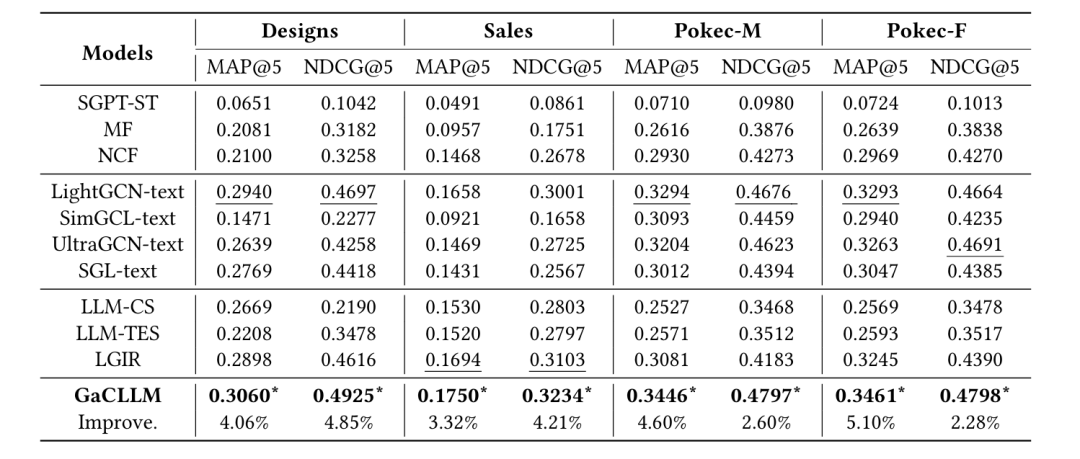
图8. 实验结果
四、总结
本文从如何利用文本信息增强推荐效果的角度出发,介绍了两个最新工作 RLMRec 和 GaCLLM 。RLMRec聚焦于对齐文本描述与协同表示从而得到更好的用户/项目的特征表示,实现更好的推荐效果;GaCLLM从如何提高文本质量角度出发构建了图卷积推理模块优化文本信息表示。这些研究表明LLMs在未来的推荐系统中拥有着巨大的作用,未来的研究和应用可能会进一步提升推荐系统的个性化和智能化,主要的方向例如个性化语义理解与推荐、跨模态推荐等等。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
原文地址:https://blog.csdn.net/python1234_/article/details/143935799
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!