oracle dataguard学习和各版本DG新特性介绍
oracle dataguard学习和各版本DG新特性介绍
DataGuard概述:
Oracle DataGuard是Oracle自带的数据同步功能,可以提供Oracle数据库的冗灾、数据保护、故障恢复等,实现数据库快速切换与灾难性恢复。
-
DataGuard数据同步技术有以下优势:
-
1)Oracle数据库自身内置的功能,与每个Oracle新版本的新特性都完全兼容。
-
2)配置管理较简单,不需要熟悉其他第三方的软件产品。
-
3)物理DataGuard数据库支持任何类型的数据对象和数据类型;
-
4)逻辑DataGuard数据库处于打开状态,可以在保持数据同步的同时执行查询等。
-
5)在最大保护模式下,可确保数据的零丢失。
-
6)网络中断在恢复连接之后自动重新同步,自动存档差异检测和解决,无需人工干预。
-
DataGuard结构
DataGuard基本原理是将日志文件从原数据库传输到目标数据库,然后在目标数据库上应用这些日志文件,从而使目标数据库与源数据库保持同步,是一种数据库级别的高可用性方案。
Oracle DataGuard由一个primary数据库(生产数据库)及一个或多个standby数据库(最多9个)组成。
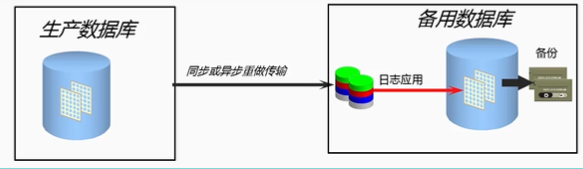
DataGurad主库与备库介绍
-
在DataGurad环境中,至少有两个数据库:
-
Primary数据库(主库):一个primary数据库即被大部分应用访问的生产数据库,该库即可以是单实例数据库,也可以是RAC。
-
Standby数据库(备库):Standby数据库是primary数据库的复制(事务上一致)。
-
-
DataGuard可以分为物理DataGuard、逻辑DataGuard两种,区别如下:
-
物理DataGuard应用的是主库的归档日志,物理DataGuard无论从逻辑结构和物理结构都是和主库保持一致;
-
逻辑DataGuard应用的是主库的归档日志中提取的SQL语句,逻辑DataGuar则只需保证逻辑结构一致。
-
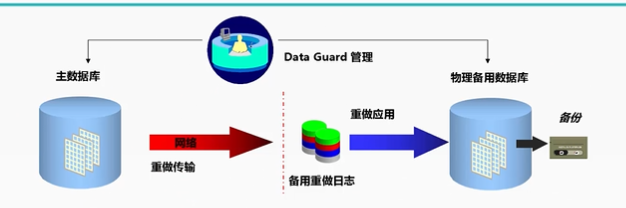
物理备用数据库:
物理备用数据库是主数据库的一个块到块的副本,只要数据库能打开,数据就肯定一致。
使用数据库recovery恢复功能来应用主库的更改
【备库】可以以只读方式打开,用于生成报表和查询、11g可以在打开摸式下进行日志应用与查询。还可用于备份和减轻生产数据库的负载。
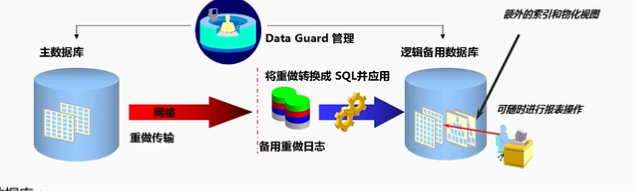
逻辑备用数据库:
生产环境基本都很少用
逻辑备用数据库是一个独立的数据库,包含与生产数据库相同的逻辑信息(行),物理组织和结构可能不同
当通过SQL来应用日志时,可以查询逻辑备用数据库,以进行报表操作
可以创建额外的索引和物化视图,以获得更高的查询性能。
DataGuard数据同步的过程:
DataGuard整个过程分成3个部分:
1)日志发送(Redo Send)
2)日志接收(Redo Receive)
3)日志应用(Redo Apply)
DataGuard日志发送、传输方式:
主库Primary Database在运行过程中,会不断地产生Redo重做日志,这些日志需要发送到备库Standy Database,这个发送动作可以由Primary Database的两种日志传输方式来完成:
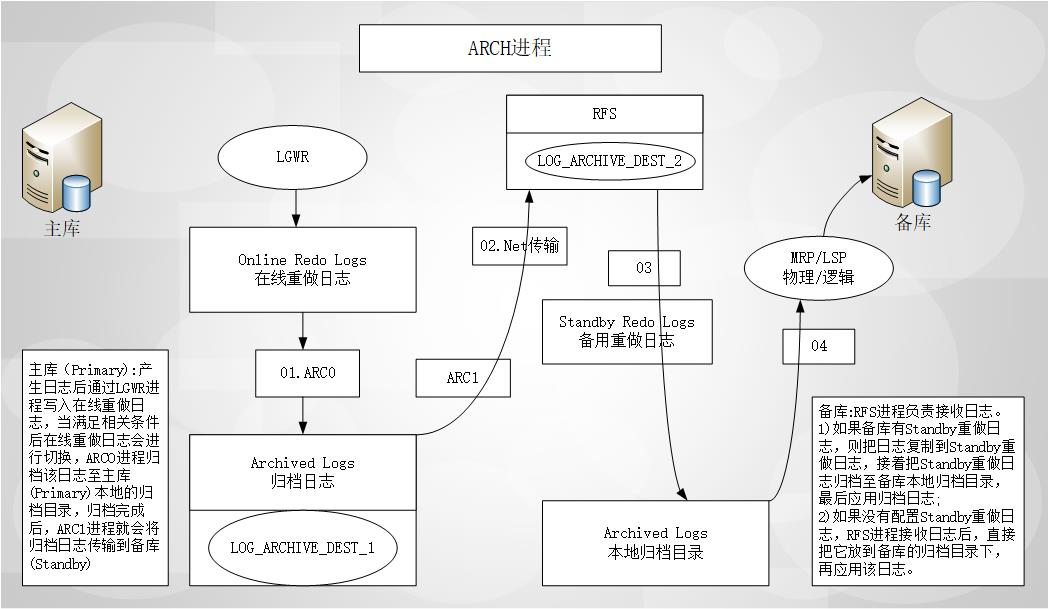
ARCH进程
-
使用ARCH进程存在的问题
-
主库只有在发生归档时才会发送日志到备库。
-
如果主库异常宕机,联机日志中的Redo内容就会丢失,因此使用ARCH进程无法避免数据丢失的问题,要想避免数据丢失,就必须使用LGWR,而使用LGWR又分SYNC(同步)和ASYNC(异步)两种方式。
-
-
Oracle12c增加FAST SYNC模式
-
在Oracle12c中提出了FAST SYNC的模式:
即主库与备库之间仍然以同步模式传输,但是主库只需等待备库收到日志即可,而无需进一步等待备库的日志写入磁盘才能提交,这就大大降低了性能的损耗同时仍可以保证主库备库之间的数据同步。
-
在缺省方式下,主库使用的是ARCH进程
LGWR进程
LGWR进程(ASYNC 异步):
–【生产环境中建议使用,相对可靠】
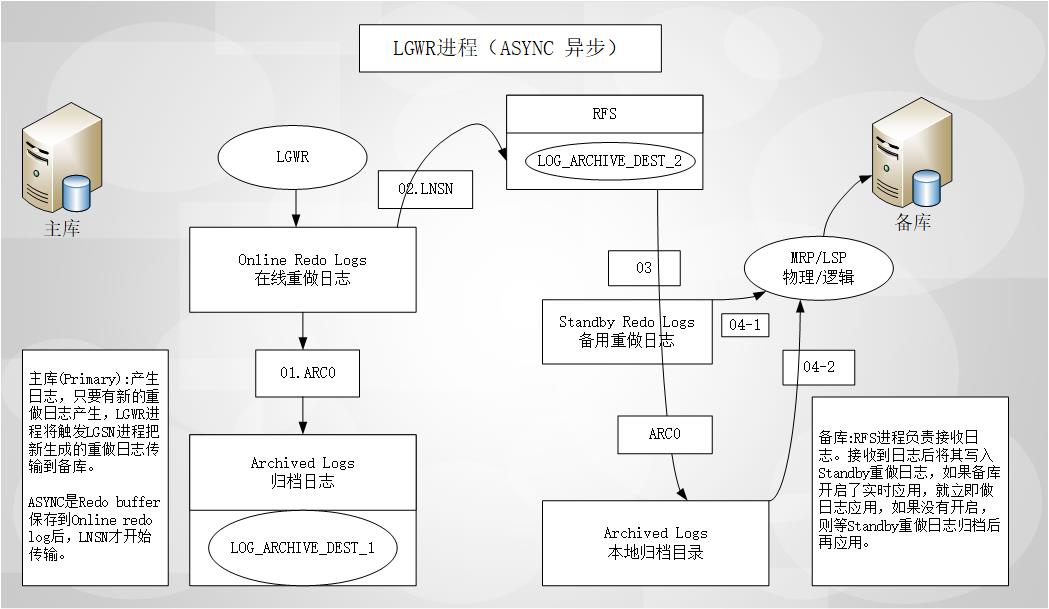
–【04-1 开启了日志实时应用,04-2没有开启日志实时应用】
LGWR进程(SYNC 同步):

- 使用LGWR进程存在的问题
- 使用LGWR SYNC方法的可能问题在于,如果日志发送给备库过程失败,LGWR进程就会报错。也就是说主库的LGWR进程依赖于网络状况,有时这种要求可能过于苛刻,这时就可以使用LGWR ASYNC方式。
DataGuard日志接收:
备库的RFS(Remote File Server)进程接收到日志后,就把日志写到Standby Redo Log或者Archived Log文件中。
如果写到Standby Redo Log文件中,则当主库发生日志切换时,也会触发备库上的Standby Redo Log的日志切换,并把这个Standby Redo Log归档。
DataGuard日志应用:
日志应用服务,就是在备库上重演主库redo日志,从而实现两个数据库的数据同步。
实时应用(Rea-Time Apply) --【04-1 开启了日志实时应用】
这种方式必须Standby Redo Log,每当日志被写入Standby Redo Log时,就会触发恢复,使用这种方式的好处在与可以减少数据库切换(Switchover或者Failover)的时间,因为切换时间主要用在剩余日志的恢复上。
归档时应用 --【04-2没有开启日志实时应用】
这种方式在主库发生日志切换,触发备库归档操作,归档完成后触发恢复。
这也是默认的恢复方式。
-
日志应用服务分为两种方式:
-
REDO应用
- 物理备库数据库专用,通过介质恢复的方式保持与Primary数据库的同步。
-
SQL应用
- 逻辑备库数据库专用,核心是通过LogMiner分析出SQL语句在Standby端执行。
-
DataGuard自动裂缝检测和解决:
当主库的某些日志没有成功发送到备库,这时候发生了归档裂缝(Archive Gap),缺失的这些日志就是(Gap)。
Data Guard能够自动检测,解决归档裂缝,不需要DBA的介入。
这需要配置FAL_CLIENT,FAL_SERVER这两个参数
-
FAL_CLIENT通过网络向FAL_SERVER发送请求
-
FAL_SERVER通过网络向FAL-CLIENT发送缺失的日志。
当然,除了自动解决,DBA也可以手工解决。
DataGuard日志传输相关进程
主库:
LGWR
LGWR搜索事务日志,并且更新联机日志。
在同步SYNC模式下,LGWR直接将redo缓冲信息直接传送到备库中的RFS进程,主库在继续进行处理前需要等待备库的确认。
在非同步ASYNC情况下,也是直接将日志信息传递到备库的RFS进程,但是不等待备库的确认信息主库进程可以继续运行处理。
ARCH进程
只对物理备库,arch进程对备库的重做日志进行归档。
FAL
FAL(Fetch archive log)只有物理备库才有该进程。 --【取回归档日志文件】
FAL进程提供了一个client/server的机制,用来解决检测在主库产生的连续归档日志,而在备库接受的归档日志不连续的问题。该进程只有在需要的时候才会启动而当工作完成后就关闭了,因此在正常情况下,该进程是无法看见的。
该进程是通过fal_client,fal_server参数进行交互的。
备库:
RFS
RFS(remote file server)进程主要用来接受从主库传送过来的日志信息。
对于物理备用数据库而言,RFS进程可以直接将日志写进备用重做日志,也可以直接将日志信息写到归档日志中。
如果要使用备库重做日志,我们必须创建他们(和主库的联机日志一样)。
ARCH进程
只对物理备库,arch进程对备库的重做日志进行归档。
MRP
MRP(managed recovery process)该进程针对物理备库,该进程应用归档日志到备库。
alter database recover managed standby database;
alter database recover managed standby database disconnect from session;--【在后台恢复】
LSP进程
LSP(logical standby process),逻辑备库专用,LSP进程主要是应用归档日志到逻辑备用数据库。
DataGuard三种数据保护模式:
最大保护(Maximum Protection)
这种模式能够确保绝无数据丢失。要实现这一步当然是有代价的,它要求所有的事务在提交前其REDO不仅被写入到本地的OnlineRedologs,还要同时写入到Standby数据库的StandbyRedologs,并确认REDO数据至少在一个Standby数据库中可用(如果有多个的话),然后才会在Primary数据库上提交。如果出现了什么故障导致Standby数据库不可用的话(比如网络中断),Primary数据库会被Shutdown,以防止数据丢失。
使用这种方式要求StandbyDatabase(备库)必须配置StandbyRedoLog,而PrimaryDatabase必须使用LGWR,SYNC,AFFIRM方式归档到StandbyDatabase.
最大可用(Maximum availability)
这种模式在不影响Primary数据库可用前提下,提供最高级别的数据保护策略。其实现方式与最大保护模式类似,也是要求本地事务在提交前必须至少写入一台Standby数据库的StandbyRedologs中,不过与最大保护模式不同的是,如果出现故障导致Standby数据库无法访问,Primary数据库并不会被Shutdown,而是自动转为最大性能模式,等Standby数据库恢复正常之后,Primary数据库又会自动转换成最高可用性模式。
这种方式虽然会尽量避免数据丢失,但不能绝对保证数据完全一致。这种方式要求StandbyDatabase(备库)必须配置StandbyRedoLog,而PrimaryDatabase必须使用LGWR,SYNC,AFFIRM方式归档到StandbyDatabase(备库).
最大性能(Maximumperformance)
缺省模式。这种模式在不影响Primary数据库性能前提下,提供最高级别的数据保护策略。事务可以随时提交,当前Primary数据库的REDO数据至少需要写入一个Standby数据库,不过这种写入可以是不同步的。如果网络条件理想的话,这种模式能够提供类似最高可用性的数据保护,而仅对Primary数据库的性能有轻微影响。这也是创建Standby数据库时,系统的默认保护模式。
这种方式可以使用LGWRASYNC或者ARCH进程实现,StandbyDatabase(备库)也不要求使用StandbyRedoLog。
DataGuard主从角度切换:
-
主要分为Switchover与Failover
-
Switchover
-
Swithchover通常都是人为的有计划的进行角色互换,比如升级等。它通常都是无损的,即不会有数据丢失。其执行主要分为两个阶段:
-
A.Primary转为Standby
-
B.Standby转为Primary
-
-
Failover
- Failover是指由于Primary故障无法短时间恢复,备库不得不充当主库的角色,如果处于最高性能模式,这种切换很有可能导致数据丢失。这种是破坏性的操作,一般情况下DataGuard是需要重做的。
-
DataGuard11g新特性ADG(Active Dataguard):
-
Active Dataguard优势:
1.管理维护简单
2.Active Dataguard节点是灵活可扩展的,可以在线添加或者删除节点,并且可以线性扩展而不对生产系统造成影响;
3.可以真正做到实时查询,不会应为大事务造成同步阻塞,性能有保障;
4.没有数据类型的限制;
5.高可用性,节点的宕机都不会影响到数据库的可用性。
-
Active Dataguard注意事项: --【好处就是:备库可以打开做一些查询】
1.Active Dataguard是11g数据库单独的一个option,需要单独付费的。
2.无法在Active Dataguard节点单独创建索引进行查询优化。
3.在所有Active Dataguard节点上sql的执行计划最好保持一致。
DataGuard12c重要新特性-Far Sync(两地三中心):
另外,12c之前遇到的问题:
1.最大数据保护模式需要远端返回提交确认后才算提交,影响主库性能。
2.如果需要最大化主库性能,日志传输应用需要异步进行,可能存在数据丢失。
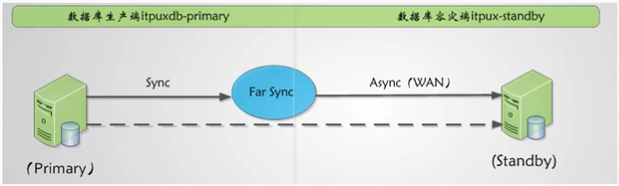
12c或之后:可以在主备库之间放一个远程同步实例,可以放在距离主库较近的异地,专门接收日志:
Far Sync是12C中新增的一种实例类型(instance type),如同rdbms和asm实例,它不运行数据库、没有数据文件,只有日志文件,专门用于DataGuard配置中负责日志转发的轻量级实例。
这个far sync实例需要配置在离主库距离不远的机房。
例如:同数据中心或同城灾备的机房,以便实现同步日志传输
在距离生产数据中心较近的地方建立Far Sync实例,通过SYNC的方式把Redo传输到Far Sync实例,然后通过ASYNC的方式传输到终端灾备数据库。
在此过程中,如果Far Sync实例出现问题,生产数据库可以直接通过ASYNC方式把Redo传输到灾备数据库。
Oracle之ADG与DG的区别
DG(Data Guard)
DG(Data Guard,数据卫士)不是一个备份恢复的工具,然而,DG却拥有备份的功能,在物理DG下它可以和主库一模一样,但是它存在的目的并不仅仅是为了备份恢复数据,应该说它的存在是为了确保企业数据的高可用性,数据保护以及灾难恢复。DBA可以通过将一些操作(例如查询报表)转移到备库执行的方式来减小主库的压力,构建高可用的企业数据库应用环境。
在DG环境中,至少有两个数据库,一个处于OPEN状态对外提供服务,这个数据库叫作主库(Primary Database)。第二个处于恢复状态,叫作备库(Standby Database)。在通常情况下,主库对外提供服务,用户在主库上进行操作,操作被记录在联机日志和归档日志中,这些日志通过网络传递给备库,然后在备库上被应用,从而实现主库和备库的数据同步。
Oracle对这一过程进一步地优化设计,使得日志的传递、恢复工作更加自动化、智能化,并且提供一系列参数和命令简化了DBA工作。如果软硬件升级,那么可以把备库切换为主库继续对外服务,这样既减少了服务停止时间,并且数据不会丢失。如果异常原因导致主库不可用,那么也可以把备库强制切换为主库继续对外服务,这时数据损失都和配置的数据保护级别有关系。所以,Primary和Standby只是一个角色概念,并不固定在某个数据库中。
adg
Oracle 11g之前,物理备库(physical Standby)在应用redo的时候,是不可以打开的,只可以mount。从11g开始,在应用redo的时候,物理备库可以处于read-only模式,这就称为Active Data Guard 。通过Active Data Guard,可以在物理备库进行查询或者导出数据,从而减少对主库的访问和压力。
Active Data Guard适用于一些只读性的应用,比如,有的应用程序只是查询数据,进行一些报表业务,不会产生redo数据,这些应用可以转移到备库上,避免对主库资源的争用。
ADG主要解决了DG时代读写不能并行的问题
DG时代的数据同步方式如采用Redo Log的物理方式,则数据库同步数据快、耗用资源低,但存在一个大问题。
Oracle 11G以前的Data Guard物理备份数据库,可以以只读的方式打开数据,但这时日志的数据同步过程就停止了。而如果日志的数据同步处于执行过程中,则数据库就不能打开。也就是日志读、写两个状态是互相排斥的。而Active Data Guard则是主要解决这个问题。
Oracle具有闪回数据库的功能,避免删表等误操作造成无法挽回
当主数据库打开并处于活动状态时,事务处于处理状态,生成Redo Log数据,并将其传送到备用的数据库中,正常情况下,可以做到秒级的数据同步。但如果在主用数据库上执行一个错误的命令,如drop database,则所有备用数据库中的数据也会被删除。
Oracle DG提供了易于使用的方式来避免这种用户错误。DBA可以在主数据库、备用数据库中同时使用闪回数据库功能,以快速将数据库恢复到一个较早的时间点上,从而取消这个误操作。
另外,Oracle还提供了延时执行备份数据库同步的功能,这样又是另一种方式防止误操作。
转载于: http://news.558idc.com/378806.html
Oracle 19c DataGuard新特性
ADG上支持DML操作
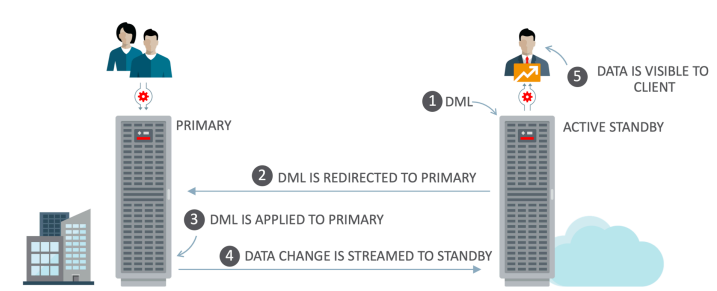
Oracle 19C ADG上⽀持DML操作,是19C中最重要的新特性之⼀。⽤户直接在ADG上发起DML操作,Oracle通过内部DBLINK将DML发送到主库并执⾏,然后将数据同步到ADG上,此时ADG上就可以查询到变更后的数据。如运⾏在ADG上的报表程序、ETL抽取程序、⽇志记录程序等最后都需要在数据库中插⼊少量记录,DML Redirection很好了解决了这个问题。
随主库自动闪回、PITR恢复备库
-
19c之前存在的问题
-
主库需要闪回数据库操作,并以resetlogs⽅式打开,此时DG⽆法同步数据,需要重新搭建DG
-
主库需要不完全恢复过去的时间点,同样要以resetlogs⽅式打开数据库,也就需要重新搭建DG
-
-
从19C开始,DataGuard备库可以随主库⼀起⾃动闪回,或者随主库⼀起不完全恢复,这些操作完成后,DG可以继续同步,⽽不需要重建,极⼤的减少了DBA的维护⼯作,减少误操作的⻛险。
-
⽀持主库PDB级别的闪回和恢复。
-
如果不想备库⾃动随主库闪回或者恢复,只需将备库open readonly或者将MRP恢复进程停⽌
-
备库闪回步骤
- 定位新的incarnation
- 闪回恢复备库(或者PDB)到和主库闪回恢复⼀样的时间点
- 重新启动备份的恢复进程,并同步新的REDO⽇志
- 前提条件
主库在mount状态并启用恢复进程
主备库都开了闪回
备库的闪回日志足够用于闪回到主库指定的时间点
SQL> ALTER DATABASE CLOSE;
SQL> FLASHBACK PLUGGABLE DATABASE pdb1 TO SCN 1437260;
SQL> RECOVER MANAGED STANDBY DATABASE DISCONNECT;
SQL> ALTER DATABASE CLOSE;
SQL> RESTORE PLUGGABLE DATABASE pdb1 UNTIL SCN 1437261;
SQL> RECOVER MANAGED STANDBY DATABASE DISCONNECT;
从主库自动同步恢复点到备库
由于恢复点(Restore Points)存储在控制⽂件中,早期版本也就⽆法同步到备库,从19C中开始⾃动将主库创建的恢复点同步到备库,并已_PRIMARY后缀命名,在failover后,备库仍然保留之前主库恢复点,以防出现failover后需要恢复到Restore Points的情况。
COMPATIBLE参数必须为19.0.0或者更⾼
- 主库必须在OPEN状态下,MOUNT下不同步
- 备库已存在相同名称的恢复点,不会同步
- 主库删除恢复点时备库同步删除
- 如果MRP进程未运⾏,则等到MRP下次启动时同步
- 可以通过V$RESTORE_POINT视图查询恢复点
Fast-Start-Failover (FSFO) 新特性
FSFO可以在主库挂掉的情况下,⾃动快速将备库切换为主库,继续对外提供服务,减少对业务的影响。
•动态改变Fast-Start-Failover (FSFO)的⽬标
新特性之前必须禁⽤FSFO才可以更改FSFO转移的⽬标,随着12.2⽀持多个FSFO⽬标后,在线动态更改FSFO⽬标就变得⾮常重要。
DGMGRL> SET FAST_START FAILOVER TARGET TO Boston;
DGMGRL> SHOW FAST_START FAILOVER;
• 以监测模式运⾏Fast-Start-Failover (FSFO)Fast-Start-Failover (FSFO)
19C开始⽀持以监测、预演的⽅式测试FSFO的切换,也就是不真实发⽣切换,确保在不影响⽣产的情况下,验证⼀旦发⽣故障时FSFO可以正常将备库切换为主库。
DGMGRL> ENABLE FAST_START FAILOVER OBSERVE ONLY
原文地址:https://blog.csdn.net/hf191850699/article/details/143882084
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!