一些任务调度的概念杂谈
任务调度
1.什么是调度任务
依赖:依赖管理是整个DAG调度的核心。调度依赖包括依赖策略和依赖区间。
依赖分为任务依赖和作业依赖,任务依赖是DAG任务本身的依赖关系,作业依赖是根据任务依赖每天的作业产生的。两者在数据存储模型上有所不同。作业依赖树存储的多了两个时间:调度时间,数据时间。
job依赖:
作业依赖:

依赖是由依赖策略和调度依赖区间组成
依赖策略 当依赖job在调度区间内有多个Task时候,需要指定依赖策略 | 依赖策略 | 描述 | |–|--| | All(*) | 调度区间内,所有依赖均成功 | | Any(+) | 调度区间内,任何一个依赖任务成功 | | First(N) | 调度区间内,前面N个依赖成功 | | Last(N) | 调度区间内,后面N个依赖成功 | | Continuous(N) | 调度区间内, 连续N个依赖成功 |
调度依赖区间
定义调度依赖的区间,通过基准时间与偏移时间来计算。 表达式 = (基准时间t, 起始偏移时间x(m), 结束偏移时间x(n)) 比如 (“yyyy-MM-dd HH:00:00”, x(n), x(m)) 基准时间t : 基准时间的格式化,默认"yyyy-MM-dd HH:mm:ss" 起始偏移时间x(n) : 基准时间"向前偏移x(n)时间,作为偏移时间的起始点。(正数向前,负数向后) 结束偏移时间x(m):偏移开始时间 向前偏移x(m)时间,作为偏移时间的结束点。(正数向前,负数向后) 时间单位 : 年 y 月M 周w 天d 时h 分m
举例子:
年 (y):比如 "2024-11-09 10:00:00", 2y, -1y 表示从基准时间向前偏移2年,再向后偏移1年,最终区间为 2022-11-09 10:00:00 到 2023-11-09 10:00:00。
月 (M):例如 "2024-11-09 10:00:00", 3M, -1M 表示从基准时间向前偏移3个月,再向后偏移1个月,最终区间为 2024-08-09 10:00:00 到 2024-09-09 10:00:00。
周 (w):例如 "2024-11-09 10:00:00", 2w, -3w 表示从基准时间向前偏移2周,再向后偏移3周,最终区间为 2024-10-26 10:00:00 到 2024-11-23 10:00:00。
天 (d):例如 "2024-11-09 10:00:00", -7d, 4d 表示从基准时间向后偏移7天,再向前偏移4天,最终区间为 2024-11-02 10:00:00 到 2024-11-13 10:00:00。
小时 (h):例如 "2024-11-09 10:00:00", -3h, 5h 表示从基准时间向后偏移3小时,再向前偏移5小时,最终区间为 2024-11-09 13:00:00 到 2024-11-09 05:00:00。
作业计划 先说一下什么是作业计划,比如调度系统有1w+的job。这些job有每天执行一次或者多次,有纯依赖,有复杂依赖。一个job从第一次创建,如何知道下一次的执行时间,依赖等。就需要通过创建作业计划来完成。 作业计划有两种创建模式:
1.每天生成第二天的 2.当前任务执行初期或者完成时自动自动生成下游plan。
如果调度系统简单,直接可以使用第二种,但是对于1w+job的系统,或者某个纯依赖的上游任务很多,或者上游也是纯依赖并且图深度>10. 显然第二种会影响执行的效率。
依赖条件:是任务调度的必要条件,当一个任务被触发了,但依赖条件不满足,则必须等待。只有当所有的依赖条件都满足了,这个任务才能开始执行。
任务之间的依赖有上周期依赖、全周期依赖、连续周期依赖、断点周期依赖。
要清晰区分全周期依赖和连续周期依赖,我们可以从任务需要的数据范围和依赖周期的处理角度来理解。
1.全周期依赖 (Full Cycle Dependency)
定义:全周期依赖指的是某个任务在执行时,依赖的是整个周期内的所有数据。这意味着它需要周期内的每一部分数据来得出结果。通常是针对完整周期内的每个单位时间(如一天、一个月、一年等)进行处理。
特点:
-
依赖的是完整周期的每一个数据点。
-
适用于需要全面汇总整个周期数据的任务。
-
通常周期的单位较大(如天、月、年等)。
例子: 假设有一个任务是计算某网站的前一天的总PV数(页面浏览量)。这个任务需要依赖前一天24小时内每个小时的数据来进行汇总。在这种情况下,任务依赖的是前一天的所有小时数据,形成了全周期依赖。这里的数据范围包括周期内的每个时间单位(每小时),任务必须等到完整的周期数据都可用后才能开始。
2.连续周期依赖 (Continuous Cycle Dependency)
定义:连续周期依赖指的是某个任务在执行时,依赖的是周期中连续一段时间的数据。这种依赖通常与某个周期的一个连续时间段相关,而不需要完整周期的数据。
特点:
-
依赖的是周期内的连续一部分数据。
-
通常周期较小,任务处理的是连续时段内的累积数据。
-
适用于需要在周期内连续时间段内获取数据的任务。
例子: 假设有一个任务是计算某网站的今天前12小时的PV数。这个任务只需要依赖今天从0点到12点的连续数据,而不需要完整的24小时数据。在这种情况下,任务依赖的是周期内的一部分连续时间段(12小时),并形成了连续周期依赖。
全周期依赖与连续周期依赖的区别:
-
数据范围:
-
全周期依赖需要整个周期的数据(如全天、全月等),每个数据点都对最终结果有影响。
-
连续周期依赖只依赖周期中的某一段连续的数据(如12小时、1小时等),并不需要整个周期的所有数据。
-
-
任务目的:
-
全周期依赖通常用于需要综合处理整个周期数据的任务,如统计日、月、年的总和、平均值等。
-
连续周期依赖则用于处理周期内连续时间段的数据,可能用于实时或中期的累积计算,如前12小时的流量、前一小时的数据等。
-
小结
-
全周期依赖:涉及周期内每个单位数据,依赖完整的周期(例如:一天的每小时数据)。
-
连续周期依赖:依赖周期内某段连续时间的数据(例如:今天前12小时的数据)。
通过这样区分,你可以明确知道任务是依赖于整个周期的数据,还是只需要周期内的部分连续时间段的数据。
3. 上周期依赖:
上周期依赖指的是任务依赖于上一周期的结果。例如,某个任务的计算需要依赖于前一天或前一小时的任务结果。这些任务依赖的是前一个周期的输出,而不是当前周期。
例子:如果需要计算某网站12点的UV数,但计算12点的UV数需要依赖于11点的数据,这就形成了上周期依赖。
4. 断点周期依赖:
断点周期依赖指的是任务依赖于周期中的特定时间点的数据,而非整个周期或连续的时段。这类任务不关心整个周期的数据,只关心某些特定时间段的数据。
2.任务调度的两种模式
1. Push(推)模式
Push模式是由调度系统主动推送任务到各个执行节点。当任务准备好时,调度系统将任务发送到指定的执行环境或代理,触发任务的执行。
优点:
-
实时性较好:由于调度系统主动推送任务,可以确保任务被及时触发和执行。
-
资源管理集中:调度系统控制任务的推送,能够对资源的使用情况进行集中管理,避免过度资源使用或任务堆积。
-
减少资源浪费:任务一旦到达指定执行节点,系统可以立即开始执行,减少了等待的时间。
缺点:
-
依赖于调度系统:系统的负载和可用性会影响任务的推送效率,可能会出现调度系统过载的情况。
-
灵活性较差:任务执行节点可能不是始终在线,导致推送失败,需要调度系统进行重试或故障恢复。
-
管理复杂度:如果任务数量极大,推送机制可能会变得复杂,特别是如果任务依赖链较长时,管理和监控任务变得较为复杂。
2. Pull(拉)模式
Pull模式是由任务执行节点主动拉取任务。执行节点定期向调度系统查询是否有任务需要执行,并根据查询结果执行任务。
优点:
-
减少调度系统负担:由于任务执行节点主动拉取任务,调度系统的负担会较轻,调度系统不需要直接推送任务,减少了系统压力。
-
提高灵活性:如果任务执行节点数量较多且分布式,Pull模式能更好地适应分布式环境,提高系统的可扩展性。
-
容错性较好:如果某个执行节点离线或不可用,其他节点可以继续拉取任务,避免因某个节点不可用导致任务无法执行。
缺点:
-
延迟较高:任务的执行需要等待执行节点主动拉取,这会导致任务的执行延迟,尤其是在任务间隔较长时。
-
资源消耗较高:执行节点需要不断向调度系统发送请求,可能会造成不必要的网络流量或资源浪费。
-
任务分配不精准:任务的调度依赖于执行节点的拉取频率和状态,可能会导致任务分配不均衡,某些节点可能没有任务,而其他节点可能过载。
总结:
-
Push模式适合于需要实时性高和集中控制的任务调度,特别是在任务数量较少或者执行节点数量不多时,能够提供较快的响应和执行效率。
-
Pull模式更适合于分布式系统和高可扩展性的环境,尤其是在任务量大、节点数量多、需要容错和负载均衡的场景中,但可能面临一定的延迟和资源消耗问题。
两者的选择要根据系统的具体需求、任务特性以及资源管理策略来决定
在任务调度系统的 Push模式 和 Pull模式 中,图的概念可以通过任务之间的依赖关系和触发机制得到扩展。图的结构可以帮助更好地理解任务之间的关系、依赖和执行流向。
1. Push模式中的图的作用
在 Push模式 中,任务调度系统主动向目标任务“推送”信息或触发事件。这种模式下,图的结构可以用于表示任务之间的依赖关系或执行顺序。
-
任务依赖图:在Push模式下,任务之间的依赖可以构成一个有向图,节点代表任务,边表示任务间的依赖关系。调度系统通过分析图的结构来确定任务的执行顺序,确保任务在依赖条件满足时才会被触发。例如,如果任务A依赖于任务B,则任务B执行完成后,任务调度系统会触发任务A的执行。
-
图的遍历:调度系统可以在图中遍历所有任务,推送消息或事件给满足条件的节点。例如,系统可以通过深度优先搜索(DFS)或广度优先搜索(BFS)遍历任务依赖图,依次激活任务执行。
深度优先搜索(DFS)
广度优先搜索(BFS)
-
任务流转:Push模式下,图可以帮助设计任务的流转逻辑,像流水线一样进行任务的自动化执行。每当一个任务完成时,图中的相关节点就会被触发,从而推动整个任务流程的推进。
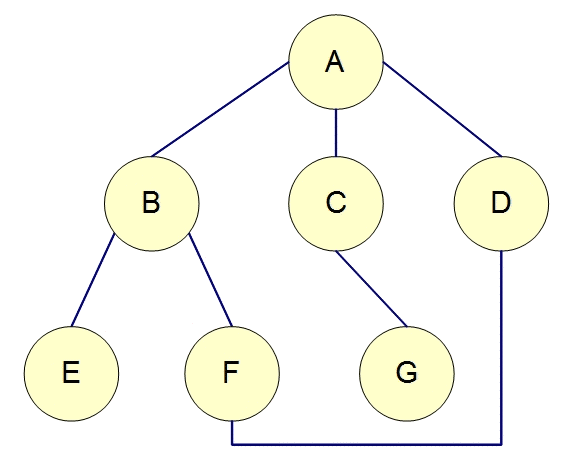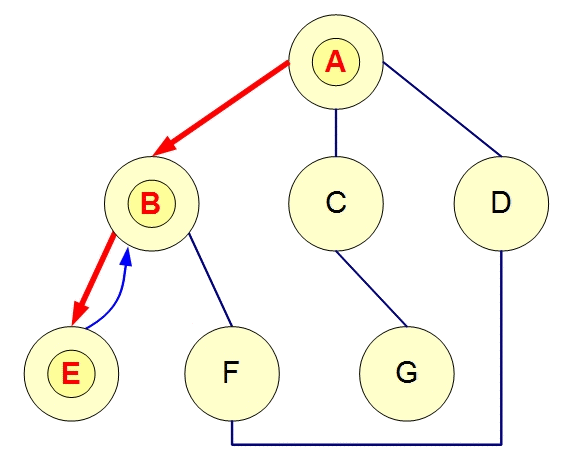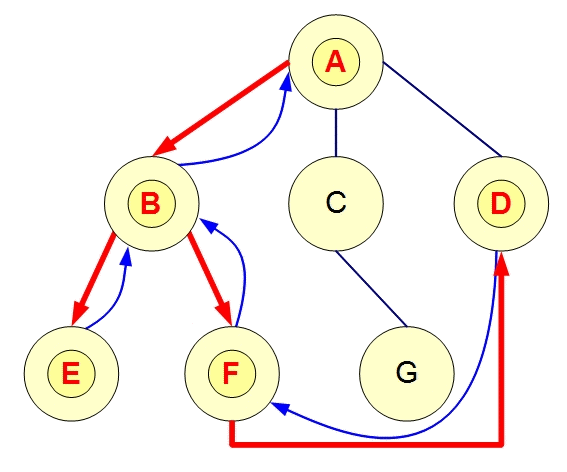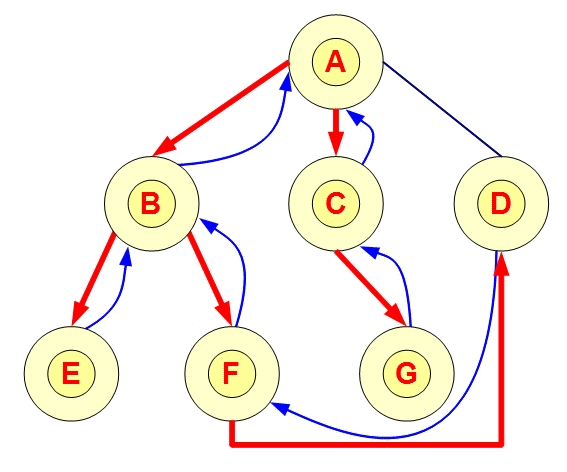
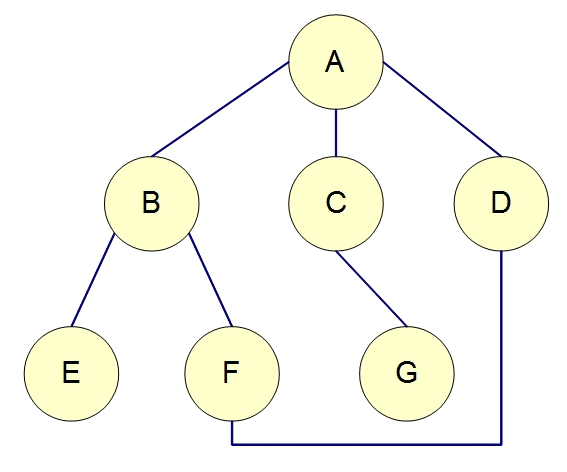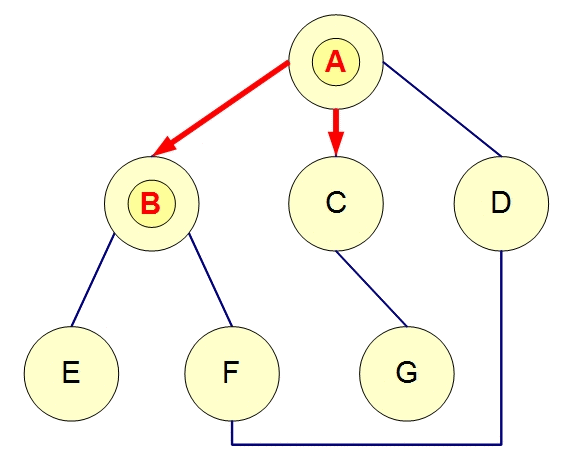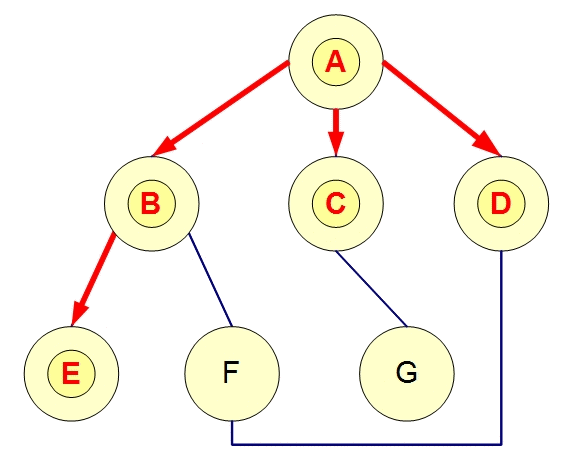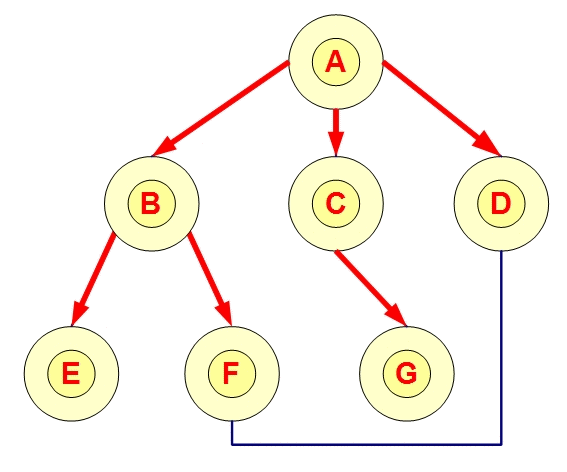
2. Pull模式中的图的作用
在 Pull模式 中,任务主动去“拉取”数据或触发依赖任务。这里,图的作用在于帮助管理依赖关系以及在适当的时机拉取任务的执行信息。
-
依赖关系图:在Pull模式下,图依然用于表示任务之间的依赖关系,但这次是任务主动查询和拉取执行条件。如果任务A依赖于任务B,那么任务A会周期性地拉取任务B的执行状态,直到任务B完成后才能执行任务A。
-
循环依赖:Pull模式下,图可以帮助识别任务间是否存在循环依赖,即任务A依赖任务B,而任务B又依赖任务A。在这种情况下,图的强连通组件(Strongly Connected Components, SCC)可以用来检测和解决这种依赖关系的冲突。
-
状态同步:在Pull模式下,任务调度系统可以通过图的结构去同步和拉取任务的状态,确保任务在被拉取时已经满足执行条件。例如,图中的节点可以表示任务的不同状态(等待、执行、完成等),而拉取操作就是通过查询图中节点的状态来决定任务是否可以执行。
3. Push与Pull模式中的图的区别
-
Push模式:系统主动推送任务执行,图的作用是管理和组织任务间的依赖关系,当任务完成时,系统根据依赖图推送给下一个需要执行的任务。此时,图作为任务调度的驱动者,确保任务按照依赖顺序执行。
-
Pull模式:任务主动去查询和拉取数据或执行条件,图的作用则是帮助管理任务依赖和状态,通过周期性地拉取任务状态,确保依赖条件满足后再执行。图作为任务调度的查询机制,提供了对任务执行条件的监控和拉取功能。
总结来说,图在这两种模式中的作用都是管理任务间的依赖关系和执行流转,Push模式侧重于主动触发任务,而Pull模式则依赖任务自我查询和状态同步。
Push模式的缺点
-
循环消耗:
-
无穷循环:在Push模式中,任务调度系统主动推送任务。若任务依赖存在循环依赖(例如任务A依赖任务B,任务B又依赖任务A),系统可能会陷入无穷推送,导致资源消耗严重,无法完成任务执行。
-
高延迟:由于每次任务完成后必须推送给下一个任务,任务链中某些任务的执行可能受到瓶颈限制。如果某个关键任务没有及时完成,后续任务无法及时开始,可能引发大量不必要的等待,影响系统整体性能。
-
-
关键路径时间:
-
关键路径延迟:Push模式的关键路径延迟(Critical Path Delay)主要体现在任务调度系统的推送时延。如果某个任务的推送触发有延迟,整个任务链可能被拖慢,导致系统整体运行效率低下。
-
不容易预测:由于Push模式依赖任务的顺序和推送策略,如果推送不合理,可能会导致某些任务在执行时需要等待前置任务完成,增加了关键路径的延迟。
-
-
资源消耗问题:
-
在高并发任务的情况下,Push模式可能导致资源大量消耗,因为任务需要持续触发并处理大量的依赖,尤其在依赖图过于复杂时,推送操作可能会产生巨大的负担,导致系统性能瓶颈。
-
Pull模式的缺点
-
循环消耗:
-
轮询负载:Pull模式需要任务主动去拉取状态或触发条件,如果任务调度系统的拉取频率设置得不合理,可能会导致系统产生大量的轮询请求,从而造成网络、存储或计算资源的浪费。
-
冗余请求:如果任务不依赖于某些资源的变化(例如资源未更新),拉取操作可能会导致冗余请求和不必要的负担,尤其是在任务依赖关系复杂时,频繁拉取状态会浪费大量系统资源。
-
-
关键路径时间:
-
拉取延迟:Pull模式下,任务的触发依赖于任务自身去拉取状态,若拉取的周期较长或者拉取过程本身产生延迟,可能会增加关键路径时间。
-
任务延迟积累:在Pull模式下,任务的执行依赖于其他任务的状态,并且任务会有拉取等待时间,这意味着,如果某个任务或资源状态未及时更新,后续任务的执行会被推迟,影响系统响应时间和整体效率。
-
-
同步问题:
-
由于任务拉取信息的时机和频率是由任务本身决定的,可能会导致不同任务之间的执行不同步。例如,如果任务A依赖任务B的执行结果,而任务B在某个周期内没有及时拉取到任务A的状态,任务A可能无法及时执行,导致整个任务链的执行延误。
-
总结
-
Push模式的缺点主要体现在推送机制的资源消耗、循环依赖引发的推送延迟、以及任务的推送时延导致关键路径延迟的风险。
-
Pull模式的缺点则主要表现为任务的拉取操作带来的资源浪费、拉取频率不合理导致的冗余请求、以及任务执行的延迟积累影响关键路径时间。
下游任务等待的原因:
1.严格的顺序依赖 当任务流设计中要求严格的顺序执行,即任务A必须完成后任务B才能启动,这种设计方式使得任何上游任务延迟都会顺延到下游任务,形成“链式”延迟。
2.多重依赖
如果一个任务依赖多个前置任务(例如任务C依赖任务A和任务B同时完成),则C任务只能在A和B都完成后才能启动。当任意一个前置任务延迟时,任务C都会被阻塞,造成等待。
3.层级依赖 有些任务依赖多个层级的任务完成。例如,任务D依赖任务C,任务C依赖任务A和B。此时,如果A或B延迟,C和D都会受到影响,导致层层等待。这种情况会因为层级增加而导致显著的“放大”效应。
4.跨流程依赖 在某些复杂调度系统中,不同任务流之间可能存在交叉依赖(例如任务流X中的任务A需要等待任务流Y中的任务B完成)。当任务依赖跨流程存在时,两个流程的时间步调可能不一致,导致等待时间增加。
5.依赖链中的重试或失败处理机制 如果依赖链中的一个任务因为错误而需要重试或延时处理(例如在一定间隔后自动重试),那么下游任务会持续等待,直到上游任务重试成功或超时。
6.依赖的时间窗口 某些调度系统允许任务设置在特定时间窗口执行。如果上游任务执行时间接近或超出窗口,下游任务就可能因为窗口未开启而等待。例如,任务B只能在每天的特定时段运行,那么即使任务A完成了,任务B也可能因为时间限制而延迟启动。
7.自依赖
自依赖指任务对自身的依赖,即当前周期的任务在执行时依赖于它在该周期或之前周期的完成情况。这种情况往往是设计错误,容易导致任务无法启动。因为任务需要自身完成才能启动,但自身尚未执行,形成逻辑上的死锁。在某些调度系统中,如果允许任务重试,那么自依赖会导致无限重试或直到手动干预。
8.跨周期依赖
跨周期依赖指任务在一个周期的执行依赖于之前周期的任务结果。例如,任务B在周一的执行依赖于任务A在上周五的执行结果。跨周期依赖通常用于累积、汇总或需要跨周期数据的任务。如果上一个周期的任务没有完成或延迟,当前周期的任务会受到影响,导致延迟。跨周期依赖可能导致数据一致性风险,尤其是在前置任务有可能被更新或重跑的情况下。跨周期依赖增加了调度的复杂性,尤其是当多个周期、多个任务流存在关联时,容易导致长时间等待或任务冲突。
依赖时间窗口在跨周期依赖中的作用
在跨周期依赖中,依赖时间窗口的作用主要体现在以下几个方面:
-
限定等待范围:依赖时间窗口设置了一个合理的等待范围,确保任务不会因为无限等待前置任务而导致系统死锁。例如,可以设定任务只允许等待上一个周期(如上一天、上周、上月)的任务结果。
-
控制跨周期依赖的影响:通过设置依赖时间窗口,可以控制跨周期依赖的范围,使任务在合理的窗口内获取所需的前置数据,避免对早期周期的依赖。这种做法减少了依赖链条的复杂性,提高了任务调度的效率和稳定性。
-
适应业务需求的周期性数据依赖:对于业务需求中需要汇总周期性数据的任务(例如,日统计依赖于前一日的数据),依赖时间窗口可以将任务配置成等待特定的周期范围。这样一来,调度系统可以在任务运行时确保前置数据是最新的并且是符合业务周期的数据。
示例:依赖时间窗口在跨周期依赖中的应用
假设有一个任务B,它需要任务A上周的执行结果作为数据来源。这种情况下,依赖时间窗口可以设置为“上周”,即任务B每次运行时,仅等待上一个完整周的任务A数据。
这样做的好处是:
-
避免无限等待:如果任务A上周未能按时完成,可以在依赖时间窗口结束后自动跳过等待,避免任务B持续等待。
-
容错性:如果前置任务的数据因某些原因不完整,依赖时间窗口的设计也可以帮助任务调度系统使用默认数据或历史数据,保证系统稳定性。
总结
跨周期依赖在任务调度系统中的实现确实依赖于“依赖时间窗口”的概念。合理设置依赖时间窗口可以有效控制任务之间的跨周期依赖关系,避免过长的等待时间,同时保证任务调度系统的灵活性和容错性。
下游任务感知上游任务是否完成是任务调度和依赖管理中的关键问题,尤其是在 Pull 模式 下。通常,下游任务需要通过某种方式(例如轮询、状态查询等)来获取上游任务的状态,确保任务依赖的正确性。以下是几种常见的方式,帮助下游任务感知上游任务是否完成:
1. 状态查询(轮询)
下游任务定期查询上游任务的执行状态,检查上游任务是否已完成。上游任务完成后,状态会更新为“成功”、“完成”或者“结束”等。
具体做法:
-
下游任务会定期通过 API、数据库查询或任务管理系统的接口检查上游任务的状态。
-
上游任务的状态可以是:
RUNNING(运行中)、SUCCESS(成功完成)、FAILED(失败)、WAITING(等待中)等。 -
下游任务可以通过轮询上游任务的状态,直到上游任务的状态变为“成功”或“完成”,从而知道上游任务已完成。
注意事项:
-
轮询的频率要适当,如果轮询过于频繁会增加系统的负担,如果频率过低,则可能延迟下游任务的执行。
-
轮询的时间间隔需要根据任务的执行时长来设置。
2. 状态标识与更新
上游任务在完成时会在共享存储系统(如数据库、分布式任务管理系统、缓存等)中更新其状态。下游任务可以通过查询这个存储来确定上游任务是否完成。
具体做法:
-
上游任务在完成时,系统会将其状态标记为“完成”或“成功”,通常也会记录完成时间。
-
下游任务通过查询共享存储中的状态字段,判断上游任务是否已完成。
注意事项:
-
确保上游任务状态的更新操作是原子性的,不会由于并发问题导致状态不一致。
-
如果使用分布式存储,要确保分布式事务的一致性,或者使用事件驱动架构来触发下游任务。
3. 回调机制(事件驱动)
如果上游任务执行的框架支持事件驱动或回调机制,下游任务可以通过事件监听的方式,实时感知上游任务的完成状态。上游任务一旦完成,就会触发一个事件,通知下游任务。
具体做法:
-
上游任务完成时,系统会发布一个事件(如通过消息队列、事件总线等),通知下游任务上游任务的状态已变更。
-
下游任务订阅这个事件,一旦接收到上游任务完成的事件,就可以开始执行。
优点:
-
无需轮询,可以减少系统负载。
-
能够实时感知任务的状态变化。
缺点:
-
需要事件驱动系统的支持,且事件的可靠性和处理顺序需要保证。
4. 任务依赖图和工作流管理
使用任务依赖图(如 DAG,Directed Acyclic Graph)来管理任务之间的依赖关系。任务调度系统会根据依赖图和任务状态,自动管理任务的执行顺序。当上游任务完成时,下游任务会根据任务图自动触发执行。
具体做法:
-
任务调度系统(如 Apache Airflow、Celery、Kubernetes CronJobs 等)会管理任务之间的依赖关系,并在上游任务完成后自动调度下游任务。
-
下游任务根据 DAG 或任务调度器的状态,直接感知上游任务是否已完成。
优点:
-
任务调度系统会自动处理任务的依赖和状态更新,减少了手动管理。
-
在复杂的依赖关系和多任务场景中非常有效。
缺点:
-
需要额外的调度系统支持,且系统的复杂性可能会增加。
5. 任务状态与超时机制
如果下游任务依赖于上游任务的完成状态,可以设计一个超时机制,确保下游任务能够在合理的时间内感知上游任务的完成情况。如果超时且上游任务没有完成,下游任务可以执行异常处理逻辑。
具体做法:
-
设置一个合理的超时时间,定期检查上游任务是否完成。
-
如果超时,认为上游任务执行失败,或者做相应的错误处理。
优点:
-
避免下游任务长时间处于等待状态。
-
可以通过超时机制避免卡死或无效的等待。
缺点:
-
需要根据任务执行时长合理设置超时时间,否则可能会造成误判。
6. 数据库标记法
如果你的任务系统使用数据库存储任务状态,下游任务可以通过查询数据库的任务状态表来感知上游任务是否完成。
具体做法:
-
上游任务在完成时,会在数据库中将状态标记为“完成”或者“成功”。
-
下游任务定期查询任务状态表,获取上游任务的状态,并判断是否完成。
注意事项:
-
需要确保数据库中任务状态的准确性和一致性。
-
定期清理过时的状态,避免状态表过于庞大。
总结
下游任务感知上游任务是否完成,通常有以下几种方式:
-
轮询(查询):定期查询上游任务的状态。
-
状态标识更新:通过查询共享存储中的上游任务状态来判断任务是否完成。
-
回调/事件驱动:通过系统事件或消息队列,实时接收上游任务完成的通知。
-
任务调度系统:使用任务调度系统或工作流引擎(如 Airflow、Celery)自动处理任务依赖和状态管理。
-
超时机制:为下游任务设置合理的超时机制,确保不会无限等待。
每种方法都有其优点和适用场景,具体选择哪种方式,需要根据任务的复杂性、系统架构以及对实时性的要求来决定。
原文地址:https://blog.csdn.net/weixin_57197500/article/details/143893180
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!