PreCT-160K数据集:包含160K个CT体积的大规模医学图像预训练数据集,覆盖了100多种解剖结构。迄今为止最大规模的医学图像预训练数据集
2024-10-08,由香港科技大学的计算机科学与工程系创建了PreCT-160K,这是迄今为止最大规模的医学图像预训练数据集。该数据集包含了160K个CT体积,覆盖了100多种解剖结构,对于推动医学图像分析领域的发展具有重要意义,特别是在标签效率和模型泛化能力方面。
一、研究背景:
在医学图像分析领域,人工智能技术的发展近年来取得了显著进展。然而,这一领域的发展受到了专家标注成本高的限制,尤其是在大规模3D医学图像的分析上,这些图像包含了体积信息,对专家的需求量更大。
目前遇到困难和挑战:
1、标注成本高昂:医学图像分析需要大量的专家标注,这不仅耗时而且成本昂贵。
2、数据规模有限:以往的研究受限于数据规模,最多只使用了10K个体积,这限制了模型的泛化能力。
3、模型容量和预训练技术的发展不足:尽管在自然图像领域已经取得了一定的进展,但这些技术在医学图像上的转移能力尚未得到充分研究。
数据集地址:PreCT-160K|医学影像数据集|数据分析数据集
二、让我们来看一下PreCT-160K数据集
PreCT-160K:包含了160,000个计算机断层扫描(CT)体积,涵盖了超过100种不同的解剖结构。这些数据不仅在数量上超过了以往的数据集,而且在多样性上也更为丰富,覆盖了从头部到颈部、胸部、腹部等多个身体部位的CT图像。
数据集构建:
PreCT-160K数据集的过程包括从多个公开的医学图像数据库中收集和整合数据。这些数据源包括了不同地区和国家的医院,因此数据集包含了不同成像参数和质量的图像。为了确保数据的一致性,研究团队还对收集到的图像进行了细致的预处理。
数据集特点:
1、大规模:数据集的规模达到了160K个CT体积,这为训练大型模型和进行大规模预训练提供了可能。
2、多样性:涵盖了多种解剖结构,使得预训练模型能够更好地泛化到不同的医学图像分析任务。
3、高质量:尽管数据来自不同的来源,但研究团队进行了严格的预处理,确保了数据的质量和一致性。
研究人员可以使用PreCT-160K数据集进行自监督预训练,通过提出的Volume Contrast (VoCo)框架,利用几何上下文先验来进行对比学习。这种方法不需要标注数据,可以有效地利用大规模未标记的医学图像数据。
基准测试:
为了评估预训练方法的有效性,研究团队建立了一个包含48个下游数据集的全面基准测试,这些数据集涵盖了分割、分类、注册和视觉-语言等多种任务。这些基准测试不仅包括了常见的医学图像分析任务,还包括了一些未见过的模态和数据集,从而全面评估预训练模型的性能。
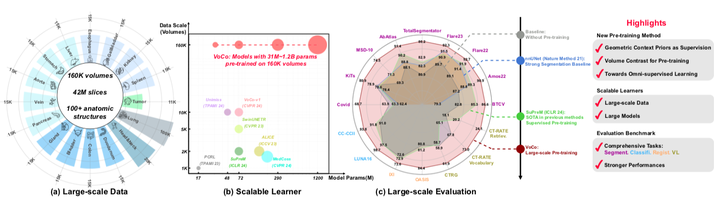
(a) 一个大规模的3D医学数据集PreCT-160K用于预训练。据我们所知,这是该领域目前最大的预训练数据集,包含160K个CT体积(4200万切片)。按照:食管 (Esophagus)、脾脏 (Spleen)、肾脏 (Kidney)、胆囊 (Gallbladder)、食管 (Esophagus)、肝脏 (Liver)、胃 (Stomach)、主动脉 (Aorta)、静脉 (Vein)、胰腺 (Pancreas)、腺体 (Gland)、膀胱 (Bladder)、结肠 (Colon)、十二指肠 (Duodenum)、头部和颈部 (Head&Neck)、肺 (Lung)。
(b) 研究了医学图像预训练中的规模法则,其中VoCo在数据规模和模型容量方面都优于之前的方法。
(c) 我们建立了一个全面的基准测试,包含48个下游数据集,涵盖不同的任务,例如分割、分类、配准和视觉-语言(VL)。
广泛的实验突出了我们提出的大规模预训练方法的有效性。
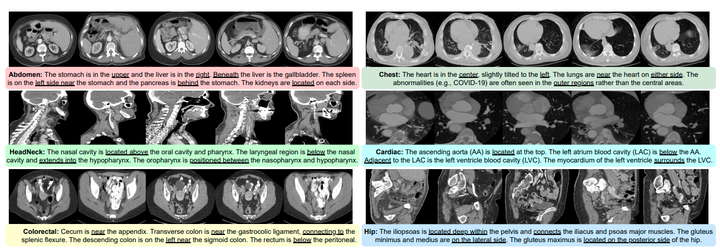
VoCo的动机。在3D医学图像中,不同器官之间的几何关系相对一致。我们从PreCT-160K中提供一些例子来说明这些不同区域之间的解剖关系。受到这一观察的启发,我们提出利用几何上下文先验来学习一致的语义表示,并引入了一个新颖的位置预测预文本任务用于预训练。
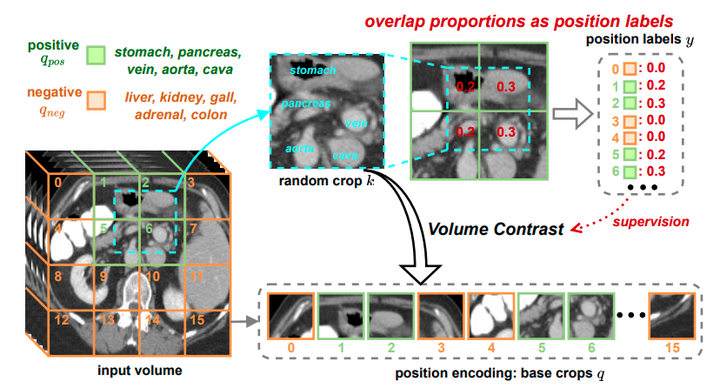
生成用于监督的位置标签。如果随机裁剪的k和基础裁剪的q共享重叠区域,则将它们配对为正样本;否则,配对为负样本。我们计算重叠比例作为位置标签y,例如,y1、y2、y5、y6分别被分配为0.2、0.3、0.2、0.3。
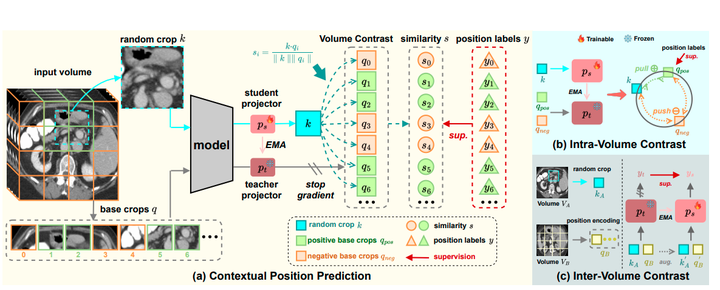
VoCo的整体框架
(a) 首先,我们生成基础裁剪图像q以及相应的位置标签y。然后,我们将随机裁剪图像k和基础裁剪图像q输入用于上下文位置预测。具体来说,我们使用一个师生模块分别对k和q进行投影,其中教师投影器是冻结的,并且使用指数移动平均(EMA)从学生投影器更新。最后,我们通过比较k和q的体积来预测相似度s(公式2),其中s由位置标签y监督(公式4)。
(b) 我们使用位置标签来监督k、qpos和qneg之间的内部体积对比,其中k、qpos和qneg来自同一体积。
(c) 我们从不同的体积VA和VB中提取随机裁剪图像kA和基础裁剪图像qB,用于体积间的对比。
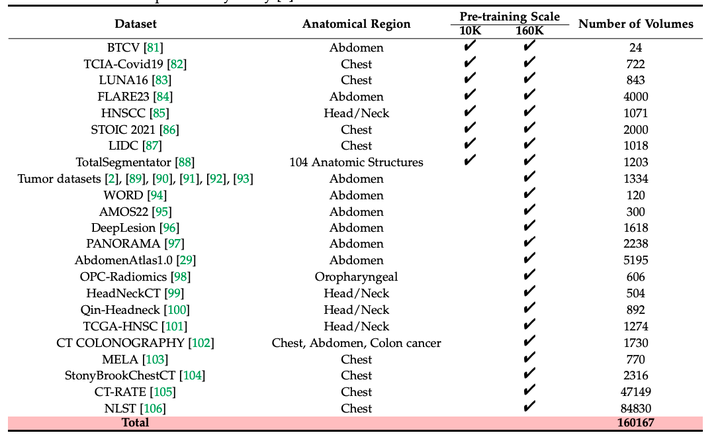
PreCT-160K包含了来自30个公共数据集的160,000个CT扫描图像,涵盖了超过4200万个切片,覆盖了解剖结构。在我们的初步研究中使用了10,000个CT扫描图像。
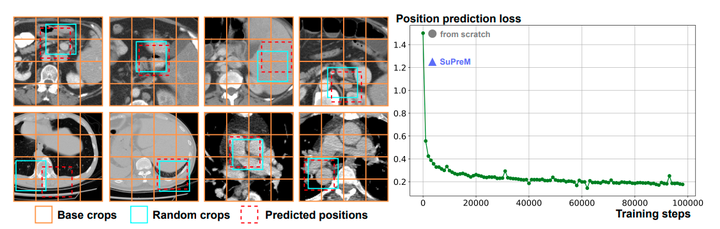
案例研究:上下文位置预测。
(1) 左侧部分显示了上下文位置预测的结果。具体来说,我们为预测逻辑值设置了阈值,以输出最可能的位置。预测结果与随机裁剪图像的原始位置非常接近。左下角是一个失败案例,其中两个区域具有相似的结构。
(2) 如右侧部分所示,位置预测损失在预训练期间稳步收敛。我们进一步验证了从头开始训练的模型和预训练的SuPreM模型的位置预测结果。值得注意的是,通过监督分割预训练,SuPreM也增强了上下文位置预测能力,间接表明了分割性能与我们提出的上下文位置预测之间存在正相关关系。
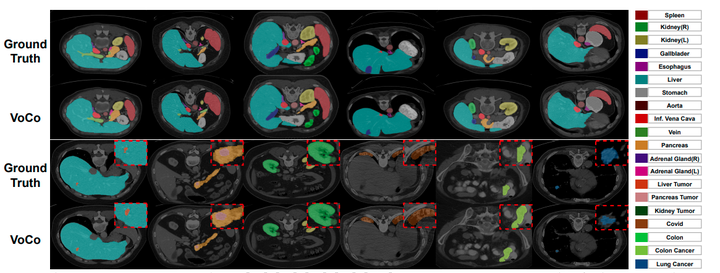
为了更好地可视化,肿瘤区域被放大显示
三、让我们一起展望PreCT-160K数据集的应用
比如,你是一名医学研究员,你的工作是研究某种罕见疾病,比如某种特殊的肺部疾病。
这种病非常少见,以至于在普通的医院里一年也见不到几例。这就意味着,如果你想要收集足够的病例来研究这个疾病,你得花费大量的时间和精力去搜集数据,这不仅效率低,而且成本高。
但现在,有了PreCT-160K数据集,情况就完全不同了。
这个数据集包含了大量的CT扫描图像,这些图像来自世界各地的不同医院,覆盖了各种各样的病例。所以,你可以直接在这个数据集上进行研究,就像是有了一个包含了世界各地罕见病例的“图书馆”。
比如说,你想要研究肺部疾病的发展模式。你可以利用PreCT-160K数据集中的图像,通过人工智能模型来分析这些CT图像,找出疾病的早期迹象。你可以训练一个模型,让它学会识别健康肺部和患病肺部之间的区别。然后,你还可以进一步训练这个模型,让它能够预测疾病的发展趋势,比如疾病可能会如何扩散,哪些区域可能会受到影响。
在这个过程中,你可能会发现一些以前没有注意到的模式。比如,你可能会发现某种特定的肺部病变总是伴随着特定的症状出现,或者某种病变的发展速度比以往认为的要快。这些发现可能会颠覆你对这种疾病的理解,甚至可能会引导你发现新的治疗方法。
而且,这个过程完全是基于数据的,所以你可以在没有实际患者参与的情况下进行研究。这意味着你可以在不打扰患者的情况下,对这种疾病进行深入的研究。这不仅提高了研究的效率,也保护了患者的隐私。
来吧,让我们走进PreCT-160K|医学影像数据集|数据分析数据集
原文地址:https://blog.csdn.net/u011559552/article/details/142999626
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!