Diffusion Model原理

🌺系列文章推荐🌺
扩散模型系列文章正在持续的更新,更新节奏如下,先更新SD模型讲解,再更新相关的微调方法文章,敬请期待!!!(本文及其之前的文章均已更新)
SD模型原理:
微调方法原理:

推荐阅读:
【生成模型】DDPM概率扩散模型(原理+代码)-CSDN博客
AIGC专栏1——Pytorch搭建DDPM实现图片生成-CSDN博客
Diffusion Model, Stable Diffusion, Stable Diffusion XL 详解_stable diffusion 训练 评价指标-CSDN博客
目录
Self-Attention Block 自注意力块最初的U-Net中的一些ResNet块被Attention Blocks取代。
概述
基本思想
最开始的扩散模型理论来源于此论文:Denoising Diffusion Probabilistic Models (DDPM)
在此论文的参考文献中有一篇,Deep Unsupervised Learning using Nonequilibrium Thermodynamics ,中文名是“基于非平衡热力学的深度无监督学习”,在此论文的Abstract(摘要)中主要介绍了其思想如下:
The essential idea, inspired by non-equilibrium statistical physics, is to systematically and slowly destroy structure in a data distribution through an iterative forward diffusion process. We then learn a reverse diffusion process that restores structure in data, yielding a highly flexible and tractable generative model of the data.
中文:受非平衡统计物理学的启发,其基本思想是通过迭代向前扩散过程系统地、缓慢地破坏数据分布中的结构。然后,我们学习一个反向扩散过程,恢复数据中的结构,产生一个高度灵活和易于处理的数据生成模型。
核心步骤
基于上述思想,Denoising diffusion 模型包括两个过程:
前向扩散过程 (Forward Diffusion): 逐渐向输入添加噪声反向去噪过程 (Reverse Denoising): 学习通过去噪生成数据

详细的扩散介绍如下。
扩散过程
摘录于:Denoising Diffusion-based Generative Modeling: Foundations and Applications
前向扩散
Forward加噪过程,对数据集的真实图片中逐步加入高斯噪声,最终变成一个杂乱无章的高斯噪声,这个过程一般发生在训练阶段。加噪过程满足一定的数学规律【确定性加噪】。

公式解释:
调度策略
以上的公式中, 是一个噪声系数,它的选择非常重要。通常,
的值会随着时间 t 逐渐增加,每一步的值由调度算法决定,常用的调度策略有线性调度和余弦调度:
线性调度
线性调度是最简单的调度策略,其中噪声参数 随时间 t 线性增加。设 T 为总的时间步数,那么线性调度可以表示为:

这种线性增长方式使得每一步的噪声量增量保持一致,保证了整个噪声添加过程的平稳性。
优点
- 实现简单:线性调度易于实现,公式简单直接。
- 适用于小规模任务:在某些简单任务上,线性调度能生成较好的数据。
缺点
- 噪声增加可能过快或过慢:在特定的生成任务中,线性调度可能导致早期噪声过少,而后期噪声增加过多,从而影响生成效果。
- 较难适应复杂数据分布:对于复杂的数据分布,线性调度的灵活性不足,可能导致模型生成的图像质量较低。
余弦调度
余弦调度是一种非线性的噪声调度策略,可以更平滑地控制噪声的增加。它通过余弦函数来调节噪声的变化,使得噪声在中间阶段增加得较多,而在两端增加得较少。余弦调度的公式通常表示为:

余弦调度将噪声增加的主要部分集中在中间阶段,而在开始和结束阶段减少噪声增加的幅度。这种策略可以让模型在初期保留更多的原始数据信息,使其在训练中更容易学习细节,并在后期避免过度加噪。
优点
-
适应性强:余弦调度能更好地适应复杂数据分布,使得生成的图像质量更高。
- 增强模型表现:在生成模型任务中,余弦调度通常比线性调度生成的图像质量更清晰,细节更丰富。
缺点
- 实现较为复杂:余弦调度的公式比线性调度复杂,参数的调整也需要更多经验。
- 计算开销略大:相比线性调度,余弦调度在计算上可能稍微复杂一些。
总结
- 线性调度适用于简单的任务,噪声增长速度均匀,适合模型在较小规模任务上生成稳定的效果。
- 余弦调度更适合复杂的生成任务,能更灵活地控制噪声的分布,通常生成的结果更细腻、逼真。
扩散核心(确定性采样公式)
使用前向扩散过程向图像逐步添加噪声将会很慢,训练过程使用的是上面的联合分布,而不是一步一步的计算。

公式解释:
1.累积噪声参数
2.联合条件分布
由之前的单步条件分布
,使用累积噪声参数替换
可以得到新单步条件分布:
3.采样公式
当然,也可以写成
4.补充噪声调度
确定性
加噪过程可以被看作是确定性公式,因为对于每个时间步 t 和固定的原始图像 ,带噪图像
是唯一确定的。
采样公式推导
条件分布和采样公式分别有两种写法。单步条件分布一种是马尔可夫链的到
,联合条件分布一种是非马尔可夫链的
到
。
从联合条件分布,根据高斯分布的采样性质,得到采样公式。

高斯分布的采样性质解释:
反向去噪
Reverse去噪过程,对加了噪声的图片/随机高斯噪声进行预测并逐步去噪,从而还原出真实图片。去噪的时候不断根据的图片生成
的噪声,从而实现图片的还原。每一步从预测的噪声中取一部分进行去噪。去噪强度由调度策略决定。前期只减去预测噪声的一小部分,后续步骤逐渐减去更多预测的噪声。

公式解释:
1.初始噪声分布
2.反向条件分布
3.反向过程的联合分布(前两个公式的结合)
调度策略
同上,线性调度、余弦调度。
扩散核心(不确定性采样公式)
注意:【TODO】待推导
在反向条件分布中,核心是使用U-Net等神经网络模型预测的均值,推导后的结果如下(两种一样,表达方式不一样):
 or
or

不确定性
去噪过程通常是非确定的。逐步去噪生成清晰图像的过程通常带有随机性,以保持生成图像的多样性和丰富性。
- 不确定性(随机性)来自于方差
:在每个时间步,新的噪声项
- 这个随机性在扩散模型的标准实现中(如 DDPM)是必需的,因为它帮助模型更自然地去噪并生成不同的样本。
当然,这里指的确定性和不确定性是依据采样方法定的,DDPM是不确定的,但是DDIM是确定的:
- DDPM(Denoising Diffusion Probabilistic Model):在每个时间步都加入一个新的随机噪声项
- DDIM(Denoising Diffusion Implicit Model):DDIM 是一种确定性的采样方法。在 DDIM 中,去噪过程不再在每一步引入随机噪声(即
),使得去噪过程是确定的。如果使用相同的初始噪声
,DDIM 在每次去噪中都会生成完全一致的图像。这种确定性非常适合需要生成稳定输出的应用场景。【确定性采样:去掉了随机噪声项,避免了随机扰动;通过跳跃步数加速生成:减少时间步数,跳跃去噪】
采样公式推导
给出采样公式(给定时间步t时刻的输出):
预测噪声
从上面的解释中,我们分析到ni
那么如何得到预测噪声
?
预测噪声是通过前向传播(forward pass)得到的。
1.前向传播输入
- 加噪后的图像
2.前向传播阶段(U-Net中)
- 编码器阶段:U-Net 的编码器部分将输入(加噪后的图像)逐层下采样,提取出多尺度的特征表示。在这个过程中,时间步嵌入 t 会在每一层与图像特征进行融合(通常是通过加法或逐元素乘法)。
- 跳跃连接:在编码和解码过程中,跳跃连接将编码器的特征直接传递到解码器相应的层,以保留空间信息和细节。
- 解码器阶段:解码器逐步上采样特征并恢复分辨率。时间步嵌入也会在解码过程中被加入到不同层的特征中,帮助解码器理解去噪的阶段。
3.前向传播输出
- 在解码器的最后一层,U-Net 生成一个与输入
相同尺寸的输出图像,这个输出即为预测的噪声
训练和推理过程
DDPM的训练和推理过程伪代码如下:

训练过程
训练过程的目标是训练去噪模型。通过训练Unet模型,该模型输入为和
,输出为
时刻预测的高斯噪声
。即利用
和
预测这一时刻的高斯噪声
,通过最小化真实加入的噪声
和预测的噪声
之间的差距(目标是让模型尽可能准确地预测添加到
中的真实噪声
)。

解释:
- 数据集中采样一张图片
- 采样一个时间步
- 从正态分布中采样一个噪音
- 前面我们定义了如何在时间步时刻,在无需迭代的情况下前向加噪
,然后用梯度下降(反向预测噪声)去训练网络模型预测噪声
的能力。
- 然后重复整个过程,直到模型最终收敛。
推理过程
推理/采样过程的目标是从纯噪声生成高质量图像。输入是随机高斯噪声或者加噪后的图像。输出是符合prompts的图像。

1. 初始化纯噪声(第1步):从标准正态分布 中采样一个随机噪声
,作为起点。
2. 逐步去噪(第2-5步):从时间步 开始,逐步将噪声去除,恢复原始数据
。公式为:
是当前时间步的带噪图像。
是模型预测的噪声。
是随机噪声,用于在去噪过程中保持生成的随机性。
是一个与噪声相关的可调参数。
3. 输出生成的图像(第6步):经过次迭代后,最终得到去噪后的图像
。
网络结构
摘录于:Step by Step visual introduction to Diffusion Models. - Blog by Kemal Erdem

模型架构使用修改后的 U-Net 架构(原始架构如上图所示,来自https://arxiv.org/pdf/1505.04597)。这里的U-net架构针对扩散模型做了进一步改进。在这里,先只讨论Diffusion Model的最初版本。(后面的SD系列有更大的改进)
各模块层及其作用

ResNet Block 残差块

我们要讨论的第一个块是ResNet块。这个版本中的ResNet块是简单和线性的。该块稍后用作下采样和上采样块的一部分。
Downsample Block 下采样块
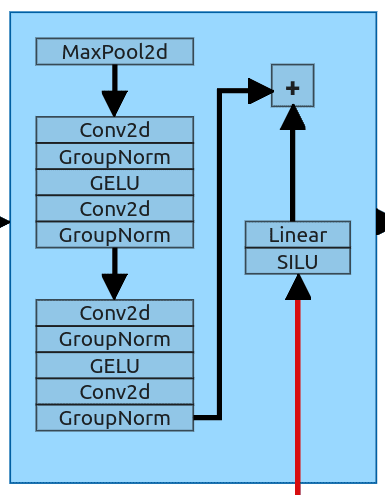
下采样块是第一个不仅接收来自前一层的数据而且接收关于时间步长和提示的数据的块。该模块有2个输入,表现为U-Net架构的标准下采样。它获取一个输入并将其下采样到下一层的大小。它使用MaxPool 2d层(内核大小2),将输入大小减半(64 x64-> 32 x32)。之后,我们有2个ResNet块(与图12中的整个层相同)。
嵌入使用Sigmoid Linear Unit进行处理,并通过简单的线性层发送,以实现与ResNet块的输出相同的形状。之后,两个张量彼此相加并发送到下一个块。
Self-Attention Block 自注意力块
最初的U-Net中的一些ResNet块被Attention Blocks取代。

为了让注意力发挥作用,我们需要重塑我们的输入。所有注意力块的结构都是相同的,所以我将使用第一个来描述所有的注意力块(第一个下采样之后的注意力块)。它接收具有形状(128,32,32)的下采样张量。这将是多头注意力(MHA),嵌入维度设置为128和4个注意力头。嵌入尺寸在注意力块之间变化(取决于输入长度),头部的数量保持不变。
为了使用我们的MHA,我们需要修改输入并创建Q,K,V张量。我们的输入长度为128,大小为32 x32。首先,我们压缩最后两个维度,然后翻转得到的张量(128,32,32)->(128,1024)->(1024,128)。我们将其通过层归一化,并将其用作所有3个输入张量(Q,K,V)。
在块内,作者添加了2个跳过连接,以与自我注意力输出相结合。第一个将纯整形的输入添加到注意力层的输出中,并将其传递给前向层(Normalization -> Linear -> GELU -> Linera)。第二个从该层获取输出,并将其添加回注意力的输出。最后,我们需要反转张量(1024,128)->(128,32,32)的初始整形。
Upsample block 上采样块
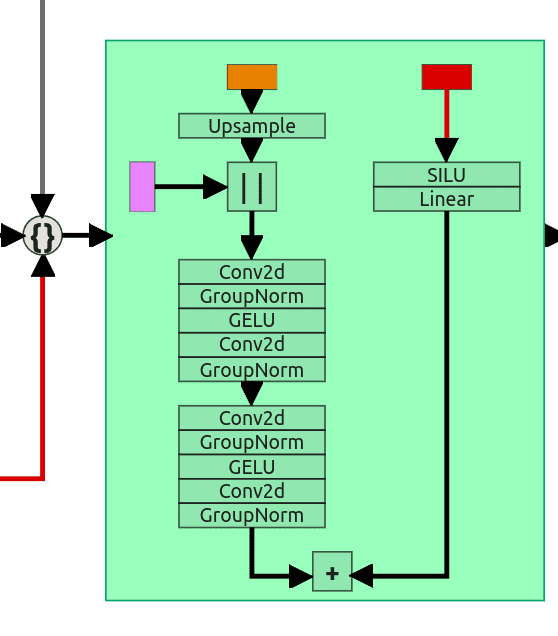
上采样有点复杂,因为我们有3个输入。来自前一层的输入(在第5个自注意块的情况下)具有不兼容的维度。因为它是“上采样”块,所以它使用比例因子为2的简单上采样层。在将输入张量传递到上采样层之后,我们可以将其与残差连接(来自第一个ResNet块)连接起来。现在它们都具有相同的形状(64,64,64)。然后通过2个ResNet块发送级联张量(与我们在下采样块中所做的相同)。
第三个输入(与下采样块相同)通过SILU和线性层发送,然后添加到第二个ResNet块的结果中。
整个架构以Conv2d层结束,它使用1的内核大小将我们的张量从(64,64,64)缩放回(3,64,64)。这是我们预测的噪音。
更改后的U-Net架构
1.We start with the modified U-Net architecture. Basic ResNet Blocks were replaced by either Self-Attention blocks or modified ResNet blocks.

2.To prevent information lose, we're adding skip connections to the upsampling blocks. Notice where those connections are coming from.

3. The next step is to add information about the current timestep t. To do that we're using sinusoidal embedding and that information is added to all downsample and upsample blocks.

4.To make the network conditional (dependent on the external input), we're adding a text embedder. It will create embedding for given text and add output vector to the timestep embedding.

模型训练和推理
参考【生成式AI】Diffusion Model 原理剖析 (1/4) (optional)
参考文件
详细的数学公式推导:What are Diffusion Models? | Lil'Log
DDPM详细讲解(视频和PPT):Denoising Diffusion-based Generative Modeling: Foundations and Applications
Step by Step visual introduction to Diffusion Models. - Blog by Kemal Erdem

原文地址:https://blog.csdn.net/qq_42410605/article/details/143256188
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!