NLP论文速读(EMNLP 2023)|工具增强的思维链推理
论文速读|ChatCoT: Tool-Augmented Chain-of-Thought Reasoning on Chat-based Large Language Models
论文信息:

简介:
本文背景是关于大型语言模型(LLMs)在复杂推理任务中的表现。尽管LLMs在多种评估基准测试中取得了优异的成绩,它们在需要特定知识和多跳推理的复杂推理任务上仍然存在挑战。这些任务通常涉及数学计算、信息检索等特定功能。为了提升LLMs的推理能力,研究者们提出了结合外部工具(如计算器、搜索引擎)的方法,但这些工具与LLMs的内在整合并不理想,导致在复杂推理任务中频繁调用工具时出现问题。因此,本文旨在提出一种新的方法,以更自然的方式通过聊天工具增强LLMs的推理能力。
论文方法:
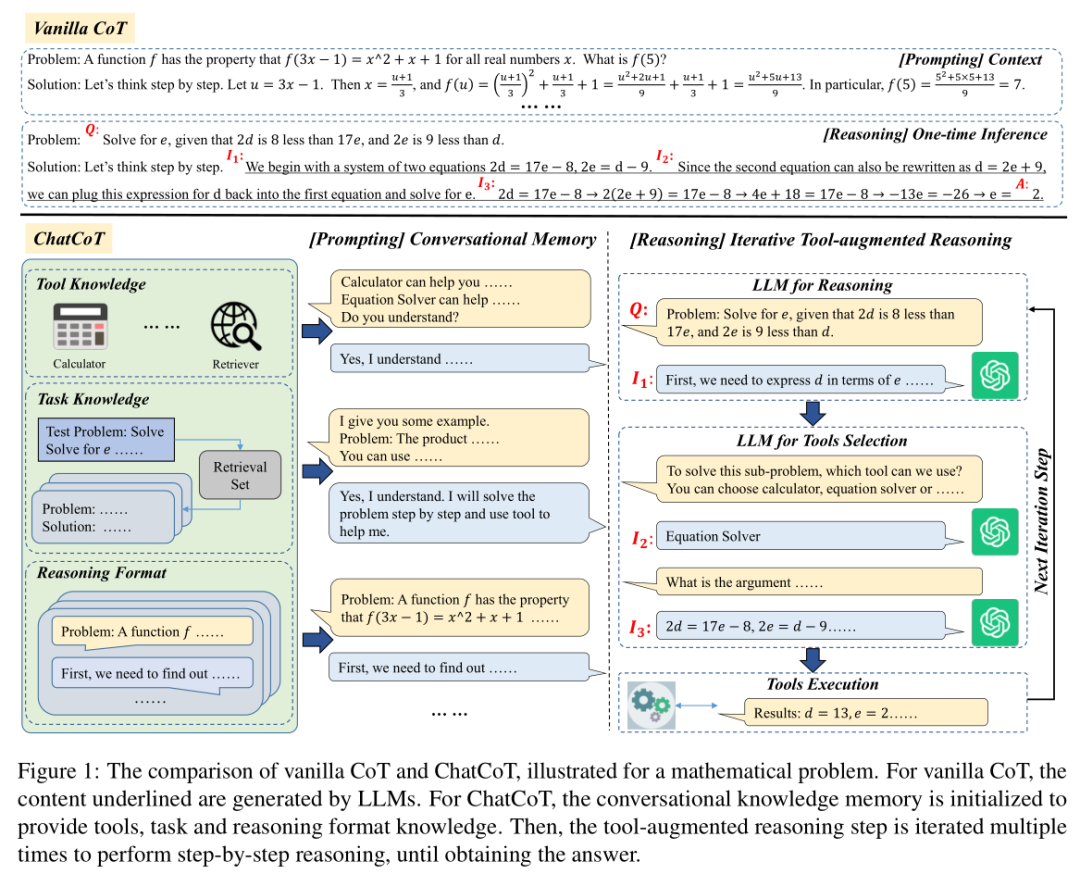
本文动机在于现有的LLMs在处理需要特定知识和多步骤推理的复杂任务时存在困难,尤其是在需要调用外部工具时。现有的方法要么需要LLMs预先规划工具使用计划,要么需要在推理和执行动作之间频繁切换,这些都影响了推理过程的连续性。因此,本文寻求一种更统一的方式来整合链式推理(CoT)和工具操作,以提高LLMs在复杂任务中的推理能力。
本文提出了一个名为ChatCoT的工具增强型链式推理框架,用于基于聊天的LLMs。ChatCoT将链式推理(CoT)建模为多轮对话,使得LLMs能够更自然地通过聊天与工具进行交互。在每一轮对话中,LLMs可以与工具交互或执行推理。具体方法如下:
初始化对话知识记忆:在对话的早期阶段,通过提供关于工具、任务和推理格式的知识,帮助LLMs利用特定任务的知识进行推理或操作工具。
迭代工具增强推理步骤:设计了一个特别的工具增强推理步骤,其中LLMs与工具交互,执行逐步的工具增强推理,直到获得最终答案。
工具知识:为LLMs提供关于工具的描述,使其了解工具的用途。
检索增强任务知识:使用检索器从训练数据集中选择最相关的实例,提供更多有用的知识。
多轮推理格式:通过手动标注多轮对话,创建示例,引导LLMs遵循多轮推理格式。
工具选择和执行:在每一步中,LLMs首先执行推理,然后选择适当的工具,并执行所选工具以获得当前步骤的中间结果。
迭代推理:基于对话知识记忆,迭代执行上述步骤,直到最终得出答案。
论文实验:
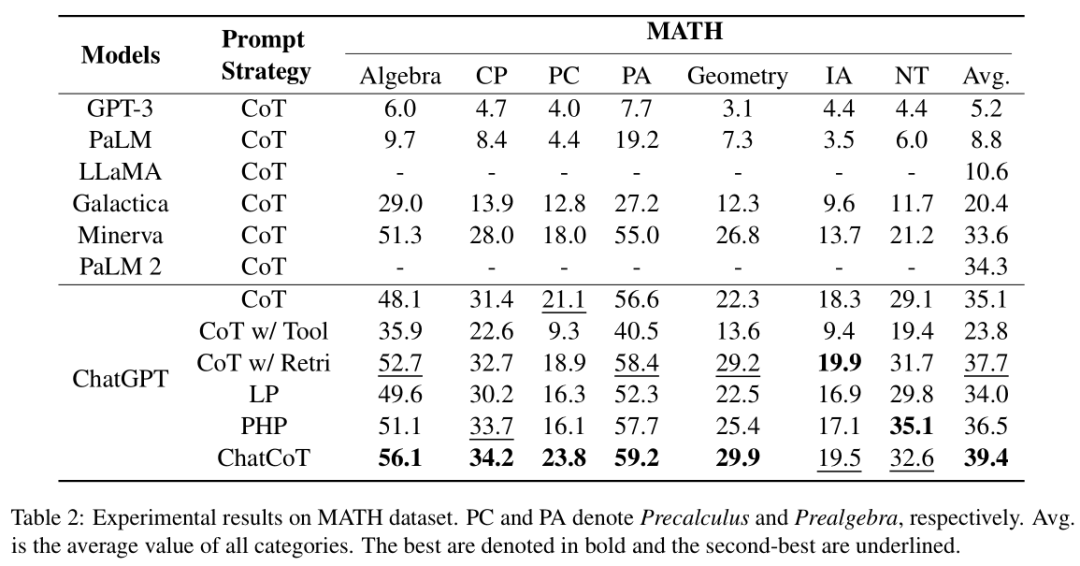
论文比较了ChatCoT方法与其他几种基于ChatGPT的提示策略,包括链式思考(CoT)、CoT结合工具使用(CoT w/ Tool)、CoT结合检索(CoT w/ Retri)、编程学习(LP)和逐步提示(PHP)。论文还比较了不同大型语言模型(LLMs)使用原始CoT提示策略的性能,包括GPT-3、PaLM、PaLM 2、Minerva、Galactica、LLaMA和ChatGPT。实验结果验证了ChatCoT在复杂推理任务中的有效性,通过利用对话知识记忆和多轮对话推理,ChatCoT能够利用即插即用的工具。尽管ChatCoT在MATH数据集的数论任务上表现不如PHP,但整体而言,ChatCoT在复杂推理任务上表现出色,尤其是在需要频繁调用工具的情况下。
论文链接:
https://aclanthology.org/2023.findings-emnlp.985/
原文地址:https://blog.csdn.net/2401_85576118/article/details/143928287
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!