数据分析 变异系数
目录
简单来讲就是平均值/标准差
变异系数(Coefficient of Variation, CV)是一种相对量的变异指标,常用于衡量数据的离散程度。它通过标准差与均值的比值来表示,消除了单位差异的影响,使得不同量纲、均值不同的数据之间可以直接比较其离散程度。
一般来说,变量值平均水平高,其离散程度的测度值越大,反之越小。编辑变异系数
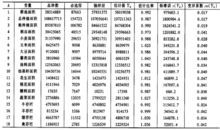{kind=link}
变异系数是衡量资料中各观测值变异程度的另一个统计量。当进行两个或多个资料变异程度的比较时,如果度量单位与平均数相同,可以直接利用标准差来比较。如果单位和(或)平均数不同时,比较其变异程度就不能采用标准差,而需采用标准差与平均数的比值(相对值)来比较。标准差与平均数的比值称为变异系数,记为C·V。变异系数可以消除单位和(或)平均数不同对两个或多个资料变异程度比较的影响。
变异系数的计算公式为:变异系数 C·V =( 标准偏差 SD / 平均值Mean )× 100%
在进行数据统计分析时,如果变异系数大于15%,则要考虑该数据可能不正常,应该剔除。
其中 �σ 是标准差,�μ 是均值。
变异系数的应用场景包括:
- 比较不同样本之间的离散程度:对于具有不同均值的数据集,直接比较标准差可能不合适,此时可以使用变异系数进行比较。
- 风险评估:在金融领域,变异系数可用于评估投资风险。
- 科学实验:在生物学、物理学等领域的实验数据分析中,变异系数可以帮助理解数据的波动性。
特点:
- 无量纲,适用于不同单位和规模的数据。
- 当均值接近于零或很小时,变异系数可能会变得很大或不稳定。
注意事项:
- 对于负数或非常小的均值,变异系数的解释需要谨慎。
- 数据分布严重偏斜时,变异系数的结果可能不够准确。
总的来说,变异系数提供了一个标准化方法来量化数据的变异性,使其在不同情况下更具可比性和解释力。
书上使用平均值/{方差+0.01}
np.nanvar——方差,np.sanstd标准差
np.nanvar 是 NumPy 库中的一个函数,用于计算沿指定轴的方差,同时忽略 NaN 值。因此,np.nanvar 是用来求方差的,而不是标准差。
标准差是方差的平方根。NumPy 提供了另一个函数 np.nanstd 来计算忽略 NaN 值的标准差。
以下是如何使用 np.nanvar 和 np.nanstd 的示例:
import numpy as np
# 创建一个包含 NaN 值的数组
data = np.array([1, 2, np.nan, 4, 5])
# 计算 NaN 被忽略的方差
variance = np.nanvar(data)
# 计算 NaN 被忽略的标准差
standard_deviation = np.nanstd(data)
print("Variance (ignoring NaN):", variance)
print("Standard Deviation (ignoring NaN):", standard_deviation)
在上面的例子中,np.nanvar(data) 将计算数组 data 中非 NaN 值的方差,而 np.nanstd(data) 将计算这些值的 standard deviation。
原文地址:https://blog.csdn.net/m0_68339197/article/details/145312254
免责声明:本站文章内容转载自网络资源,如侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!