MySQL分区及索引
概述
分区概述
在 MySQL 中, InnoDB存储引擎长期以来一直支持表空间的概念。在 MySQL 8.0 中,同一个分区表的所有分区必须使用相同的存储引擎。但是,也可以为同一 MySQL 服务器甚至同一数据库中的不同分区表使用不同的存储引擎。
通俗地讲表分区是将一大表,根据条件分割成若干个小表。MySQL 5.1开始支持数据表分区操作。为了改善大型表以及具有各种访问模式的表的可伸缩性,可管理性和提高数据库效率,我们做出了表分区的概念。表分区有如下优点:
- 存储更多的数据
- 对于失去保存意义的数据,删除有关的分区,很容易地删除那些数据,相比较delete语句和truncate语句,删除分区更容易。
- 查询可以得到极大优化,虽然可以增加索引、主键和外键。
- 很容易地进行并行处理聚合函数SUM()和COUNT()。
- 增加查询吞吐量。
重要:分区适用于表的所有数据和索引;您不能只对数据进行分区而不对索引进行分区,反之亦然,也不能只对表的一部分进行分区。
分区类型
MySQL 8.0 中可用的分区类型。其中包括此处列出的类型:
- 范围分区。 这种类型的分区根据落在给定范围内的列值将行分配给分区。
- LIST 分区。 类似于分区 by RANGE,不同之处在于分区是根据与一组离散值中的一个匹配的列来选择的。
- 哈希分区。 使用这种类型的分区,根据用户定义的表达式返回的值选择分区,该表达式对要插入表的行中的列值进行操作。
- KEY分区。 这种类型的分区类似于分区 by HASH,只是只提供了一个或多个要评估的列,并且 MySQL 服务器提供了自己的散列函数。
- 列分区。包含列范围分区(RANGE COLUMNS partitioning)和列集合分区(LIST COLUMNS partitioning)。
- 子分区。子分区(也称为 复合分区(Subpartitioning))是对分区表中每个分区的进一步划分。
数据库分区的一个非常常见的用途是按日期分隔数据。一些数据库系统支持显式日期分区,而 MySQL 在 8.0 中没有实现。但是,在 MySQL 中创建基于[DATE]、 [TIME]、 或 [DATETIME]列或基于使用这些列的表达式的分区方案并不困难 。MySQL的分区是采用最优化 [TO_DAYS()], [YEAR()]和 [TO_SECONDS()]功能,也可以使用其他日期和时间函数返回一个整数或者NULL。
重要:要记住——无论您使用哪种分区类型——分区总是在创建时自动按顺序编号,从 0. 当新行插入到分区表中时,这些分区号用于标识正确的分区。
1 分区管理
RANGE 分区和 LIST 分区的管理的新增和删除差不多,下面我就用比较常用的RANGE 分区作为实战。
1.1 创建带有分区的表
可以在命令行执行,也可以在工具Navicat界面工具里面执行下面的语句,下面我将展示我在Navicat界面工具里面执行情况以及执行后返回的结果。
【插入数据脚本】
CREATE TABLE tb_tr (
id INT COMMENT "ID编号",
name VARCHAR(50) COMMENT "名称",
purchased DATE COMMENT "购买时间",
PRIMARY KEY (`id`, `purchased`) USING BTREE COMMENT "主键",
INDEX `idx_id`(id) COMMENT "索引-id",
INDEX `idx_name`(name) COMMENT "索引-名称",
INDEX `idx_purchased`(purchased) COMMENT "索引-购买"
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic
COMMENT '购买日志'
PARTITION BY RANGE( YEAR(purchased) ) (
PARTITION p0 VALUES LESS THAN (1990) ENGINE = InnoDB,
PARTITION p1 VALUES LESS THAN (1995) ENGINE = InnoDB,
PARTITION p2 VALUES LESS THAN (2000) ENGINE = InnoDB,
PARTITION p3 VALUES LESS THAN (2005) ENGINE = InnoDB,
PARTITION p4 VALUES LESS THAN (2010) ENGINE = InnoDB,
PARTITION p5 VALUES LESS THAN (2015) ENGINE = InnoDB,
PARTITION p6 VALUES LESS THAN (2020) ENGINE = InnoDB
PARTITION pmax VALUES LESS THAN (MAXVALUE) ENGINE = InnoDB
);
OK, Time: 0.055000s
【插入数据结果展示】

这里我创建了名称为p0、p1、p2、p3、p4、p5、pmax 六个分区。其中p0和pmax分区比较特别,这里可以理解为数学上面的分区函数或分段函数,从函数上,很好理解分区到底是什么概念。
六个分区。其中p0和pmax分区比较特别,这里可以理解为数学上面的分区函数或分段函数,从函数上,很好理解分区到底是什么概念。

1.2 插入几条数据
【插入数据脚本】
INSERT INTO tb_tr VALUES
(1, 'desk organiser', '2003-10-15'),
(2, 'alarm clock', '1997-11-05'),
(3, 'chair', '2009-03-10'),
(4, 'bookcase', '1989-01-10'),
(5, 'exercise bike', '2014-05-09'),
(6, 'sofa', '1987-06-05'),
(7, 'espresso maker', '2011-11-22'),
(8, 'aquarium', '1992-08-04'),
(9, 'study desk', '2006-09-16'),
(10, 'lava lamp', '1998-12-25');
Affected rows: 10, Time: 0.004000s
【插入数据结果展示】

1.3 查看分区内的数据
下面的结果是一样的,但是效果不一样。可以使用EXPLAIN查看下执行计划。
SELECT * FROM tb_tr PARTITION (p2);
SELECT * FROM tb_tr WHERE purchased BETWEEN '1995-01-01' AND '1999-12-31';
1.4 删除分区
删除分区时,也会删除该分区中存储的所有数据。必须先拥有该[DROP](表的 权限,然后才能ALTER TABLE … DROP PARTITION对该表执行。
ALTER TABLE tb_tr DROP PARTITION p2;
OK, Time: 0.022000s
那有没有可以在不删除数据的情况下,删除分区呢?答案是有的,请使用ALTER TABLE ... REORGANIZE PARTITION改用。对于按范围分区的表,您只能 ADD PARTITION将新分区添加到分区列表的高端。这就意味着,需要从pmax分区再次分出来一张表空间,例如
1.5 增加分区
1.5.1 增加分区
如果使用这种方式增加分区,那么你得到的将会是错误的提示
1481 - MAXVALUE can only be used in last partition definition, Time: 0.002000s
1.5.2 重新组织为两个新分区
ALTER TABLE tb_tr
REORGANIZE PARTITION pmax INTO (
PARTITION p6 VALUES LESS THAN (2020) ENGINE = InnoDB,
PARTITION n1 VALUES LESS THAN (MAXVALUE) ENGINE = InnoDB
);
在增加分区时,新的RANGE分区方案不能有任何重叠范围;新的LIST 分区方案不能有任何重叠的值集。分区的表RANGE,您只能重组相邻的分区;您不能跳过范围分区。分区也不是无限制的分区下去,不使用[NDB]存储引擎的给定表的最大可能分区数是 8192。
1.6 查询已经创建分区
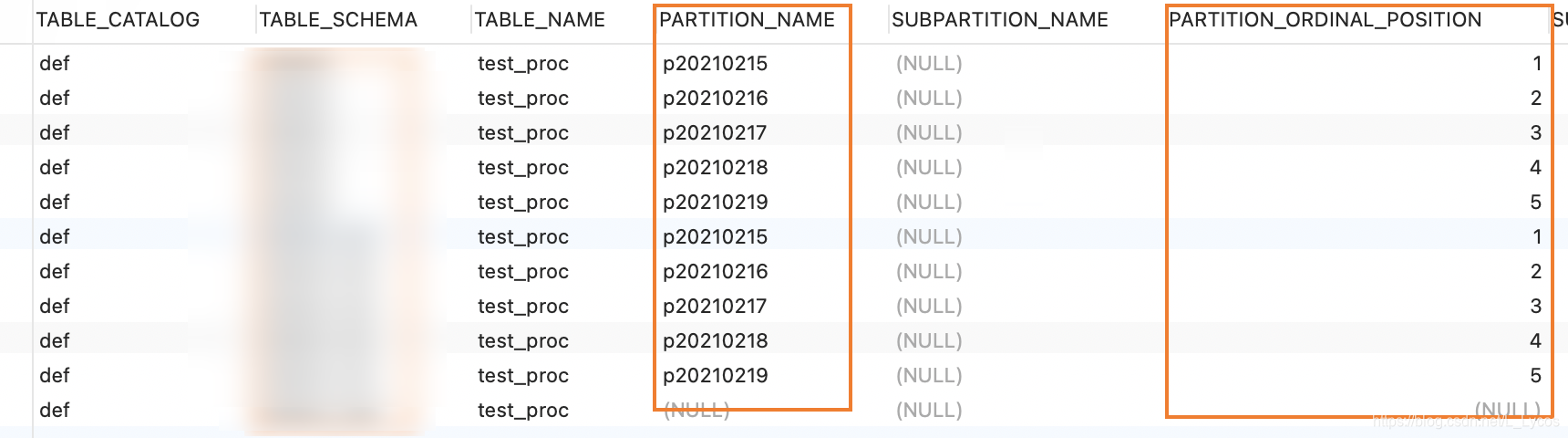
【查询数据脚本展示】
SELECT * FROM information_schema.`PARTITIONS` WHERE table_schema = 【dbName】 and table_name = "【tableName】";
【查询数据结果展示】
2 分区限制条件
2.1 禁止的构造。
分区表达式中不允许使用以下结构:
- 存储过程、存储函数、可加载函数或插件。
- 声明的变量或用户变量。
当然下面自带的函数除外:
ABS()CEILING()DATEDIFF()DAY()DAYOFMONTH()DAYOFWEEK()DAYOFYEAR()EXTRACT()FLOOR()HOUR()MICROSECOND()MINUTE()MOD()MONTH()常用QUARTER()SECOND()TIME_TO_SEC()TO_DAYS()常用TO_SECONDS()UNIX_TIMESTAMP()(withTIMESTAMPcolumns)WEEKDAY()YEAR()YEARWEEK()
上面的函数可以在分区中使用,这样子就可以按照需求来制定自己的分区。
2.2 允许在分区中使用运算符
- 算术、逻辑运算符
允许在分区表达式中 使用算术运算符 +、 -和 *。但是,结果必须是整数值或NULL
- 位运算符 | 、&、 ^、 <<、 >>、 ~不允许在分区表达式中使用。
- 分区 InnoDB 表不支持外键
- 全文索引。 分区表不支持
FULLTEXT索引或搜索。 - 空间列。 具有空间数据类型(例如
POINT或GEOMETRY不能在分区表中使用)的列。 - 临时表。 临时表不能分区。
- 日志表。 无法对日志表进行分区;[
ALTER TABLE ... PARTITION BY ...]此类表上的 语句因错误而失败。 - 分区键的数据类型。 分区键必须是整数列或解析为整数的表达式。[
ENUM]不能使用使用列的表达式 。列或表达式值也可能是NULL; 例外情况参考官网。
3 分区索引
3.1 分区索引概述
mysql分区后每个分区成了独立的文件,虽然从逻辑上还是一张表其实已经分成了多张独立的表,从“information_schema.INNODB_SYS_TABLES”系统表可以看到每个分区都存在独立的TABLE_ID,由于Innodb数据和索引都是保存在".ibd"文件当中(从INNODB_SYS_INDEXES系统表中也可以得到每个索引都是对应各自的分区(primary key和unique也不例外)),所以分区表的索引也是随着各个分区单独存储。
在INNODB_SYS_INDEXES系统表中type代表索引的类型;
0:一般的索引,
1:(GEN_CLUST_INDEX)不存在主键索引的表,会自动生成一个6个字节的标示值,
2:unique索引,
3:primary索引;
所以当我们在分区表中创建索引时其实也是在每个分区中创建索引,每个分区维护各自的索引(其实也就是local index);对于一般的索引(非主键或者唯一)没什么问题由于索引树中只保留了索引key和主键key(如果存在主键则是主键的key否则就是系统自动生成的6个的key)不受分区的影响;但是如果表中存在主键就不一样了,虽然在每个分区文件中都存在主键索引但是主键索引需要保证全局的唯一性就是所有分区中的主键的值都必须唯一(唯一键也是一样的道理),所以在创建分区时如果表中存在主键或者唯一键那么分区列必须包含主键或者唯一键的部分或者全部列(全部列还好理解,部分列也可以个人猜测是为了各个分区和主键建立关系),由于需要保证全局性又要保证插入数据更新数据到具体的分区所以就需要将分区和主键建立关系,由于通过一般的索引进行查找其它非索引字段需要通过主键如果主键不能保证全局唯一性的话那么就需要去每个分区查找了,这样性能可想而知。
To enforce the uniqueness we only allow mapping of each unique/primary key value to one partition.If we removed this limitation it would mean that for every insert/update we need to check in every partition to verify that it is unique. Also PK-only lookups would need to look into every partition.
3.2 分区索引方式
性能依次降低
1.主键分区
主键分区即字段是主键同时也是分区字段,性能最好
2.部分主键+分区键索引
使用组合主键里面的部分字段作为分区字段,同时将分区字段建索引(这种方式下两种索引)
-
前缀索引(local prefixed index):以分区键作为索引定义的第一列
-
非前缀索引(local nonprefixed index):分区键没有作为索引定义的第一列
--范围分区
--创建表
create table student_range_part(
stu_id varchar2(4),
stu_name varchar2(100), --姓名
sex varchar2(1), --性别 1 男 2 女 0 未知
credit integer default 0
)
partition by range (credit)
(
partition student_part1 values less than (60) tablespace kdhist_data,
partition student_part2 values less than (70) tablespace kdhist_data,
partition student_part3 values less than (80) tablespace kdhist_data,
partition student_part4 values less than (maxvalue) tablespace kdhist_data
);
--创建局部前缀索引;分区键(credit)作为索引定义的第一列
create index local_prefixed_index on student_range_part (credit, stu_id) local;
--创建局部非前缀索引;分区键未作为索引定义的第一列
create index local_nonprefixed_index on student_range_part (stu_id, credit) local;
-- 索引查询示例
①
select * from student_range_part where credit = &credit and stu_id = &stu_id;
②
select * from student_range_part where stu_id = &stu_id;
对于以上两个查询来说,如果查询第一步是走索引的话,则:
局部前缀索引 local_prefixed_index 只对 ① 有用;
局部非前缀索引 local_nonprefixed_index 则对 ① 和 ② 均有用;
如果你有多个类似 ① 和 ② 的查询的话,则可以考虑建立局部非前缀索引;如果平常多使用查询 ① 的话,则可以考虑建立局部前缀索引;
3.分区索引
没有主键,只有分区字段且分区字段建索引
4.分区+分区字段没有索引
只建了分区,但是分区字段没有建索引
3.3 总结
因为每一个表都需要有主键这样可以减少很多锁的问题,由于上面讲过主键需要解决全局唯一性并且在插入和更新时可以不需要去扫描全部分区,造成主键和分区列必须存在关系;所以最好的分区效果是使用主键分区其次是使用部分主键+分区键索引,其它分区方式都建议不采取。
F&Q
有些时候,写着,写着,也会翻车,例如,我在实际操作过程中遇到很多问题,但是有了网络之后,就开始搜罗,一点点解决。
Q1:定时处理这些数据
需求描述:
我搜索了一番,将上述的表分区整理成为了按照月度来进行调度分区,然后根据月度来将3个月前的数据迁移到第三张表history表,history是基本上不使用的表,结构同业务表。
具体的思路:
1:创建相同结构的表;
2:创建一个函数,这个函数用于分区
3:创建一个事件,在每月的1号调用分区函数,创建分区,这个分区是两张表(业务表和业务_history表)
4:创建一个函数,用于查询业务数据插入到业务历史表,并删除业务表的数据和分区
5:创建一个事件,用于每月1号调用处理数据函数,迁移数据、删除分区
原文地址:https://blog.csdn.net/liudachu/article/details/143565944
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!