如何通过高效的缓存策略无缝加速湖仓查询
引言
本文将探讨如何利用开源项目 StarRocks 的缓存策略来加速湖仓查询,为企业提供更快速、更灵活的数据分析能力。作为 StarRocks 社区的主要贡献者和商业化公司,镜舟科技深度参与 StarRocks 项目开发,也为企业着手构建湖仓架构提供更多参考。
随着数据湖仓和查询引擎架构的发展,开放文件格式和表格格式为数据分析带来了更好的生态兼容性和灵活性。然而,在实际应用中,特别是面向用户的实时查询场景下,数据湖的查询性能往往难以满足需求。一、Data Cache 面临的挑战
然而,简单地添加缓存并不能解决所有问题,实践中往往面临以下挑战:
- 数据一致性风险:Cache 很容易遇到过期失效的问题,缓存更新不及时可能导致查询结果不准确,数据变更难以实时反映到缓存层;
- 资源利用效率:为了降低维护成本,一些企业会选择使用本地缓存,但是本地缓存需要预留固定磁盘空间,缺乏灵活性,资源无法根据负载动态调整;
- 性能优化瓶颈:频繁的缓存操作会增加系统开销,当缓存的文件过多的时候,大量文件会带来额外系统开销以及锁的问题。当本地磁盘压力过大的时候,强行去读写缓存反而可能会导致性能瓶颈;
- 运维成本增加:需要额外的人力进行系统的监控和维护工作,同时,系统上下游生态的整合与打通也都会带来额外的成本问题。
二、如何构建完善的 Data Cache 解决方案?
Cache 是一个查询加速的手段而不是目标。为了解决上述 Cache 带来的问题,企业需要构建具备以下特性的的缓存系统:
1. 数据一致性: 通过元数据管理确保数据时效性,实现实时感知数据更新,避免提供过期的数据。5. 高效的缓存架构设计:尽量降低因读写缓存文件而产生的系统操作。并且将缓存的填充过程异步化,从而可以在不显著消耗资源的情况下保持高查询性能。
三、利用 StarRocks 构建高效的缓存策略
构建高效的缓存策略不仅需要设计所提出的文件结构,还需要动态处理各种复杂的细节。
StarRocks 是一个开源的 MPP 查询引擎,旨在处理开放数据湖上的仓库类工作负载。它支持 Iceberg、Delta 和 Hudi 等流行的表格格式,以及 Parquet 和 ORC 等文件格式。StarRocks 结合了很多各种特性和优化,来在数据湖上提供快速、可靠的查询性能,其中磁盘的发挥起到了关键作用。
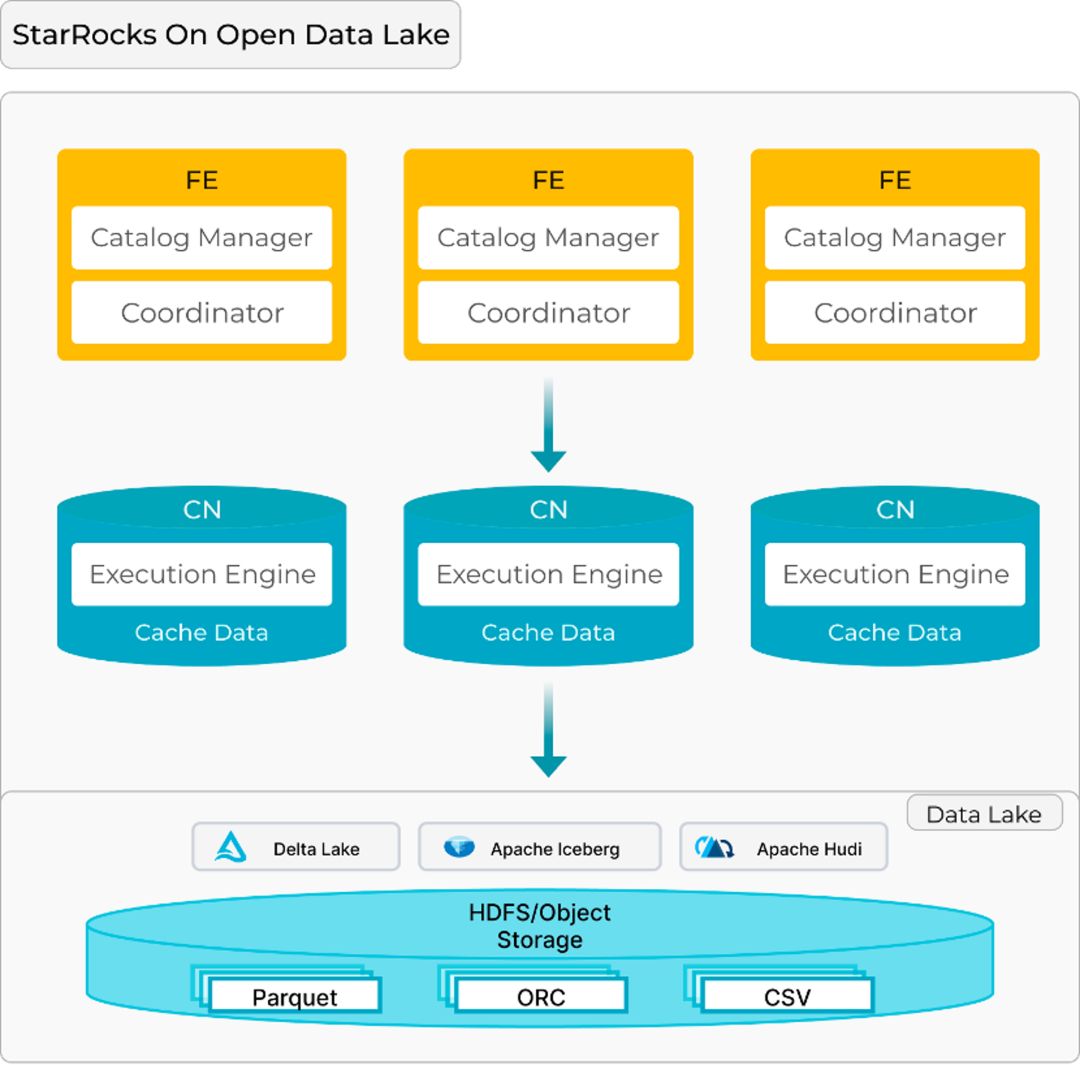
- 前端节点(FE):负责元数据管理,执行查询规划,并协调查询的整体执行。
- 计算节点(CN):处理实际的数据缓存和处理任务。
四、StarRocks 是如何处理缓存的?
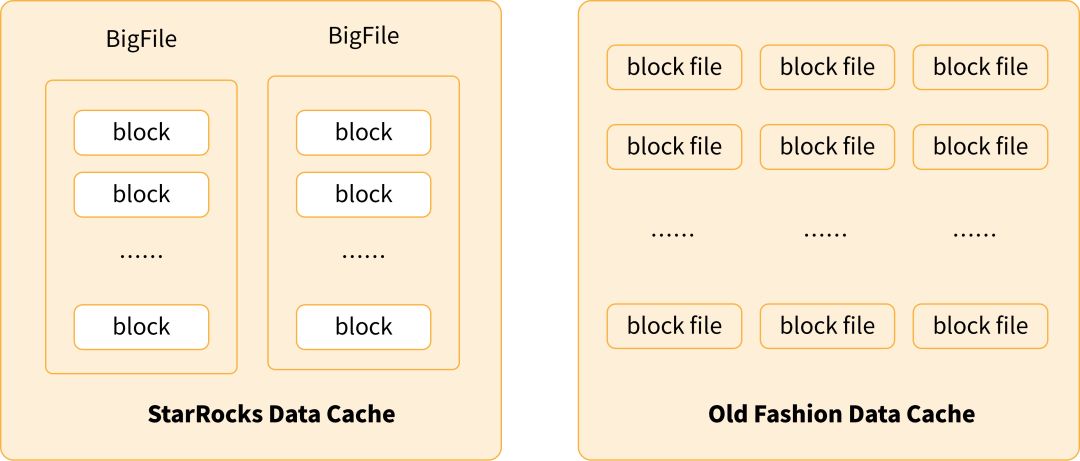
相比于传统简单的单个文件的 Cache,StarRocks 采用了大文件内切 Block 而非小文件的方式,并由 CN 中元数据模块整体管理每个 Block 的元信息。这一结构减少了过多文件的问题,提高了存储磁盘效率,增强了整体性能。
2. 更深入的策略优化
StarRocks 采用内存和磁盘两级缓存策略,根据查询的频度,让更热的数据保留在内存这类更快的存储介质中。在淘汰策略上,采用 SLRU,让频繁查询的热数据更不容易被淘汰,也更不容易被冷查询所影响。同时,StarRocks 能够排除非查询活动,如导入、物化视图刷新、ETL 任务和全表或分区扫描,以最大限度地减少磁盘污染。
3. 更强的自适应能力
StarRocks 可以根据当前磁盘的容量动态的对 Cache 的容量占用进行调整,保证磁盘空间尽可能被使用,同时在磁盘空间占用率较高时为导入、ETL、Spill 等任务让出更多空间,保证磁盘和系统的稳定性
同时,为了保证开箱即用的性能,当缓存的磁盘当前吞吐较低的情况下,StarRocks 会自动放弃读取 Cache 而选择远端,对性能进行改善。除了开源社区版本,镜舟科技也提供了成熟的基于 StarRocks 的企业级解决方案:镜舟湖仓分析引擎。企业级产品在开源项目的基础功能之外,还提供了更完善的:
- 数据安全能力:细粒度访问控制、数据加密、审计日志等
- 运维工具:可视化监控、告警、诊断工具
- 企业级特性:灾备方案、多活部署、资源隔离等
在对稳定性和服务响应要求较高的金融、电信等场景,镜舟科技的企业级产品能提供更安全、易用的数据保障。
五、缓存功能最佳应用案例
案例一:携程的 StarRocks 缓存应用实践
携程运营着一个基于 Hive 的报表平台 Artnova,支撑数据查询与报表查看。面对复杂 SQL、高并发查询等挑战,携程通过利用 StarRocks 的数据缓存功能,将查询性能的提升了 3.36 倍。
特别是通过湖上直接查询和物化视图技术的结合,携程不仅避免了数据搬迁的复杂性和成本,还实现了平均查询性能提升 7 倍以上,部分场景甚至达到几十倍的性能提升。
案例二:唯品会的 StarRocks 架构演进与性能提升唯品会在大数据分析中,经历了从 Presto 到 StarRocks 的架构演进。在面对复杂分析和存储挑战时,通过存算分离和 Data Cache 功能的启用,唯品会不仅提升了查询速度,还大幅降低了存储成本。唯品会从部署了 100 多台物理机的 Presto 集群中选出耗时最长的 500 个查询进行测试,其中约有 210 个查询在 1800 秒后超时(如下图中蓝线所示)
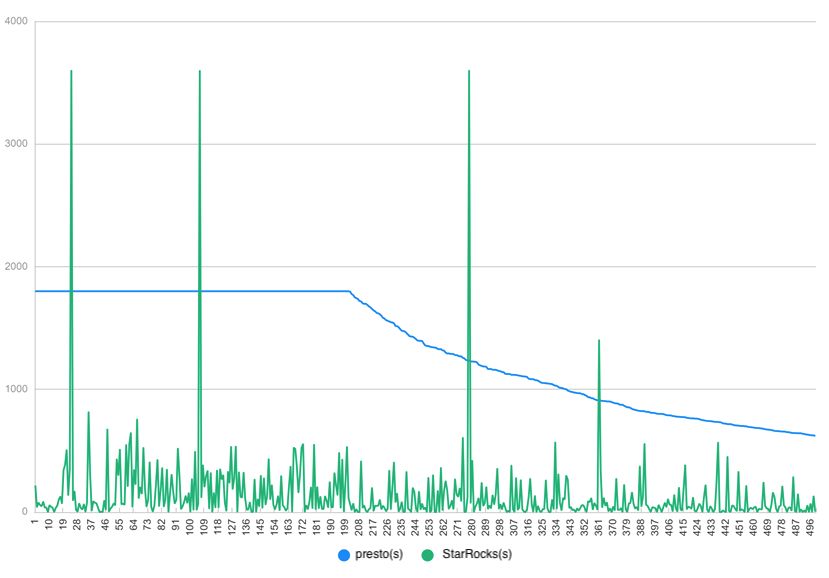
唯品会仅在 19 台 Xeon E5-2683V4 64C 机器的负载上测试了 StarRocks,相比之下,StarRocks 表现出比 Presto 更快的查询性能,同时这也说明了数据本地化对查询速度的提升非常重要。
六、结语
开放湖仓与查询引擎架构有其优势,但通常会面临查询性能的限制。Data Cache 是湖上性能的关键所在,也是在湖上提供仓的性能的重要手段之一。StarRocks 通过深入优化的 Data Cache,在用户无感知的前提下开启 Cache,享受到极快的加速性能。
无论是开源项目 StarRocks 还是镜舟科技的企业级产品,都为企业提供了灵活的选择空间。随着数据规模的增长和业务对安全、易用等要求的提升,企业可以根据实际需求平滑过渡到更适合的解决方案。
原文地址:https://blog.csdn.net/Mirrorship/article/details/144069273
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!