【视频异常检测】Real-Time Anomaly Detection and Localization in Crowded Scenes 论文阅读
文章信息:

发表于:CVPR2015(workshop)
原文链接:https://www.cv-foundation.org/openaccess/content_cvpr_workshops_2015/W04/papers/Sabokrou_Real-Time_Anomaly_Detection_2015_CVPR_paper.pdf
Real-Time Anomaly Detection and Localization in Crowded Scenes 论文阅读
Abstract
在本文中,我们提出了一种用于拥挤场景中实时异常检测和定位的方法。每个视频被定义为一组非重叠的立方体块,并通过两种局部和全局描述符进行描述。这些描述符从不同角度捕捉视频的特征。通过结合简单且具有成本效益的高斯分类器,我们可以区分视频中的正常活动和异常事件。局部和全局特征基于相邻块之间的结构相似性,并通过稀疏自编码器以无监督的方式学习得到。实验结果表明,我们的算法在UCSD ped2和UMN基准测试上与最先进的算法相当,但更加高效。实验验证了我们的系统能够在视频中发生异常时,及时、可靠地检测和定位异常。
1. Introduction

图1. 我们算法的框架(从左到右):输入帧,视频块的两个视角(全局和局部),使用高斯分布建模数据,并做出最终决策。
异常的定义取决于关注的上下文。如果一个视频事件在视频中发生的可能性很低,则该事件被视为异常[6]。在复杂场景中描述不寻常的事件是一项繁琐的任务,通常通过采用高维特征和描述符来解决。开发一个可以通过这些描述符进行训练的可靠模型是非常具有挑战性的,且需要大量的训练样本;同时,它也具有较高的计算复杂度。因此,这可能会面临所谓的“维度灾难”,即随着特征描述符维度的增加,训练模型的预测能力会下降。
在最近的研究中,通常会从训练视频中学习一个或一组参考正常模型,然后在测试阶段应用这些模型来检测异常。此类方法通常将测试视频视为异常,前提是该视频与学习到的模型不相似。为了构建这些参考模型,必须使用一些特定的特征描述符。一般来说,特征通常用于表示 (1) 轨迹或 (2) 时空变化。例如,[8] 和 [19] 关注视频中物体的轨迹,其中每个物体根据其是否遵循学习到的正常轨迹被标记为异常或正常。这些方法无法处理遮挡问题,并且在拥挤场景中计算开销非常大。
为了克服这些缺点,研究人员提出了使用低级特征(如光流或梯度)的方法。他们通过低级特征分布来学习形状和时空关系。举例来说,[13] 使用高斯混合模型来拟合特征,而[1] 则使用指数分布。
在[16]中,利用低级特征对测试数据进行聚类。 在[2, 9, 10, 22]中,正常模式被拟合到马尔可夫随机场,而[14, 18]则应用了潜在狄利克雷分配模型。[11]介绍了一种时空异常联合检测器,作者使用了动态纹理混合(MDT)模型。
在最近的研究中,视频中事件的稀疏表示[6, 7, 12]受到了广泛关注。值得注意的是,[6, 7, 11, 14, 15, 12]中提出的模型在异常检测中取得了良好的性能,但它们通常在异常定位任务中表现不佳。除[12]外,所有这些方法都未针对实时应用进行设计,并且通常在现实世界的异常检测问题中失败。
在本文中,我们提出从两个不同的角度或视角来表示视频,从而得到两个部分独立的特征描述符。然后,我们引入了一种方法,在测试步骤中整合这些视角,以实时地同时执行异常检测和定位。与以往的工作不同,我们提出基于自编码器[17]学习一组代表性特征,而不是使用低级特征。
我们的检测框架以实时方式识别异常。我们的异常检测方法具有较高的真阳性率和较低的假阳性率,使其非常可靠。我们在流行的数据集上评估了我们的异常检测和定位框架,并报告了整个过程的运行时间。与最先进的方法进行比较,结果表明我们的方法在性能和运行时间方面都具有优势。
我们工作的主要贡献如下:
(1) 提出了一种特征学习过程,用于描述视频中的异常定位任务。该方法在训练时较为耗时,但学习到的特征对建模正常块具有很好的区分性。
(2) 引入了一个基于描述符的相似性度量,用于检测时空领域中相邻块的突变。
(3) 从两个不同的角度或视角表示视频块。每个视角都使用局部和全局特征集。在最终决策中,这些视角相互支持。
(4) 用高斯分布建模所有正常块。对于测试视频,使用马氏距离来计算其与正常块的相关性。
(5) 实时性强,我们能够在测试视频或流中异常发生后迅速检测并定位异常。
我们算法的总体框架如图1所示。我们在处理时达到了25帧每秒(fps)的处理能力,在容忍一些误差的情况下,使用一台配备3.5 GHz CPU和8G RAM的PC,并在MATLAB 2012a环境下,最高可达到200 fps。
2. Proposed System

图2. 视频表示:每个视频通过一系列不重叠的立方体块表示,覆盖视频中的整个时空。
Overall Scheme.为了表示每个视频,首先将每个视频转换为多个非重叠的立方体块;该视频表示的示意图如图2所示。一般来说,每个视频都有一个或一组主导事件。因此,正常的块应该与其相邻的块具有相似的关系,并且在视频中出现的可能性较高。因此,这些异常块应满足三个条件:
- 异常块与其相邻块(即由空间变化定义的相邻块)之间的相似性,并不像正常块与其相邻块之间的相似性那样遵循相同的模式。
- 异常块的时序变化最有可能不遵循正常块的时序变化模式。
- 显然,异常块的发生概率低于正常块的发生概率。
可以很容易推断出,以上的条件1和2是局部特征所表征的。因此,它们可以通过局部特征描述符进行编码,而条件3则类似于场景的全局特征。换句话说,条件1和2考虑的是块与其相邻块之间的关系,而条件3描述的是视频中块的整体外观。因此,前两个条件对应于时空变化,而后一个则有所不同。因此,我们通过局部表示来建模条件1和2,通过更全局的表示来建模条件3。另一方面,为了避免所谓的“维度灾难”,我们将这两个方面独立建模。
到目前为止,我们已经定义了两种不同的方式来解决这个问题,从而得出了两个独立的模型。为了做出最终决策,我们将两个模型的决策进行聚合。如果两个模型都判定某个块为异常,则该块被认为是异常的。这种组合方式使得系统在真阳性率和假阳性率方面表现更好,因为这种组合方式保证了只有当两个模型一致认为某个块为异常时,才将其选定为异常。
总之,输入视频从两个不同的角度进行表示。然后,这些表示被拟合到一组高斯分布,并为每个表示计算一个决策边界。最后,根据全局和局部模型的结果,做出关于某个块是否为异常的决策(检测)。定位可以通过视频中哪些块被分类为异常来轻松推断。接下来的章节将介绍这两组特征(全局特征和局部特征)。
Global descriptors.视频全局描述符是一组特征,用于整体描述视频,因此最能描述正常的视频块。在[21]中提出,经典的手工设计低级特征,如HOG和HOF,可能并不适用于所有类型的视频,也不足以具有足够的区分能力。因此,与以往使用低级特征的工作不同,我们采用了一种基于自编码器的无监督特征学习方法。自编码器的结构如图3所示。

图3. 使用自编码器学习全局特征的概述。 左侧:学习特征的步骤使用原始正常块;需要组件(1)、(2)、(3)、(4)和(5);目标是通过调整 W 1 W_1 W1 和 W 2 W_2 W2 使用梯度下降重建输入块。 中间:自编码器结构。 右侧:使用 W 1 W_1 W1 权重表示 y y y 块( y × W 1 y \times W_1 y×W1);仅使用(1)、(2)和(3);这是两个矩阵的乘法,因此非常快速。
自编码器通过建模神经网络,基于梯度下降学习稀疏特征。假设我们有 m 个正常块,尺寸为 (w, h, t),创建一个数据结构 x i ∈ R D x_i \in \mathbb{R}^D xi∈RD,其中 D = w × h × t D = w \times h \times t D=w×h×t(原始数据)。自编码器通过重新构建原始数据,最小化在公式 (1) 中定义的目标:

其中,s 是自编码器隐藏层的节点数, W 1 ∈ R s × D W_1 \in \mathbb{R}^{s \times D} W1∈Rs×D 和 W 2 ∈ R D × s W_2 \in \mathbb{R}^{D \times s} W2∈RD×s 是权重矩阵,分别将输入层的节点映射到隐藏层的节点,以及将隐藏层的节点映射到输出层的节点。 W j i W_{ji} Wji 是第 j 个隐藏层节点与第 i 个输出层节点之间的权重,δ 是 sigmoid 函数。此外, b 1 b_1 b1 和 b 2 b_2 b2 分别是输出层和隐藏层的偏置。 K L ( ρ ∥ ρ j ) KL(\rho \parallel \rho_j) KL(ρ∥ρj)是一个正则化函数,用于强制隐藏层的激活保持稀疏性。KL 基于一个伯努利分布,其参数为 ρ \rho ρ,与激活节点的分布之间的相似性。参数 β \beta β 是惩罚项的权重(在稀疏自编码器的目标函数中)。我们可以通过随机梯度下降法高效地优化上述目标,针对 W 1 W_1 W1 进行更新。
Local descriptors.为了描述每个视频块,我们使用一组局部特征。计算每个块与其邻近块之间的相似性。对于邻近块,我们考虑九个空间邻近块和一个时间邻近块(即在时间上紧接着感兴趣块之前的那个块),这样每个块有10个邻近块。对于时间邻近块,我们只考虑感兴趣块之前的那个块(而不是下一个块),因为我们旨在尽可能早地检测到异常,甚至是在下一个视频帧(以及随后的块)到达之前。我们使用SSIM(结构相似性指数)来计算两个块之间的相似性,SSIM是一个广泛使用的图像质量评估工具[4]。此外,作为第二种局部描述符,我们计算每个单帧与其后续帧在感兴趣块中的SSIM值。图4展示了我们通过时空邻近块进行局部特征评估的过程。局部描述符将是这些SSIM值的组合,即 [ d 0 ⋅ ⋅ ⋅ d 9 , D 0 ⋅ ⋅ ⋅ D t − 1 ] [d_0 · · · d_9, D_0 · · · D_{t−1}] [d0⋅⋅⋅d9,D0⋅⋅⋅Dt−1]。
***
图4. 我们的局部描述符示意图:每个感兴趣块与其邻近块的相似性(上图),每个感兴趣块的时间内相似性(下图)
Anomaly Classifier.
为了建模每个视频块中的正常活动,我们引入了两个高斯分类器 C1 和 C2。对于分类 x ′ x' x′块,如前所述,我们使用两个部分独立的特征集(全局特征和局部特征),并计算马哈拉诺比斯距离 f ( y ) f(y) f(y)。如果 f ( y ) f(y) f(y) 大于阈值,则该块被视为异常块,其中 y 在全局分类器中等于 W 1 × x ′ W_1 \times x' W1×x′,而在局部分类器中则为 [ d 0 ⋅ ⋅ ⋅ d 9 , D 0 ⋅ ⋅ ⋅ D 3 ] [d_0 · · · d_9, D_0 · · · D_3] [d0⋅⋅⋅d9,D0⋅⋅⋅D3]。为了避免数值不稳定性,我们避免了密度估计。因此,C1 和 C2 分类器定义如下:


其中, μ \mu μ 和 Σ \Sigma Σ 分别是均值和协方差矩阵。选择一个“合适”的阈值对性能非常重要;它可以基于训练块来选择。如前所述,如果 C1 和 C2 分类器都将某个块标记为异常,则该块被视为异常;如果其中一个或两个分类器都认为该块是正常的,我们的算法将其分类为正常块。以下方程中展示了这些标准的总结,即 F 函数:

Anomaly detection using feature learning.
我们从原始训练数据中学习特征,并按照前一节中规定的方法对视频块进行分类。但基于 [3] 中的观点,使用小块和大块通常会导致假阳性率增加和真阳性率下降。当块变得更大时,自编码器的输入维度增加,因此需要学习的网络权重数量也会增加。
在训练样本有限的情况下,从大块(例如 40×40×5)中学习特征是不可行的。为了克服这些挑战,我们从小块(10×10×5)中学习特征。为了使用这些特征创建一个模型,在测试阶段,我们考虑大块(40×40×5)。由于学习到的分类器是针对 10×10×5 块表示的,我们在 40×40×5 块中卷积已学习的特征(W1),不进行重叠,并对从 40×40×5 块中提取的 16 个特征向量进行池化。因此,我们使用均值池化来实现 40×40×10 块的表示,并使用基于 10×10×5 块的已学习分类器进行检测。该过程如图5所示。

图5. 使用特征学习进行大块异常检测。 (A) 输入视频。 (B) 选定的测试块(例如,40×40×5)被划分为 16 个小块。 (C ) W 1 × W_1 \times W1× 小块。 (D) 对所有特征向量(16 个向量)进行池化。 (E) 计算每个特征的均值并创建一个特征向量。 (F) 使用基于 10×10×5 块的已学习分类器进行分类。
3. Experimental results and comparisons
我们将算法与最先进的方法在Ped2、UCSD1和UMN2基准上进行了比较。实验证明,我们的方法适用于监控系统。
Experimental settings.特征学习是在 10×10×5 的小块上进行的。异常检测的训练和测试阶段分别使用了 10×10×5 和 40×40×5 的块大小。在异常检测中,使用的是 40×40×5 的块大小。特征学习通过自编码器完成,稀疏度设置为 0.05。每个 10×10×5 的块由一个 1000 维的特征向量表示。在特征学习之前,进行了归一化处理,将均值和方差分别设置为 0 和 1。
UCSD datasets.该数据集包括两个子集,ped1 和 ped2,分别来自两个不同的户外场景。两者都是以静态摄像头在 10 帧每秒的速度下录制的,分辨率分别为 158×234 和 240×360。场景中主要的移动物体是行人。因此,任何物体(例如汽车、滑板车、轮椅或自行车)都被认为是异常物体。我们在 ped2 子集上评估我们的算法。该子集包含 12 个视频样本,每个样本被划分为训练帧和测试帧。为了评估定位效果,我们利用所有测试帧的真实标注。我们将我们的结果与现有的先进方法进行比较,使用接收操作曲线(ROC)和等错误率(EER)分析,类似于 [13]。我们使用两个评估指标,一个是帧级别的,另一个是像素级别的。此外,我们还定义了一种新的度量方法,用于评估异常定位的准确性,称为双像素级别。以下是这些指标的定义:
Frame level measure:如果一个像素检测到异常,则认为该帧是异常的。
Pixel level measure:如果算法检测到的像素覆盖了至少 40% 的异常地面真实像素,那么该帧就被认为是异常的。
假设算法检测到某个区域为异常,并且这些区域中的一个与异常的地面真实数据有重叠;在前两种度量中不会考虑这些假阳性区域。这样的区域被称为“幸运猜测”。为了考虑“幸运猜测”区域,我们引入了双像素级别度量。该度量对“幸运猜测”区域较为敏感。
双像素级别度量:在该度量中,如果一个帧满足以下两个条件,则被视为异常帧:(1) 它满足像素级别的异常条件;(2) 至少有 β 百分比(例如,10%)的被检测为异常的像素被异常地面真实数据覆盖。如果除了异常区域之外,其他无关区域也被视为异常,则该度量不会将该帧标记为正样本。图6展示了不同异常检测度量的示例。

图6. 异常评估度量。蓝色和红色矩形分别表示算法输出和异常真实标签。(a)帧级评估。(b)像素级评估:40%的红色(真实标签)被蓝色(检测到的区域)覆盖。(c)双像素级评估:评估40%的红色被蓝色覆盖,但至少 β% 的蓝色没有被红色覆盖。(d)双像素级评估。
Performance Evaluations.图7展示了与其他方法的定性比较。该图表明,在与所有竞争算法的比较中,我们的算法表现最佳。关于运行时间的比较,请参见表1。



在图8(左)中,我们的方法在 ped2 数据集上与其他方法的帧级 ROC 进行了比较。结果显示,我们的方法与其他方法相当。在这个度量上,表2 显示了不同方法的帧级 EER。这确认了我们的方法在与其他方法的比较中表现良好。除了 Li 等人([11] 中报告的方法,我们低了 0.5%)的方法外,我们超越了所有其他方法。
UMN dataset.UMN 数据集包含三个不同的场景。在每个场景中,一群人正在一个区域内行走,突然间所有人都跑开(逃离);这种逃离行为被视为异常。图10展示了该数据集中的正常帧和异常帧的示例。

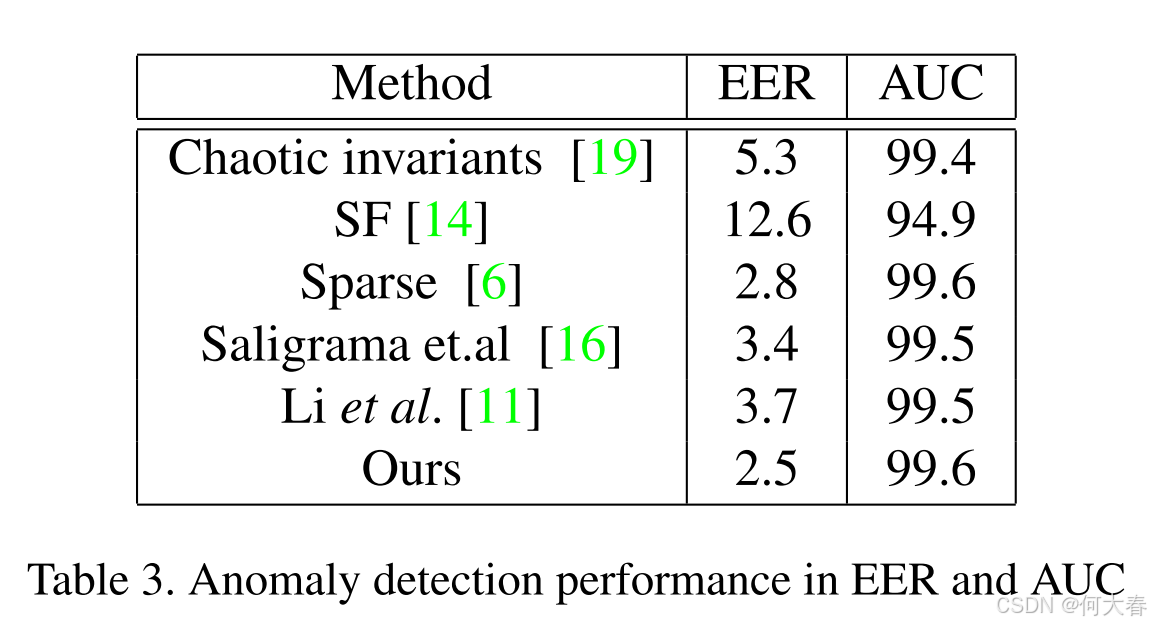
该数据集存在一些限制。数据集中只有三个异常场景,并且正常帧和异常帧之间的时空变化非常大。该数据集没有像素级的真实标签。基于这些限制,为了评估我们的方法,我们使用了帧级的 EER 和 AUC 指标。EER 和 AUC 的结果见表3。由于该数据集相对简单,且异常定位不太重要,因此仅使用了全局检测器。之前的方法在该数据集上表现得相当不错。我们方法的 AUC 与其他最好的结果相当,而 EER 比之前最好的方法好(提高了 0.3%)。
4. Conclusions
我们提出了一种异常检测和定位方法。在我们的方法中,我们提议使用全局和局部描述符来表示视频。基于这两种表示形式,我们提出了两种分类器。通过对这两个分类器输出的融合策略,我们实现了准确可靠的异常检测和定位。然而,单独使用这两个分类器中的任何一个,都能很好地进行异常检测。尤其是在UMN数据集上,全局描述符实现了最先进的结果。我们还为可疑区域引入了一种新的区域级异常检测指标。此外,我们的方法在UCSD数据集上的表现优于近期的方法。值得注意的是,我们在运行时间上比所有竞争方法都要快,取得了这些良好的结果。我们的方法具有低计算复杂度,可以实时运行。这使得它在实时监控应用中非常有用,在这些应用中,我们处理的是视频的实时流。
原文地址:https://blog.csdn.net/weixin_44609958/article/details/144425173
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!