Linux 基础环境的开发工具以及使用(下)

1. make / Makefile 自动化构建的工具
1)引入
在我们进行一些大型的工程的时候,代码量是极其大,当我们代码在进行一系列的编译的时候,难免会出现一些错误,当我们对错误进行一系列的更改之后,难道我们需要再重新敲刚刚一系列的相关指令吗?? 假设我们有上百个源代码,每一个都需要重新敲入相关的指令吗?? 这难免比较耗时。那有没有一些工具,可以进行对文件的相关编译原则,我们只需要输入指定的简短的指令,来完成对上百个源代码的编译。
make/Makefile 就是一个解决上述问题的自动化工具。
make:是一条指令。
Makefile: 是一个包含一系列编译原则的文件。通过调用make 指令来完成指定文件的编译。他用
于告诉 make 程序如何编译和链接一个程序。它包含了目标(target)、依赖关系
(dependencies)、命令(commands)等内容,使得我们可以通过简单的命令来构建和管理复杂
的软件项目。
2)使用
I)首先创建一个 makefile / Makefile 文件
touch makefile/MakefileII) Makefile 里面的内容:存放依赖的 关系以及依赖方法
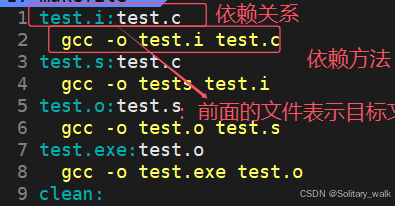
对指定文件进行预编译,编译,汇编,链接对应的指令 ,这里不再一一赘述,可见上篇博客文件编译对应的指定指令
III)在命令提示符里面直接使用meke 指令,就可以自动化完成指定文件的 编译。

注意:make 指令会自动推导对应的依赖关系,他的推导过程是一种栈式推导的;
一旦生成对应的第一个目标文件,此时就会停下来,其他 的对应目标文件不会生成,在默认的情
况下。也可以使用 make + 指定的目标文件
3)相关问题
I) 为什么多次进行 make 的时候,显示以下的提示信息:该目标文件已经是最新的
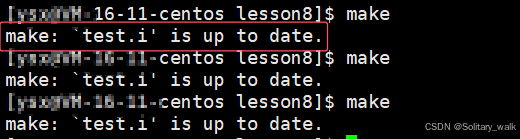
分析:其实每次在进行 make 指令进行编译的时候,通过对比目标文件与源文件之间的“新旧” 时间,来决定是否再次执行make 指令。
II) 为什么会这样进行执行???

为了提高编译的效率。
一般情况下:首次进行编译的时候,目标文件是新于 源文件的,因为先有源文件,才有了对应的
目标文件(注意:这里的目标文件不仅仅指的是,汇编生成的目标文件,也可能是可执行文件或者
是预编译,编译生成对应的目标文件)。
当我们没有对源文件进行相应的修改,此时源文件是老于 目标文件的,假设当前make 指令会再
次生效,当源文件的体积很大时候,在进行编译的时候,会消耗大量的时间,所以为了提高编译
的效率,当源文件老于 目标文件的时候,不会再次执行make 指令。
本质:看源文件的内容是否发生变化,来决定是否再次进行make 指令的执行
4)对上面 的问题进行验证
编译器是如何知道当前的源文件的时间是 老于,还是新于 目标文件的呢???
首先需要知道几个时间:
access:记录对文件访问的时间
modify: 记录对文件内容的修改时间
change:记录对文件的属性修改时间
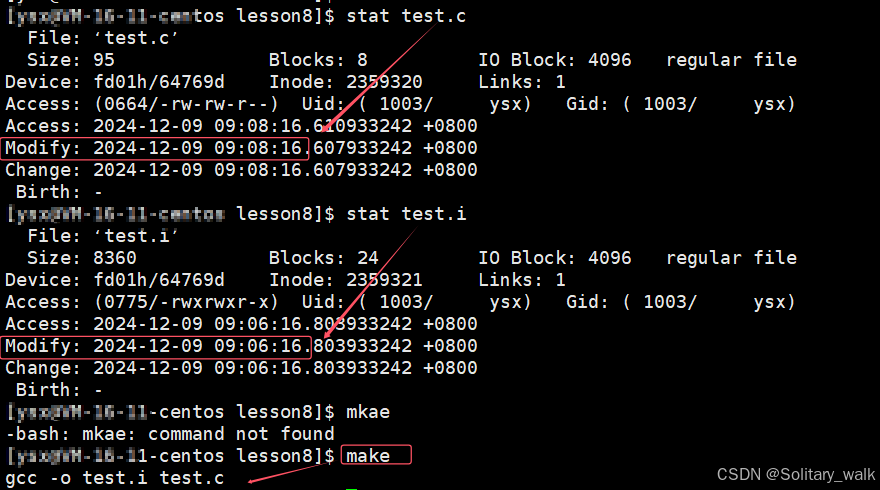
I) 查看一个文件的访问,修改,时间:stat
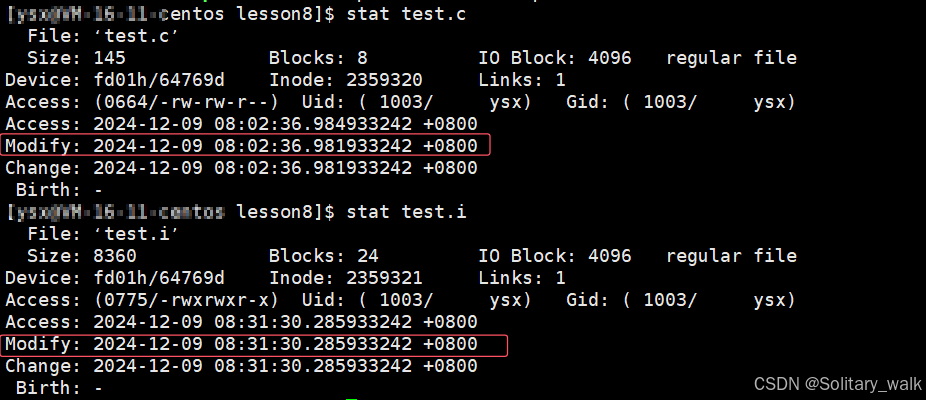
此时目标文件是新于 源文件的,所以当我们再次执行 make 的时候初出现以下的现象:
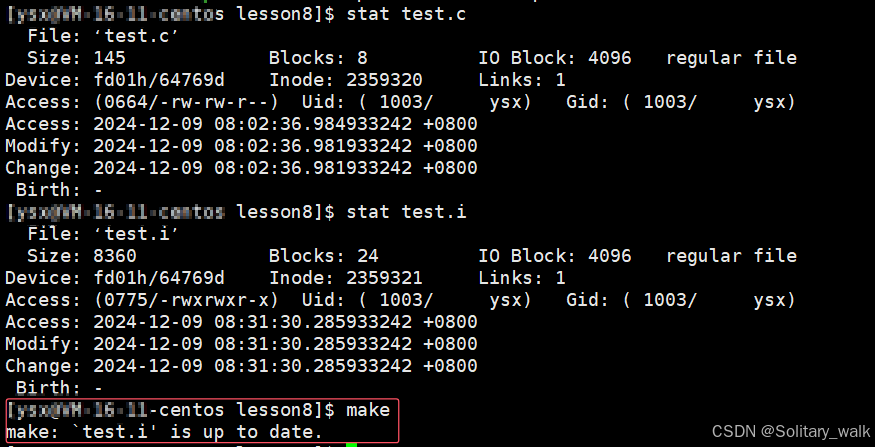
当我们对源文件进行修改的时候(对文件的内容或者是文件的属性进行修改),所见现象如下:
5)伪目标: .PHONY 的使用
当我们想 每次使用 make 的时候,都强制执行文件的编译,此时可以使用伪目标 .PHONY
对要生成的目标文件进行 .PHONY 伪目标的修饰
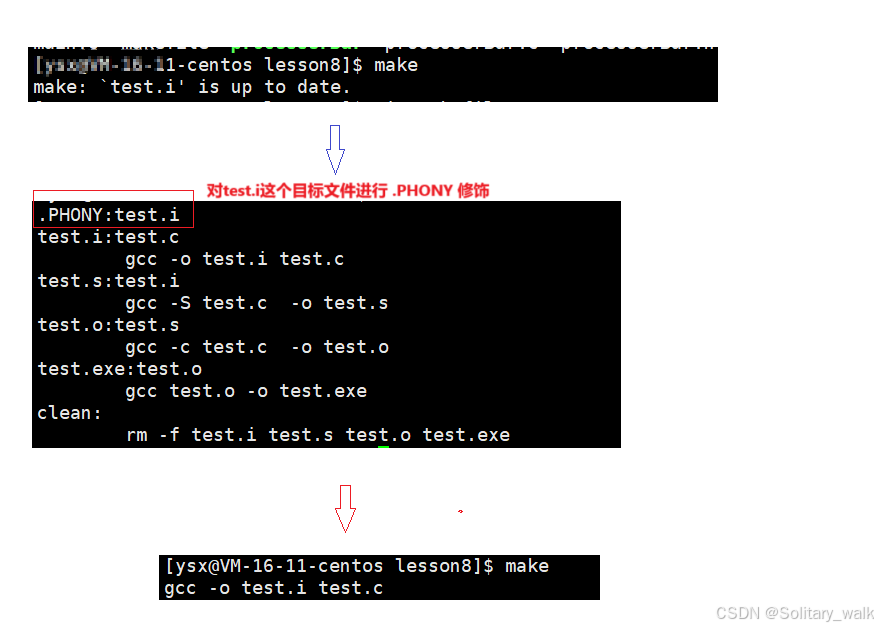
但是一般不建议这样写,因为对于目标文件要是每次 make 的时候,都进行编译,这样不仅仅会消耗时间还极其销毁内存。但是对于文件的清理,可以使用 伪目标进行修饰。
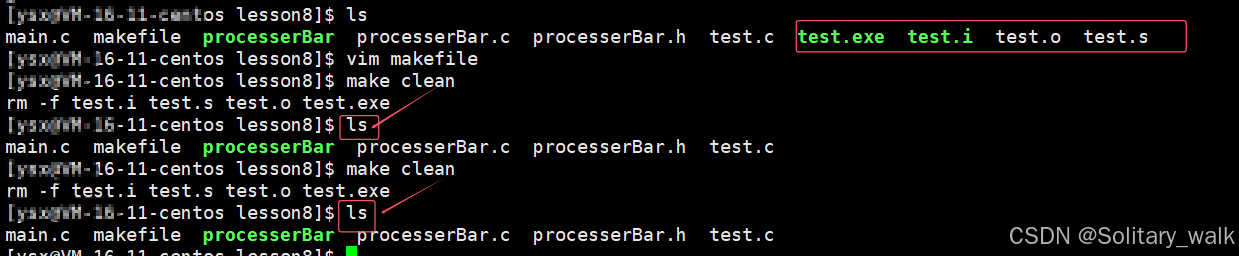
2) make clean :文件清理
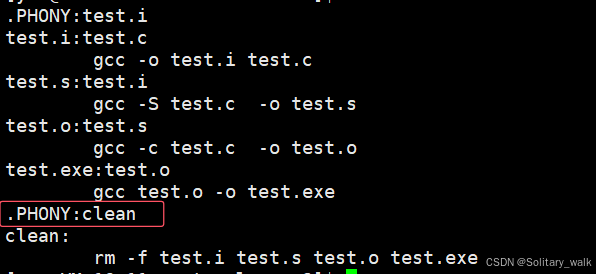
使用:直接在命令提示符使用 make clean
2. git
1)git 是什么
Git是一款免费、开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目。
使用git 也可以进行团队合作。
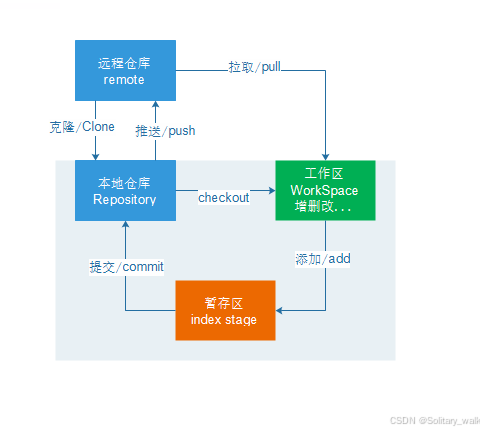
git 的工作流程:
从远程仓库中克隆 Git 资源作为本地仓库;
从本地仓库中checkout代码然后进行代码修改;
在提交本地仓库前先将代码提交到暂存区;
提交修改,提交到本地仓库;本地仓库中保存修改的各个历史版本;
在需要和团队成员共享代码时,可以将修改代码push到远程仓库。
2)git 的使用
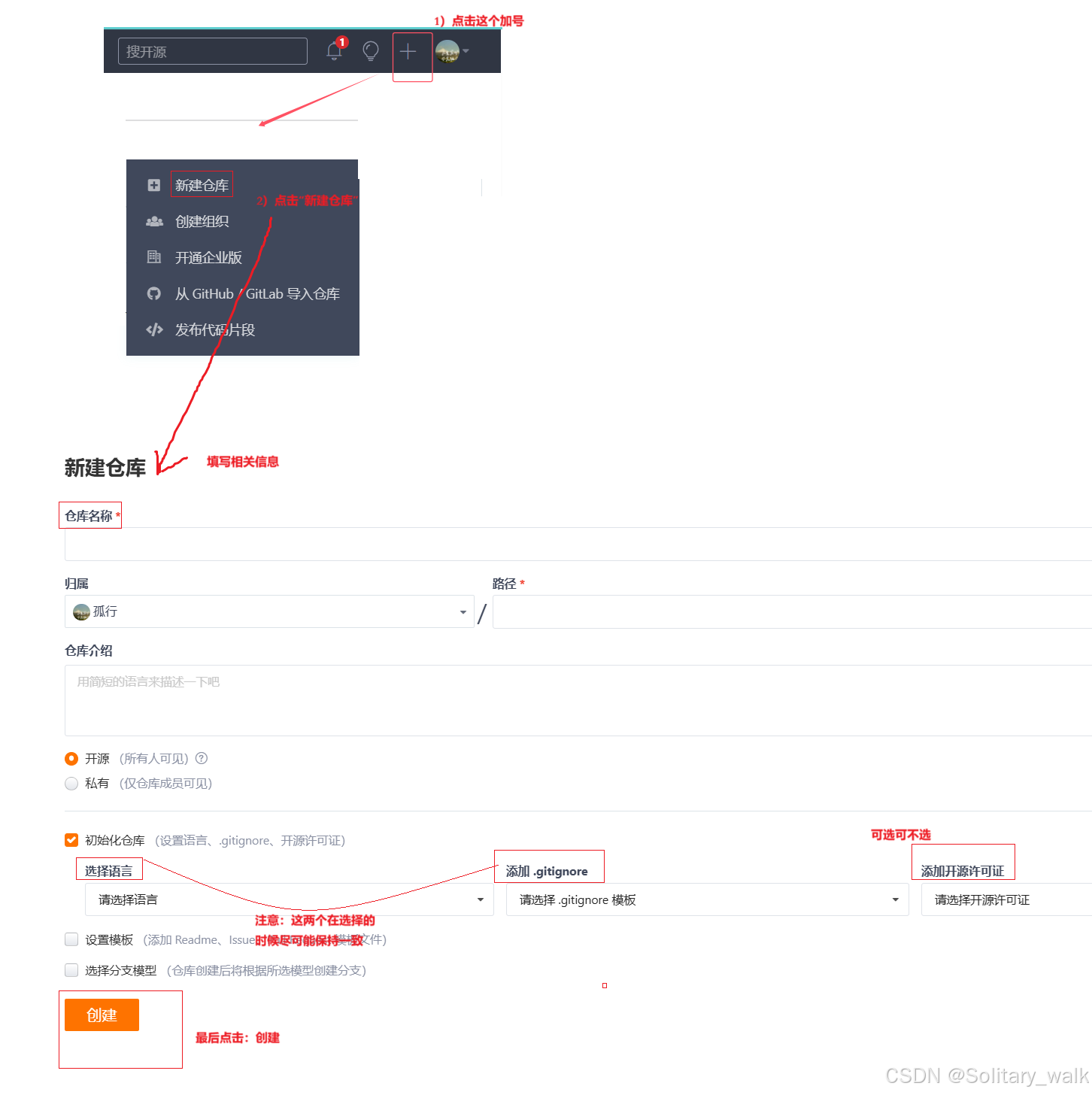
I) 首先我们需要先创建一个远程仓库,具体实现细节见下:
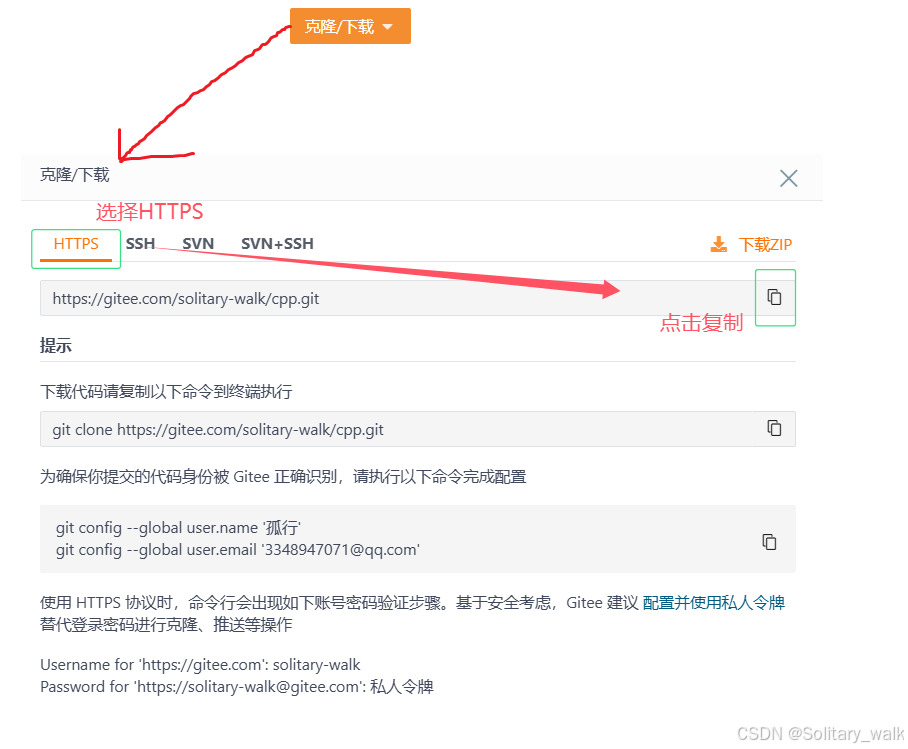
II) 把远程仓库拉取下来:先复制远程仓库的地址,具体实现细节见下
III)在命令行提示里面输入一下指令:
![]()
IIII) git 三板斧
git add + 指定的文件
git commit -m "关键 的文字说明"
git push :注意在这一步,会进行身份验证,输入git 的账号以及对应的密码即可

以上只是对git 的简单介绍,感兴趣的铁汁们,可以自行资料的搜集
3 . gdb 调试器的使用
1)引入
众所周知,Linux 是一个非图形化界面的操作系统(也支持图形化界面),在上面可以使用命令行的方式进行文件的创建,代码的编写,软件的下载…… 但是当我们的代码在进行运行的时候难免会遇到一些Bug ,此时又是如何调试的???
我们知道对于VS 下,进行代码的调试,有相关的按键支持,对于Linux 系统上,也是可以的,只不过这里是命令行的方式。
首先我们需要先下载 gdb 这个调试器。
sudo yum install -y gdbgdb 是一个开发环境必不可少的调试工具。
2) Debug 和 Release 版本区别
当我们使用VS 进行代码运行的时候,多数是在 Debug 版本下进行的,方面我们进行相关的调试
简言之:Debug 版本,进行程序的调试。
对于测试人员:当我们把写好的项目进行终版的提交,他们会在 Release 版本下进行,主要
是发下各种问题,此时代码里面是不包调试信息的,也就是用户最终拿到的版本
3)Linux 下的gdb 相关的指令
I) 准备工作 :编一个测试代码
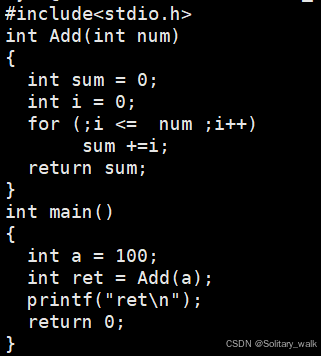
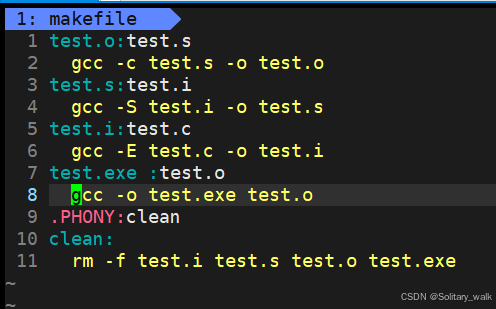
makefile 文件的内容:
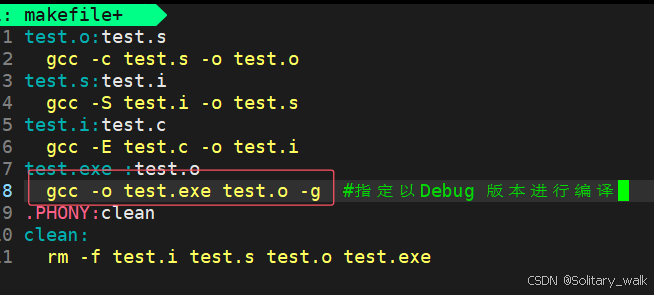
gcc 默认进行文件编译采用的是版本是Debug ,当我们指定进行Debug 版本进行相关信息的调试 的
时候对应 的指令:对可执行程序进行编译的 时候,添加 -g :进行debug 版本编译
2)对指定程序进行调试 gdb + 可执行程序(注意这里 必须是可执行程序的文件)
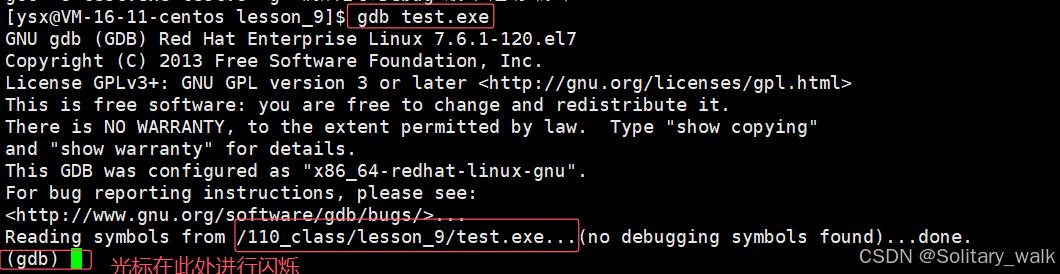
如何判断当前的可执行程序到底是Debug 版本下生成的还是 Release 版本生成的???

通过比较对应生成文件的大小:因为Debug 版本生成的文件,对应体积较大,因为需要包含一些
对应 的调试信息。
注意:gcc/g++ 编译生成对应的文件默认是以 release 版本发布的;想对知道程序进行调试 的时
候,必须借助 Debug 版本生成的程序:在编译的时候指定 -g
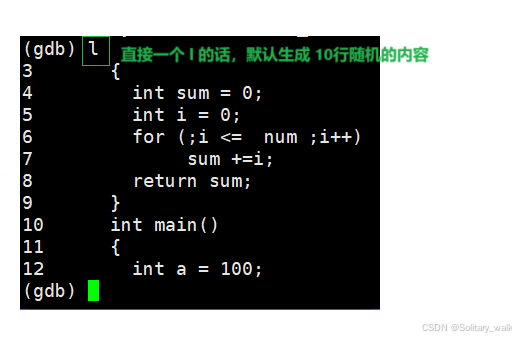
当我们进入gdb 模式下,我们是无法知道当前代码的内容,此时可以借助 l 指令进行相关内容查找
l + n :查看当前代码指定的多少行,一般方便我们进行相关断点设置
l 0 和 l 1 打印出来的内容是一样的

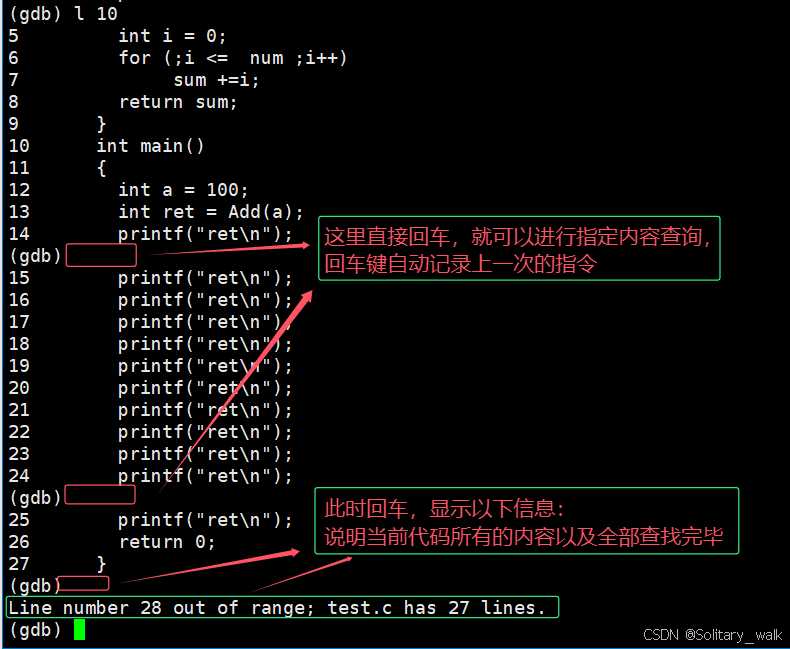
当我们有了相关的内容,接下来就是如何进行打断点
b +指定的行号(源代码对应的某一行)

有了断点的设置,接下来就是如何查看已经打的断点???
info b
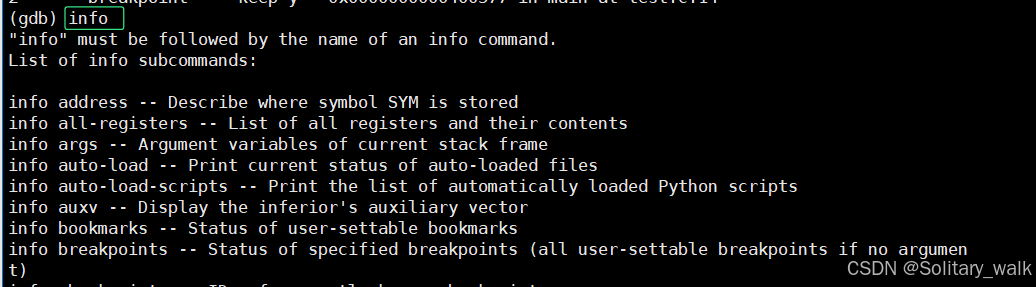
直接输入 info 的时候,默认是把所有的调试信息打印出来,如今我们只需要知道当前的 断点信息直接 info b
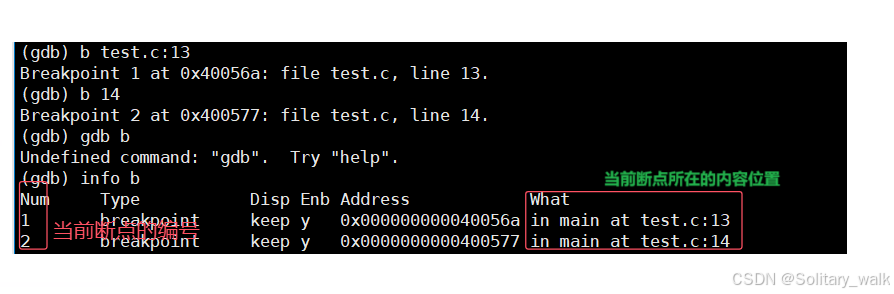
断点的删除:
d + 要删除断点对应的编号 对指定端点的删除
d breakpoints :删除所有 的断点

假设当前需要删除代码第7行对应的断点,此时就需要找到当前断点对应的编号: 3

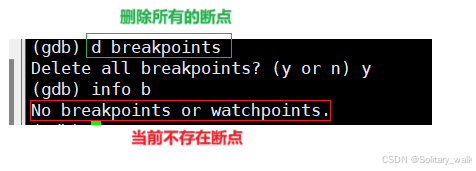
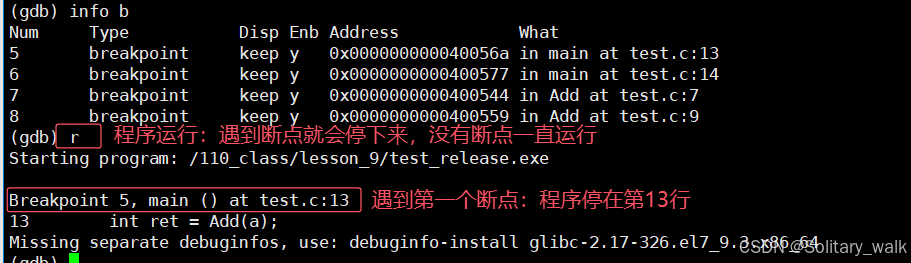
程序的运行与调试:
r :遇到断点会停下来,相当于VS下的 F5
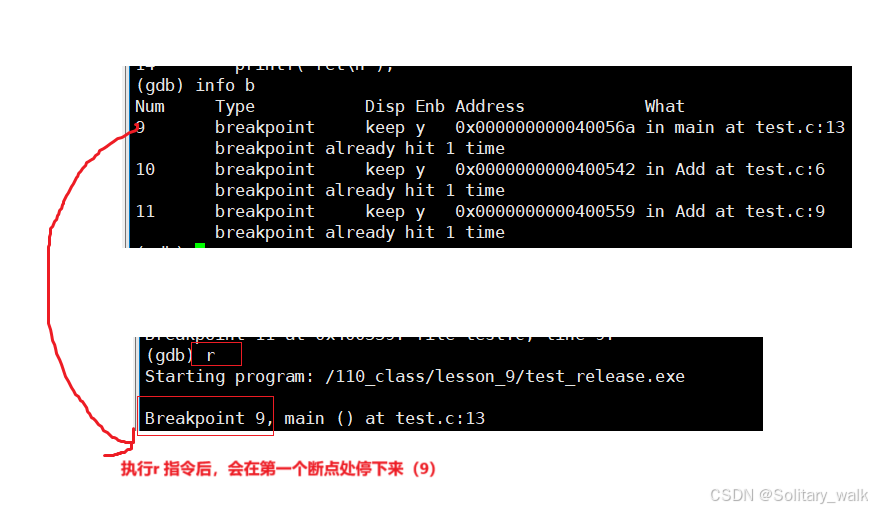
逐过程 和逐语句的调试:
n :逐过程的调试,一般用于对函数的调试,相当于VS 下的 F10
s: 逐语句的调试,一个语句一个语句的调试,相当于VS 下的F11
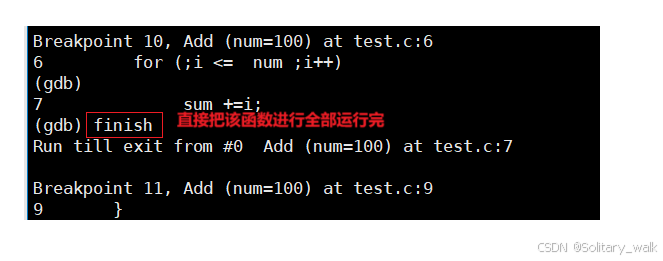
当我们进入函数内部,发现这个执行的过程比较长,并且也不是出发报错的位置,想直接把
该函数运行完,返回调用该函数的位置:直接使用 finish 指令即可
对变量的打印和追踪:
p + 变量名 : 显示变量的值
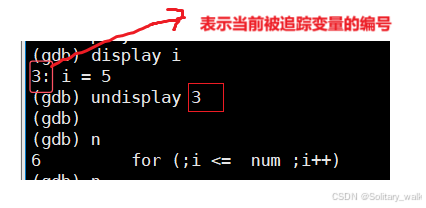
display + 变量名 : 每次运行完,都会打印一个当前变量对应的数值
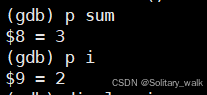
对一个循环很长的代码块,此时一个一个指令的显示比较麻烦,可以使用diaplsy 进行追踪,此时
每执行一次循环,会自动打印变量的数值:

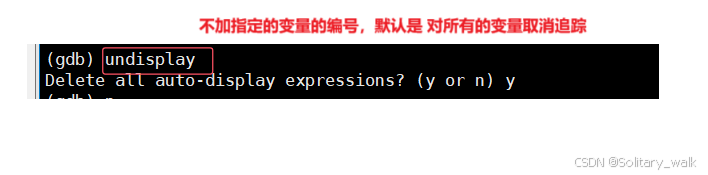
当不需要对某个变量进行实时的跟踪的时候,使用undislay 进行设置。

以上是关于Linux 相关工具使用的简单介绍,后期会不定期的进行内容法更新~~~

原文地址:https://blog.csdn.net/X_do_myself/article/details/144214298
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!