【机器学习】机器学习的基本分类-监督学习-岭回归(Ridge Regression)
岭回归是一种针对多重共线性问题的回归方法,通过对线性回归模型引入 正则化项,限制模型系数的大小,从而提高模型的泛化能力。
1. 背景问题
在普通最小二乘(OLS)回归中,损失函数是最小化残差平方和:
其中,预测值 。
多重共线性
- 如果特征之间存在强烈的相关性(即多重共线性),会导致普通线性回归的解不稳定:
- 矩阵
的条件数很大或接近奇异。
- 回归系数 β 对训练数据的噪声极为敏感,导致模型泛化能力差。
- 矩阵
2. 岭回归的改进
引入 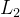 正则化
正则化
岭回归在 OLS 损失函数中添加了一个惩罚项,限制回归系数的平方和:
是正则化强度的超参数,控制惩罚的大小:
- 当
,等同于普通最小二乘回归。
- 当
,所有回归系数趋近于 0。
- 当
优化目标
最小化目标函数:
其中:
是残差平方和。
是
3. 岭回归的解
岭回归的闭式解为:
是一个正定矩阵,确保了逆矩阵的存在,即使
是单位矩阵。
相比于 OLS 解 ,岭回归通过
对
加入平滑,提高了数值稳定性。
4. 优缺点
优点
- 解决多重共线性:通过正则化减少模型对特征噪声的敏感性。
- 稳定性:模型更加稳定,预测结果更鲁棒。
- 控制过拟合:引入正则化,有效降低复杂模型的过拟合风险。
缺点
- 特征选择能力弱:岭回归不会将特征系数缩减为 0,因此不适合用于特征筛选(相比于 Lasso 回归)。
- 对 λ 的依赖:正则化参数需要通过交叉验证调优。
5. 实现代码
以下是 Python 中使用 scikit-learn 的实现示例:
from sklearn.linear_model import Ridge
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_regression
from sklearn.metrics import mean_squared_error
# 生成数据
X, y = make_regression(n_samples=100, n_features=5, noise=10, random_state=42)
# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建岭回归模型
ridge = Ridge(alpha=1.0) # alpha 即正则化参数 λ
ridge.fit(X_train, y_train)
# 预测
y_pred = ridge.predict(X_test)
# 评价
print("MSE:", mean_squared_error(y_test, y_pred))
print("回归系数:", ridge.coef_)
输出结果
MSE: 121.64571508040383
回归系数: [60.80641691 96.97650095 59.85083263 54.82588222 35.69887237]6. 岭回归的应用场景
- 金融领域:解决变量间高度相关的问题,如资产定价模型。
- 基因数据分析:处理特征数量远大于样本数量的高维数据。
- 时间序列预测:对相关变量的噪声进行平滑处理。
7. 岭回归与其他方法的比较
| 方法 | 正则化类型 | 优点 | 缺点 |
|---|---|---|---|
| 普通回归 | 无 | 简单直观、无偏估计 | 对多重共线性敏感 |
| 岭回归 | 稳定性高,解决共线性问题 | 无法特征选择 | |
| Lasso | 可稀疏化系数(特征选择) | 存在一定的偏差 | |
| ElasticNet | 综合岭回归和 Lasso 的优点 | 需要调节两个正则化参数 |
8. 超参数调优
正则化参数 λ(在 scikit-learn 中为 alpha)是岭回归中的核心超参数,常用的调优方法是交叉验证:
from sklearn.linear_model import RidgeCV
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_regression
# 生成数据
X, y = make_regression(n_samples=100, n_features=5, noise=10, random_state=42)
# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 设置不同的 λ 值
alphas = [0.1, 1.0, 10.0, 100.0]
# 交叉验证选择最佳 λ
ridge_cv = RidgeCV(alphas=alphas, cv=5) # 5 折交叉验证
ridge_cv.fit(X_train, y_train)
# 最佳正则化参数
print("最佳 λ:", ridge_cv.alpha_)
输出结果
最佳 λ: 0.1岭回归通过引入 正则化,有效解决了多重共线性和过拟合问题,适合在高维和相关性强的数据集中使用。
原文地址:https://blog.csdn.net/IT_ORACLE/article/details/144257644
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!