Stable Diffusion 3.5 能力挽狂澜吗?
前几天 Stability AI 发布了 Stable Diffusion 3.5,相比之前的 SD3 发布,这次 Stable Diffusion 3.5 学乖了很多,对社区友好了很多:研究或非商业用途、以及年总收入不足100万美元的组织或个人的商业用途都可以免费使用。这个效果还是很明显的,huggingface 上很快出现了很多基于 SD3.5 的衍生模型。
Stable Diffusion 3.5 大模型是一款多模态扩散变换器(MMDiT)文本到图像模型,其特点是在图像质量、排版、复杂提示理解和资源效率方面具有改进的性能。
目前还是 ComfyUI 对 SD3.5 的支持更好,Stable Diffusion WebUI 还不支持3.5,SD WebUI 的衍生版本 SD WebUI Forge 好像已经支持 SD3.5,不过我还没有测试。最近一年 AUTOMATIC1111慢了很多,SD WebUI的社区有点沉寂了,不知道敏神的 stable-diffusion-webui-forge 能否接过WebUI的衣钵,让这个工具再次活跃起来。
下面我们就来详细了解下这个模型。
效果
废话不多说,先看看效果。

模型
基础模型
这次 Stability AI 一连发布了三个大模型SD 3.5 Large、SD 3.5 Large Turbo 和 SD 3.5 Medium 。
1、SD 3.5 Large
完整模型需要20个采样步骤。每张图片处理时间为20秒。
仓库地址:https://huggingface.co/stabilityai/stable-diffusion-3.5-large
2、SD 3.5 Large Turbo
这是SD 3.5 Large的蒸馏版,模型生成图片只需要4个采样步骤。每张图片处理时间为10秒。
仓库地址:https://huggingface.co/stabilityai/stable-diffusion-3.5-large-turbo
3、SD 3.5 Medium
这是 SD 3.5 Large 的一个较小的检查点,使用的是MMDiT的一个改进模型,在变换器的前13层引入自注意力模块,增强多分辨率生成和整体图像的一致性。SD 3.5 Medium也内置了文本编码器/CLIP。
仓库地址:https://huggingface.co/Comfy-Org/stable-diffusion-3.5-fp8
模型下载后通常的存放路径是:ComfyUI > models > checkpoints,就是基础模型的路径,具体的路径可能和你的设置有关。
如果你访问 huggingface 不方便,也可以使用我整了的模型集合,下载方式见文末。
文本编码器模型
SD 3.5 支持多个文本编码器,这和SD3、Flux等使用文本编码器的方式差不多。
-
clip_l.safetensors
-
clip_g.safetensors
-
t5xxl_fp16.safetensors 或者使用更小尺寸的 t5xxl_fp8_e4m3fn.safetensors 代替
仓库地址:
https://huggingface.co/stabilityai/stable-diffusion-3.5-large/tree/main/text_encoders
如果你访问 huggingface 不方便,也可以使用我整了的模型集合,下载方式见文末。
显存需求
最少也要12G显存,多多益善,24G最佳,当然32G更好。
本地没有合适显卡的同学,可以试试我制作的ComfyUI云镜像,内置大量工作流,开局就送体验金,可以免费用几个小时:https://www.haoee.com/applicationMarket/applicationDetails?appId=27&IC=XLZLpI7Q
图片尺寸
标准的图片分辨率是 1024×1024。就像 SDXL 和 Flux,你也可以使用其它比例的尺寸,只要大概在1M像素就可以。推荐图片尺寸:
-
1:1 – 1024 x 1024
-
5:4 – 1152 x 896
-
3:2 – 1216 x 832
-
16:9 – 1344 x 768
使用SD3.5
升级到最新版本(至少要10月26日的版本)。
下边是一个最基础的SD3.5的工作流,包括:SD3.5基础模型、CLIP模型、提示词、Latent潜空间、采样器等。
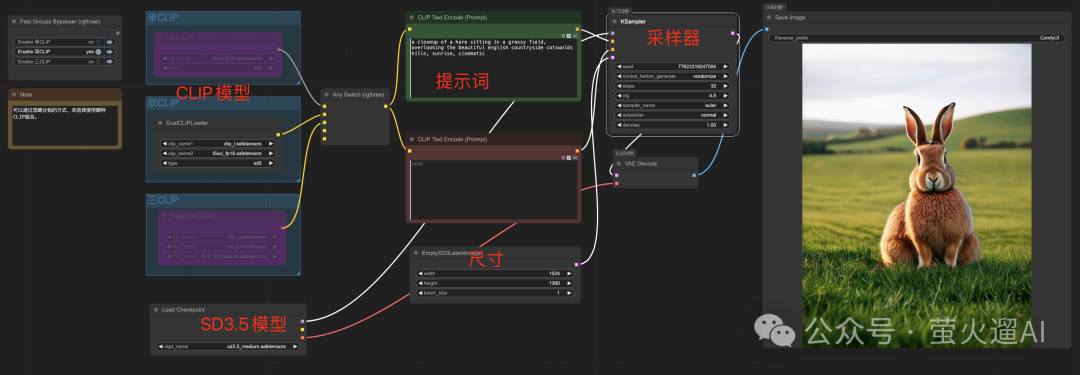
如果你选择的是SD3.5官方发布的原版Large或者Medium模型,CLIP模型需要单独加载。
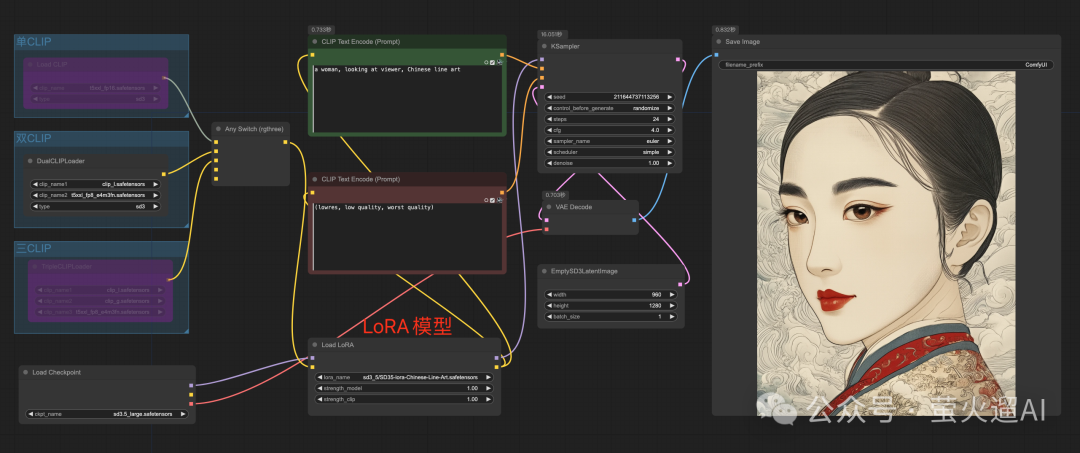
使用LoRA模型也很简单,串联一个LoRA模型就可以了。
与前几代模型的对比
这里做个简单的对比。

基础模型依次是:SDXL Base 1.0 -> SD3 Medium -> SD 3.5 Large
提示词:masterpiece, best quality, 1girl, long hair, brown hair, looking at viewer, smiling, blue and white clothes, upper body, flower garden, photorealistic,
从上图可以看出,SDXL的塑料感比较强,SD3有些用力过度,SD3.5的真实感更强。从这个简单的对比上看SD3.5确实在进步。
与Flux.1模型的对比
大家先自己对比下看看,左侧是Flux.1生成的,右侧是SD3.5生成的。
提示词1:
Black and white photo, a 1930s celebrity, a sensuous young woman, looking at the viewer, a little smile, close up to the face, perfect lighting, dark background

提示词2:
Vibrant Colorful Realistic analog photo, very detailed, hyper detailed, photorealistic, hyperdetailed, uhd, 4k, the focus of the image is on the witch, extreme closeup Face Portrait, extreme face closeup, head focus, Realistic analog photo, awesome, high Quality, photorealistic, atmospheric lighting, volumetric lighting, cinematic, Epic Film Quality, dense Sand storm, dust, floating Sand,
Capture the essence of medieval valor in this close-up shot: a weathered knight with spiked hair in high collar armor bearing a bold text crafted masterfully from its metal “buzz”. Positioned in a morning dueling arena, he awaits his opponent with a stance of readiness. Let the fluttering banners and flags in the wind tell the story of anticipation and honor on the battlefield.

提示词3:
A high-resolution, waist up portrait of a young woman in her early twenties with a soft, innocent expression, exuding a sense of Victorian elegance. She has fair, porcelain skin and wide, doe-like eyes that sparkle with a hint of mystery. Her lips are painted a gentle rose shade, slightly parted. Her dark, wavy hair is styled in an elegant Victorian updo adorned with a lace ribbon. She wears a vintage, dress with intricate lace details and a cameo brooch at her neck, evoking both innocence and old-world charm. The background is dimly lit, with shadows that seem to subtly encroach, adding an eerie, gothic atmosphere to the scene. Soft, diffused lighting highlights her delicate features, casting a gentle glow over her pale complexion, giving her an ethereal, haunting beauty that feels both inviting and unsettling
glow effects, godrays, Hand drawn, render, 8k, octane render, cinema 4d, blender, dark, atmospheric 4k ultra detailed, cinematic, Sharp focus, big depth of field, Masterpiece, colors, 3d octane render, 4k, concept art, trending on artstation, hyperrealistic, Vivid colors, extremely detailed CG unity 8k wallpaper, trending on CGSociety, Intricate, High Detail, dramatic intricate, detailed . magnificent, celestial, ethereal, painterly, epic, majestic, magical, fantasy art, cover art, dreamy

说说我的看法,整体上Flux.1 的人像更加真实,也难怪很多人用它来生成虚拟IP,SD3.5对环境的渲染似乎更为丰富一些,可以直出更重风格的图片,但是画手还是不太行,对长提示词的处理也不太好,这与Flux.1有比较大的差距。

写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。


若有侵权,请联系删除
原文地址:https://blog.csdn.net/2401_84830464/article/details/143588856
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!