自然语言处理-文本对分类或回归
我们研究了自然语言推断。它属于文本对分类,这是一种对文本进行分类的应用类型。
以一对文本作为输入但输出连续值,语义文本相似度是一个流行的“文本对回归”任务。 这项任务评估句子的语义相似度。例如,在语义文本相似度基准数据集(Semantic Textual Similarity Benchmark)中,句子对的相似度得分是从0(无语义重叠)到5(语义等价)的分数区间。我们的目标是预测这些分数。来自语义文本相似性基准数据集的样本包括(句子1,句子2,相似性得分):
-
“A plane is taking off.”(“一架飞机正在起飞。”),“An air plane is taking off.”(“一架飞机正在起飞。”),5.000分;
-
“A woman is eating something.”(“一个女人在吃东西。”),“A woman is eating meat.”(“一个女人在吃肉。”),3.000分;
-
“A woman is dancing.”(一个女人在跳舞。),“A man is talking.”(“一个人在说话。”),0.000分。
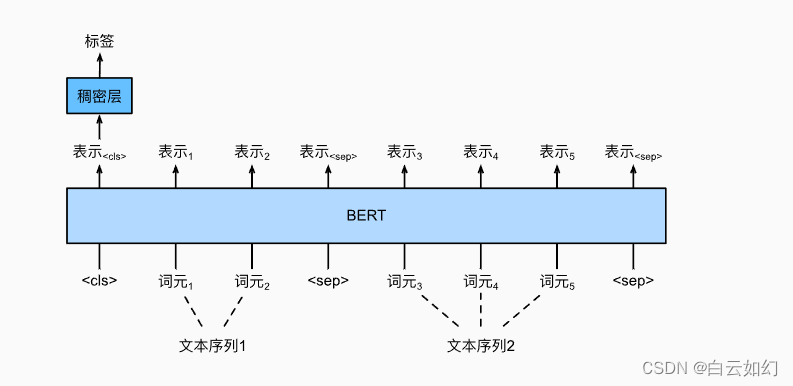
与单文本分类相比,上图中的文本对分类的BERT微调在输入表示上有所不同。对于文本对回归任务(如语义文本相似性),可以应用细微的更改,例如输出连续的标签值和使用均方损失:它们在回归中很常见。
原文地址:https://blog.csdn.net/weixin_43227851/article/details/135857136
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!