python-爬虫入门指南
前言:由于个人负责的运维组,其中有个同事每回在某个项目发版更新后,需手动在k8s容器平台web界面上复制出几百个微服务的名称以及镜像版本等信息,用来更新微服务清单,个人决定抽时间写个爬虫脚本自动完成手动执行的任务。由于公司信息需保密,这里介绍个简单入门的爬虫脚本做为范例。
Python爬虫:通常指的是使用Python语言编写的网络爬虫程序。网络爬虫(Web crawler)是一种自动化的程序,用于在互联网上浏览和检索信息。爬虫可以访问网站,获取网页内容,然后从这些内容中提取有用的数据。以下是Python爬虫的一些基本概念和组成部分:
-
请求网页:使用HTTP库(如
requests)向目标网站发送请求,获取网页内容。 -
解析内容:解析获取到的网页内容,通常使用HTML解析库(如
BeautifulSoup或lxml)来提取所需的数据。 -
数据提取:从解析后的内容中提取有用的信息,如文本、链接、图片等。
-
存储数据:将提取的数据保存到文件、数据库或其他存储系统中。
-
遵守规则:尊重网站的
robots.txt文件,遵守网站的爬虫政策,避免对网站造成不必要的负担。 -
用户代理:模拟浏览器行为,设置用户代理(User-Agent),以避免被网站识别为爬虫。
-
处理重定向:处理HTTP重定向,确保爬虫能够正确地跟踪到最终的网页地址。
-
错误处理:处理网络请求中可能出现的各种错误,如超时、连接错误等。
-
多线程/异步:使用多线程或异步IO(如
asyncio库)来提高爬虫的效率。 -
数据清洗:对提取的数据进行清洗和格式化,以便于后续的分析和使用。
-
遵守法律:在进行网络爬虫操作时,遵守相关法律法规,不侵犯版权和隐私。
Python爬虫的应用非常广泛,包括但不限于:
- 数据挖掘:从网页中提取大量数据,用于市场研究、消费者行为分析等。
- 信息聚合:收集特定主题的信息,构建信息聚合平台。
- 价格监控:监控电商平台的价格变化,进行价格比较。
- 新闻监控:收集新闻网站的最新新闻,用于新闻摘要或新闻分析。
Python爬虫的开发需要考虑到效率、准确性和合法性,以确保爬虫程序能够稳定、高效地运行,同时不违反法律法规和网站政策。
抓取豆瓣前250高分电影爬虫脚本(名称、评分、评价人数):
import requests
from bs4 import BeautifulSoup
import csv
# 请求头部
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
# 解析页面函数
def parse_html(html):
soup = BeautifulSoup(html, 'lxml')
movie_list = soup.find('ol', class_='grid_view').find_all('li')
for movie in movie_list:
title = movie.find('div', class_='hd').find('span', class_='title').get_text()
rating_num = movie.find('div', class_='star').find('span', class_='rating_num').get_text()
comment_num = movie.find('div', class_='star').find_all('span')[-1].get_text()
yield {
'电影名称': title,
'评分': rating_num,
'评价人数': comment_num
}
# 保存数据函数
def save_data():
with open('douban_movie_top250.csv', 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerow(['电影名称', '评分', '评价人数'])
for i in range(10):
url = 'https://movie.douban.com/top250?start=' + str(i * 25)
response = requests.get(url, headers=headers)
for item in parse_html(response.text):
f.write(str(item) + '\n')
if __name__ == '__main__':
save_data()
执行:
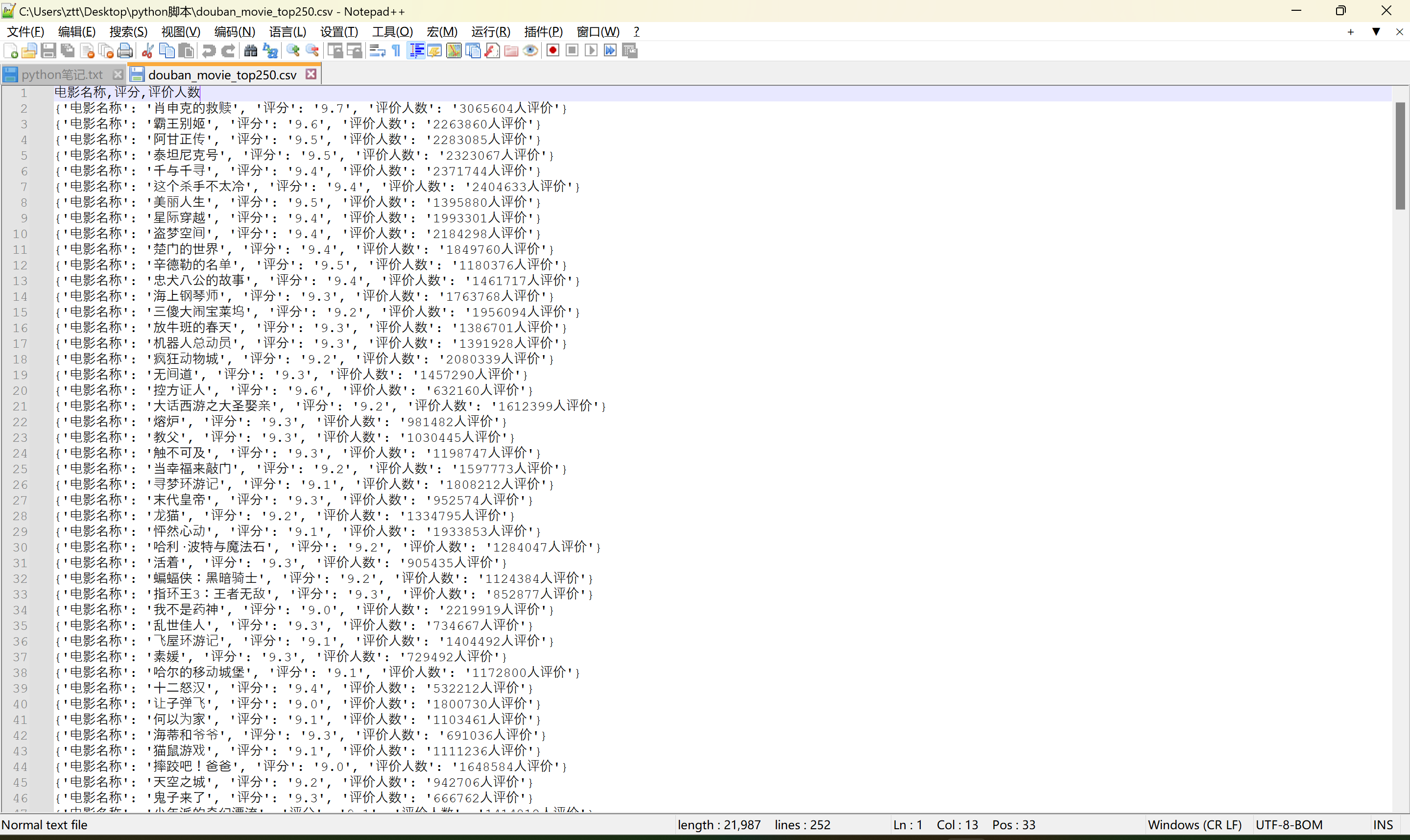
结果:
以下是Python爬虫脚本的逐条讲解:
-
导入必要的库:
import requests from bs4 import BeautifulSoup import csvrequests: 用于发送HTTP请求。BeautifulSoup: 从bs4库中导入,用于解析HTML文档。csv: 用于写入CSV文件。
-
设置请求头部:
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36' }- 这里定义了一个字典
headers,包含User-Agent,用于模拟浏览器请求,避免被网站识别为爬虫。
- 这里定义了一个字典
-
定义解析页面的函数:
def parse_html(html): soup = BeautifulSoup(html, 'lxml') movie_list = soup.find('ol', class_='grid_view').find_all('li') for movie in movie_list: title = movie.find('div', class_='hd').find('span', class_='title').get_text() rating_num = movie.find('div', class_='star').find('span', class_='rating_num').get_text() comment_num = movie.find('div', class_='star').find_all('span')[-1].get_text() yield { '电影名称': title, '评分': rating_num, '评价人数': comment_num }parse_html函数接收一个HTML字符串作为参数。- 使用
BeautifulSoup解析HTML,指定lxml作为解析器。 - 找到所有电影的列表(
ol标签,类名为grid_view),然后遍历每个电影的HTML元素(li标签)。 - 对于每个电影,提取电影名称、评分和评价人数,使用
get_text()方法获取文本内容。 - 使用
yield返回一个包含电影信息的字典。
-
定义保存数据的函数:
def save_data(): with open('douban_movie_top250.csv', 'w', newline='', encoding='utf-8-sig') as f: writer = csv.writer(f) writer.writerow(['电影名称', '评分', '评价人数']) for i in range(10): url = 'https://movie.douban.com/top250?start=' + str(i * 25) response = requests.get(url, headers=headers) for item in parse_html(response.text): f.write(str(item) + '\n')save_data函数用于保存数据到CSV文件。- 使用
with open(...)打开文件,确保文件在操作完成后自动关闭。 - 创建一个
csv.writer对象用于写入CSV文件。 - 写入列标题。
- 循环10次,每次请求豆瓣电影Top 250的不同部分(通过修改URL中的
start参数)。 - 对于每个请求,调用
parse_html函数解析响应的HTML内容,并遍历返回的电影信息。 - 将每个电影的信息转换为字符串并写入文件,每个信息后面添加换行符。
-
主程序入口:
if __name__ == '__main__': save_data()- 这是Python程序的主入口点。
- 如果这个脚本作为主程序运行,调用
save_data函数开始执行。
这个脚本的目的是爬取豆瓣电影Top 250的信息,并将其保存到CSV文件中。每个电影的信息包括名称、评分和评价人数。
原文地址:https://blog.csdn.net/weixin_66855479/article/details/144018220
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!