开源模型也能强过闭源?Llama 3.1-405B数值对标GPT4!
Llama 3.1-405B引起AI浪潮:开源模型也能强过闭源?

Llama 3.1
就这几天,只要你有在关注AI相关的事,你就会看见一群人在讨论 Meta 新出的 Llama 3.1。外网无数的业内大佬都在为之疯狂,因为 Llama3.1-405B 成为了目前开源模型中性能最强的模型,甚至直逼闭源大模型。
了解Llama 3.1
Llama 3.1 405B 是第一个公开可用的模型,在通用知识、可操纵性、数学、工具使用和多语言翻译方面的最新能力方面可以与顶级 AI 模型相媲美。
8B 和 70B 模型的升级版本是多语言的,上下文长度明显更长,为 128K,使用最先进的工具,整体推理能力更强。这使 Meta 的最新模型能够支持高级用例,例如长格式文本摘要、多语言对话代理和编码助手。
Meta 还对其许可证进行了更改,允许开发人员使用 Llama 模型(包括 405B 模型)的输出来改进其他模型。
开源与闭源的战争
开源与闭源的战争也不是一两天了。闭源模型通常由大型科技公司或研究机构开发,这些数据的质量和数量可能比开源模型更高,从而使闭源模型在性能上更具优势。但这次 Llama3.1 也不惯着你,直接“重拳出击”,怒砸了15 万亿个 token 用来训练,表示开源的数据也不比闭源差。
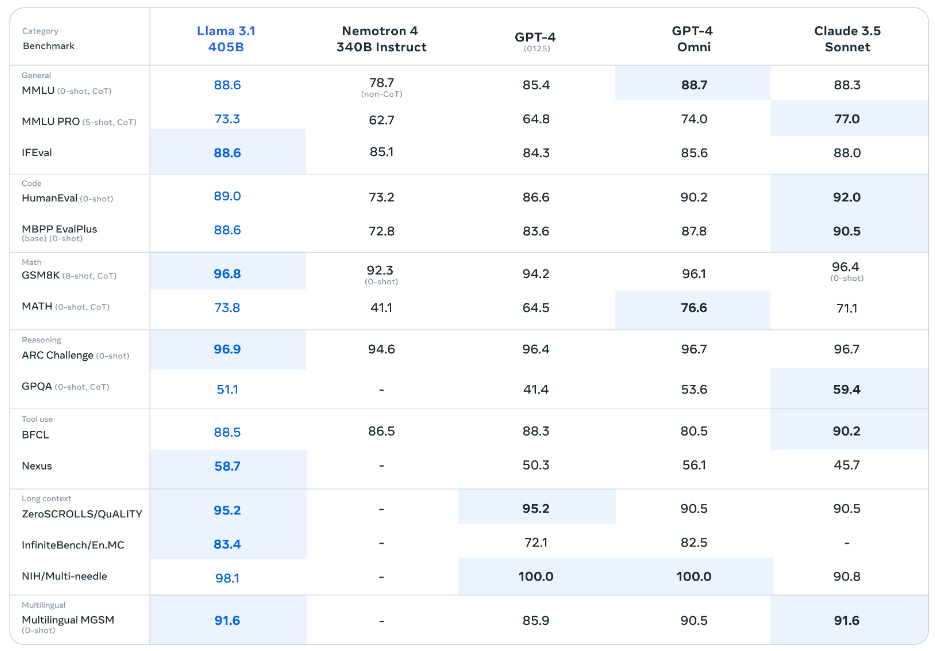
Llama官网数据对比图
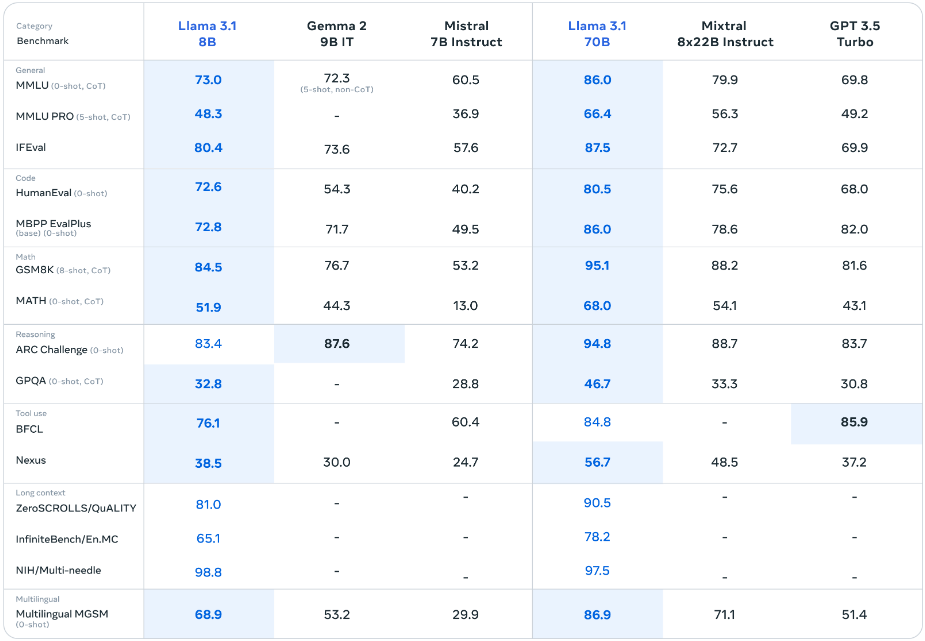
Llama官网数据对比图
从提供的基准测试数据来看的话,Llama 3.1 405B 基本所有的参数都超过了 GPT-4,与 GPT-4mini 也能打的又来有回。性能可以说是非常的恐怖。而8B的版本也是超过了其他同阶水平的模型,70B的版本更是甩开了GPT 3.5 Turbo 一截。
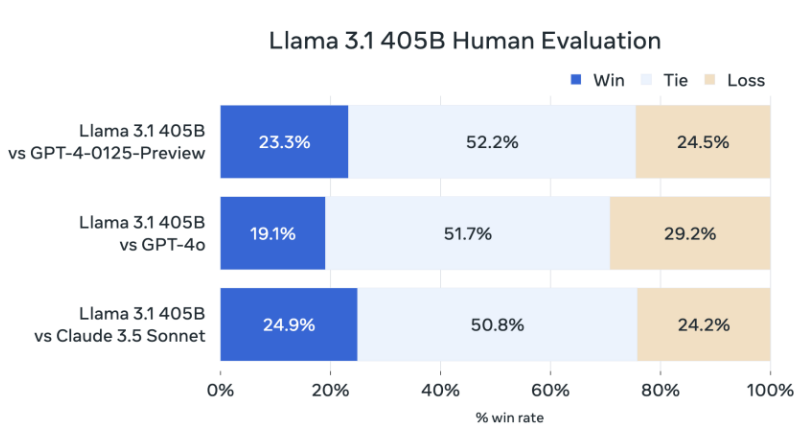
Llama3.1 405B的对比情况
而Llama官方也说他们在150多个多语言基准数据集上进行了性能评测和人工测试。而测试的结果也表明了他们的模型是可以和 GPT-4、GPT-4o 和 Claude 3.5 Sonnet 去相比较的。
NVIDIA × Llaama 3.1

NVIDIA × Llama 3.1
NVIDIA 今天宣布推出了 NVIDIA AI Foundry 服务和 NVIDIA NIM™ 推理微服务,通过 Llama 3.1 公开可用模型集合为全球企业增强生成式 AI 技术。
借助 NVIDIA AI Foundry,企业和国家现在可以使用 Llama 3.1 和 NVIDIA 软件、计算和专业知识为其特定领域的行业用例创建自定义“超级模型”。企业可以使用专有数据以及从 Llama 3.1 405B 和 NVIDIA Nemotron™ Reward 模型生成的合成数据来训练这些超级模型。
NVIDIA 创始人兼首席执行官黄仁勋表示:“Meta 公开提供的 Llama 3.1 模型标志着全球企业采用生成式 AI 的关键时刻。“Llama 3.1 为每个企业和行业打开了构建最先进的生成式 AI 应用程序的闸门。NVIDIA AI Foundry 已在整个过程中集成了 Llama 3.1,并已准备好帮助企业构建和部署定制的 Llama 超级模型。
圈内大佬的看法
Llama 3.1 相关消息
Llama 3.1 相关消息
现在 Llama 3.1 在外网可以说火的是一塌糊涂。今早打开 twitter 全是它的内容。如你所见,不少的大佬在自己的账号上都对 Llama 3.1 称赞不已。

马克·扎克伯格探讨 Llama 3.1
而Meta的创始人兼CEO马克·扎克伯格更是亲笔撰写了一篇题为《Open Source AI Is the Path Forward》的文章。如果你对文章不感兴趣也可以直接搜到他所录制的视频,视频中也聊到了 Llama 3.1 的方方面面,很有意思。
就目前来看,Llama 3.1 的出现无疑给 AI 领域带来了新的冲击和思考。它证明了开源模型具备挑战闭源模型的实力,也让人们看到了开源模式在推动 AI 发展方面的巨大潜力。
有关厚德云
厚德云致力于为用户提供稳定、可靠、易用、省钱的 GPU 算力解决方案。海量 GPU 算力资源租用,就在厚德云。
原文地址:https://blog.csdn.net/holdcloud/article/details/140665375
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!