SAM功能改进VRP-SAM论文解读VRP-SAM: SAM with Visual Reference Prompt
现已总结SAM多方面相关的论文解读,具体请参考该专栏的置顶目录篇
一、总结
1. 简介
发表时间:2024年3月30日
论文:
2402.17726.pdf (arxiv.org)![]() https://arxiv.org/pdf/2402.17726.pdf代码:
https://arxiv.org/pdf/2402.17726.pdf代码:
syp2ysy/VRP-SAM (github.com)![]() https://github.com/syp2ysy/VRP-SAM
https://github.com/syp2ysy/VRP-SAM
2. 摘要
在本文中,我们提出了VRP-SAM,通过集成视觉参考提示(VRP)编码器实现了SAM框架的创新扩展。这个附加功能使SAM能够利用视觉参考提示进行引导分割。
核心方法包括通过VRP编码器编码带注释的参考图像,然后与目标图像交互,在SAM框架内生成有意义的分割提示,对目标图像中的特定对象进行分割。VRP编码器可以支持各种参考图像的注释格式,包括点、框、涂鸦和掩码。它克服了SAM现有提示格式的限制,特别是在复杂场景和大型数据集中。为了提高VRP- SAM的泛化能力,VRP编码器采用了元学习策略。我们还对Pascal和COCO数据集进行了广泛的实证研究。
VRP-SAM在保留SAM固有优势的同时扩展了它的多功能性、灵活性和适用性,增强了用户友好性。大量的实证研究表明,VRP-SAM在视觉参考分割中以最小的可学习参数实现了最先进的性能,展示了强大的泛化能力,允许它执行未见对象的分割并实现跨域分割。
3. 引言
SAM存在以下两个问题:如下图所示,SAM依靠用户提供的提示(点、框、粗掩码)对目标图像中的物体进行分割,要求用户对目标物体有全面的了解。用户对目标对象的熟悉程度会显著影响提供特定提示的有效性。

此外,不同图像中目标对象的位置、大小和数量的变化需要为每个图像定制提示。如图所示,为了对“自行车”进行分割,用户需要为每个图像定制不同的提示,这极大地影响了SAM的效率。为了解决这一问题,PerSAM和Matcher结合语义相关模型来建立参考目标相关性,获得目标对象的伪掩码。在此之后,设计了一种采样策略,从伪掩模中提取一组点和边界框,作为SAM分割目标图像的提示。这些方法忽略了伪掩码内的假阳性,并对超参数表现出高灵敏度。因此,它严重依赖于伪掩码的质量,泛化能力差。

现有的方法受到SAM现有提示模式的限制,在面对复杂的对象和不熟悉的场景时可能会遇到困难。我们整合视觉参考提示来克服这些局限性。视觉参考提示是描述用户期望分割的对象的带注释的参考图像。如下图所示,通过简单地提供一个可视的参考提示对于自行车,可以在不同的图像中分割自行车,而不需要用户为每个图像提供特定的提示。它显著提高了SAM的效率,同时减少了对用户熟悉对象的依赖。

视觉参考分割的目的是利用语义标注的参考图像来指导目标图像中与参考图像中具有相同语义的对象或区域的分割。在目前的研究中,方法大致可以分为两大类:基于原型的方法和基于特征匹配的方法。基于原型的方法,如PFENet、PANet和CWT,通常侧重于区分具有不同类特定特征的原型。另一方面,ASGNet通过增加原型的数量来提高分割性能。另一种特征匹配方法利用参考图像和目标图像之间的像素级相关性来显著增强分割性能,如CyCTR和HDMNet等方法。此外,现代大尺度视觉模型已经将视觉参考分割作为主要任务,因为它在处理复杂物体和未知场景中起着不可或缺的作用。然而,需要注意的是,SAM不具备执行此任务的能力,这强调了引入VPR-SAM的必要性。
4. 贡献
(1)提出了一个由特征增强器和提示生成器组成的视觉参考提示(VRP)编码器,它接受多种格式的视觉参考,并将其编码为提示嵌入,而不是几何提示。
(2)通过元学习方法,VRP编码器在参考图像中提取目标对象的原型特征,并将其与目标图像的特征相结合,以生成用于分割的提示。
(3)在和
数据集上进行了广泛的实验,证明了VRP-SAM在处理复杂场景和大量图像时的有效性,特别是在处理新对象和跨域场景时。
(4)通过结合BCE损失和Dice损失,VRP-SAM在生成精确分割结果方面表现出色。
二、模型结构
1. 整体流程
VRP-SAM利用带注释的参考图像作为提示,接受各种注释格式(点、涂鸦、方框和掩码)的输入,来分割目标图像中相似的语义对象。在SAM固有功能的基础上,VRPSAM增强了模型的视觉参考分割能力。引入视觉参考提示(VRP)不仅使提示多样化,使模型能够快速分割具有相同语义的对象,而且还结合了元学习机制,显着提高了模型的泛化,特别是在处理新对象和跨域场景时。
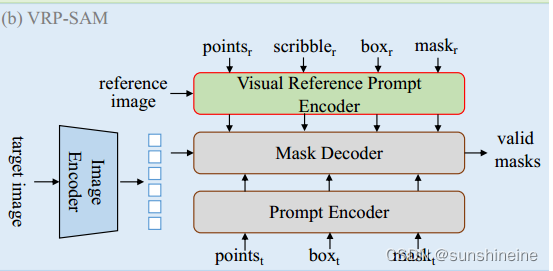
VRP-SAM通过训练效率高的视觉参考提示编码器扩展了SAM,在不损害其原始功能的情况下执行视觉参考分割。首先,它可以容纳不同粒度的视觉参考,其次,直接将这些视觉参考编码成提示嵌入而不是几何提示。然后,将这些提示嵌入直接馈送到掩码解码器中,从而生成目标掩码。
如下图所示,VRP编码器由特征增强器和提示生成器组成。具体来说,VRP编码器引入了语义相关模型,将参考图像和目标图像编码到同一空间。采用元学习方法,我们首先从参考图像的注释信息中提取目标对象的原型,增强目标对象在两幅图像中的表示。根据元学习方法,首先从带注释的参考图像中生成目标对象(用户标记)的原型,目的是突出这些目标实例在参考和目标图像中。然后,我们引入了一组可学习的查询,从关注的增强参考特征中提取目标对象的语义线索。然后,这些查询与目标图像交互,生成可用于掩码解码器的提示嵌入,以分割目标图像中语义特定的对象。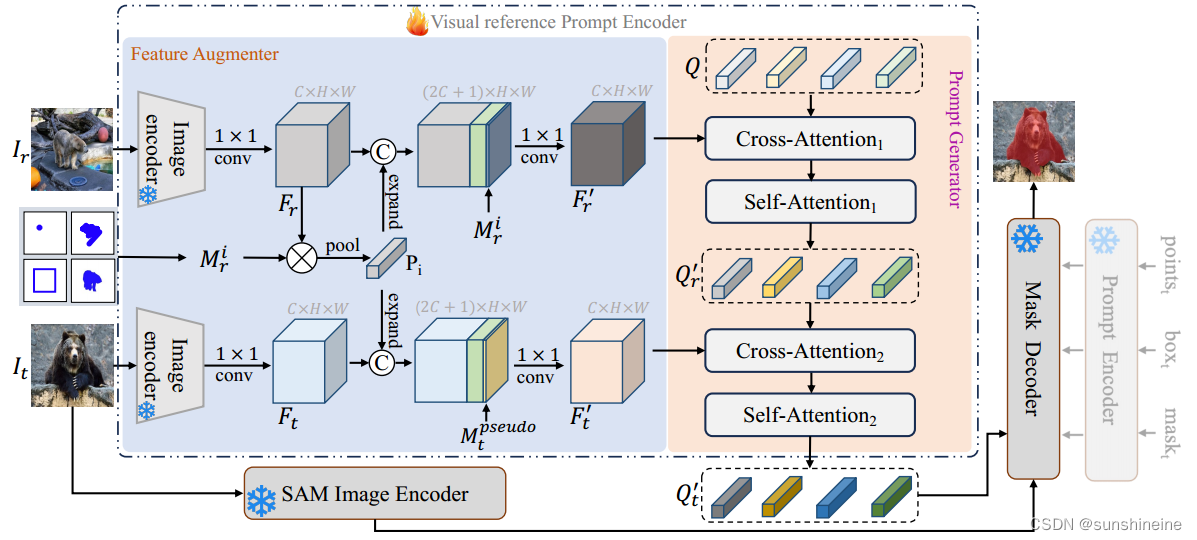
2. 特征增强器
特征增强器受元学习启发,能够将参考图像的注释信息编码到参考图像和目标图像的特征中,从而在两个图像之间建立语义关联。为目标图像中特定类别的对象分割提供了强有力的特征表示,从而提高了分割的准确性和模型的泛化能力。
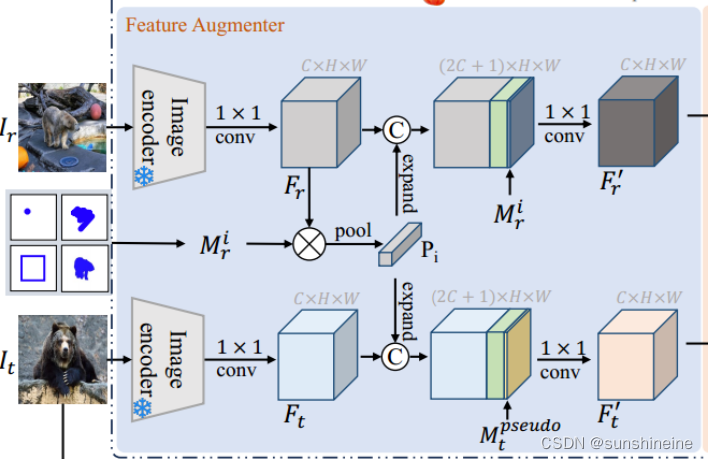
特征增强器的主要步骤包括:
(1)初始编码:使用语义感知图像编码器(例如ResNet-50)分别对参考图像和目标图像
进行编码,得到特征图
和
。
(2)提取原型特征:使用参考图像的掩码(表示以下注释格式之一:点、涂鸦、框或掩码)从参考图像的特征图
中提取与特定类别
相关的原型特征
。
(3)特征增强:将原型特征与参考图像和目标图像的特征图
和
进行拼接,增强特征图中关于类别
的上下文信息。
与掩码
连接,
与伪掩码
连接。
(4)降维处理:通过共享的1×1卷积层减少增强特征的维度,得到降维后的特征图(和
),这些特征图包含了类别
的前景表示和其他类别的背景表示。
(5)特征图输出:最终,特征增强器输出增强后的参考图像和目标图像特征(和
),这些特征随后被送入提示生成器(Prompt Generator)以获取一组视觉参考提示。
【注意】伪掩码生成:根据相似性图,选择最相似的像素点作为目标对象的近似位置,并将这些点连接起来形成一个粗略的掩码,即伪掩码。它的主要作用是为分割模型提供一个初步的对象位置提示,帮助模型在没有精确标注的情况下进行对象分割。
3. 提示生成器
提示生成器的目的是为SAM掩码解码器生成一组富含语义信息的视觉参考提示嵌入(embeddings),这些嵌入能够有效地指导目标图像中的前景对象分割,以实现目标图像中特定对象的精确分割。
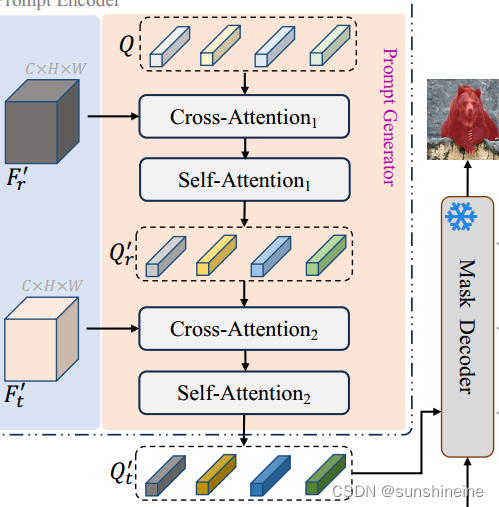
提示生成器的主要步骤包括:
(1)引入可学习查询(queries):提示生成器首先引入一组可学习的查询向量,这些查询向量用于从参考图像中提取与目标对象相关的语义信息。
(2)交互参考图像特征:这些查询向量通过交叉注意力(cross-attention)和自注意力(self-attention)层与参考图像特征进行交互,从而获得关于待分割对象的类别特定信息。
(3)生成目标图像提示:接着,这些查询向量通过交叉注意力与目标图像特征
进行交互,以获取目标图像中的前景信息。之后,使用自注意力层更新这些查询向量,生成一组与SAM表示对齐的提示
。
(4)产生提示嵌入:最终生成的作为视觉参考提示嵌入,它们具备指导目标图像中特定语义对象分割的能力。将这些视觉参考提示嵌入输入到掩码解码器中,可以生成目标图像中类别
的掩码
。
4. 损失函数
VRP-SAM模型中训练视觉参考提示编码器时,结合了二元交叉熵(Binary Cross-Entropy, BCE)损失和Dice损失,使其能够在训练过程中同时优化像素级别的分类准确性和对象空间位置的准确性,从而提高模型在视觉参考分割任务上的性能。
(1)BCE损失:这种损失确保像素级别的准确性,即模型预测的掩码与真实标签之间的匹配程度。BCE损失鼓励模型正确地识别目标对象的每个像素。
(2)Dice损失:这种损失提供了额外的上下文信息,帮助模型在像素级别进行更准确的分割。Dice损失是一种常用于图像分割任务的损失函数,它衡量两个样本的相似度,特别是在医学图像分割中。
(3)总损失:VRP-SAM的总损失是BCE损失和Dice损失的组合,其中包含了一个平衡因子,用于调整两种损失的相对重要性。这种组合损失函数全面考虑了分割的准确性和上下文效果,从而更有效地指导视觉参考提示编码器生成精确的分割结果。
三、实验
1. 设置
数据集:在和
数据集上验证VRP-SAM的分割性能和泛化能力。具体来说,我们将两个数据集中的所有类组织为4个folds,对于每个folds,
包括15个用于训练的基类和5个用于测试的新类,而
包括60个训练基类和20个测试新类。在每个folds中随机抽取1000对参考目标对用于评估模型的性能。在每个folds中按照SEEM通过基于参考真实掩码随机模拟用户输入来生成这些注释标签。
实现细节:在视觉参考提示编码器中,使用VGG-16和ResNet-50作为图像编码器,并使用ImageNet预训练的权值进行初始化。使用AdamW优化器以及余弦学习率衰减策略来训练VRPSAM。在数据集上训练了50个epoch,初始学习率为1e-4,批大小为8。在
数据集上训练了100个epoch,初始学习率为2e-4,批大小为8。在VRP中,查询次数默认设置为50,所有实验的输入图像大小需要调整为512 × 512。在训练过程中,根据掩码注释获得点、涂鸦和框的注释。
2. 与最先进的比较
(1)与其他基础模型比较:在上的一次性语义分割结果。灰色表示模型是由域内数据集训练的。†表示使用SAM的方法。
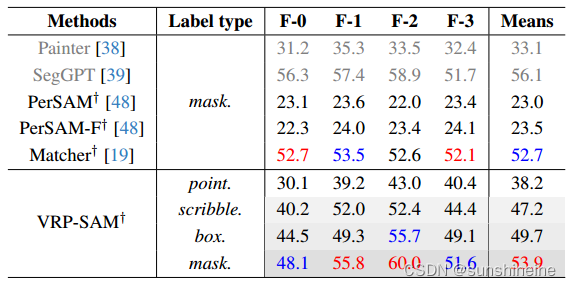
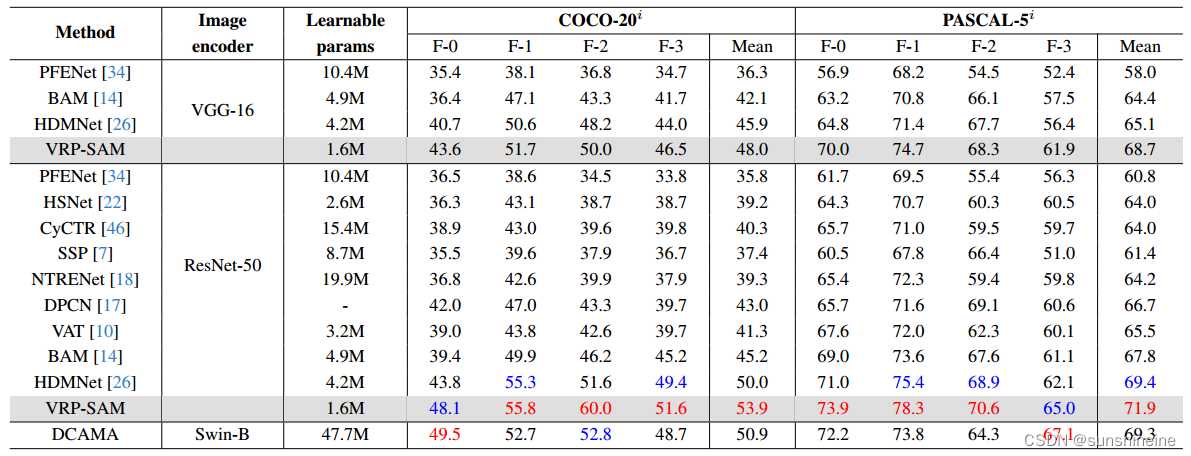
(2)与few-shot方法比较:在和
上的一次性语义分割性能,红色和蓝色分别代表最优和次优结果。
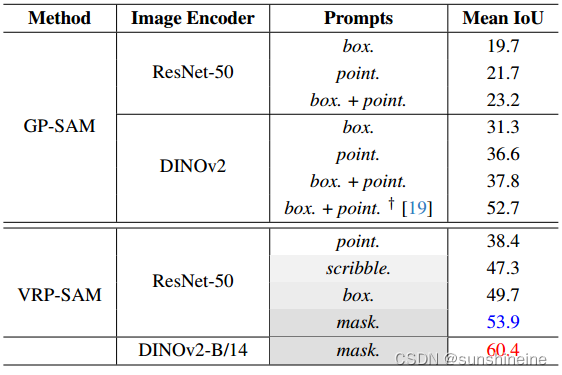
3. 几何提示的比较
如下表所示,几何提示从伪掩码中随机采样。†表示Matcher中提出的精心设计的抽样策略。
下图显示了GP-SAM和VRP-SAM的分割结果。可视化结果表明,GP方法容易产生假阳性提示,严重影响分割性能。相反,我们的VRP有效地避免了这些问题。

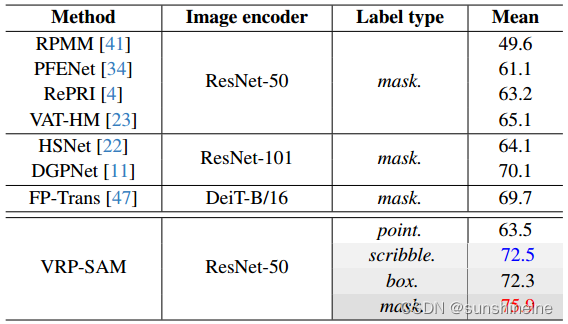
4. 概括评价
(1)域的转变:从到
域移下的评估(Mean IoU(%))。
(2)可视化:给出了VRP-SAM在不同图像样式下的定性结果。目标图片来自互联网。

5. 消融实验
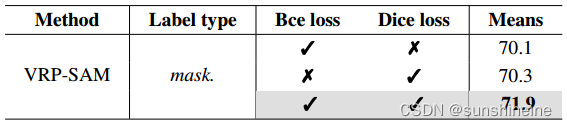
(1)损失:VRP-SAM不同损失函数的消融研究。
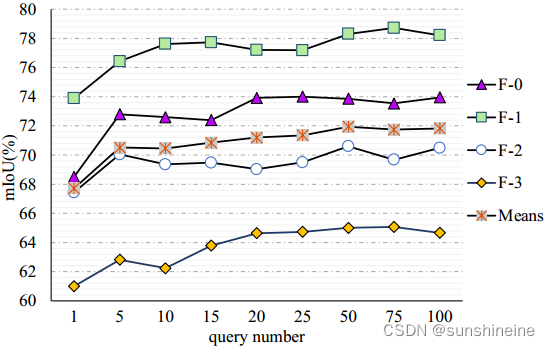
(2)查询次数:不同查询数对VRP-SAM的消融研究。x轴表示查询的数量,y轴表示模型性能。
(3)查询的初始化: VRP-SAM上不同查询初始化方法的消蚀研究。

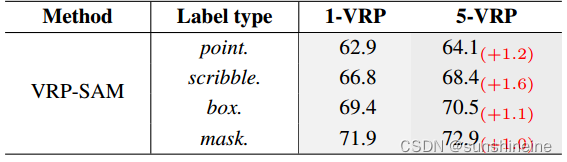
(4)VRP数量:VRP-SAM几种视觉参考提示的消融研究。
原文地址:https://blog.csdn.net/sunshineine/article/details/137265720
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!