Embedding #notebook
Embedding
上一个篇章huggingface tokenizer #notebook我们讲解了tokenizer的使用,这一个篇章我们继续讲解所谓的embedding,这是通向模型的第一个层,它实际上就是一个全连接层,那么从一个text文本’我爱中南大学’,经过tokenizer得到了每个token在vocab.txt中的id编码,即[101, 2769, 4263, 704, 1298, 1920, 2110, 102] (ps:别忘了101和102在bert词表中的含义),那么接下来经过embedding层的时候会得到什么呢?
整个过程可以如下图所示:
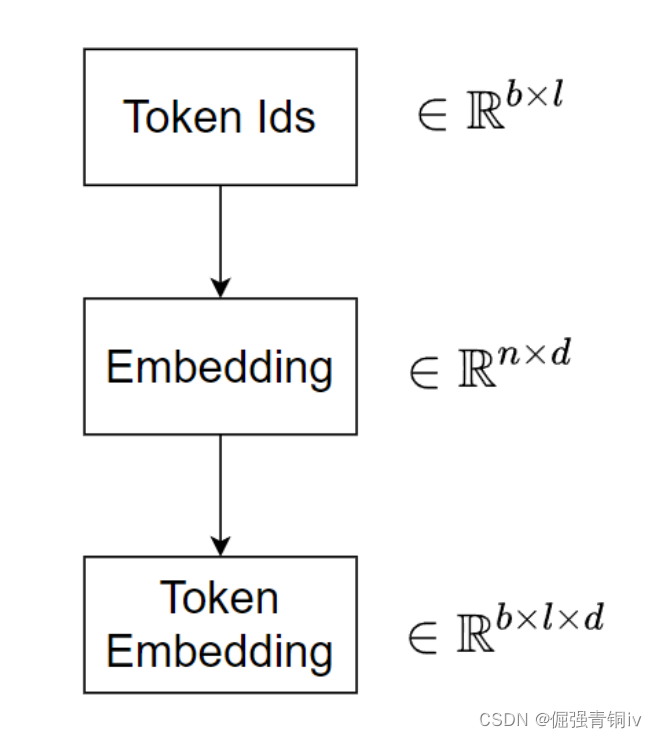
一个batch的文本有b个,每个文本的长度为l,那么经过tokenizer得到了一个 b × l b\times l b×l的token id矩阵,接着通过embedding层,这个embedding层是 n × d n \times d n×d的全连接层(其中n代表词表的大小,d映射成的词向量的维度),得所谓的token embedding,它的形状是 b × l × d b \times l \times d b×l×d,这个时候就有人会困惑了, b × l b \times l b×l的矩阵与 n × d n \times d n×d的矩阵是通过怎样的计算得到 b × l × d b \times l \times d b×l×d的矩阵的呢?这貌似也不是矩阵乘法啊?
下面我们就来解惑:
来龙去脉还得从embedding的来历说起,此处省略一万字,详情可以知乎之[手动\dog]。
当我们得到所谓的token id的时候,不能只把他看成一个number,而是要看成一个one-hot编码的向量,这么一说是不是就恍然大悟了,这个形状为
b
×
l
b \times l
b×l的token id矩阵其实还有一个维度,那就是在每个token上可以张成一个
1
×
n
1 \times n
1×n的one-hot编码向量,每个token在各自token id处的one-hot向量取值为1,其余地方都为0,举个例子,比如上面"我爱中南大学"中的"我"在词表中的id是2769,假设整个词表有3000个token,那么"我"的one-hot编码就是
[
0
,
…
,
0
⏟
2769
个
,
1
,
0
,
…
,
0
⏟
230
个
]
\underbrace{[0,\ldots,0}_{2769\text{个}},1,\underbrace{0,\ldots,0}_{230\text{个}}]
2769个
[0,…,0,1,230个
0,…,0]
那么在计算的时候呢,就是每个这样的one-hot向量与embedding进行矩阵乘法,这就很简单了
1
×
n
1 \times n
1×n的行向量与
n
×
d
n \times d
n×d的矩阵相乘得到
1
×
d
1 \times d
1×d的token embedding,也就是俗称的词向量。
一个简单的例子如下:
(
0
1
0
0
0
0
0
1
0
0
)
⏟
Token的one-hot编码
×
(
w
11
w
12
w
13
w
21
w
22
w
23
w
31
w
32
w
33
w
41
w
42
w
43
w
51
w
52
w
53
)
=
(
w
21
w
22
w
23
w
31
w
32
w
33
)
⏟
Token的embedding编码
\underbrace{\begin{pmatrix} &0 &1 &0 &0 &0 \\ &0 &0 &1 &0 &0 \end{pmatrix}}_{\text{Token的one-hot编码}}\times \begin{pmatrix} &w_{11} &w_{12} &w_{13} \\ &w_{21} &w_{22} &w_{23} \\ &w_{31} &w_{32} &w_{33} \\ &w_{41} &w_{42} &w_{43} \\ &w_{51} &w_{52} &w_{53} \\ \end{pmatrix}= \underbrace{\begin{pmatrix} &w_{21} &w_{22} &w_{23} \\ &w_{31} &w_{32} &w_{33} \\ \end{pmatrix}}_{\text{Token的embedding编码}}
Token的one-hot编码
(0010010000)×
w11w21w31w41w51w12w22w32w42w52w13w23w33w43w53
=Token的embedding编码
(w21w31w22w32w23w33)
好了,有了这个直观的认识,下面来写写代码吧!
pytorch中embedding
pytorch中nn模块已经实现了embedding层
参考代码如下:
import torch
import torch.nn as nn
# 创建一个词汇表大小为10,嵌入维度为3的词嵌入层
# 换句话说embedding的形状是n*d(10*3)
embedding = nn.Embedding(num_embeddings=10, embedding_dim=3)
# 获取权重
embedding_weights = embedding.weight
print(embedding_weights)
# 随机生成一个包含6个单词索引的张量
# 换句话说 input_indices的形状是b*l(5*6)
input_indices = torch.randint(0, 10, (5,6))
print(input_indices)
# 通过词嵌入层获取对应的嵌入向量
embedded_vectors = embedding(input_indices)
# 得到的embedded_vectors形状肯定是b*l*d(5*6*3)
print(embedded_vectors.shape)
# 得到第一个句子中所有token的词向量
print(embedded_vectors[0,:,:])
参考输出如下:
Parameter containing:
tensor([[-0.1934, 0.6466, 0.5258],
[ 0.5738, -0.9027, 0.4368],
[-1.0536, -0.4649, 0.2745],
[-0.8986, -1.9465, 0.6572],
[ 0.4368, 0.7227, -0.1527],
[ 0.2178, -0.2536, -0.6115],
[-0.1638, -0.0326, 0.0175],
[ 0.4321, -0.0515, 0.9138],
[-0.2880, 0.6950, 0.9472],
[ 0.4437, 1.4020, -0.4609]], requires_grad=True)
tensor([[8, 0, 9, 6, 1, 1],
[4, 8, 2, 6, 8, 8],
[2, 1, 0, 8, 7, 7],
[2, 1, 7, 2, 6, 0],
[8, 3, 4, 1, 5, 4]])
torch.Size([5, 6, 3])
tensor([[-0.2880, 0.6950, 0.9472],
[-0.1934, 0.6466, 0.5258],
[ 0.4437, 1.4020, -0.4609],
[-0.1638, -0.0326, 0.0175],
[ 0.5738, -0.9027, 0.4368],
[ 0.5738, -0.9027, 0.4368]], grad_fn=<SliceBackward0>)
不难看出,第一个句子[8, 0, 9, 6, 1, 1]中每一个token id对应的词向量的取值在embedding层的行标与token id是一致。
可以手动验证一下计算的对不对。
当然,在现在的语言模型中embedding层所做的事情远不止编码这么简单,就以bert为例,除了得到token embedding,还会得到position embedding,token_type_embedding,以及还会进行LN和dropout等等。这些就留给读者自己探索吧!
原文地址:https://blog.csdn.net/weixin_53162487/article/details/136972355
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!