计算机毕业设计Python+Scrapy+Vue.js机器学习招聘推荐系统 招聘数据可视化 招聘爬虫 招聘数据分析 大数据毕业设计 大数据毕设
桂林学院
本科生毕业论文(设计、创作)开题报告
| 二级学院 | 理工学院 | 专业 | 数据科学与大数据技术(专升本) | 年级 | 2022级 | 姓名 | 徐彬彬 | ||
| 学号 | 202213018222 | 指导教师 | 沈岚岚 | 职称/学位 | 高级实验师 | 第二 导师 | 职称/学位 | / | |
| 论文(设计、创作) 题目 | 招聘网站数据分析平台的设计与实现 | ||||||||
| 研究综述(前人的研究现状、进展及意义): 研究现状、进展: 目前的招聘网站数据分析平台涉及到了数据抓取和爬虫、数据处理和清洗、数据存储和管理、数据可视化、机器学习和统计分析、自然语言处理、高性能计算和云计算技术等等。主要就是通过网络爬虫获取招聘网站上的大量信息,并将其转换成可处理的数据格式。进而对原始数据进行清洗、去重、格式化等处理,再使用MySQL、MongoDB数据库技术对数据进行存储和管理,以便后续的查询和分析。利用Tableau、PowerBI等可视化工具将数据转化为易于理解和分析的图表和报表。然后通过各种机器学习算法和统计分析方法,从数据中提取出有意义的信息和规律来提供支持和参考。用自然语言处理技术,对招聘信息进行分析和理解,从而提取出关键信息和特征。利用高性能计算和云计算技术实现大规模数据的计算和分析,提高数据处理和分析的效率。 现在招聘网站数据分析平台通过对大量招聘数据、招聘信息和求职者简历数据、招聘数据和薪酬数据、不同招聘渠道的数据、候选人履历和面试数据的分析,实现了人才需求预测、职位匹配优化、薪酬分析和优化、招聘渠道优化、候选人评估和筛选功能。 这些成果为企业在人才招聘和管理方面提供了重要的参考依据,帮助企业提高招聘效率、降低成本,并更好地满足人才需求。 意义:
| |||||||||
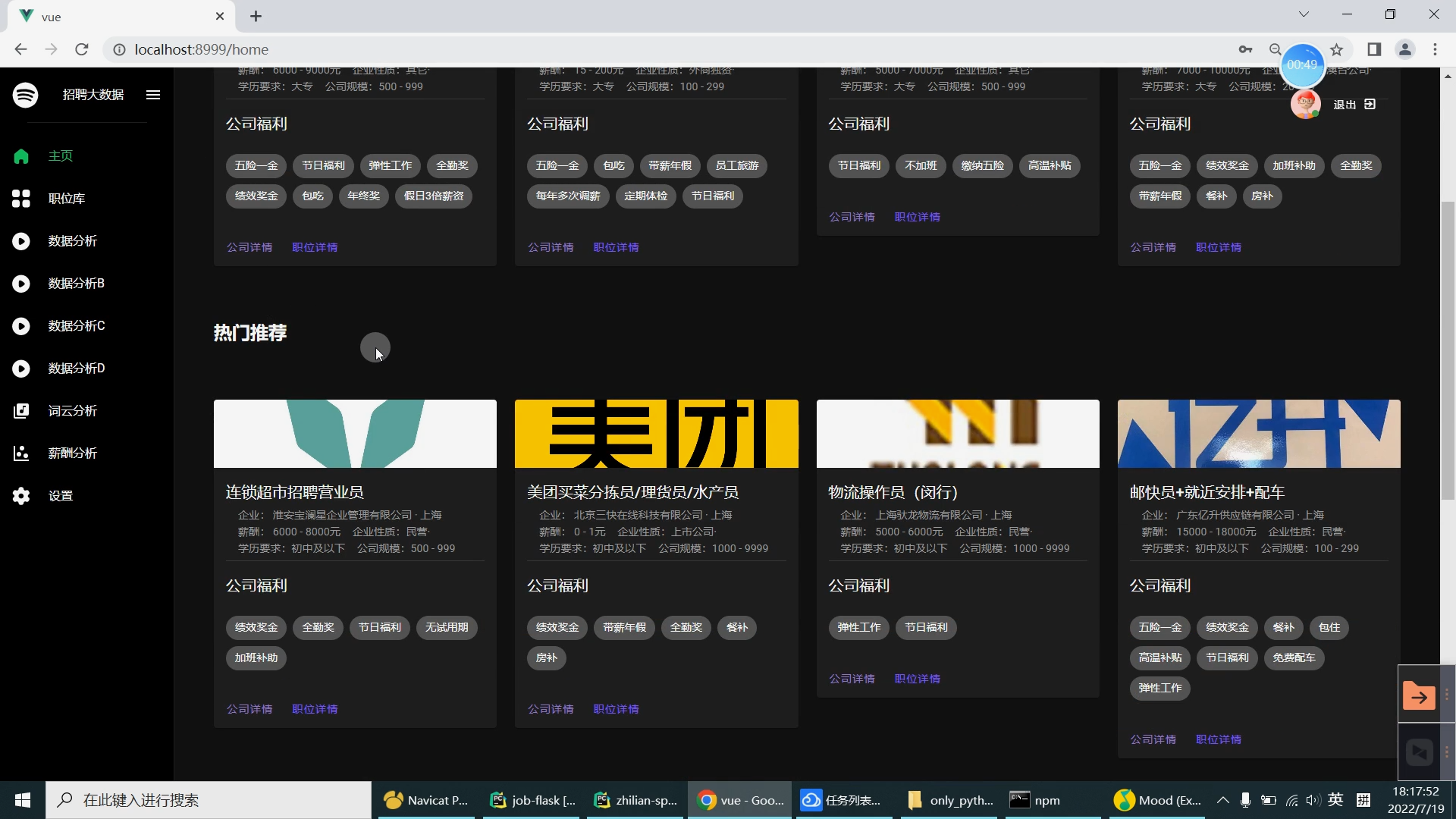
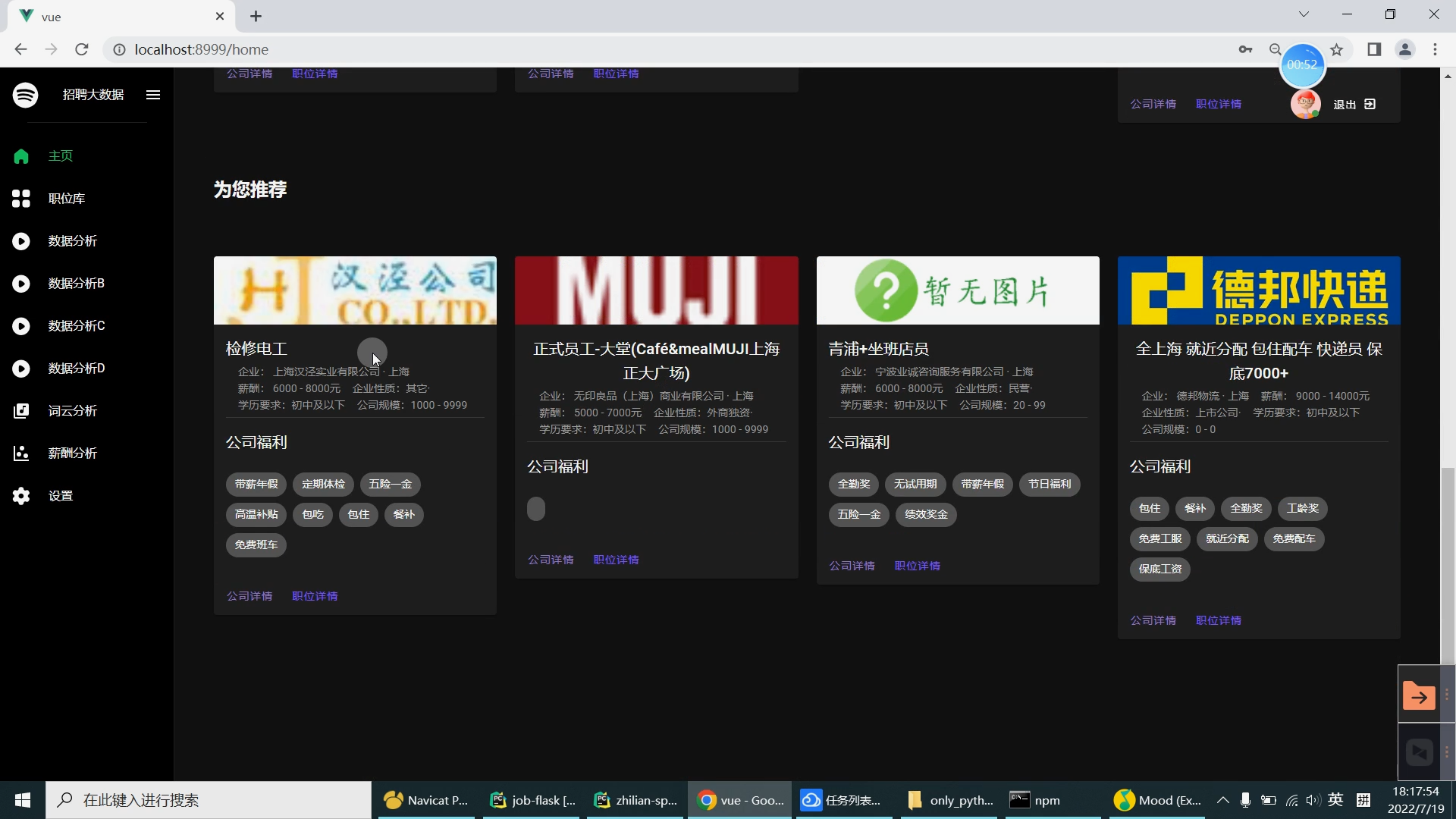
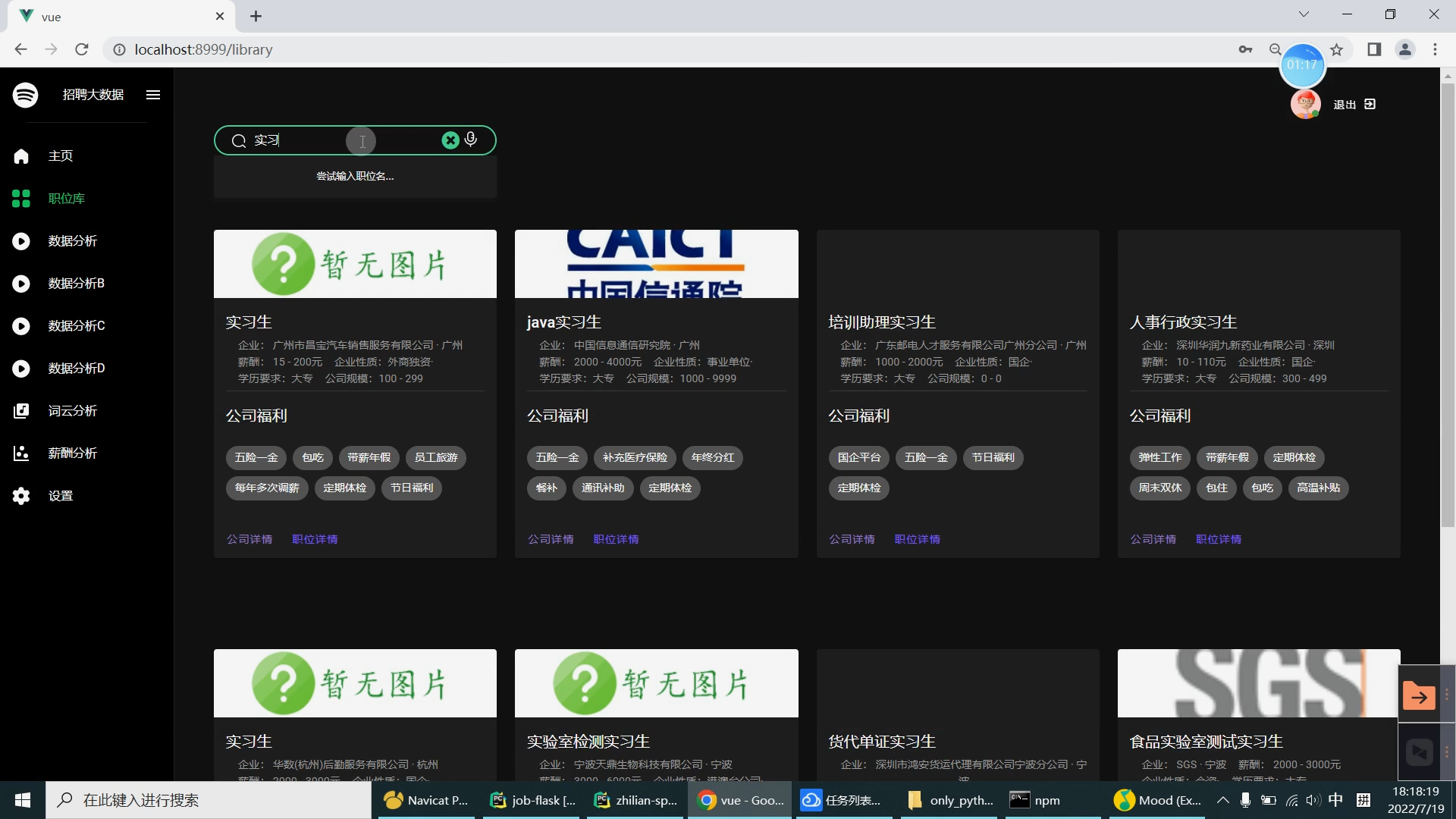
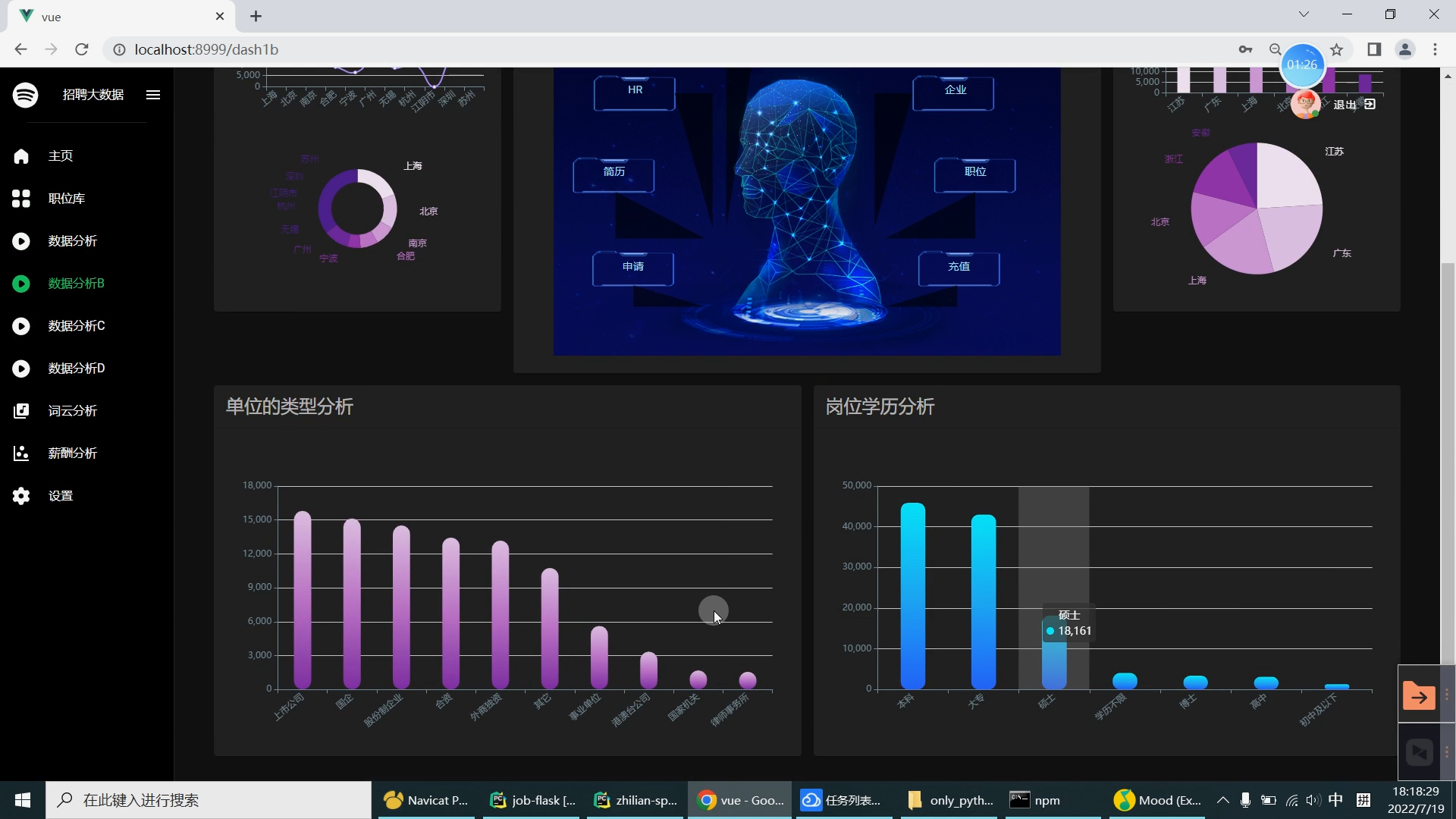
| 研究的主要内容和拟采用的方法、实施计划: 研究内容: 设计内容为主要是由大数据系统以及可视化前端子系统组成。在可视化前端子系统中主要是采用了Springboot框架,mybatis框架,因为其去繁就简的特点,很容易创建一个独立的产品级应用,在可视化阶段采用Echarts来提供可交互的直观数据可视化图表。本系统采用的数据库是MySQL数据库,其目的是用来存储利用爬虫爬取到的大量招聘信息数据集和数据处理之后的分析结果。大数据系统中主要是对招聘信息数据集通过使用Hive进行数据清洗,然后再导入Hadoop HDFS中分布存储。在通过Spark并行计算进行数据抽取,多维分析,查询统计等操作来完成数据分析部分。在前端子系统中的数据明细查询功能中读取到MySQL数据库中的数据分析结果,最后生成Echarts图表展示给用户,大数据招聘分析平台的工作流程如下图所示。
拟采用的方法:
实施计划:
| |||||||||
| 指导教师意见: 指导教师签名: 年 月 日 | |||||||||

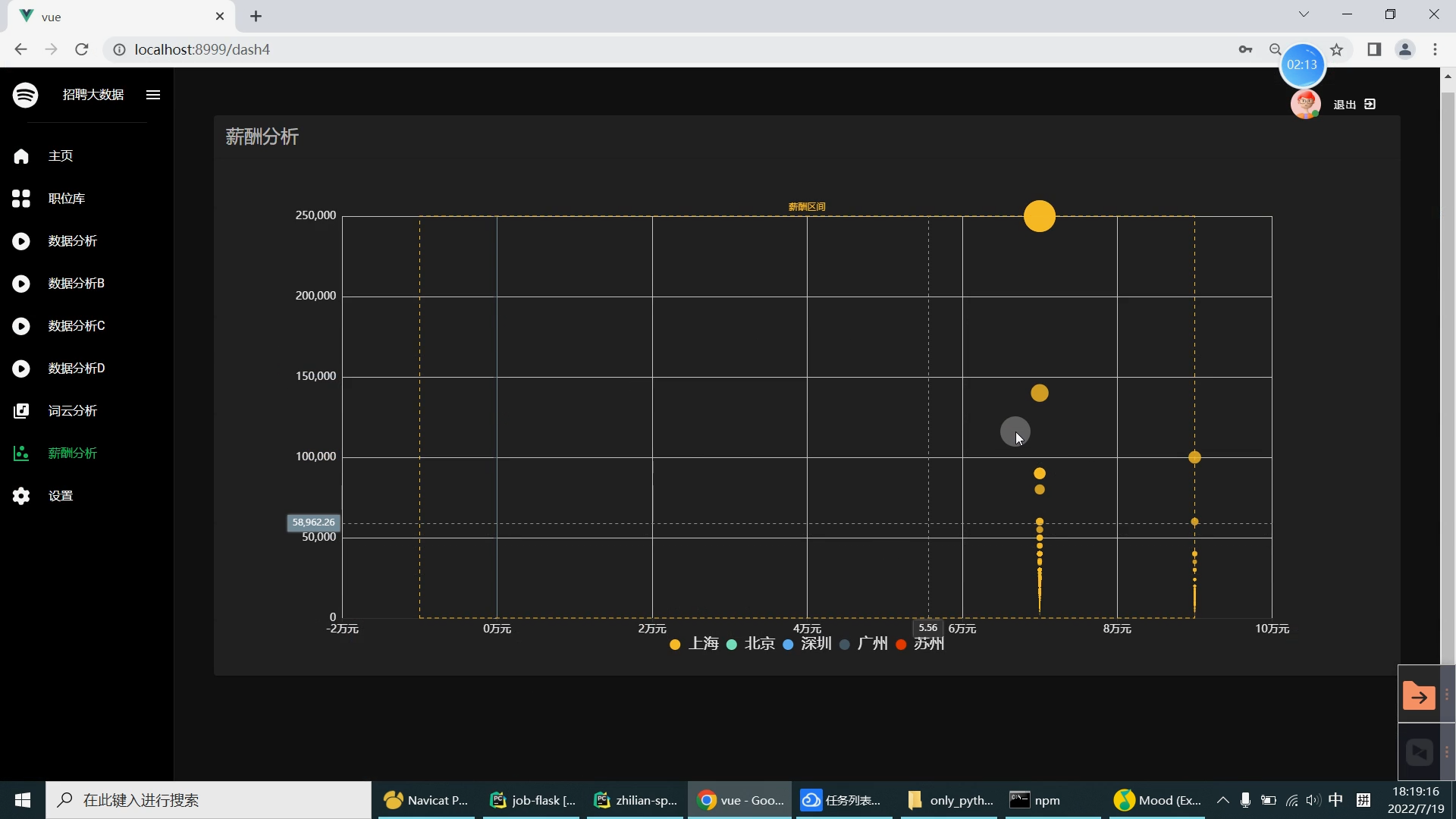
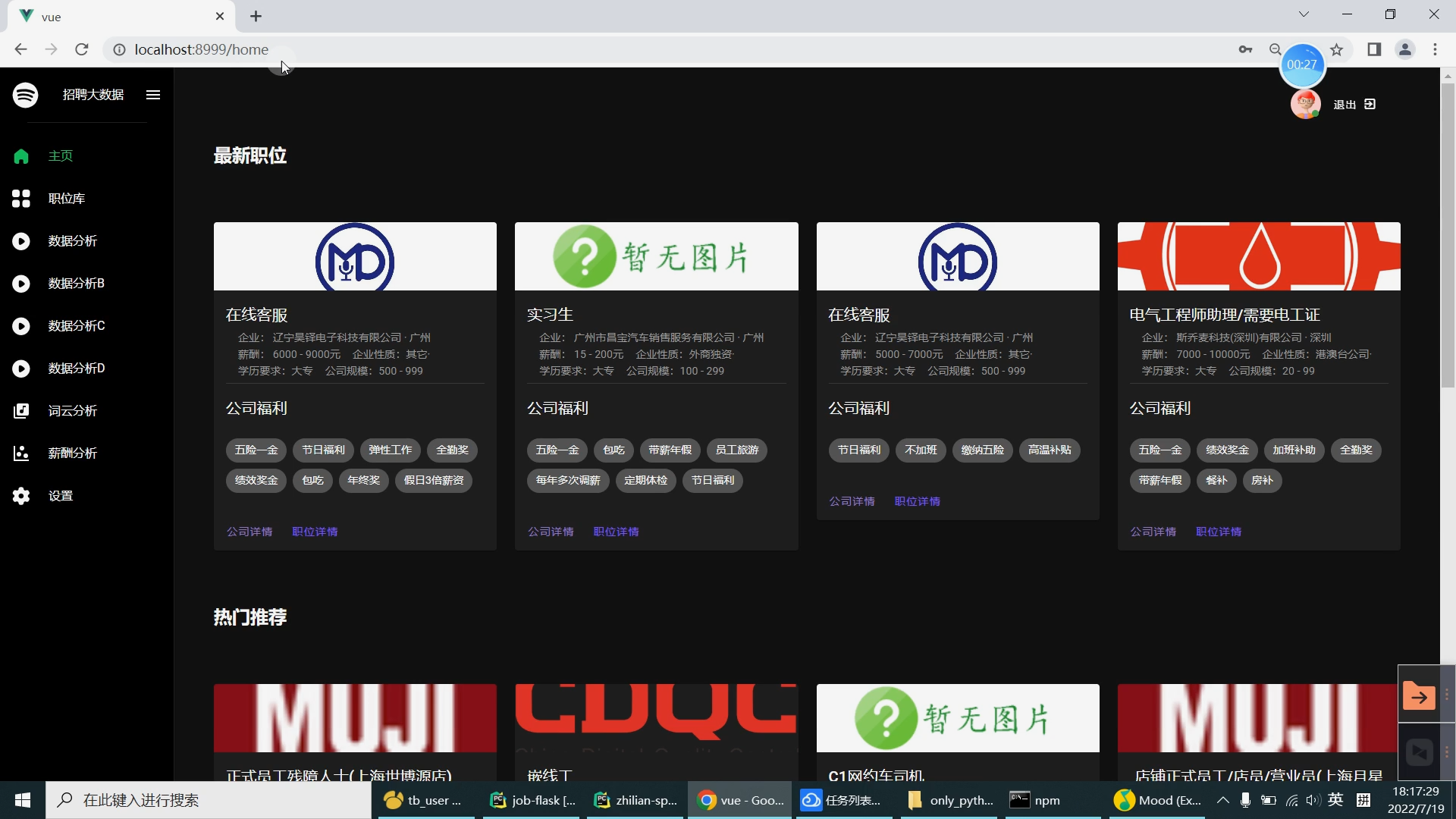


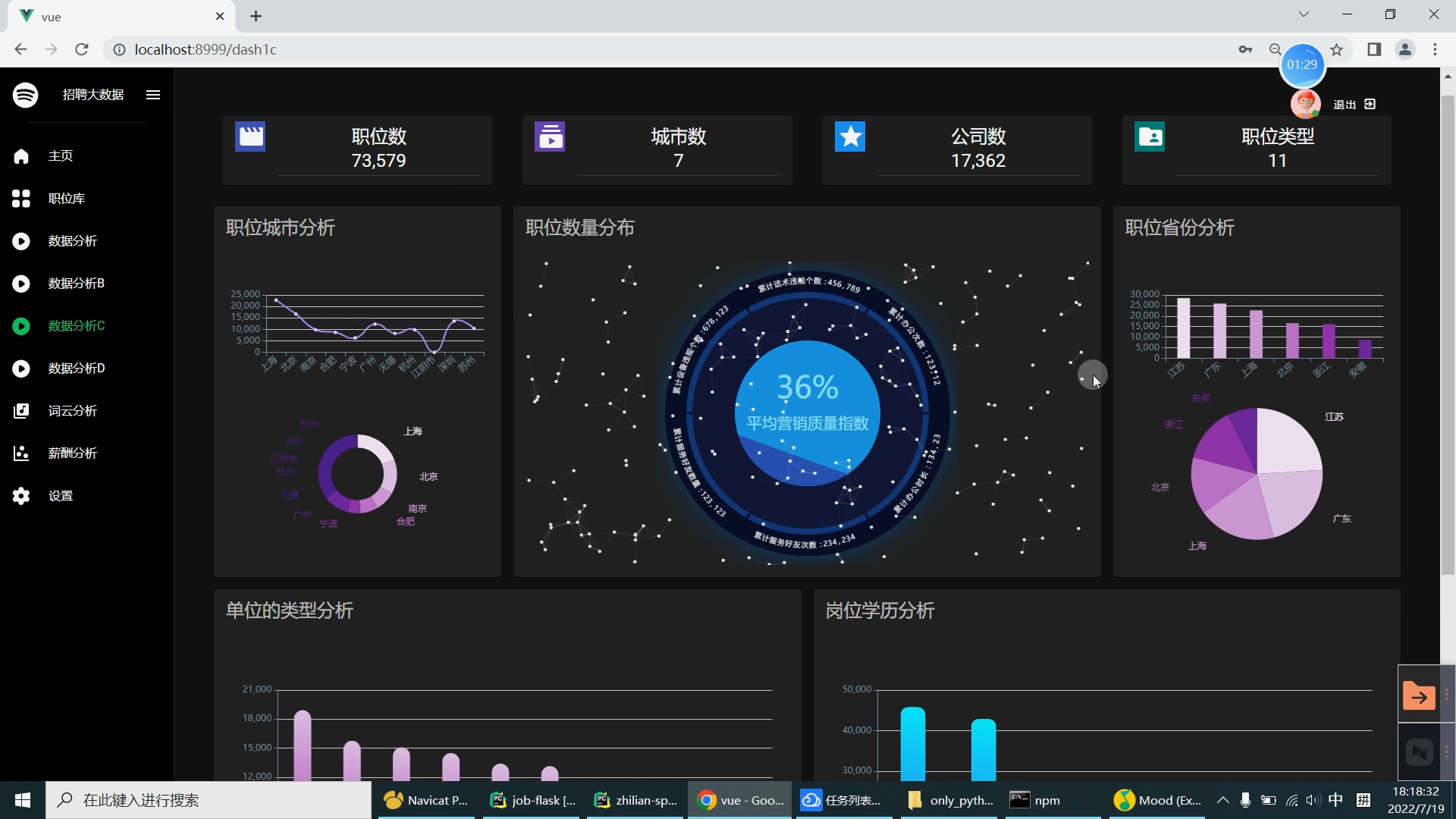
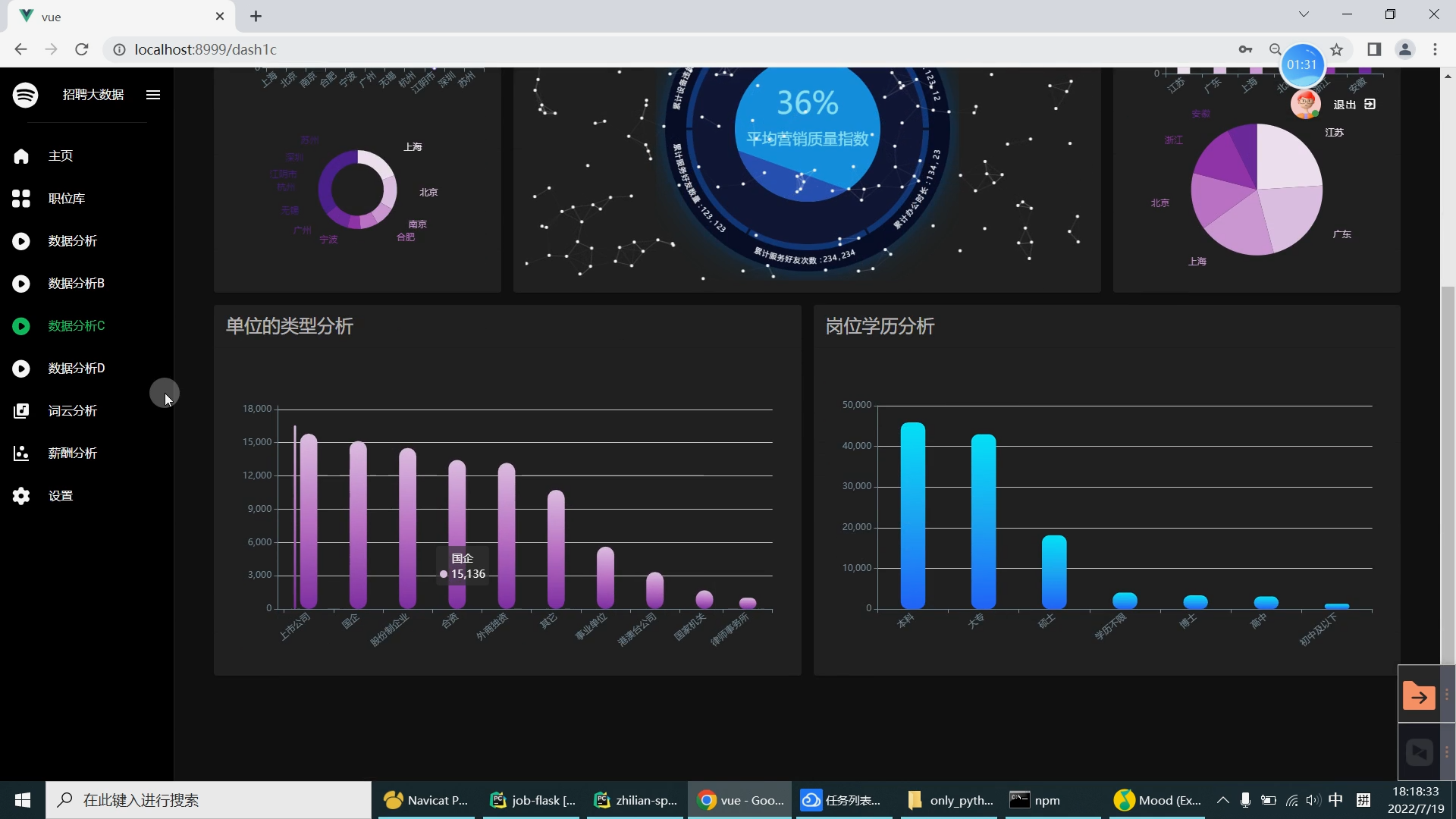
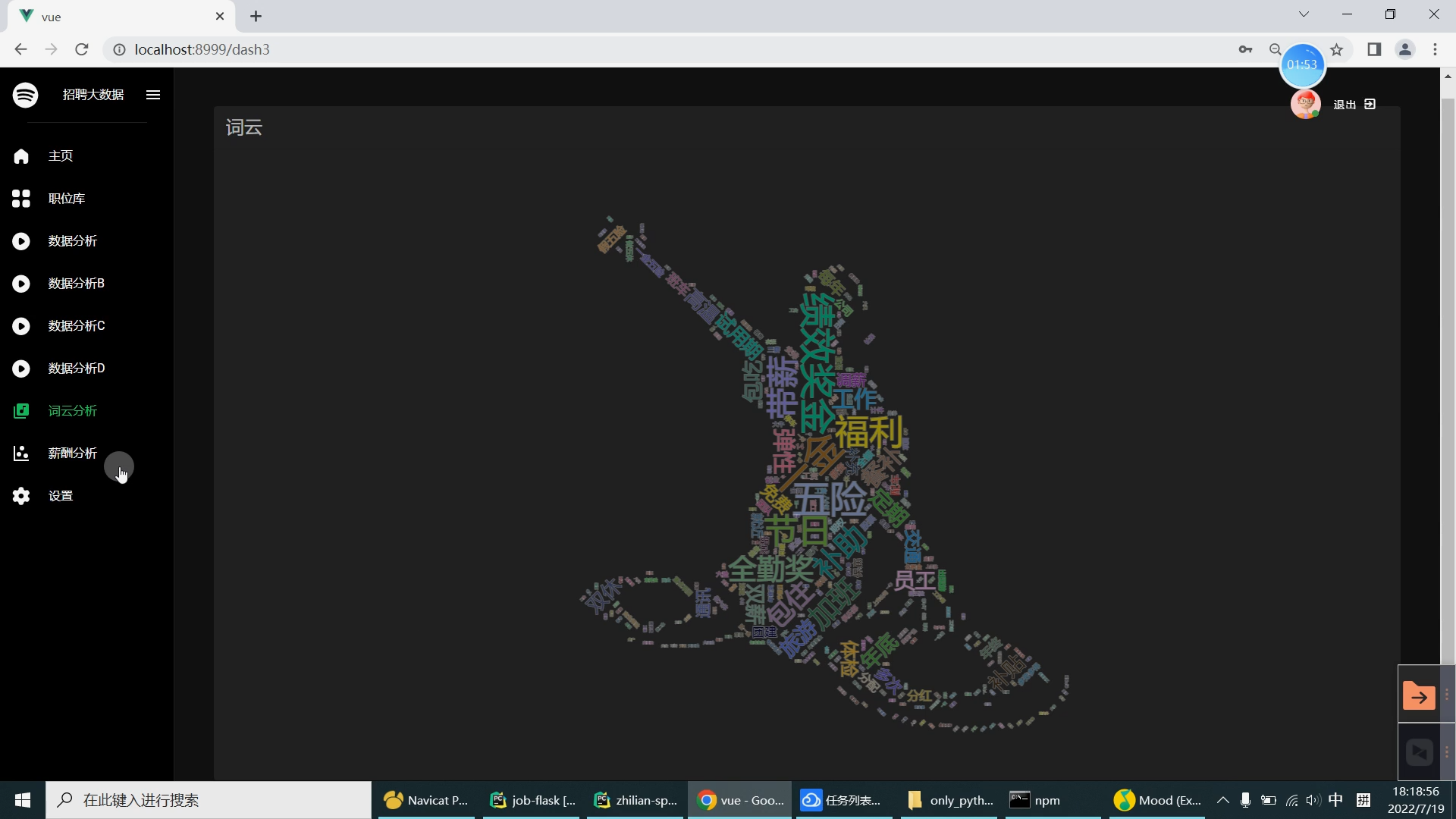
核心算法代码分享如下:
# -*- codeing = utf-8 -*-
# Author: Redcomet
# @Time: 2022/3/8 14:20
# @Author: Administrator
# @File: wash.py
# @Desc: 智联招聘数据清洗处理
import pymysql
def hoop(start, end):
# mysql 数据库连接
db = pymysql.connect(host='127.0.0.1', user='root', password='123456', port=3396, database='flask_job',
charset='utf8')
# 使用cursor()方法获取操作游标
cursor = db.cursor()
sql = " select * from tb_job limit %s, %s" % ( start, end )
cursor.execute(sql)
jobs = cursor.fetchall()
for job in jobs:
washdata(job, db)
db.close()
def transformMoney(s):
if s[-1] == '千':
money0 = 1000
elif s[-1] == '万':
money0 = 10000
else:
money0 = 1
return money0
def washdata(item, db):
s = item[5].split('-')
size = item[12].split('-')
time = item[13].split('-')
if len(s)>1:
salary0 = float(s[0][:-1]) * transformMoney(s[0])
if s[1][-1] == '天': #特殊处理带天的薪酬
yuan=s[1][:-2].replace('元','')
salary1 = float(yuan) * transformMoney(s[1])
else:
print(s[1][:-1])
yuan=s[1][:-1].replace('万','')
yuan=yuan.replace('千','')
yuan=yuan.replace('元','')
yuan=yuan.replace('/','')
salary1 = float(yuan) * transformMoney(s[1])
else:
salary0 = 0
salary1 = 1
if len(size)>1:
cosize0 = float(size[0])
cosize1 = float(size[1][:-1])
else:
cosize0 = 0
cosize1 = 0
if len(time)>1:
worktime0 = float(time[0])
worktime1 = float(time[1][:-1])
else:
worktime0 = 0
worktime1 = 0
cursor = db.cursor()
sql = "INSERT INTO tb_job2(id, number, company_name, position_name, city,salary0,salary1, degree,\
company_logo, url,company_url, education, coattr, cosize0, cosize1, worktime0, worktime1, welfare, publish_time) \
VALUES (%d, '%s', '%s', '%s','%s',%f, %f, '%s', '%s', '%s','%s', \
'%s', '%s', %f, %f, %f, %f, '%s', '%s') " % \
(item[0], item[1], item[2], item[3],item[4], salary0, salary1, item[6], item[7], item[8] \
, item[9], item[10], item[11], cosize0 ,cosize1 , worktime0, worktime1, item[14], item[15])
try:
# print(salary0, salary1)
# print(worktime0, worktime1)
# print(cosize0, cosize1)
cursor.execute(sql)
db.commit()
except Exception as e:
db.rollback() # 发生错误时回滚
print(e)
# print(item)
if __name__ == '__main__':
start = 1
total = 120000
interval = 1000
for i in range(start, total, interval):
# print(i, interval)
hoop(i, interval)
print('处理完成:', i+interval)
原文地址:https://blog.csdn.net/spark2022/article/details/139092769
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!