亮数据----教你轻松获取数据
文章目录
1. 数据采集遇到的瓶颈
1.1 不会造数据?
在项目开发的早期阶段,常常需要我们制造一些数据用于快速设计数据报告样品DEMO,这有利于目标实现、需求收集反馈和项目可行性分析。
这一过程就是项目中常用的原型法,它主要强调创建一个初步的原型模型,引导项目相关干系人积极参与讨论和分析,进而来获取反馈和验证需求,逐步完善需求和最终产品。
如果不使用样例数据或者数据质量太差,在项目开发中采用原型法时可能会导致许多不良效果:
- 需求理解错误:如果原型使用的数据不准确或不代表实际情况,可能会导致对用户需求的理解错误,进而可能导致开发出的产品与用户期望不符。
- 增加时间和资源:使用不合适的数据,可能不能得到项目干系人的及时反馈,反而在后期才发现一系列问题,最终不得已增加时间和人力资源成本。
- 功能缺失:不合适的数据可能导致不能交互和联动,以至于掩盖问题和功能,造成后期频繁互动和变更。
造数据用的最多的就是rand()函数,许多软件都能实现,下面使用 SQL 造数据,模拟订单交易记录,代码和结果如下:
select floor(rand() * 900000000 + 100000000) as `用户编号`
, concat('1', floor(rand() * 7000000000 + 3000000000)) as `手机号`
, from_unixtime(unix_timestamp('2022-01-01') +
floor(rand() * (unix_timestamp('2022-12-31') - unix_timestamp('2022-01-01') + 1))) as `订单时间`
, round(rand() * 10000, 2) as `消费金额`
;
+-----------+-------------+---------------------+---------+
| 用户编号 | 手机号 | 订单时间 | 消费金额 |
+-----------+-------------+---------------------+---------+
| 482402020 | 16417672316 | 2022-03-02 14:43:43 | 3678.89 |
+-----------+-------------+---------------------+---------+
如果想要批量数据,那么可以使用存储过程和循环实现,也可以借助其他工具配合实现。
但通过上面生成的数据,可能缺少相关维度信息,指标生成数字过于平均,得到的趋势趋于平稳,不能体现极大或极小,易掩盖系列问题造成返工。
那么是否考虑获取相同领域内,同类型性质类数据呢?
1.2 不会写爬虫代码?
我们知道网络爬虫是按照一定的逻辑,获取网页内容并提取有效信息的程序或脚本。当我们采集指定的数据内容并结构化存储数据库时,常常需要解决许多问题:
- 安全性问题:在采集数据时,必须遵守相关的法律法规,确保不会侵犯他人的版权或违反网站的使用条款,保护相关隐私信息。
- 数据格式复杂:网站的数据一般都会嵌套的 HTML 结构、XML 或 JSON 等复杂数据格式,如果需要结构化存储在数据库中,那么就要进行适当的解析,解析后还需要进行清洗和预处理才能得到真正所需要的信息。
- 请求频率限制:爬虫代码需要控制请求访问速度,避免被视为恶意访问。
- 动态内容抓取:数据量大,数据需要动态分页抓取,这时可能需要模拟浏览器行为或使用其他专门的工具。
- 网络连接问题:爬取数据过程中,可能会遇到网络不稳定、代理服务器故障或网站服务器繁忙等问题。
- 适应网站的变化:网站的结构和内容可能会经常变化,爬虫程序需要具备一定的适应性,能够应对这些变化并及时调整。
- 网站反爬虫机制:许多网站会采取反爬虫措施,如设置 IP 限制、验证码验证、动态页面等,以防止爬虫程序的过度访问。这可能导致爬虫无法正常获取数据或被封禁 IP 地址。
面对以上一系列问题,爬虫代码可能需要综合运用各种技术手段、经常性维护和调整,那有没有已应付系列问题成熟可用的平台呢?
★
\bigstar
★ 当然有,最近发现一个宝藏产品:亮数据,该平台专业研发攻破各种数据问题,采集各大领域全网数据,提供对应场景的 IP 代理,帮助用户轻松获取所需数据。

2.IP 代理基础知识
前面提到 IP 代理,也许有小伙伴不太熟悉,本节将带大家进一步了解。
2.1 基本概念
IP(Internet Protocol)即互联网协议,主要用于在网络中确定设备的身份和位置,然而许多网站通常会设置 IP 限制或者 IP 封禁等,那要继续稳定进行访问,就要使用到 IP 代理。
IP 代理是一种网络技术,用户可以通过中间服务器来隐藏或调整真实 IP 地址,进一步实现网络通信,让用户可以更好地访问,安全采集公开数据,使得网络爬虫程序更加稳定高效的获取数据。
2.2 作用和分类
作用
- 隐藏真实 IP 地址:保护用户的隐私和安全。
- 突破访问限制:访问被限制的地区或网站。
- 高速稳定:代理服务器通过优化缓存和路由,减少网络延迟,提高访问速度和稳定性。
- 安全采集数据:安全的代理服务器可以模拟不同区域的用户访问,能更加获取更加全面的数据,减少数据丢失问题。
分类
- 按匿名分类:可以分为透明代理(会透露用户真实 IP)、匿名代理(隐藏用户真实 IP,但目标服务器仍可检测到代理的存在)和高匿代理(完全隐藏用户的真实 IP 代理的存在)。
- 按是否固定分类:根据是否固定场所,可分为机房代理 IP和移动代理 IP。
- 按是否变化分类:根据 IP 代理是否变化,分为动态代理 IP和静态代理 IP。
2.3 IP 代理的配置和使用
代理的配置和使用步骤如下:
- 选择合适的 IP 代理服务提供商,并获取代理服务器的相关信息,如 IP 地址、端口号和认证方式(如果需要)。
- 在用户的设备或应用程序中进行代理配置,将网络设置改为使用指定的代理服务器。
- 根据需要设置是否使用 HTTP、SOCKS 等协议,并进行相应的认证(如用户名、密码)。
- 测试代理是否正常工作,确保可以成功访问目标网站或应用程序。
2.4 安全和合规
使用合法合规的 IP 代理服务,避免违反网站的使用条款或相关法律法规。
注意代理服务的安全性,避免选择不可靠的代理,以免遭受中间人攻击或数据泄露。
3. 为何使用亮数据 IP 代理
网络数据采集,商用代理通通一网打尽!!! 点击亮数据-Bright Data
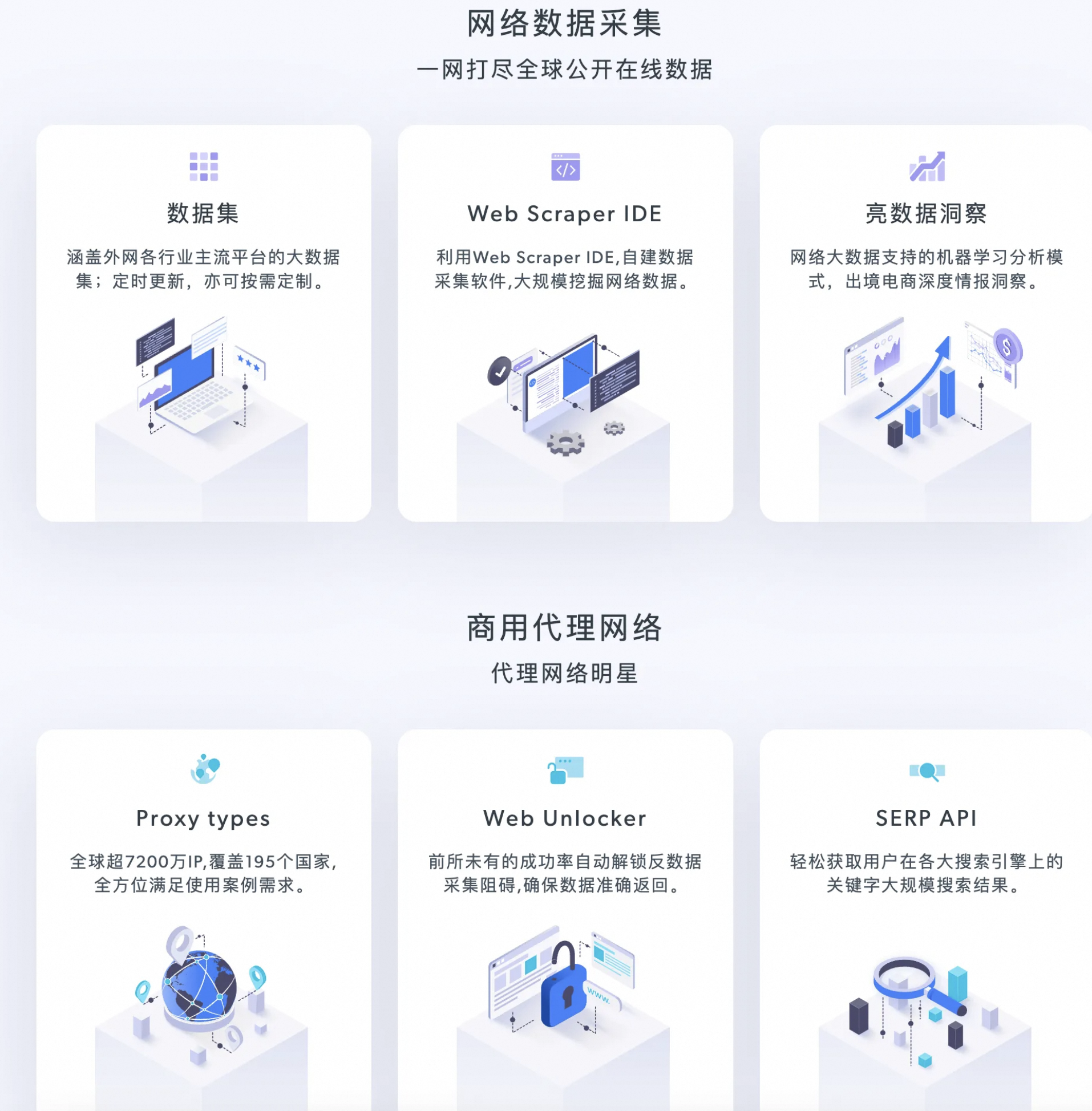
3.1 拥有丰富的代理网络服务
高质量 IP 全球覆盖,超级代理服务器快速分流发送到最近 IP ,实现高速高效,主要的代理服务如下:
- 动态住宅代理:超7200万合法合规 IP,运行稳定,网络在线时间100%。
- 静态住宅代理:遍布全球,高速稳定,可长期甚至终身使用。
- 机房代理:拥有最高质量超700万优质 IP 。
- 移动代理:超70万优质 IP,实现任何地方的用户都可以稳定地获取大且真实的信息。

3.2 简单易操作的采集工具
- 亮数据Web Scraper IDE:强大的集成开发环境,可以完全托管的云环境。
- 亮数据浏览器:市面上首款,解锁最强大的页面屏障,轻易绕过各种检测软件和程序,可以根据所需批量自动化抓取数据。
- 亮网络引擎采集 SERP API:适用于市面上各大搜索引擎,全方位获取复杂的结构化数据,再利用 SERP 数据驱动决策。
- 亮网络解锁器:仿真模拟用户 IP,自动解锁网站并采集数据。

3.3 拥有各平台领域数据集
- 数据集:整合全网各大平台安全公开的最新数据集,并且支持指定参数选择搜索各大行业数据,让你快速定位所需数据。
- 敏锐的洞察情报:基于机器学习,分析商业竞争力,确定市场份额,及时作出调整;精准的商品分类和捆绑搭配,提供商品销售额;实时跟踪产品销售情况,对比同行业间差距,针对性的为你提供优化方案;通过比较同业各大平台产品价格,已建立高效智能的定价系统,拿来即用。
4. 数据获取应用案例
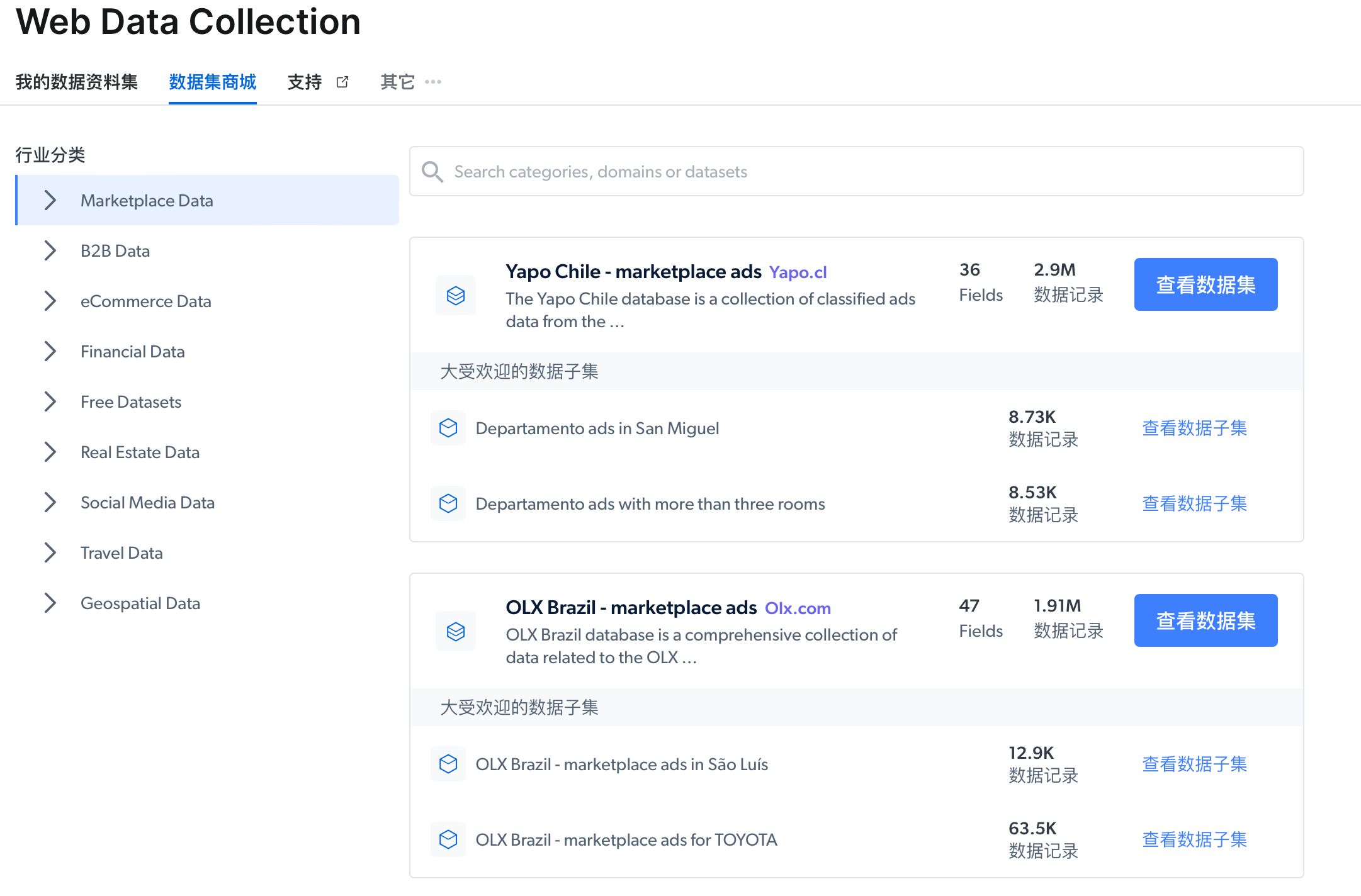
示例1. 直接使用平台数据集商城数据,可以直接搜索或者选择行业分类查找定位到所需数据。
在这里我们直接搜索”product“,选择“Amazon products”,点击查看数据集。
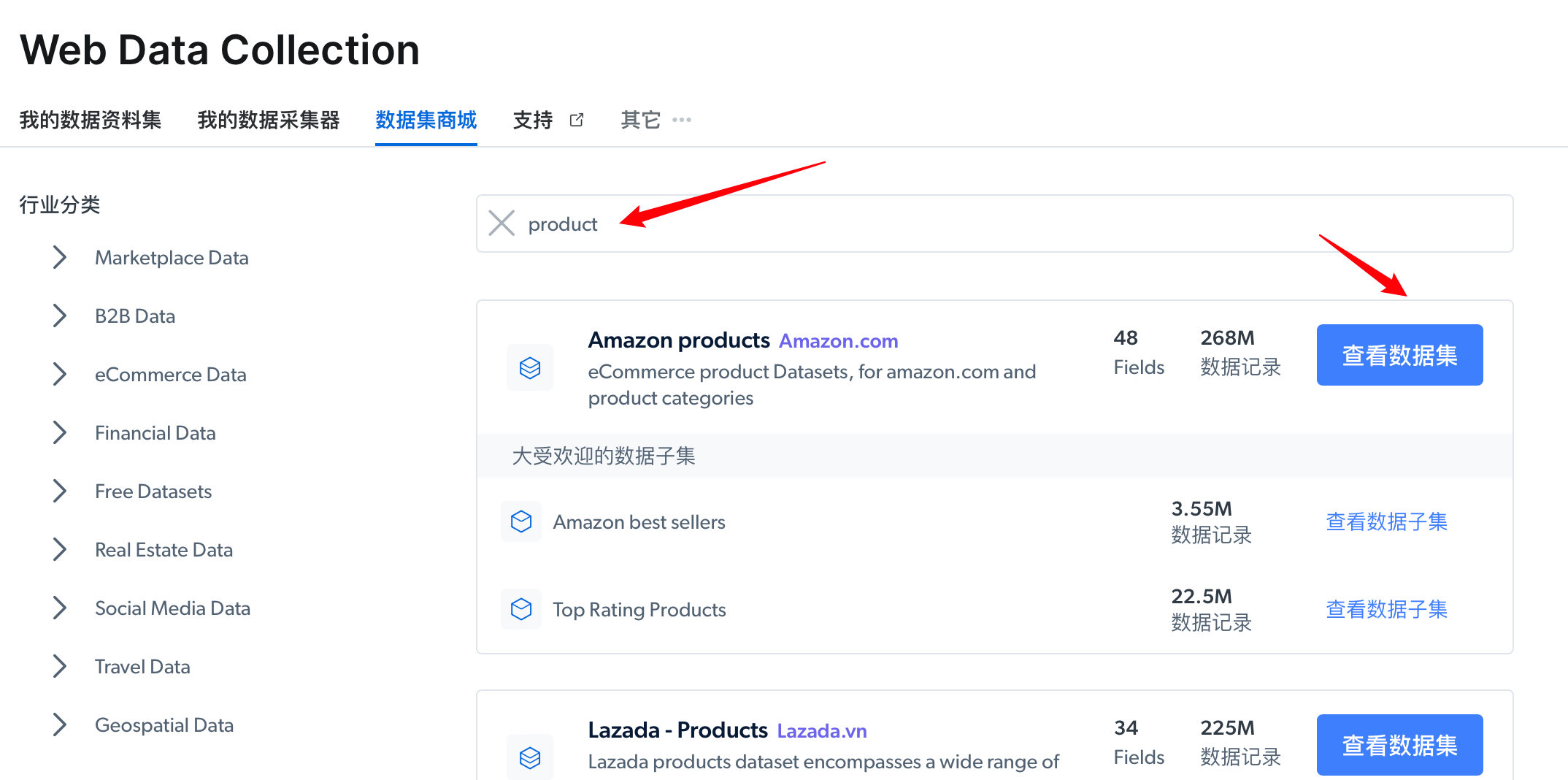
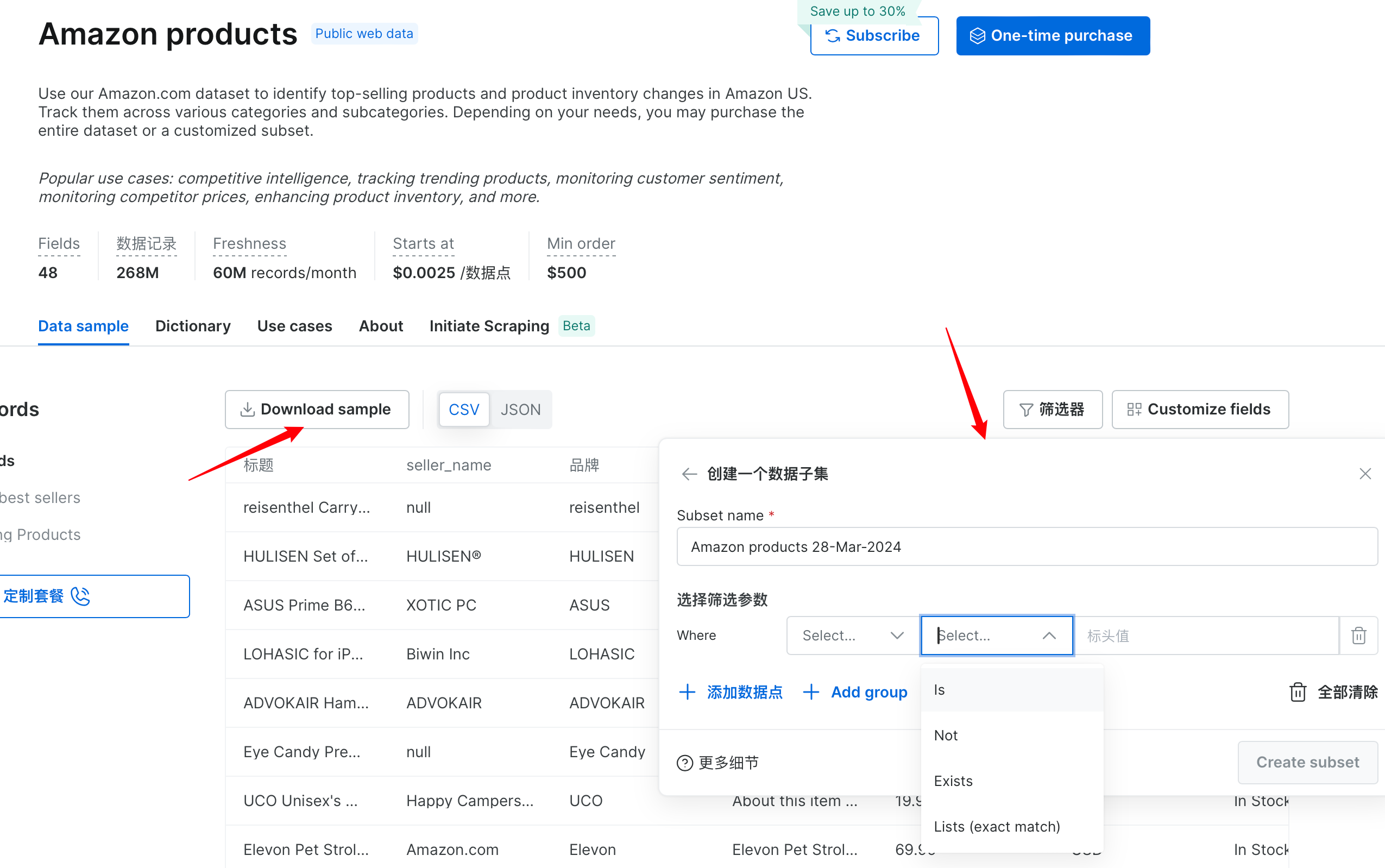
进入到数据集后,这里可以看到数据的描述信息、字段数和数据记录大小,点击下载即可获得 CSV 数据,而且还可以根据筛选器定制自己所需要的数据集,该部分类似于我们地 SQL 查询。
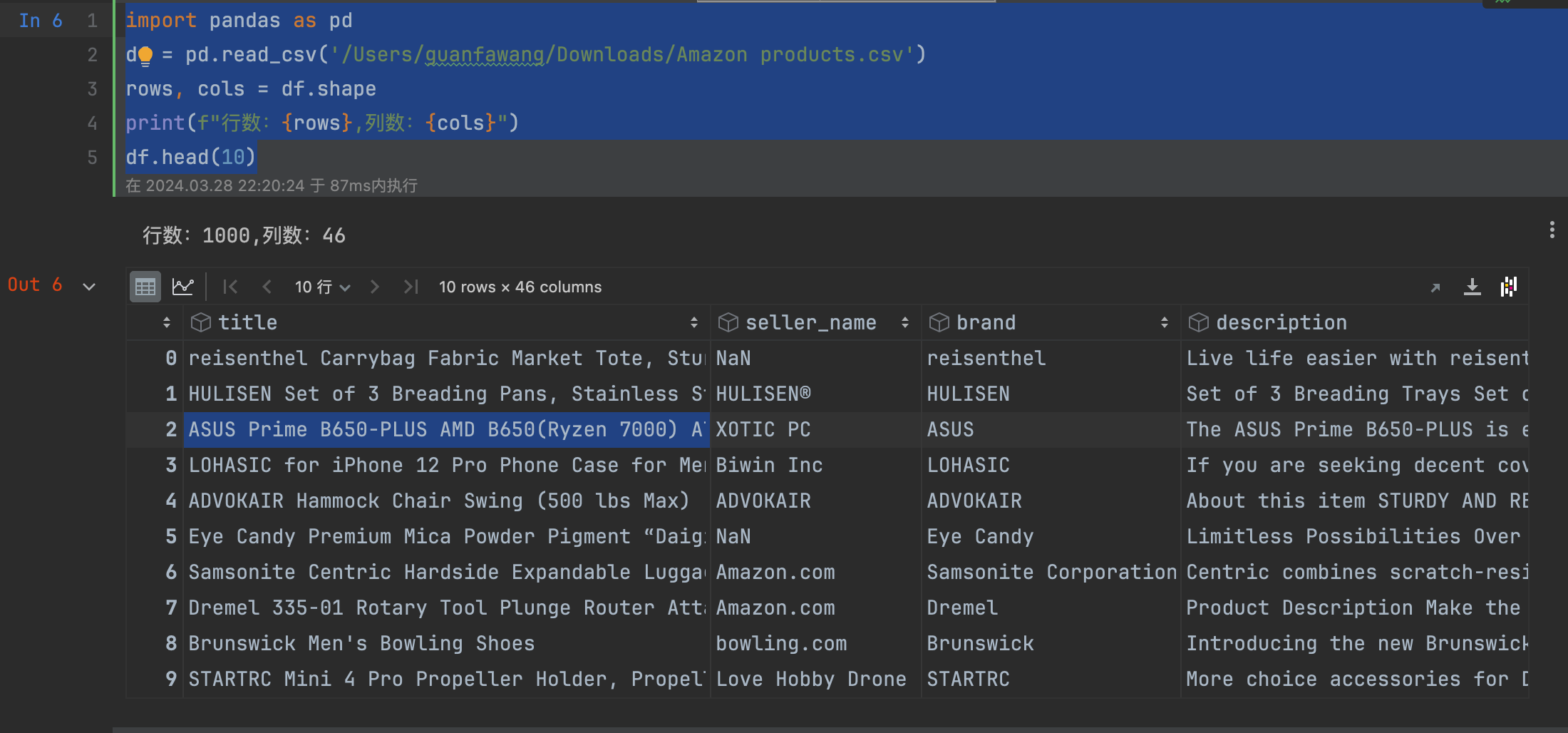
可以使用Python查看获取数据后的基本信息:
import pandas as pd
df = pd.read_csv('/Users/guanfawang/Downloads/Amazon products.csv')
rows, cols = df.shape
print(f"行数:{rows},列数:{cols}")
df.head(10)
示例2:如何使用代理产品获取数据?
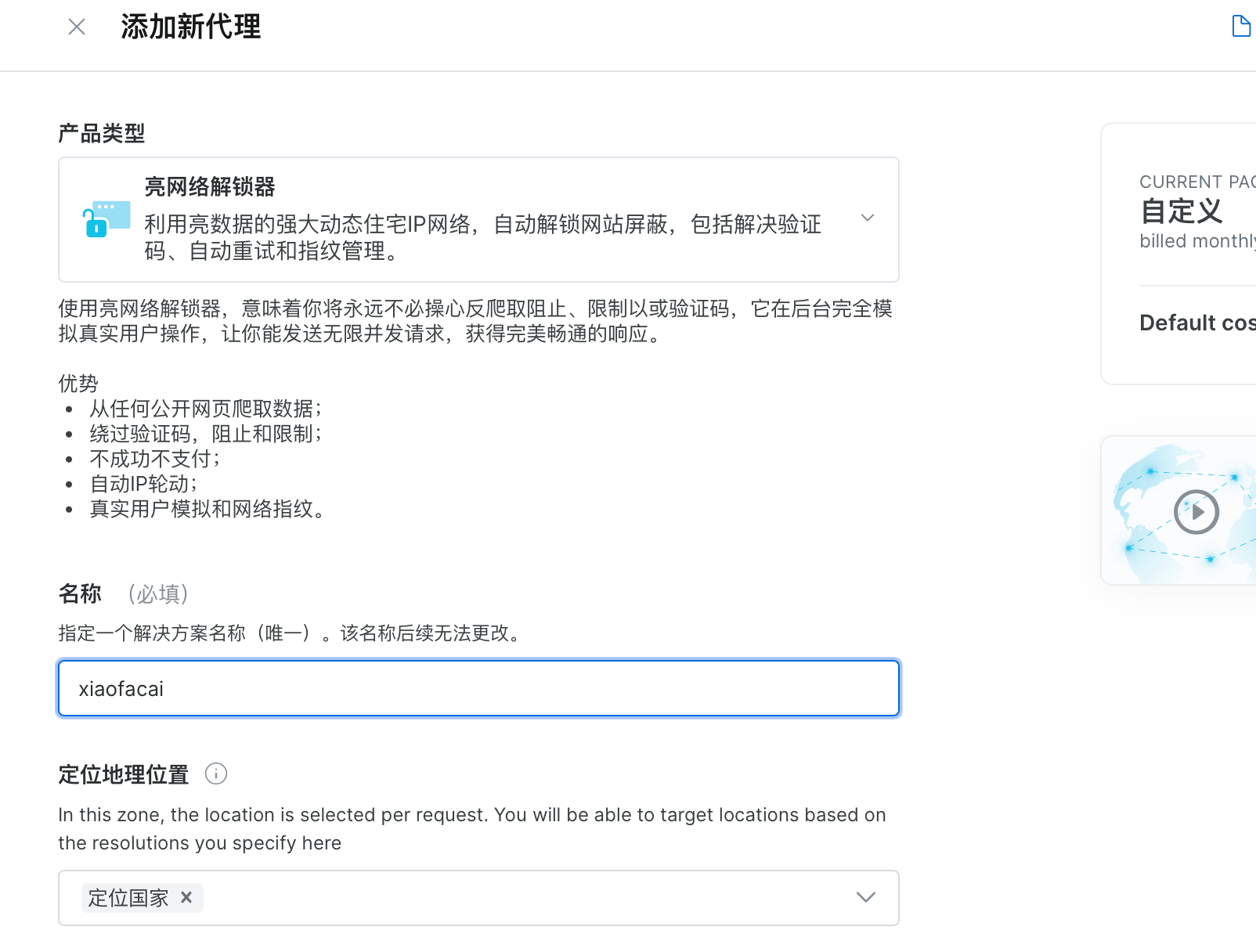
进入到产品代理IP,这里点击亮网络解锁器开始使用,定义一个属于自己的通道名称,点击添加。
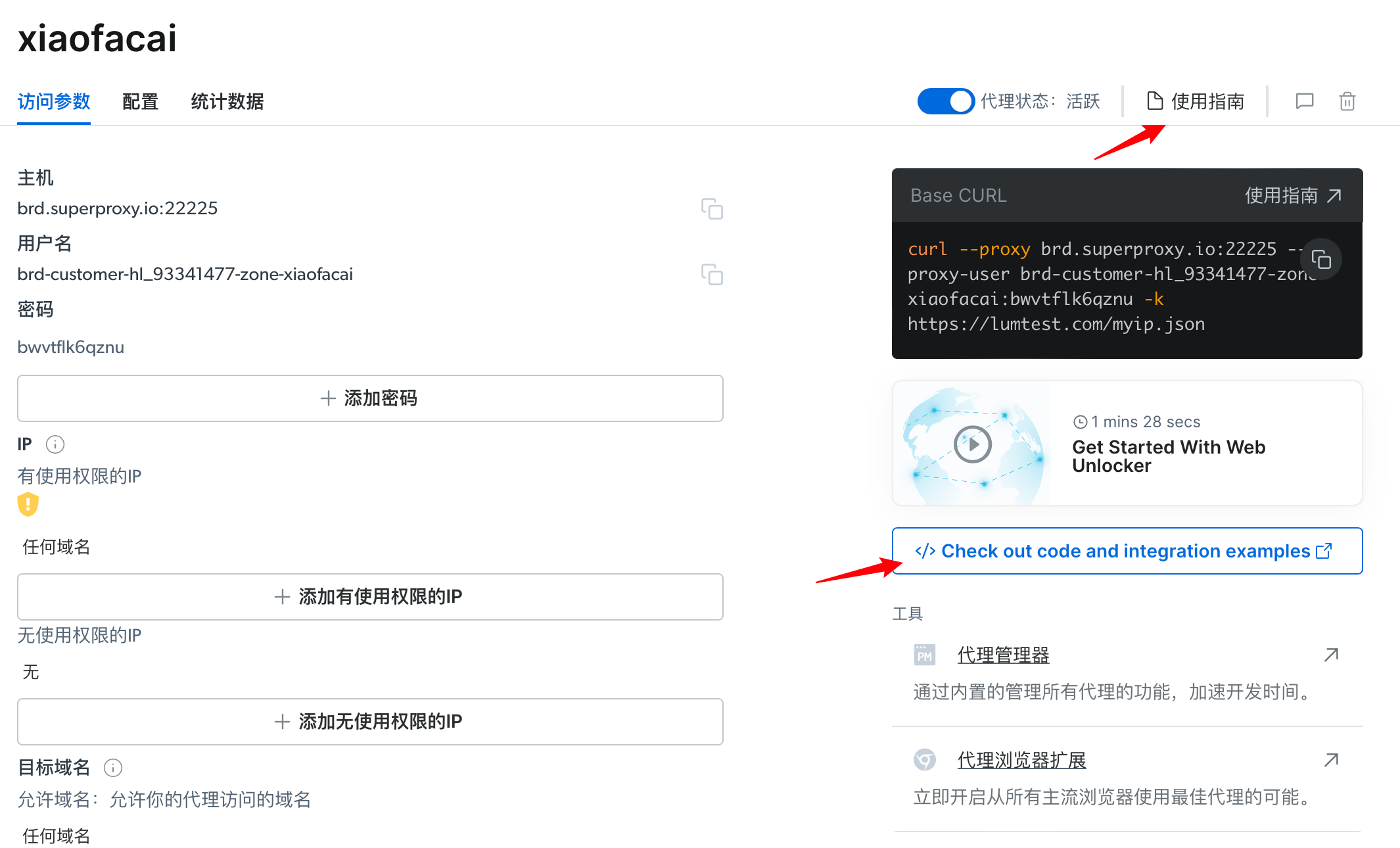
添加后在该页面可以继续添加密码和目标域名等参数配置,也可以点击使用指南,或者点击代理集成示例,查看别人如何配置的。
代理集成示例可以选择类型和自己熟悉的语言,也可以修改目标网站和定位国家,获取自己想要的数据。
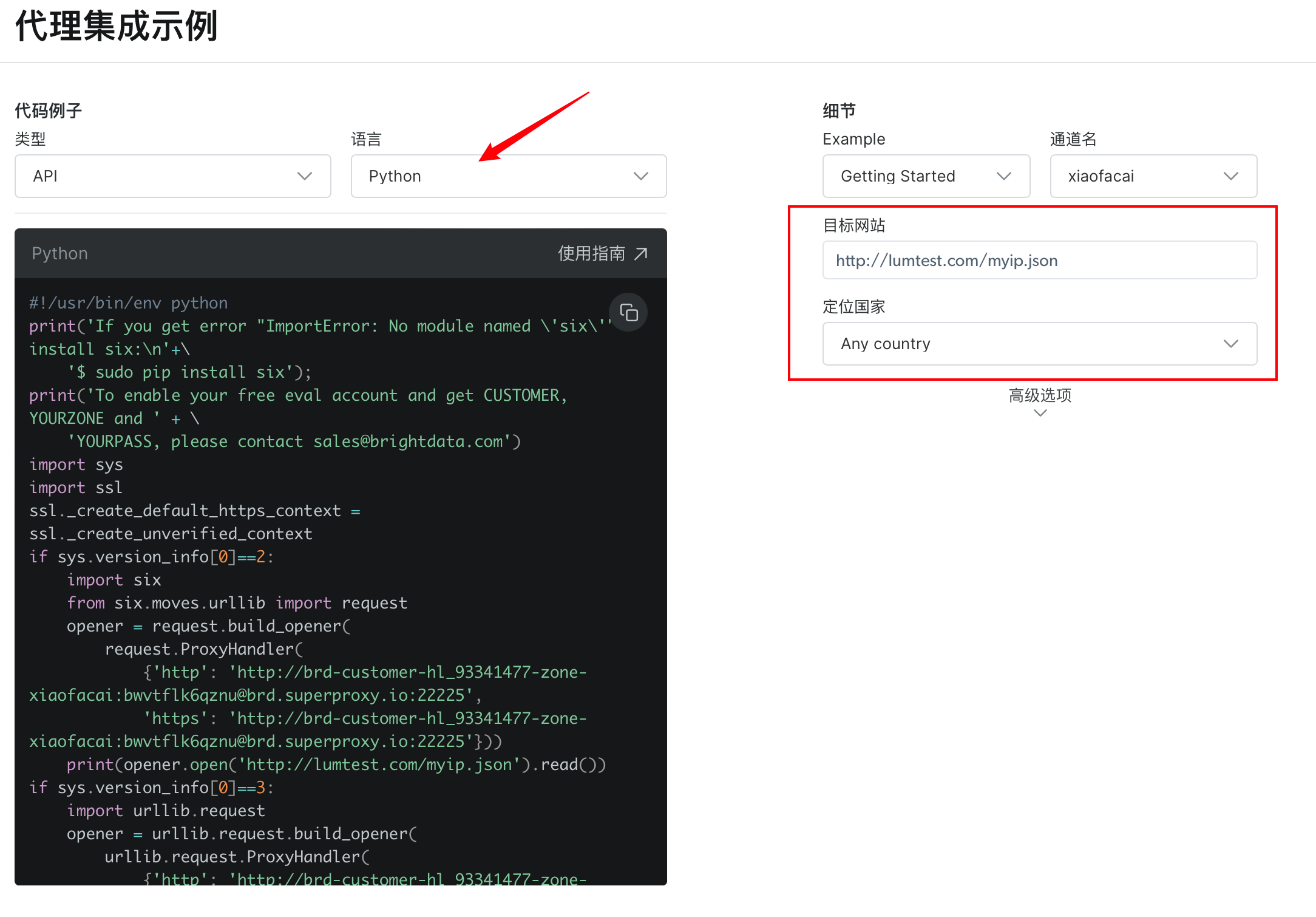
以Python语言为例,在编辑器下启动脚本获取数据的结果如下:
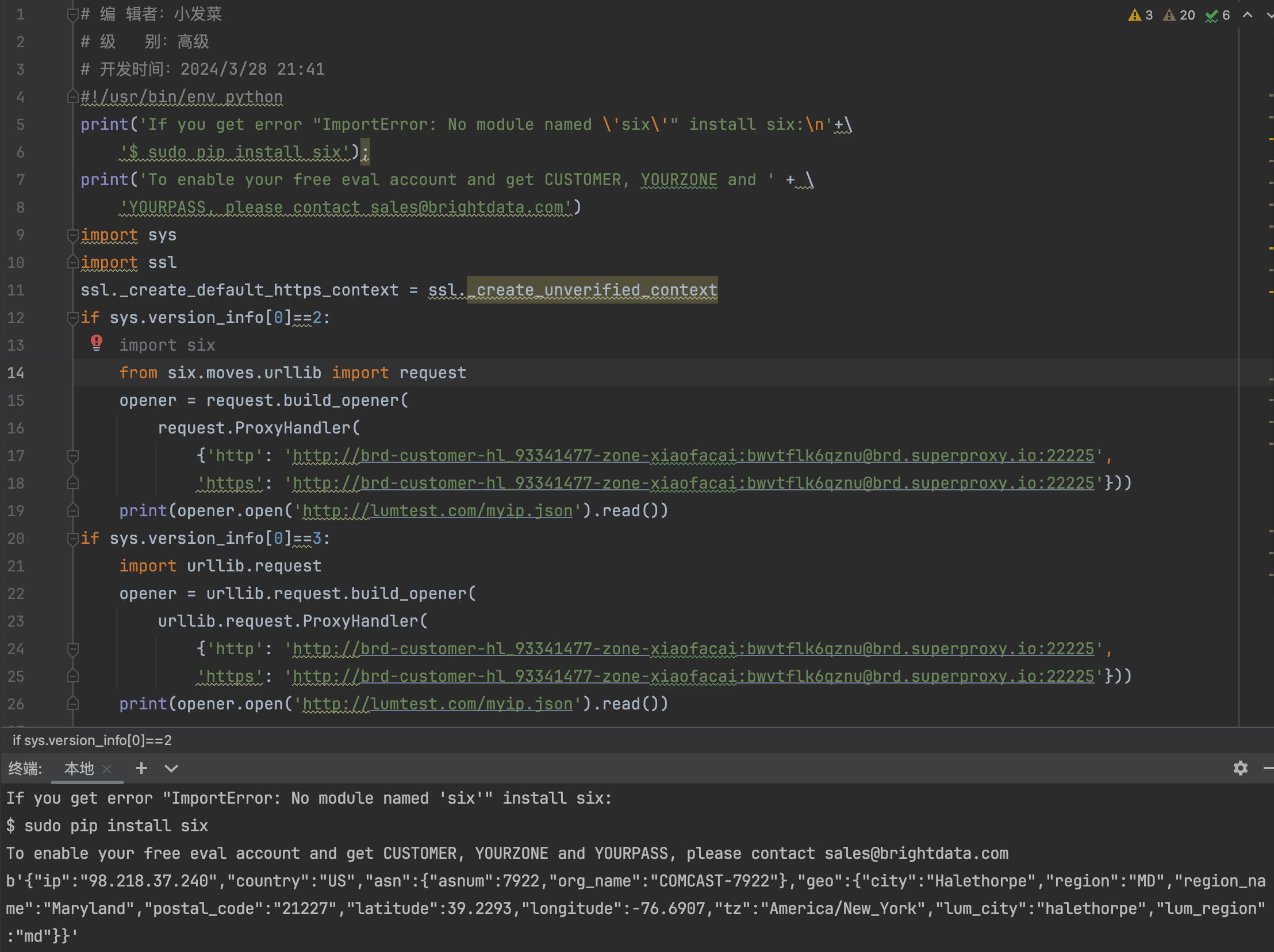
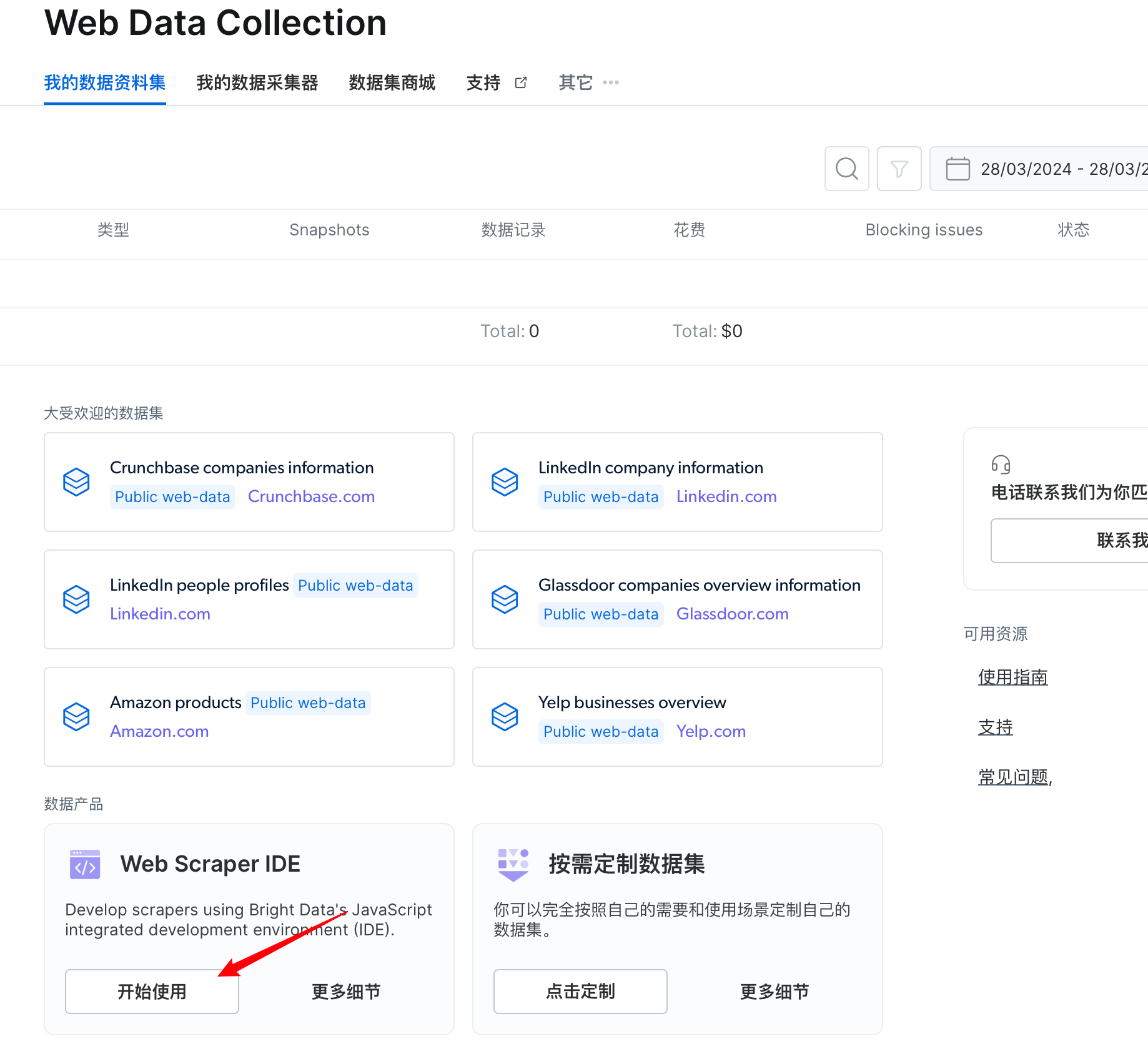
示例3. 通过集成开发环境获取数据?
点击“Web Scraper IDE“开始使用,直接在集成环境操作获取数据。
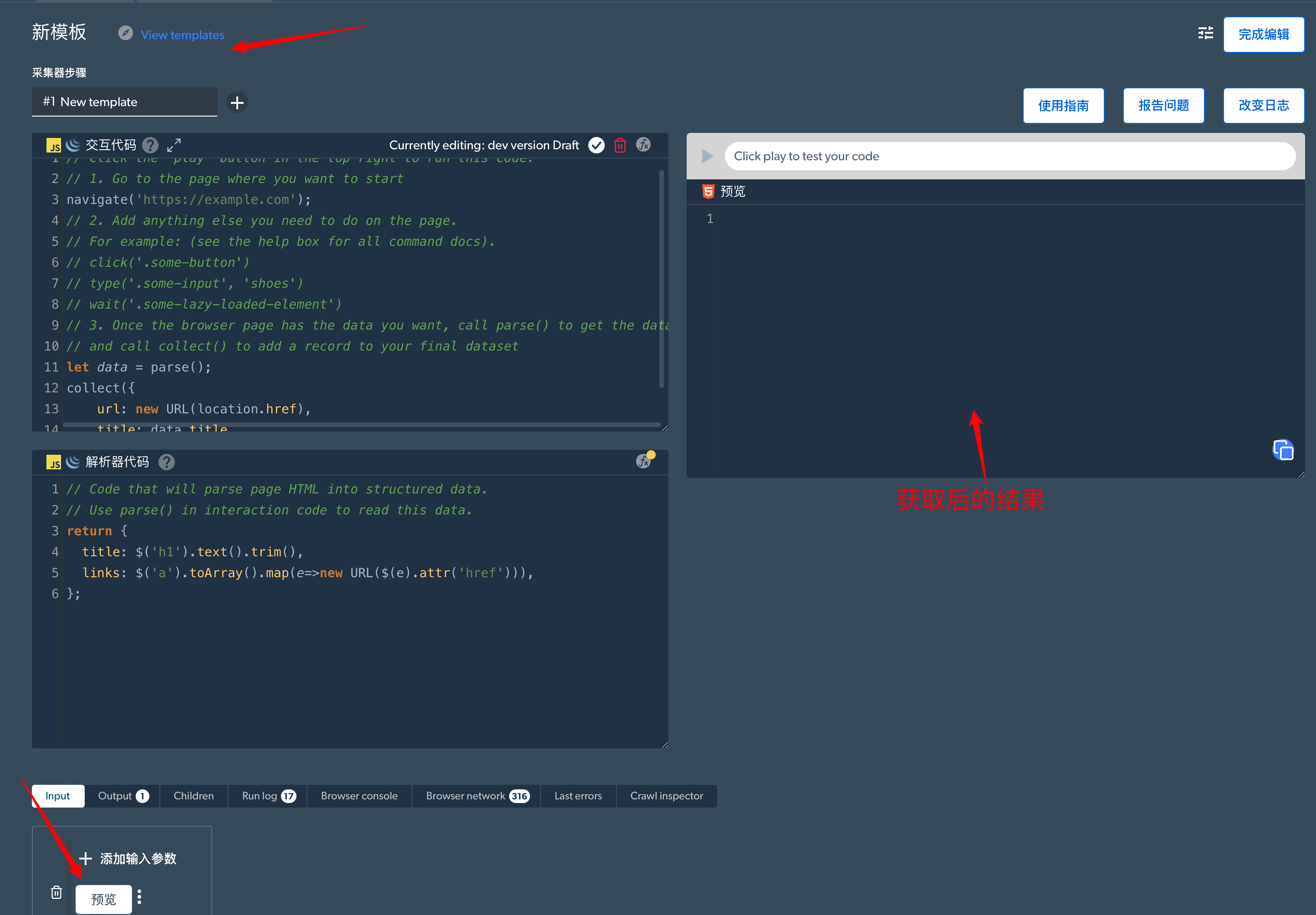
进入集成环境可以发现与我们常用的Pycharm等编辑器其实类似,左上角可以选择示例,左下角可以点击预览执行,相应地会输出结果。右边是获取数据后的结果。
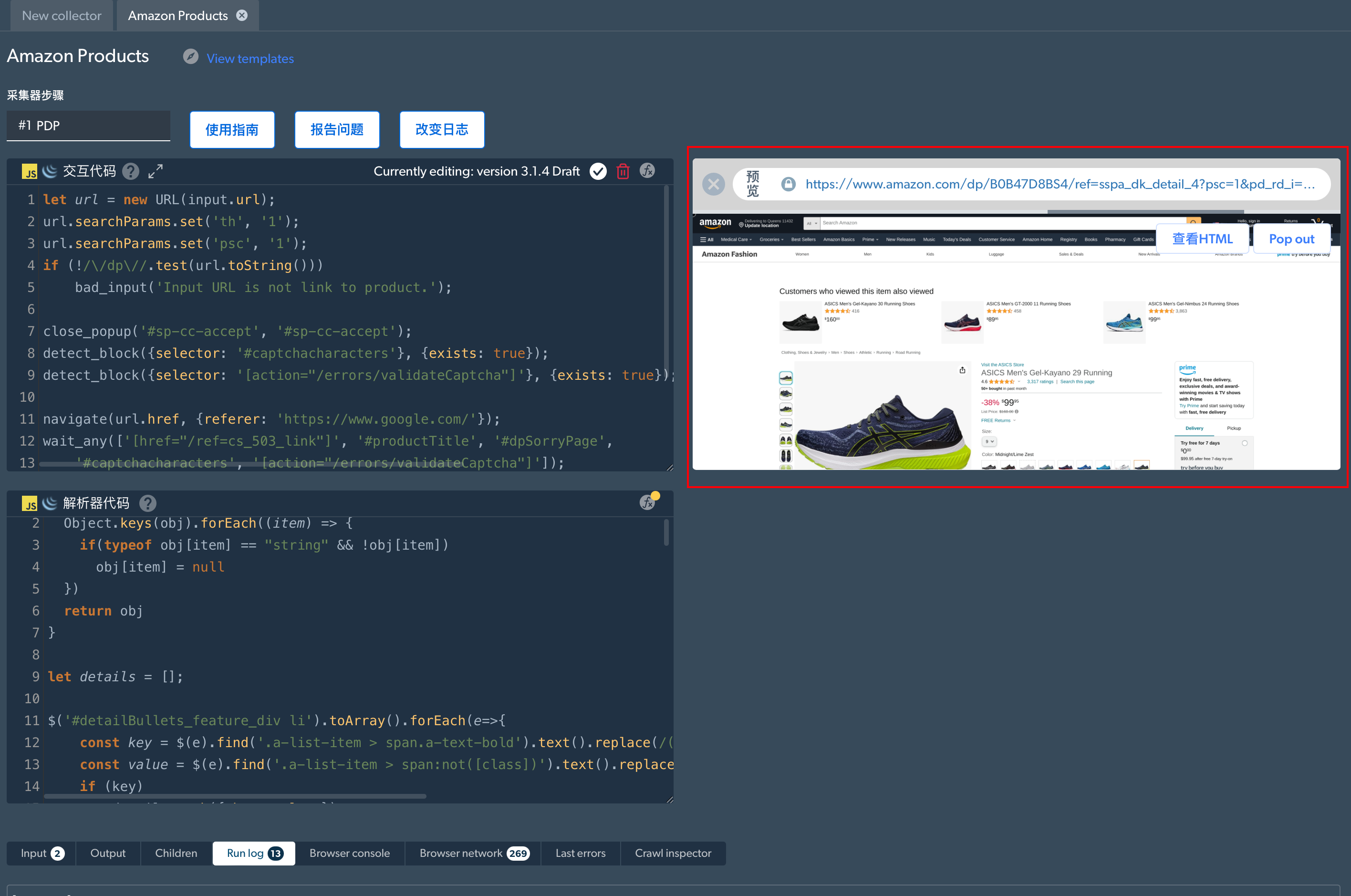
在这里,我们点击“View templates”查看“Amazon Products”示例,预览后,可以看到右边输出的结果,可以切换HTML或者复制网址到其他浏览器查看。
★ \bigstar ★ 上面分别介绍了使用亮数据中的数据集、代理产品和采集攻击获取数据,如果想了解更多详细步骤或者产品功能,可以进一步查看亮数据官网使用指南。
5. 总结
在如今这个信息化时代,数据的价值变得前所未有的重要,如果你还在纠结如何造数据,不会写爬虫代码问题,我建议赶快将亮数据用起来,另外也不要一直在维护自己的低代码,将更多的时间用在思考决策分析上显得更为重要。
目前,亮数据提供了许多折扣,成功注册账户并登录,就能领取福利啦,感兴趣的小伙伴试试吧!
亮数据为粉丝提供了10美金的抵用券,成功注册账户,并登录后在用户界面里输入折扣代码即可享受抵扣!
折扣代码:shizhenzhen
访问页面:亮数据
如有问题,可以关注“Bright_Data”亮数据官微,联系后台客服。
原文地址:https://blog.csdn.net/u010634066/article/details/137142360
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!