client-go中ListAndWatch机制,informer源码详解
文章首发地址: 学一下 (suxueit.com)![]() https://suxueit.com/article_detail/s9UMb44BWZdDRfKqFv22
https://suxueit.com/article_detail/s9UMb44BWZdDRfKqFv22
先上一张,不知道是那个大佬画的图
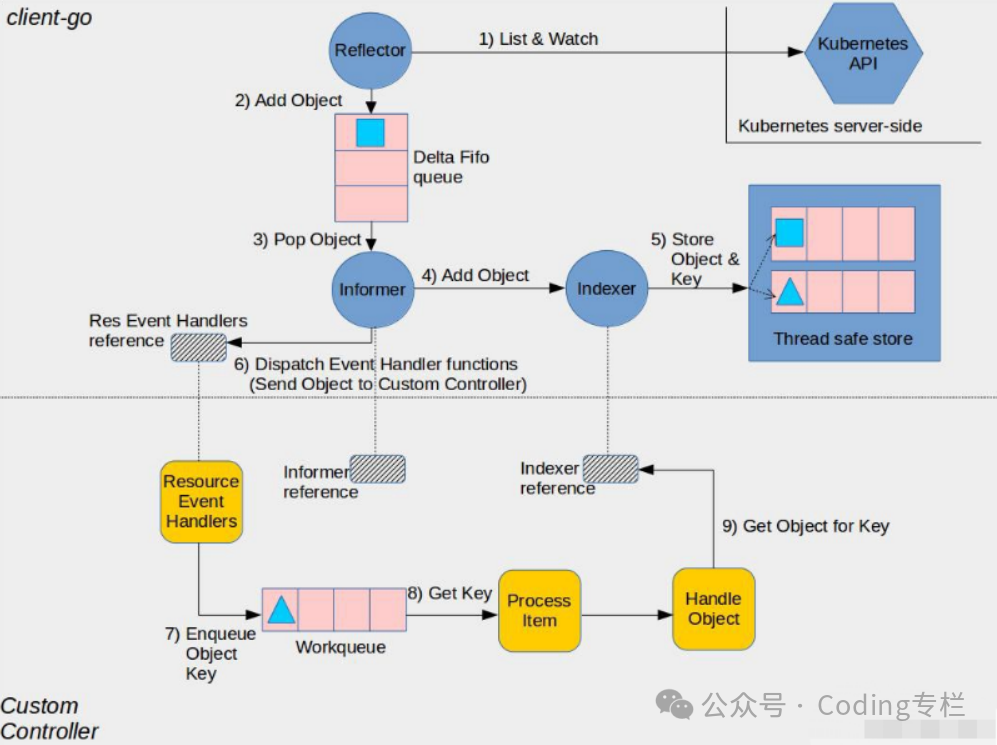
简单描述一下流程
client-go封装部分
以pod为例
-
、先List所有的Pod资源,然后通过已经获取的pod资源的最大版本去发起watch请求,watch持续接收api-server的事件推送,
-
将所有的pod写入到queue
-
从队列中取出pod
-
4和5将 取出的pod缓存到本地
-
调用用户自定义的资源处理函数【AddEventHandler】
用户自定义部分
-
将事件写入,自定义的工作队列
-
遍历队列,取出资源key
-
用key从缓存取出对应资源,进行逻辑处理
阅读完成后续部分,你会发现上面的流程是有一点问题的
list后会立刻写入队列,然后再发起watch,并将监控的事件入队
informer入口分析
通常我们写controller都会初始化一个informer,然后lister对应资源,或者给资源添加的hook点
// 开始运行informer
kubeInformerFactory.Start(stopCh)
//
func (f *sharedInformerFactory) Start(stopCh <-chan struct{}) {
f.lock.Lock()
defer f.lock.Unlock()
// 这里为什么是一个 数组?
for informerType, informer := range f.informers {
if !f.startedInformers[informerType] {
// informer入口
go informer.Run(stopCh)
f.startedInformers[informerType] = true
}
}
}面试问题
一个informer可以监听多个资源吗?
不能: 我们在使用时是看似是通过定义的一个informer客户端去监听多个资源【该informer不是实际意义上的informer,而是一个工厂函数】,实际上,该informer每监听一个资源会生成一个informer并存入工厂informer数组中,启动时再分别调用【goruntine】
因为 一个informers是可以listAndWatch多种资源的 当你调用 kubeInformerFactory.Core().V1().Pods().Lister() kubeInformerFactory.Core().V1().ConfigMaps().Lister() 会分别给 pods和configmap的资源类型生成一个informer
func (f *sharedInformerFactory) InformerFor(obj runtime.Object, newFunc internalinterfaces.NewInformerFunc) cache.SharedIndexInformer {
f.lock.Lock()
defer f.lock.Unlock()
informerType := reflect.TypeOf(obj)
informer, exists := f.informers[informerType]
if exists {
return informer
}
resyncPeriod, exists := f.customResync[informerType]
if !exists {
resyncPeriod = f.defaultResync
}
informer = newFunc(f.client, resyncPeriod)
// 通过类型将 资源的informer进行存储
f.informers[informerType] = informer
return informer
}sharedIndexInformer分析
主要结构
type sharedIndexInformer struct {
indexer Indexer
controller Controller
// 封装多个事件消费者的处理逻辑,client端通过AddEventHandler接口加入到事件消费Listener列表中
processor *sharedProcessor
cacheMutationDetector MutationDetector
listerWatcher ListerWatcher
objectType runtime.Object
started, stopped bool
....
}-
indexer: 本地缓存,底层的实现是threadSafeMap
-
controller: 内部调用Reflector进行ListAndWatch, 然后将事件发送给自定义事件消费者【往上获取apiserver事件,往下发送事件给定义的消费者】
-
processor: 封装多个事件消费者的处理逻辑,client端通过AddEventHandler接口加入到事件消费Listener列表中
kubeLabelInformer.Core().V1().Pods().Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{ AddFunc: controller.enqueuePodFn, UpdateFunc: func(old, new interface{}) { newPod := new.(*covev1.Pod) oldPod := old.(*covev1.Pod) if newPod.ResourceVersion == oldPod.ResourceVersion { return } controller.enqueuePodFn(new) }, DeleteFunc: controller.enqueuePodFn, }) // AddEventHandler 主要内容 // handler 就是注册的函数 listener := newProcessListener(handler, resyncPeriod, determineResyncPeriod(resyncPeriod, s.resyncCheckPeriod), s.clock.Now(), initialBufferSize) // 不能重复加入,所有判断是否已经开始了 if !s.started { s.processor.addListener(listener) return } -
listerWatcher:实现从apiserver进行ListAndWatch的对象,发起watch请求,将server推送的事件传入本地channel,等待消费
-
objectType: 该informer监听的资源类型,例如 Pods
informer.run都干了什么
func (s *sharedIndexInformer) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
// 定义了 DeltaFIFO 队列
fifo := NewDeltaFIFOWithOptions(DeltaFIFOOptions{
KnownObjects: s.indexer,
EmitDeltaTypeReplaced: true,
})
cfg := &Config{
Queue: fifo,
// listand watch 的接入口
ListerWatcher: s.listerWatcher,
ObjectType: s.objectType,
FullResyncPeriod: s.resyncCheckPeriod,
RetryOnError: false,
ShouldResync: s.processor.shouldResync,
// Process 是将事件发送给本地注册的事件处理函数的入口
Process: s.HandleDeltas,
WatchErrorHandler: s.watchErrorHandler,
}
func() {
// 这里为什么要加锁呢?
// 猜测: 可能是防止有人不规范使用 informer,在多个goruntine中启动Start,导致多次初始化
s.startedLock.Lock()
defer s.startedLock.Unlock()
s.controller = New(cfg)
s.controller.(*controller).clock = s.clock
s.started = true
}()
// Separate stop channel because Processor should be stopped strictly after controller
processorStopCh := make(chan struct{})
var wg wait.Group
defer wg.Wait() // Wait for Processor to stop
defer close(processorStopCh) // Tell Processor to stop
// 这里如果使用的是 kubebuild和代码生成,默认使用的是 defaultCacheMutationDetector
wg.StartWithChannel(processorStopCh, s.cacheMutationDetector.Run)
// 运行 sharedProcessor
wg.StartWithChannel(processorStopCh, s.processor.run)
defer func() {
s.startedLock.Lock()
defer s.startedLock.Unlock()
s.stopped = true // Don't want any new listeners
}()
s.controller.Run(stopCh)
}这里主要讲解一下
wg.StartWithChannel(processorStopCh, s.processor.run)
记得我们上面分析了,processor: 封装多个事件消费者的处理逻辑,client端通过AddEventHandler接口加入到事件消费Listener列表中,这里就开始运行Listeners
运行两个函数:
for _, listener := range p.listeners {
// 内部会定时运行 1 秒运行一次去获取
p.wg.Start(listener.run)
p.wg.Start(listener.pop)
}-
listener.run 从channel【nextCh】中读取数据,然后去触发注册的函数
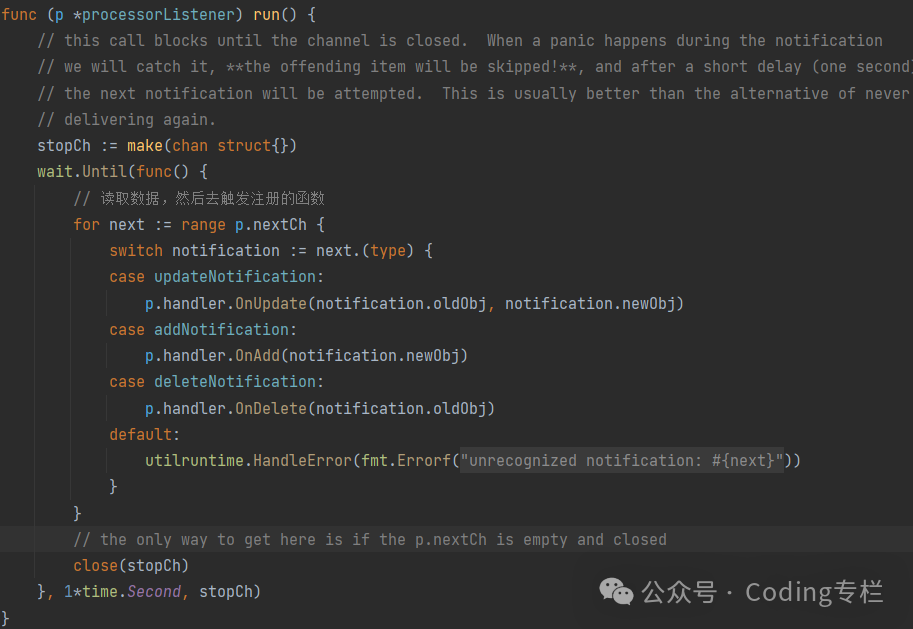
-
将数据从channel【addch】发送到 nextCh 【后面还会有将事件发送到channel【addCh】的操作】
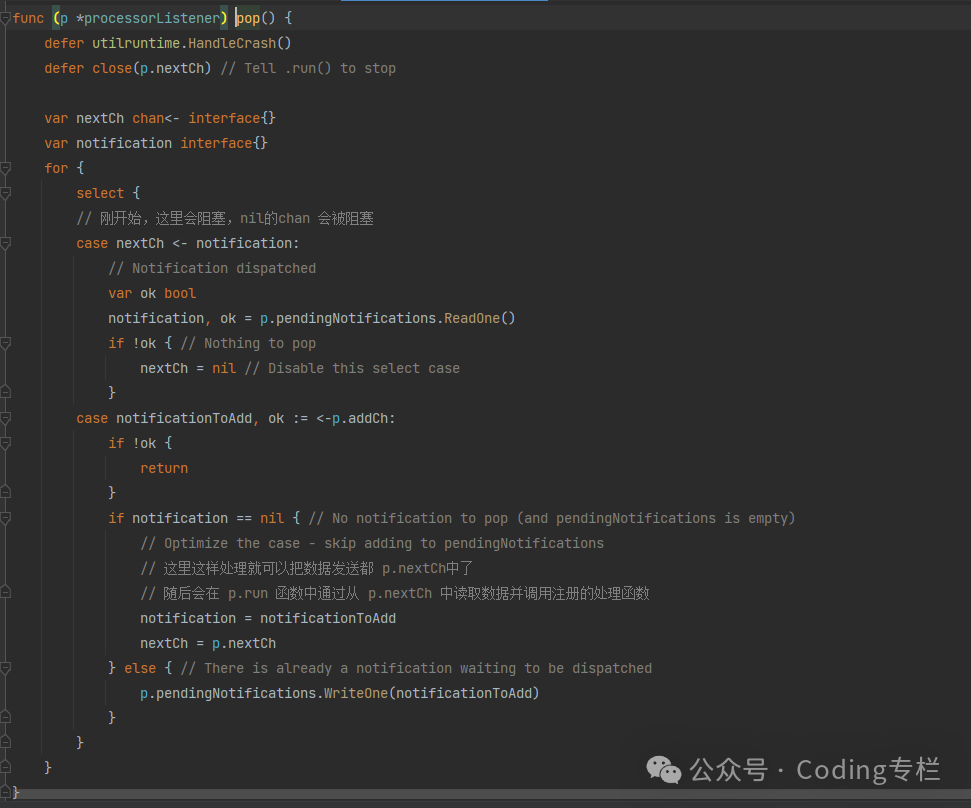
controller分析
func (c *controller) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
r := NewReflector(
c.config.ListerWatcher,
c.config.ObjectType,
c.config.Queue,
c.config.FullResyncPeriod,
)
....
// 运行 Reflector ,进行listAndWatch
// 先进行list,将list的数据存入 队列,并存入队列自带的缓存item【map结构】
// 然后watch
// 对服务端推送的事件进行解码后,会将事件存入 queue【包括queue和item】
// 详细见: 后面的reflector分析
wg.StartWithChannel(stopCh, r.Run)
// 循环执行processLoop
// 内部调用 //err := process(item) process就是 HandleDeltas
// 执行 HandleDeltas
// HandleDeltas这里做两件事
// 1,将数据存到 本地缓存,也就是 ThreadSafeStore【实际开发中就可以通过: lister直接获取】
// 2、只是将事件通过distribute 函数发送到了一个channel【Addch】
wait.Until(c.processLoop, time.Second, stopCh)
wg.Wait()
}processLoop——》c.config.Queue.Pop——》HandleDeltas
Pop函数
id := f.queue[0]
f.queue = f.queue[1:]
if f.initialPopulationCount > 0 {
f.initialPopulationCount--
}
// 获取对象
item, ok := f.items[id]
if !ok {
// This should never happen
klog.Errorf("Inconceivable! %q was in f.queue but not f.items; ignoring.", id)
continue
}
// 删除items中的缓存
delete(f.items, id)
// 调用process,前面的 sharedIndexInformer.HandleDeltas,
// 将事件发送到本地注册的处理函数
err := process(item)
// 如果处理失败 从新加入队列
if e, ok := err.(ErrRequeue); ok {
f.addIfNotPresent(id, item)
err = e.Err
}HandleDeltas函数
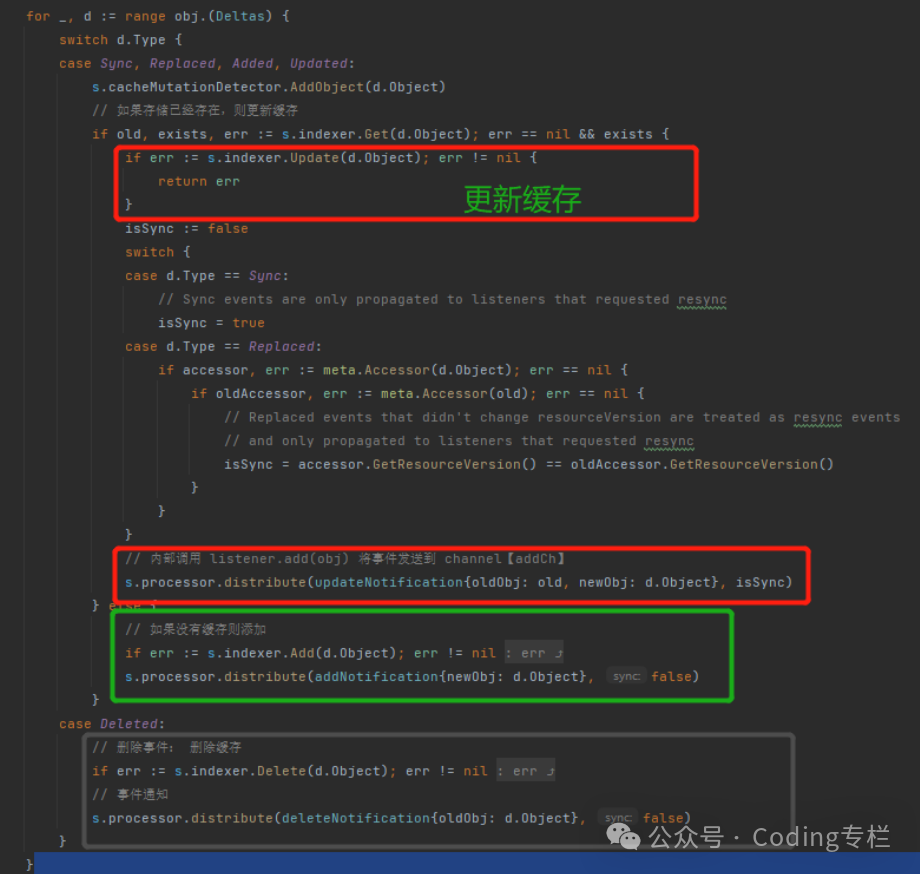
面试题
什么情况下资源对象会在DeltaFIFO存在,但是缓存中不存在【ThreadSafeStore】
答: 写入队列和写入缓存是有先后顺序的,事件到达后会先写入队列,再通过队列的Pop方法进行处理,写入缓存,
扩展: 但是在实际使用中并不影响,因为自定的代码中的队列是在写入缓存后才会有事件通知到我们注册的handler,这时才会添加事件进入我们定义的队列,并开始运行代码更新资源
因为:HandleDeltas函数和 Watch写入队列是异步的,而且肯定是等Watch写入队列后,才会调度HandleDeltas进行缓存写入所有这个中间会有延迟
会不会出现缓存中有,而队列中没有的情况?
答: 是的,确实会有这种情况
1、队列中的事件处理后就会被清理,所有总是会出现这种情况的
Reflector分析
reflector做三件事
-
启动的时候向apiserver发起List请求,获取所有监听的资源,放入 DeltaFIFO
-
进行resync,定期将item中的资源,重新同步到queue中
-
watch资源,通过rest接口发起watch请求,并等待apiserver推送的数据,
type DeltaFIFO struct {
// 缓存资源对象
items map[string]Deltas
// 采用slice作为队列
queue []string
// 基于下面两个参数可以判断资源是否同步完成
// 只要添加数据就会设置为 true
populated bool
// 第一次镜像replace时会设置 为资源数量【List阶段同步数据到队列调用的是 DeltaFIFO的replace】
// 调用Pop时会initialPopulationCount--,Pod时会调用HandleDeltas,将数据同步到自定义的队列中,第一批插入的数据都Pop完成后,initialPopulationCount==0.说明同步完成
initialPopulationCount int
}func (r *Reflector) Run(stopCh <-chan struct{}) {
wait.BackoffUntil(func() {
// 开始进行ListAndWatch
if err := r.ListAndWatch(stopCh); err != nil {
r.watchErrorHandler(r, err)
}
}, r.backoffManager, true, stopCh)
}List阶段
这里没啥可说的,就是请求数据写入队列
// 发起List,这里采用了分页获取【如果设置了chunk】
list, paginatedResult, err = pager.List(context.Background(), options)
// 将数据写入队列
if err := r.syncWith(items, resourceVersion); err != nil {
return fmt.Errorf("unable to sync list result: %v", err)
}
// 设置资源版本,防止后续网络断开需要重试的情况,可以从已经获取的版本开始获取
r.setLastSyncResourceVersion(resourceVersion)Watch过程
-
指定资源版本通过rest请求apiserver进行Watch
-
apiserver推送的数据会被Watch对象写入channel【result】
-
从Result这个channel中不断接收原生,将事件通过 switch 不同的类型调用不同的函数
第一阶段
options = metav1.ListOptions{
// 该值会持续更新,如果网络异常导致 连续中断,则会从接收到的版本再次进行watch
ResourceVersion: resourceVersion,
....
}
// start the clock before sending the request, since some proxies won't flush headers until after the first watch event is sent
start := r.clock.Now()
// 开始对资源进行watch, apiserver推送事件后,会将事件推送到一个 result的channel中,然后由后续的watchHandler进行处理
w, err := r.listerWatcher.Watch(options)Watch对象的实现
retry := r.retryFn(r.maxRetries)
url := r.URL().String()
for {
if err := retry.Before(ctx, r); err != nil {
return nil, retry.WrapPreviousError(err)
}
// 构造请求
req, err := r.newHTTPRequest(ctx)
if err != nil {
return nil, err
}
resp, err := client.Do(req)
updateURLMetrics(ctx, r, resp, err)
retry.After(ctx, r, resp, err)
if err == nil && resp.StatusCode == http.StatusOK {
// 返回流对象
return r.newStreamWatcher(resp)
}
}流对象
// NewStreamWatcher creates a StreamWatcher from the given decoder.
func NewStreamWatcher(d Decoder, r Reporter) *StreamWatcher {
sw := &StreamWatcher{
source: d,
reporter: r,
// It's easy for a consumer to add buffering via an extra
// goroutine/channel, but impossible for them to remove it,
// so nonbuffered is better.
result: make(chan Event),
// If the watcher is externally stopped there is no receiver anymore
// and the send operations on the result channel, especially the
// error reporting might block forever.
// Therefore a dedicated stop channel is used to resolve this blocking.
done: make(chan struct{}),
}
go sw.receive()
return sw
}sw.receive()
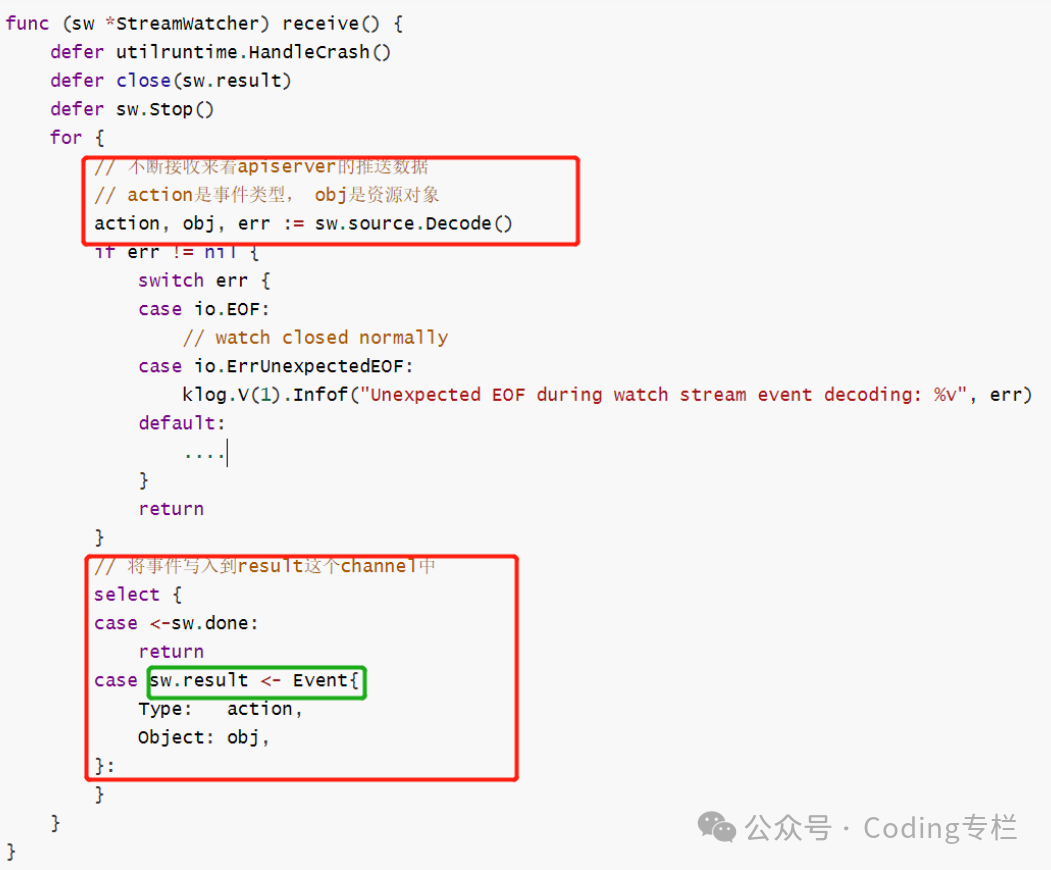
从result这个channel获取数据,并调用对应的事件
会在这里循环读取数据,ResultChan()返回的就是 result 这个channel
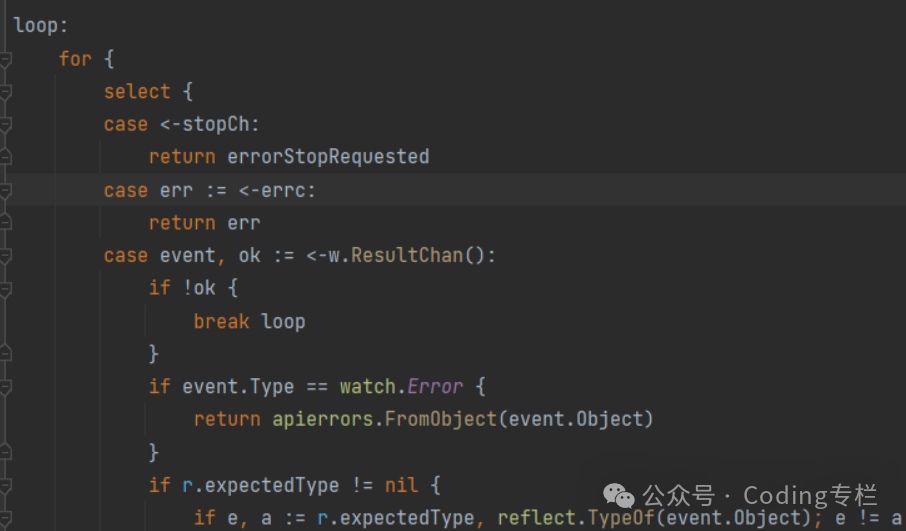
通过不同的事件类型,调用不同的队列方法 【store是前面定义的 DeltaFIFO】
同时还会将已经获取的 资源版本进行更新【这里传进来的是指针,所有更改后 外面会生效】
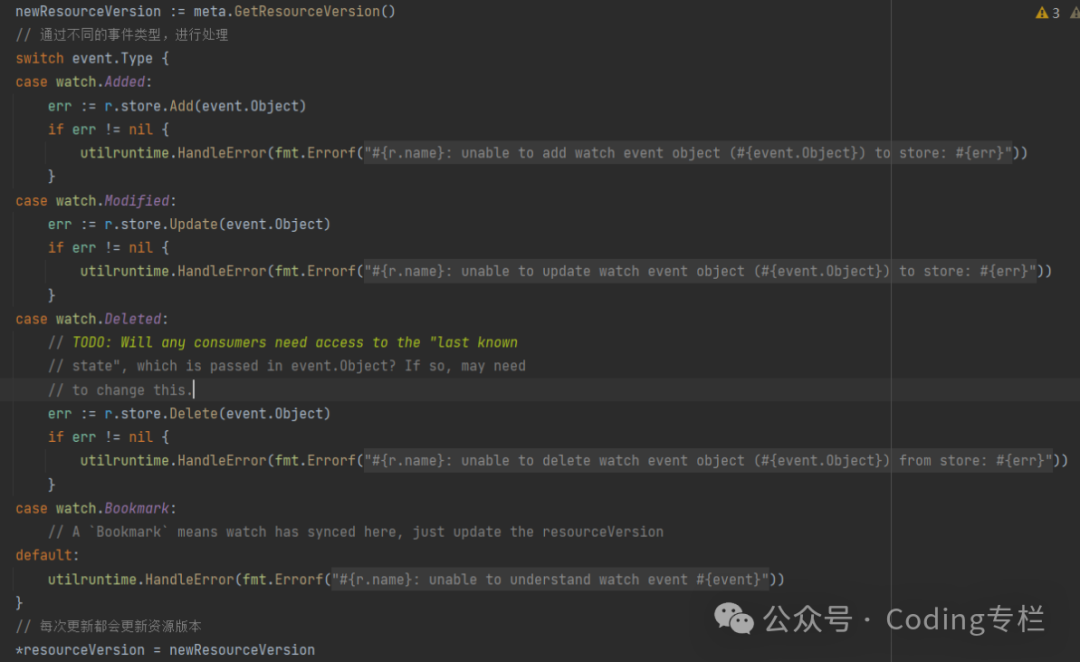
reSync过程
// 这里进行重新 同步数据到队列中, 同步主要是为了 能够周期性的去触发我们自己写的代码更新资源状态
go func() {
resyncCh, cleanup := r.resyncChan()
defer func() {
cleanup() // Call the last one written into cleanup
}()
for {
select {
case <-resyncCh:
case <-stopCh:
return
case <-cancelCh:
return
}
// 重新同步资源对象到队列中
if r.ShouldResync == nil || r.ShouldResync() {
klog.V(4).Infof("%s: forcing resync", r.name)
if err := r.store.Resync(); err != nil {
resyncerrc <- err
return
}
}
cleanup()
// 是否可以进行同步: 这里是去重试时间开启了一个定时通知
resyncCh, cleanup = r.resyncChan()
}
}()
// 进行重新同步
func (f *DeltaFIFO) Resync() error {
f.lock.Lock()
defer f.lock.Unlock()
if f.knownObjects == nil {
return nil
}
// fifo := NewDeltaFIFOWithOptions(DeltaFIFOOptions{
// KnownObjects: s.indexer,
// EmitDeltaTypeReplaced: true,
// })
// 这里同步是去取 indexer里面的数据: indexer就是 threadSafeMap
keys := f.knownObjects.ListKeys()
for _, k := range keys {
if err := f.syncKeyLocked(k); err != nil {
return err
}
}
return nil
}面试题
网络异常,会不会导致事件丢失?
不会,网络异常只会影响到Watch,这中间发送的事件无法接收到,但是一旦网络恢复,重新开始Watch,客户端会维护一个已经接收事件的版本号,当网络恢复,会从这个版本号开始进行watch资源,
如果客户端重启呢,会不会丢失事件?
是的,客户端重启肯定是会丢失事件的,但是并不影响controller的运行,重启会重新获取全量的资源列表,这时能够获取到最新的版本,controller的目标就是将用户期望spec,实际进行应用,所有只需要应用最新版本即可
存的资源版本号,是每个资源对象都有存吗,例如pod资源,pod1的版本号和pod2的版本号?
不用,只用存储一个版本号即可,因为资源的的版本号是递增的,只用记录最后一个同步的版本即可,
ListAndWatch中的watch过程,是每一个资源都有一个watch吗?
答:不是,client-go采用的是采用的区间watch【同时watch满足条件的一批资源】,所以只需要一个watch请求,
扩展:是一类对象一个watch,例如pod,configmap,这是一类对象
k8s采用了多路复用,可以将一个controller发起的watch请求,通过一个连接进行发送,可以降低api-server的连接数量
为什么要进行重新同步?
1、重新同步是为了controller能够定期的去更新对应的资源
2、controller在处理事件时,如果需要等待或者处理错误,通过重新同步可以再次触发更新
listAndWatch的流程?
1、发起List请求,获取所有需要Watch的资源 2、将这些资源写入队列
3、定期的中缓存中取出 资源对象,写入队列
4、对资源进行Watch,如果有事件会同步到队列
5、从队列中取出资源,写入到缓存
6、调用用户定义的handler处理事件
原文地址:https://blog.csdn.net/weixin_42236288/article/details/136986882
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!