Kafka第四篇——生产数据总体概括,源码解析分区策略,数据收集器,Sender发送线程,key值
目录
流程图以及总体概述
producer进行发送record,record对象包含topic,key,value,partition,时间戳,通过拦截器,将数据信息发送给broker,但是咱们也不知道把数据信息发送给哪个broker,而我们的Metadata就可以获取出来这个,如下面代码就是获取到9092.获取到缓存,放在底层。然后经过key对象的序列化,value对象的序列化,对应在代码中就是,configMap.put()那两行,并且这个是必须写的。然后经过分区器,partition,每个数据需要发送到broker中,每个消息发送到特定的主题,主题分为多个分区。kafka在发送数据时候,可以将数据发送到指定主题的指定分区,kafka会自动决定将消息发送到那个分区。分区器有那种判断发送给那个broker。然后进行数据校验。在数据收集器当中,相当于一个缓冲池,将同一个主题的数据可以存放在一个队列中,按“批”为单位进行发送,提高效率,并且指定了每批的大小是16K,
数据已经缓存到数据收集器后,就可以进行发送数据喽!此时就不会按topic为单位进行发送了,就可以重新整合,以节点为主!(why??因为不同的topic可以发送给同一个节点呀傻瓜!也就是说,在缓冲区以topic为单位,在发送线程中以节点为单位)封装请求,然后放在缓冲区中。再由网络通信从缓冲区中取出,发送给socket。在缓冲区,需要注意概念,在途请求缓冲区为5,表示同一个节点同一时间处理的请求数量。


拦截器
数据的规范化处理。可以有多个,可以按顺序执行数据的被拦截。和框架那块的一样。
onsend方法就是主要进行执行拦截规则的,for(ProducerInterceptor<K,V> interceptor:this.intercept)就可以循环执行多个拦截器,并且,看try,catch内容,无论当前拦截器发生什么异常,都不会影响到下一个拦截器的执行,更不会影响整个数据的发送。



自定义实现拦截器,帮助自己更好地了解拦截器。
java import org.apache.kafka.clients.producer.ProducerInterceptor; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import java.util.Map; public class ValueInterceptorTest implements ProducerInterceptor<String, String> { /** * 实现拦截器规则 * */ @Override public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) { } /** * 当记录被Broker确认接收时调用 * * */ @Override public void onAcknowledgement(RecordMetadata metadata, Exception exception) { // 这个方法在记录被Broker确认接收时被调用 // 根据确认情况实现自定义的处理逻辑 } /** * 关闭拦截器时调用 */ @Override public void close() { } /** * 配置拦截器时调用 * *configs 配置信息 */ @Override public void configure(Map<String, ?> configs) { } }

分区器以及分区计算策略
为啥进行分区计算?
数据发送给某个主题,主题会有很多分区,会在不同的broker当中,所以要算分区编号,不然连数据要发送给主题哪个节点都不知道。但是分区标号也得有范围呀!
producer生产者怎么知道有哪些分区?

从元数据缓存中获取到producer需要的主题相关信息
意味着只要元数据信息缓存了,主题的相关信息我们就可以拿到。



分区器通过Matadata获取到分区,副本id,leadid之类的,
分区计算
 ¹²³⁴ 如果参数中指定了分区编号就直接返回
¹²³⁴ 如果参数中指定了分区编号就直接返回

如何自定义实现分区器?
1.实现partitioner接口, 重写相关方法。感觉主要就是实现partition方法。
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.utils.Utils;
import java.util.List;
import java.util.Map;
public class CustomPartitioner implements Partitioner {
/**
* 配置分区器
*
* @param configs 配置信息
*/
@Override
public void configure(Map<String, ?> configs) {
}
/**
* 计算分区
*
* @param topic 主题名称
* @param key 消息键,可以为null
* @param keyBytes 消息键的字节数组表示,可以为null
* @param value 消息值
* @param valueBytes 消息值的字节数组表示
* @param cluster Kafka集群信息
* @return 分配的分区ID
*/
@Override
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
// 如果键为null,则使用轮询分区策略
if (keyBytes == null) {
return Utils.toPositive(Utils.murmur2(valueBytes)) % numPartitions;
}
// 使用键的hashCode来计算分区
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
/**
* 关闭分区器
*/
@Override
public void close() {
// 可以在这里进行资源的清理操作,通常分区器不需要进行额外的关闭操作
}
}
想说的在图里啦!宝宝!💡
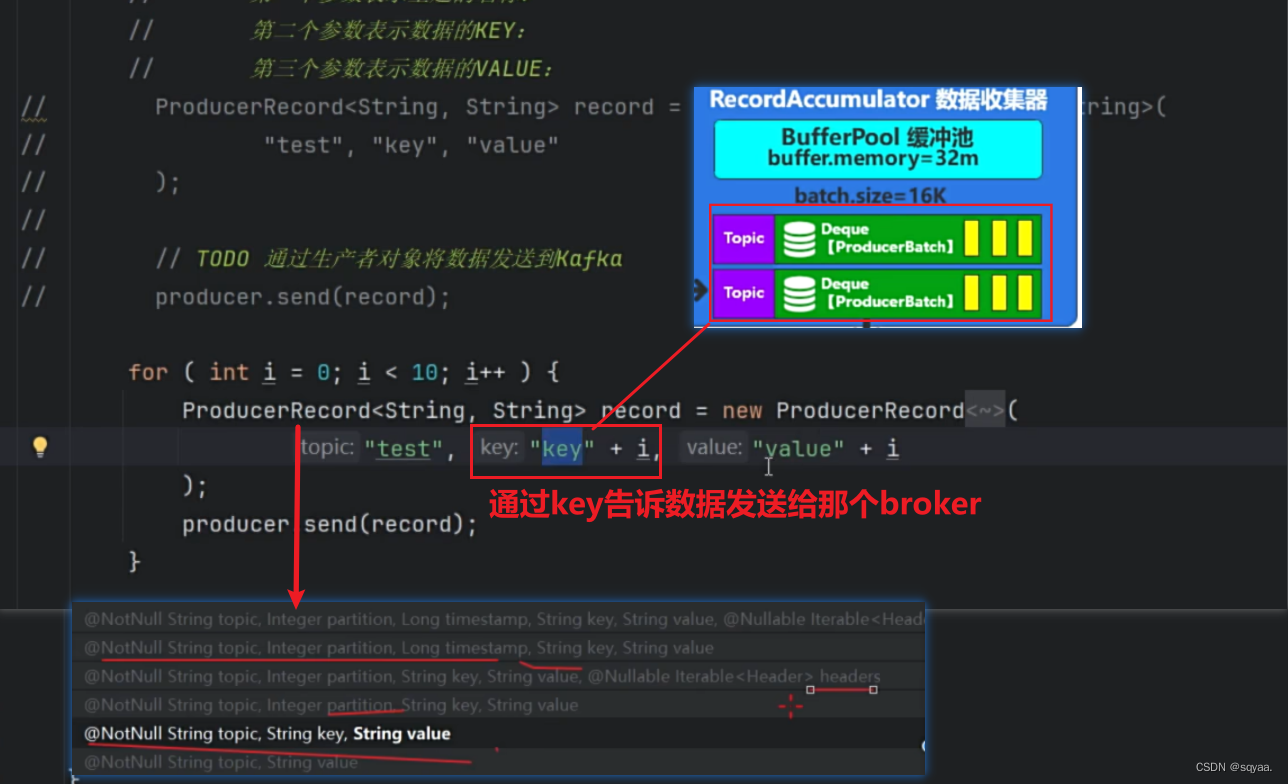
嘿嘿,这里解决了之前的问题,key并不像之前学到的hashmap中消费者用来消费的key,它的核心作用就是用来进行分区计算!
这个点就可以从:没有指定特定的分区标号,并且分区标号没有超过范围!序列化key以及分区器不忽略key的情况下看出来。partitionForKey()方法中就用不加密的hash算法并且对分区数量进行取余处理计算。
如果key值忘记传递了呢!?
return RecordMetadata.UNKNOWN_PARTITION;(这是一个表示未知分区的常量)。表明当前生产者无法确定消息发送到哪个分区,可能需要进一步处理或记录错误信息。那感觉也不太对啊,不知道把key发送到哪一个分区!
其实他是在数据收集器那一步追加了,看这个accumulator.append方法!
点进去哦!分区标号计算:粘性分区策略
如果没有进行传递key参数,也就是当前分区是未知分区,就会根据当前主题的分区负载情况来动态获取分区标号。这就是一种优化后的粘性分区策略!如图1.1

🤔图1.1 当前分区是未知分区,就会根据当前主题的分区负载因子来动态获取分区标号。 会根据当前分区负载情况判断去那个分区!如图1.2
✅当分区负载情况为空,就动态去随机选择分区,然后就尽可能的给这个分区追加数据(粘性分区策略),并且也不能超过数值batch.size=16K。如果超过这个阈值就会切换到下一个分区。并且更新分区负载情况。
✅当前主题分区负载情况不为空,那就不用随机生成了。会根据分区负载使用频率随机生成一个随机权重,然后利用二分查找算法找与权重相近的值,根据这个值获取到相应的分区,就可以得到我们的分区标号啦!

图1.2




数据校验
当数据校验成功,数据就到达了数据收集器当中。数据收集器,生产的数据作为一个临时的存储。

数据收集器
如果直接生产一条数据就通过网络通信来发送,这样做效率很低哦!像javaio流读取文件一样,读一个字节写一个字节,性能很低呀!
所以就有了ProducerBatch双端队列,从很减少频繁的网络交互,提高传输效率!
在神魔时候真正进行网络交互呢??
嘿嘿,看最大范围,batch.size=16K。在前面分区计算中,有一个粘性分区策略(一旦确定了一个分区,就尽可能往这个分区中追加数据,追加数据就是往producebatch中追加数据,当到达16K,就会被sender检测到),里面就有“没有传递key,如果没有分区负载情况,就会随机生成分区,不能超过最大

注意
🤔而且这里的16k意思是超过16k就不再接收数据了,不意味着数据不能超过16k!比如数据是20k,kafka要保证数据的完整性,发现这个数据值大于16k,就立马关闭,不再接收!
Sender发送线程
kafka底层就采用了很多生产者消费者模型,一个放一个取。数据收集器是按照主题分区来放数据,而Sender发送线程会按照broker重新整合。(主题的不同分区会放在不同的节点当中,所以有可能存在不同主题的分区在同一个节点当中)。
当整合好之后,就会封装成produceRequest,进而发送给网络客户端。
默认发送时间0,也就是消息取过来就可以直接发送了!
注意这个在途请求缓冲区数量:5



- Broker 和 Topic:每个 broker 可以存储一个或多个 topic 的数据分片,Kafka 集群的每个 broker 都可以服务于多个 topic。
- Topic 和 分区:每个 topic 可以被分为多个分区,分区内的消息顺序是有序的,而不同分区之间的消息顺序则不保证,分区允许 Kafka 横向扩展和提高并行处理能力。
- Broker 和 分区:每个 broker 可能会存储多个 topic 的多个分区数据,这样在整个 Kafka 集群中就形成了数据的分布式存储和处理能力。
原文地址:https://blog.csdn.net/m0_74106420/article/details/139889232
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!