240713_昇思学习打卡-Day25-LSTM+CRF序列标注(4)
240713_昇思学习打卡-Day25-LSTM+CRF序列标注(4)
最后一天咯,做第四部分。
BiLSTM+CRF模型
在实现CRF后,我们设计一个双向LSTM+CRF的模型来进行命名实体识别任务的训练。模型结构如下:
nn.Embedding -> nn.LSTM -> nn.Dense -> CRF
其中LSTM提取序列特征,经过Dense层变换获得发射概率矩阵,最后送入CRF层。具体实现如下:
# 定义双向LSTM结合CRF的序列标注模型
class BiLSTM_CRF(nn.Cell):
def __init__(self, vocab_size, embedding_dim, hidden_dim, num_tags, padding_idx=0):
"""
初始化BiLSTM_CRF模型。
参数:
vocab_size: 词汇表大小。
embedding_dim: 词嵌入维度。
hidden_dim: LSTM隐藏层维度。
num_tags: 标签种类数量。
padding_idx: 填充索引,默认为0。
"""
super().__init__()
# 初始化词嵌入层
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=padding_idx)
# 初始化双向LSTM层
self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2, bidirectional=True, batch_first=True)
# 初始化从LSTM输出到标签的全连接层
self.hidden2tag = nn.Dense(hidden_dim, num_tags, 'he_uniform')
# 初始化条件随机场层
self.crf = CRF(num_tags, batch_first=True)
def construct(self, inputs, seq_length, tags=None):
"""
模型的前向传播方法。
参数:
inputs: 输入序列,形状为(batch_size, seq_length)。
seq_length: 序列长度,形状为(batch_size,)。
tags: 真实标签,形状为(batch_size, seq_length),可选。
返回:
crf_outs: CRF层的输出,如果输入了真实标签则为损失值,否则为解码后的标签序列。
"""
# 通过词嵌入层获取词向量表示
embeds = self.embedding(inputs)
# 通过双向LSTM层获取序列特征
outputs, _ = self.lstm(embeds, seq_length=seq_length)
# 通过全连接层转换LSTM输出到标签空间
feats = self.hidden2tag(outputs)
# 通过CRF层计算损失或解码
crf_outs = self.crf(feats, tags, seq_length)
return crf_outs
完成模型设计后,我们生成两句例子和对应的标签,并构造词表和标签表。
# 设置词嵌入维度和隐藏层维度
embedding_dim = 16
hidden_dim = 32
# 定义训练数据集,每条数据包含一个分词后的句子和相应的实体标签
training_data = [
(
"清 华 大 学 坐 落 于 首 都 北 京".split(), # 分词后的句子
"B I I I O O O O O B I".split() # 相应的实体标签
),
(
"重 庆 是 一 个 魔 幻 城 市".split(), # 分词后的句子
"B I O O O O O O O".split() # 相应的实体标签
)
]
# 初始化词典,用于映射词到索引
word_to_idx = {}
# 添加特殊填充词到词典
word_to_idx['<pad>'] = 0
# 遍历训练数据,构建词到索引的映射
for sentence, tags in training_data:
for word in sentence:
# 如果词不在词典中,则添加到词典
if word not in word_to_idx:
word_to_idx[word] = len(word_to_idx)
# 初始化标签到索引的映射
tag_to_idx = {"B": 0, "I": 1, "O": 2}
len(word_to_idx)
接下来实例化模型,选择优化器并将模型和优化器送入Wrapper。
由于CRF层已经进行了NLLLoss的计算,因此不需要再设置Loss。
# 实例化BiLSTM_CRF模型,传入词汇表大小、词嵌入维度、隐藏层维度以及标签种类数量
model = BiLSTM_CRF(len(word_to_idx), embedding_dim, hidden_dim, len(tag_to_idx))
# 初始化随机梯度下降优化器,设置学习率为0.01,权重衰减为1e-4
optimizer = nn.SGD(model.trainable_params(), learning_rate=0.01, weight_decay=1e-4)
# 使用MindSpore的value_and_grad函数创建一个函数,它会同时计算模型的损失值和梯度
# 第二个参数设置为None表示不保留反向图,第三个参数是优化器的参数列表
grad_fn = ms.value_and_grad(model, None, optimizer.parameters)
def train_step(data, seq_length, label):
"""
训练步骤函数,执行一次前向传播和反向传播更新模型参数。
参数:
data: 输入数据,形状为(batch_size, seq_length)。
seq_length: 序列长度,形状为(batch_size,)。
label: 真实标签,形状为(batch_size, seq_length)。
返回:
loss: 当前批次的损失值。
"""
# 使用grad_fn计算损失值和梯度
loss, grads = grad_fn(data, seq_length, label)
# 使用优化器更新模型参数
optimizer(grads)
# 返回损失值
return loss
将生成的数据打包成Batch,按照序列最大长度,对长度不足的序列进行填充,分别返回输入序列、输出标签和序列长度构成的Tensor。
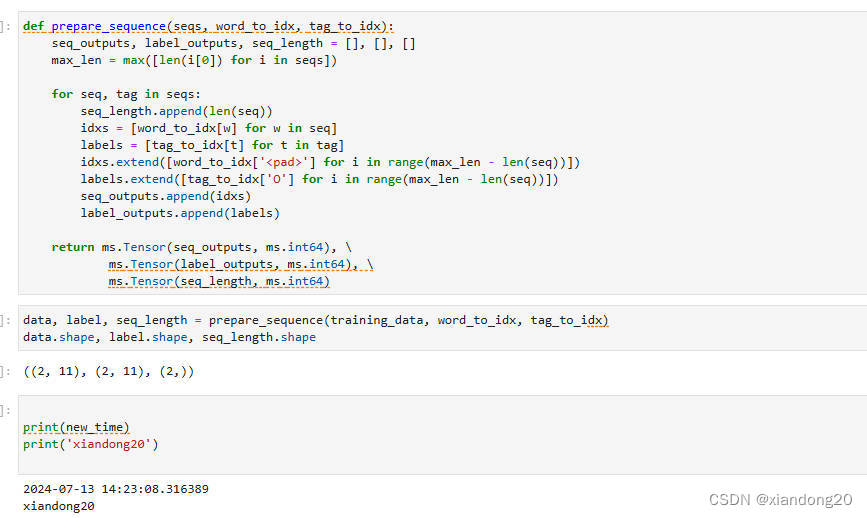
def prepare_sequence(seqs, word_to_idx, tag_to_idx):
"""
准备序列数据,包括填充和转换成张量。
参数:
seqs: 一个包含句子和对应标签的元组列表。
word_to_idx: 词到索引的映射字典。
tag_to_idx: 标签到索引的映射字典。
返回:
seq_outputs: 填充后的序列数据张量。
label_outputs: 填充后的标签数据张量。
seq_length: 序列的真实长度列表。
"""
seq_outputs, label_outputs, seq_length = [], [], []
# 获取最长序列长度
max_len = max([len(i[0]) for i in seqs])
for seq, tag in seqs:
# 记录序列的真实长度
seq_length.append(len(seq))
# 将序列中的词转换为索引
idxs = [word_to_idx[w] for w in seq]
# 将标签转换为索引
labels = [tag_to_idx[t] for t in tag]
# 对序列进行填充
idxs.extend([word_to_idx['<pad>'] for i in range(max_len - len(seq))])
# 对标签进行填充,用'O'的索引填充
labels.extend([tag_to_idx['O'] for i in range(max_len - len(seq))])
# 添加填充后的序列和标签到列表
seq_outputs.append(idxs)
label_outputs.append(labels)
# 将列表转换为MindSpore张量
return ms.Tensor(seq_outputs, ms.int64), \
ms.Tensor(label_outputs, ms.int64), \
ms.Tensor(seq_length, ms.int64)
# 调用prepare_sequence函数处理训练数据,并获取处理后的数据、标签和序列长度
data, label, seq_length = prepare_sequence(training_data, word_to_idx, tag_to_idx)
# 打印处理后的数据、标签和序列长度的形状,以确认数据转换是否正确
print(data.shape, label.shape, seq_length.shape)
对模型进行预编译后,训练500个step。
训练流程可视化依赖
tqdm库,可使用pip install tqdm命令安装。
from tqdm import tqdm
# 定义训练步骤的总数,用于进度条的设置
steps = 500
# 使用tqdm创建一个进度条,总进度为steps
with tqdm(total=steps) as t:
for i in range(steps):
# 执行单步训练,这里假设train_step是一个已定义的训练函数
# 参数data为训练数据,seq_length为序列长度,label为标签
loss = train_step(data, seq_length, label)
# 更新进度条的附带信息,显示当前的损失值
t.set_postfix(loss=loss)
# 更新进度条,表示完成了一步训练
t.update(1)
最后我们来观察训练500个step后的模型效果,首先使用模型预测可能的路径得分以及候选序列。
# 调用模型进行预测或评估,返回得分和历史记录
score, history = model(data, seq_length)
# 输出得分,用于查看模型的表现或决策
score
使用后处理函数进行预测得分的后处理。
predict = post_decode(score, history, seq_length)
predict
最后将预测的index序列转换为标签序列,打印输出结果,查看效果。
# 通过索引和标签的映射关系,构建标签到索引的反向映射
idx_to_tag = {idx: tag for tag, idx in tag_to_idx.items()}
def sequence_to_tag(sequences, idx_to_tag):
"""
将序列中的索引转换为对应的标签。
参数:
sequences: 一个包含标签索引的序列列表。
idx_to_tag: 一个字典,用于将索引映射到对应的标签。
返回:
一个列表,其中每个元素是输入序列中索引转换为标签后的结果。
"""
# 初始化一个空列表,用于存储转换后的标签序列
outputs = []
# 遍历输入的序列列表
for seq in sequences:
# 对每个序列,将索引转换为标签,并添加到输出列表中
outputs.append([idx_to_tag[i] for i in seq])
# 返回转换后的标签序列列表
return outputs
sequence_to_tag(predict, idx_to_tag)
打卡照片:
原文地址:https://blog.csdn.net/weixin_66378701/article/details/140382836
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!