ES数据聚合 DSL实现Bucket聚合
ES数据聚合
聚合的分类
聚合(aggregations)可以实现对文档数据的统计、分析、运算。聚合常见的有三类:
- 桶(Bucket)聚合:对文档做分组 (类似数据库的group by)
- TermAggregation:按照文档字段值分组 (该字段就不能分词了 不能是text)
- Date Histogram:按照日期阶梯分组,比如一周为一组,或者一个月为一组 (这个功能用mysql实现就复杂多了)
- 度量(Metric)聚合:用于计算一些值
- Avg
- Max
- Min
- Stats:同时求max min avg sum
- 管道(pipeline)聚合:其它聚合的结果为基础做的聚合
桶和度量用的比较多

DSL实现Bucket聚合

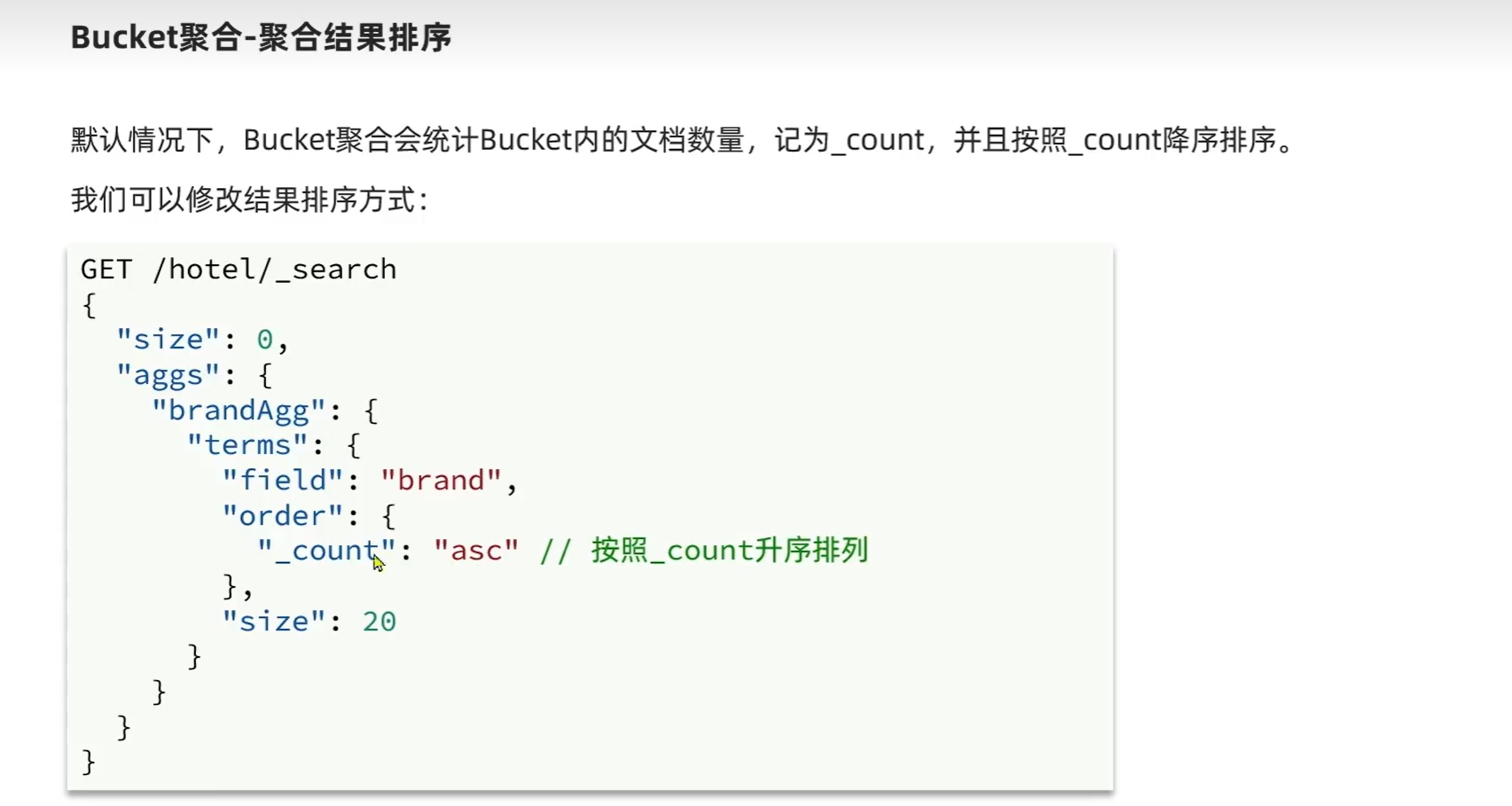
设置size为0 结果中不包含文档,只包含聚合结果
记住三个:聚合名称 聚合类型 聚合对应的字段
实例:
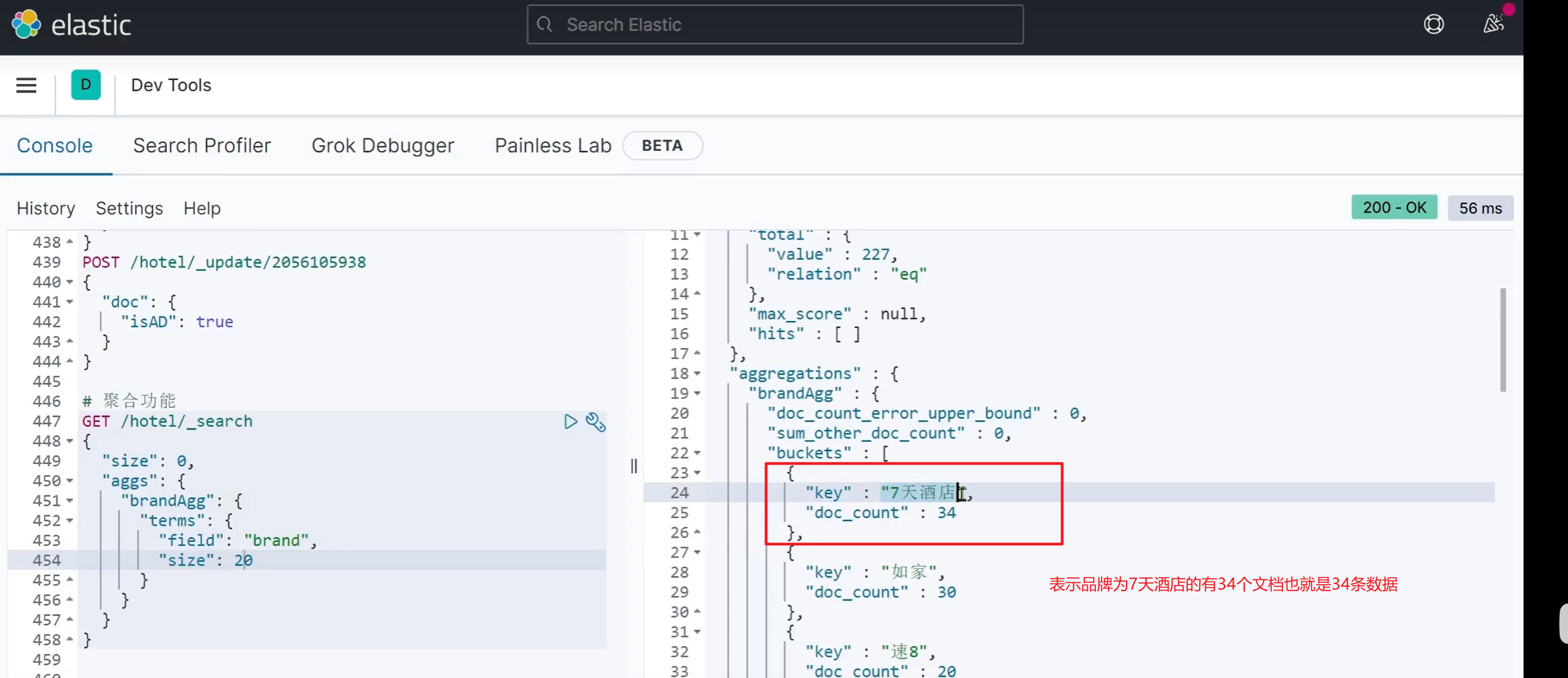
可以理解为命中数符合条件的文档数据 相当于数据库中的一条条数据。可以修改排序规则 ,默认是按照_count 降序排序
品牌一样的会放在一个桶里面 可以比作垃圾分类

Bucket 聚合-限定聚合搜索范围
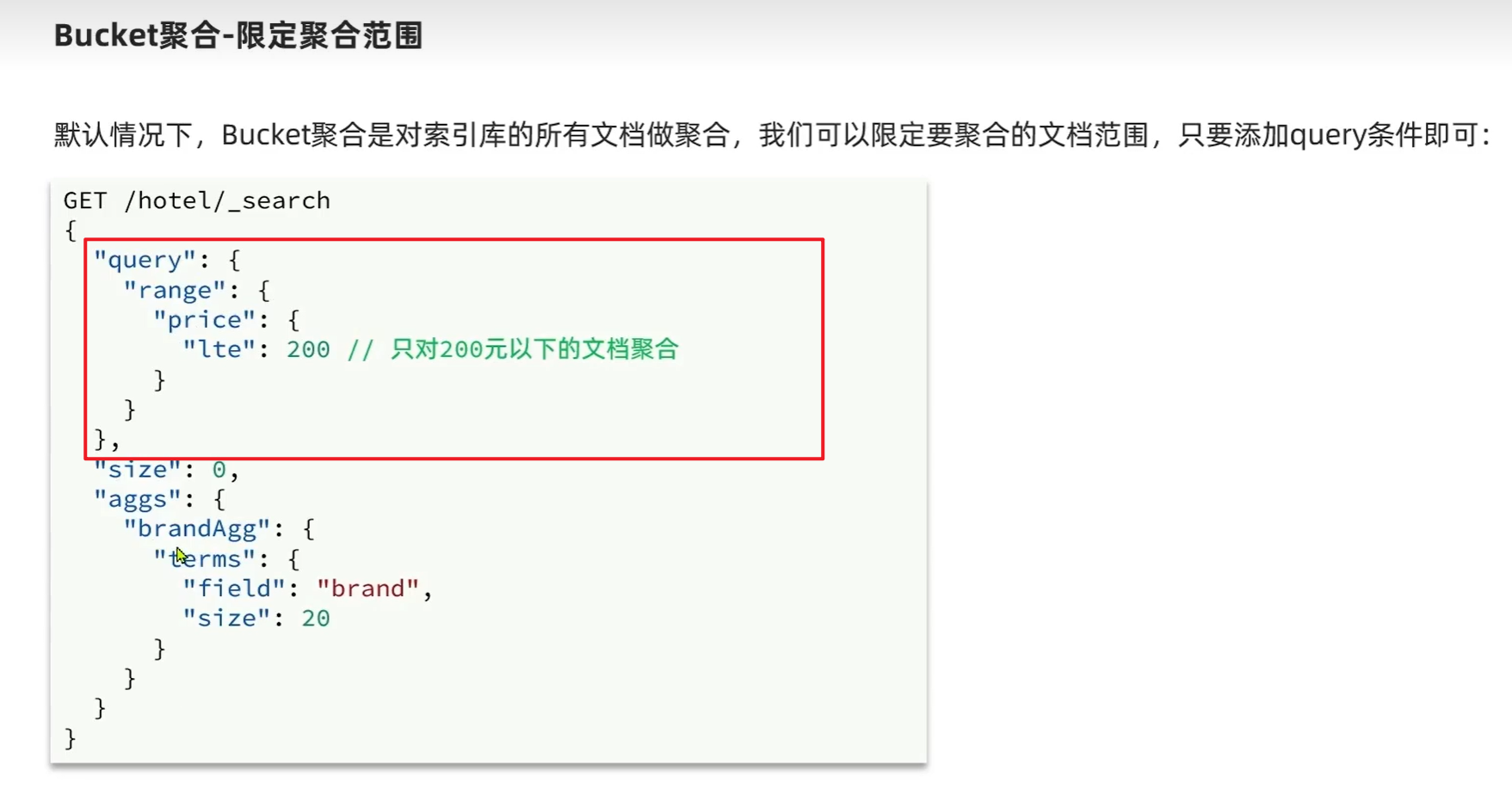
默认情况下,bucket聚合是对索引库的所有文档做聚合,我们可以限定聚合的文档范围,添加 query条件即可
总结:

原文地址:https://blog.csdn.net/qq_46603351/article/details/140622607
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!