kafka(六)——存储策略
存储机制
kafka通过topic作为主题缓存数据,一个topic主题可以包括多个partition,每个partition是一个有序的队列,同一个topic的不同partiton可以分配在不同的broker(kafka服务器)。
关系图
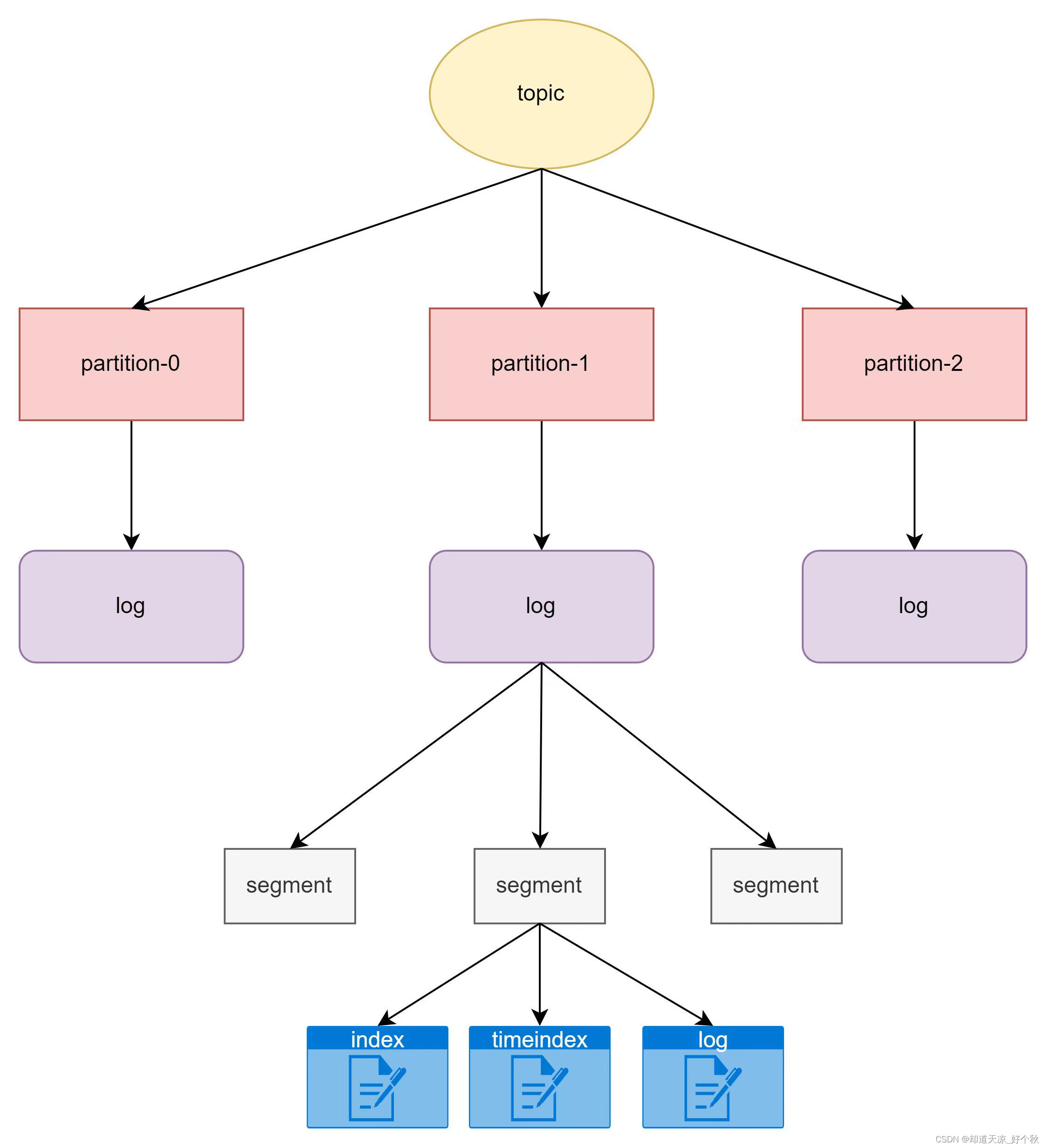
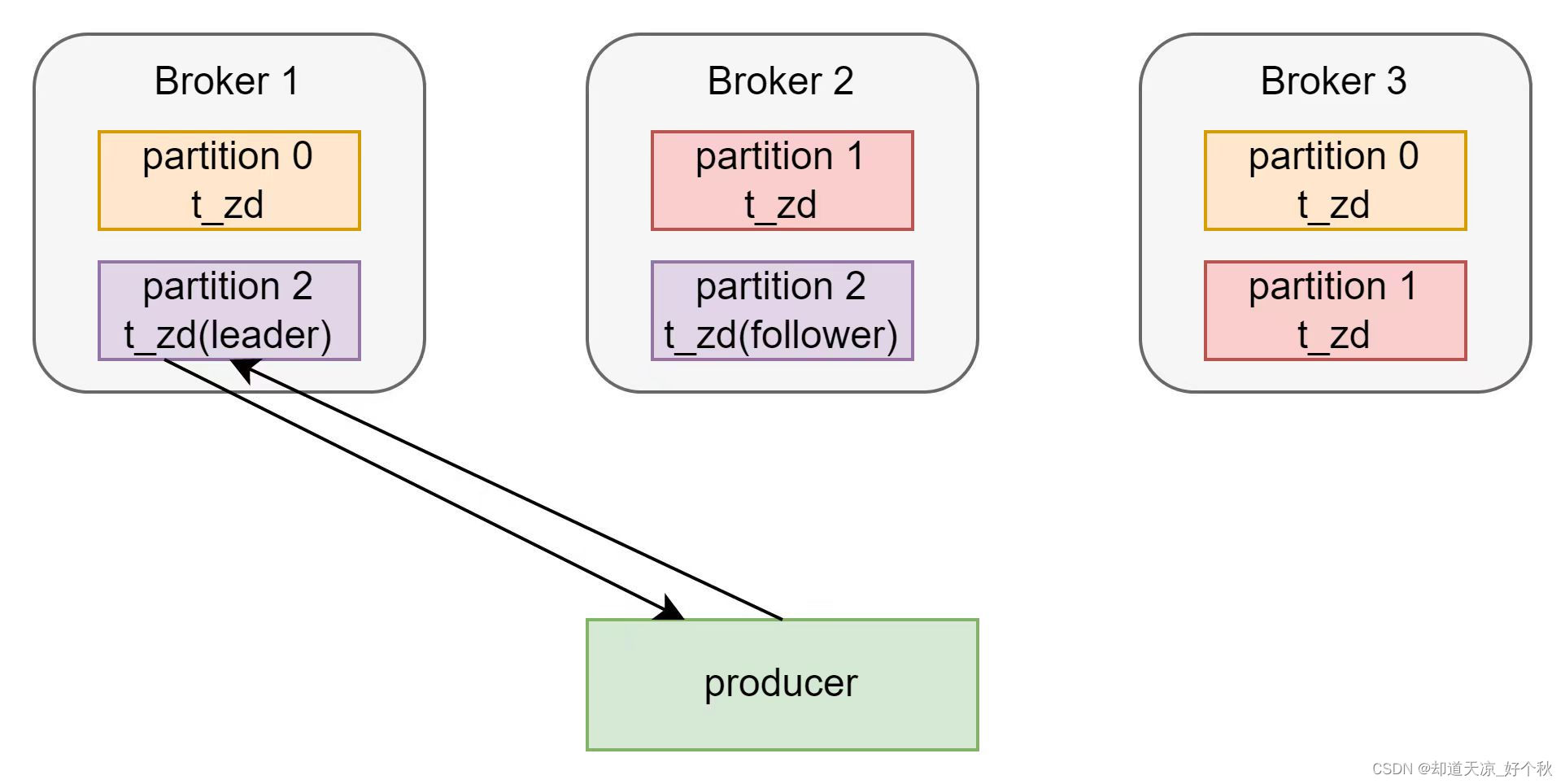
partition分布图
名称为t_zd的topic为3分区2副本,其在3节点kafka集群的分布如下:
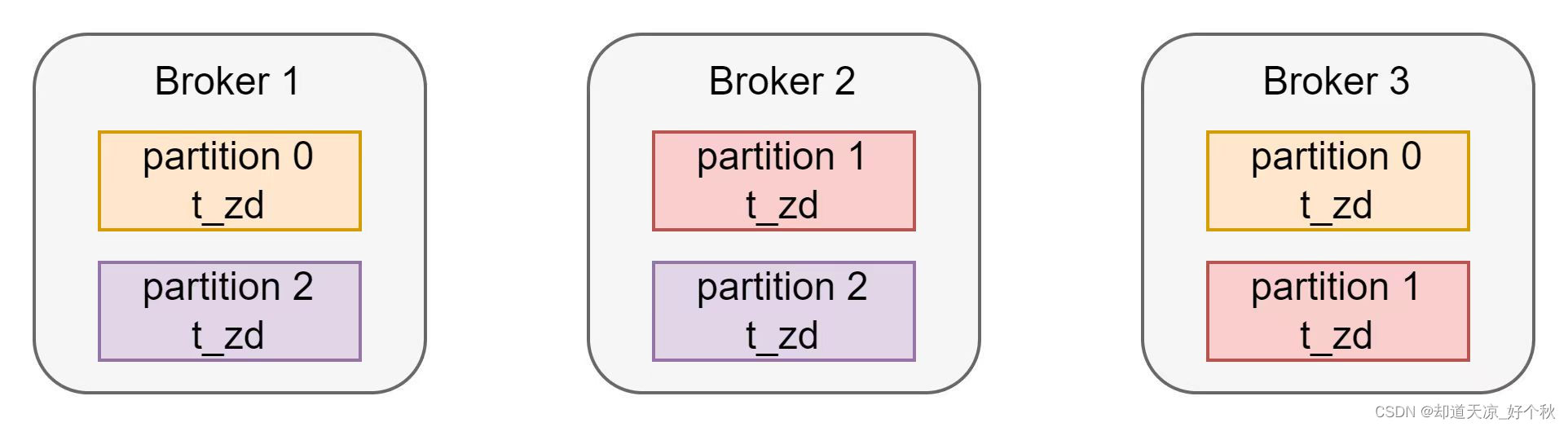
概念
topic
主题,即消息存放的目录。
Partition
-
一个topic可以分为多个partition;
-
每个partition是一个有序的队列;
-
每个partition实际对应一个文件夹,包含多个segment文件;
-
partition中的每条消息都会分配一个有序的id,即offset;
segment
- Kafka用于存储消息的基本单元;
- segment指partition文件夹下产生的文件;
- segment文件命名与offset有关,为log start offset;
- 每个分段都有一个起始偏移量和一个结束偏移量,用于定位消息的位置;
- 一个segment对应一个日志文件([offset].log)、时间索引文件([offset].timeindex)和索引文件([offset.index]),日志文件是用来记录消息,索引文件用来保存消息的索引;
- segment的大小可以通过server.properties配置文件中log.segment.bytes来配置,默认1G;

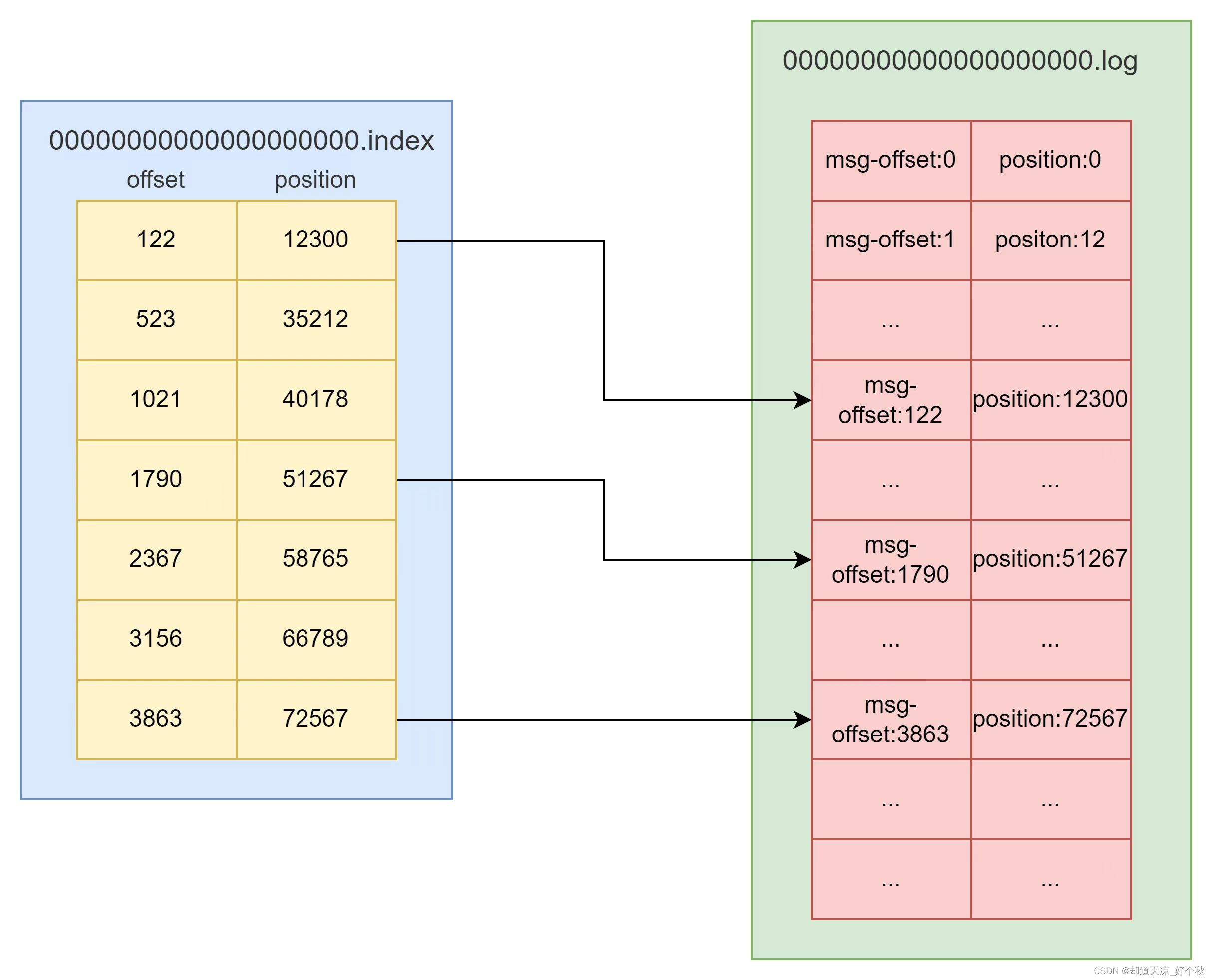
索引文件(index)
- 记录固定消息量的索引编号范围;
- Kafka在查询时,先从Index中定位到小范围的索引编号区间,再去Log中在小范围的数据块中查询具体数据,此索引区间的查询方式称为:稀疏索引;
日志文件(log)
- 负责消息的追加、读取和索引等操作;
- 每条消息有自增编号,只追加不修改;
消息(message)
示例
[root@192 zd-first-topic-0]$ls
00000000000000000000.index 00000000000000000000.timeindex partition.metadata
00000000000000000000.log leader-epoch-checkpoint
[root@192 zd-first-topic-0]$sh bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.log --print-data-log
Dumping 00000000000000000000.log
Log starting offset: 0
baseOffset: 0 lastOffset: 0 count: 1 baseSequence: 0 lastSequence: 0 producerId: 0 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 0 CreateTime: 1712889750352 size: 79 magic: 2 compresscodec: none crc: 3489688351 isvalid: true
| offset: 0 CreateTime: 1712889750352 keySize: -1 valueSize: 11 sequence: 0 headerKeys: [] payload: hello kafka
baseOffset: 1 lastOffset: 1 count: 1 baseSequence: 1 lastSequence: 1 producerId: 0 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 79 CreateTime: 1712889754967 size: 84 magic: 2 compresscodec: none crc: 2134132965 isvalid: true
| offset: 1 CreateTime: 1712889754967 keySize: -1 valueSize: 16 sequence: 1 headerKeys: [] payload: kafka first test
baseOffset: 2 lastOffset: 2 count: 1 baseSequence: 2 lastSequence: 2 producerId: 0 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 163 CreateTime: 1712889762442 size: 85 magic: 2 compresscodec: none crc: 3019058576 isvalid: true
| offset: 2 CreateTime: 1712889762442 keySize: -1 valueSize: 17 sequence: 2 headerKeys: [] payload: kafka second test
[root@192 zd-first-topic-0]$
参数说明
- baseOffset:当前消息起始位置的offset;
- position:消息在日志分段文件中对应的物理地址;
- size:消息长度;
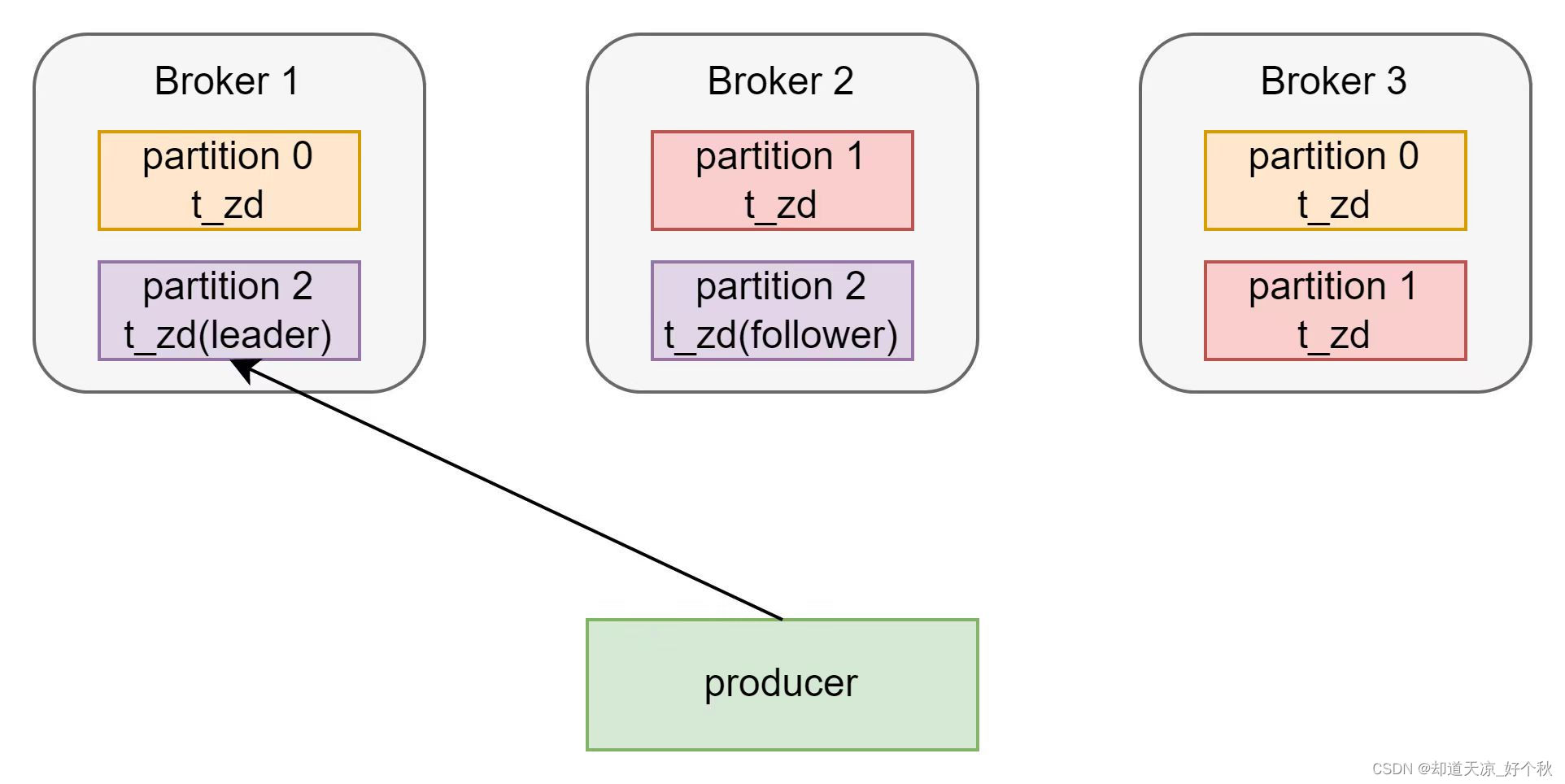
关系图
副本机制
- kafka副本机制提高了数据可靠性;
- Kafka默认副本1个,生产环境一般配置为2个,保证数据可靠性,但性能相对降低;
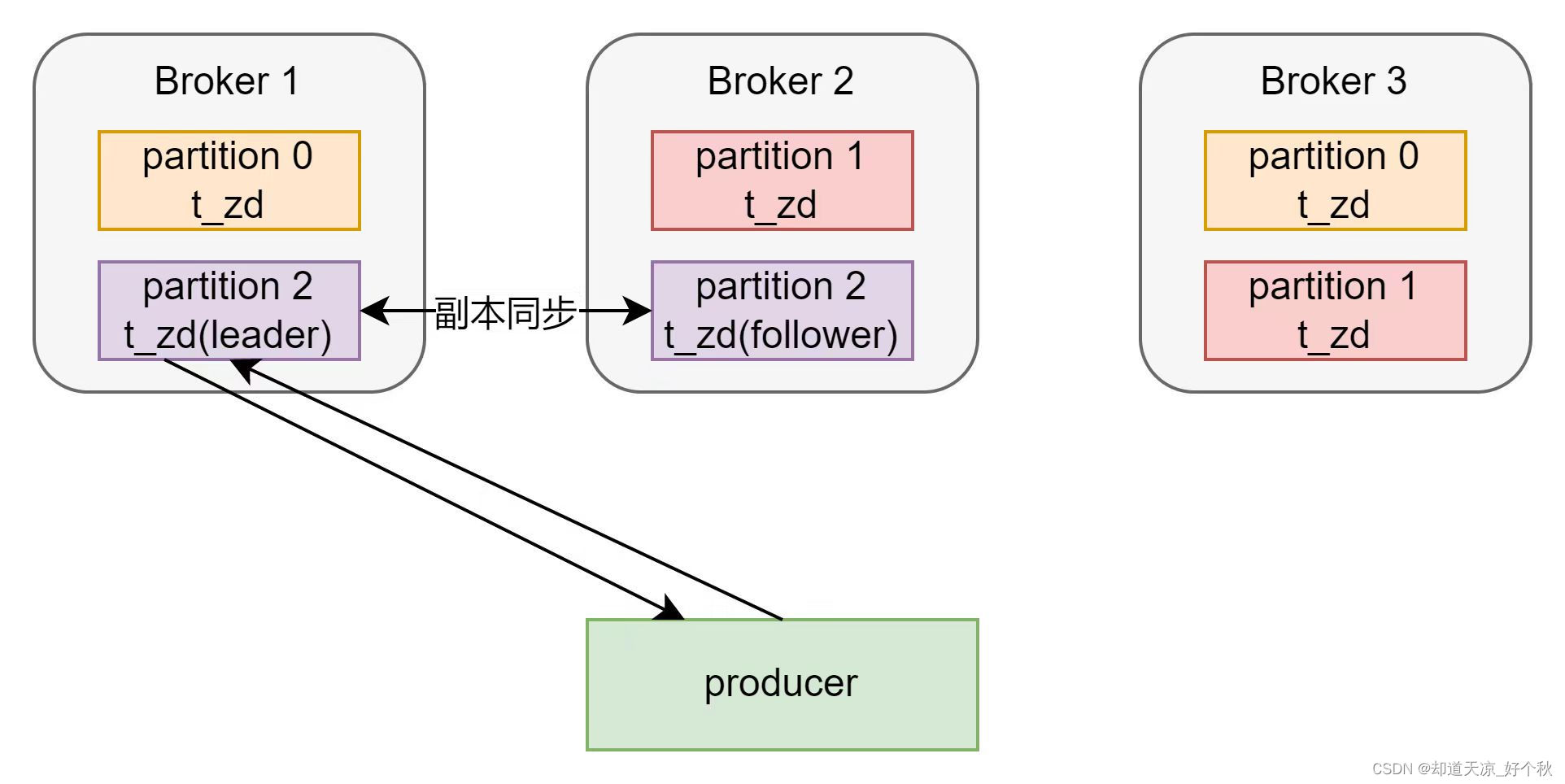
- Kafka中将副本分为Leader副本和Follower副本;
- Kafka生产者只会把数据发往Leader副本,Follower副本找Leader副本进行数据同步;
- Kafka分区中的所有副本统称为AR(Assigned Repllicas),AR = ISR + OSR;
- ISR:表示和Leader保持同步的Follower集合。如果Follower长时间未向Leader发送通信请求或同步数据,则该Follower将被踢出ISR。该时间阈值由replica.lag.time.max.ms参数设定,默认30s。Leader发生故障之后,就会从ISR中选举新的Leader;
- OSR:Follower与Leader副本同步时,延迟过多的副本;
producer的acks参数表示当生产者生产消息的时候,写入到副本的要求严格程度。
- acks为0:生产者将消息发送至主副本,不等确认可继续发送下一条消息,数据可能丢失。
- acks为1:生产者将消息发送至主副本,等主副本确认可继续发送下一条消息。
- acks为-1或all:生产者将消息发送至主副本,等主副本和从副本同步完成后可继续发送下一条消息。
日志清理机制
配置参数
log.retention.hours: 控制日志文件保留的最长时间;log.retention.bytes: 控制日志文件保留的最大大小;log.retention.minutes: 控制日志文件保留的最短时间;log.retention.check.interval.ms: 日志清理器检查日志是否满足清理条件的频率;log.cleaner.enable: 是否启用日志清理;log.cleanup.policy: 对于超过保留时间的日志文件,如何处理,默认delete。支持日志压缩(compaction)和delete+compaction;
日志删除
基于时间的删除策略
log.retention.hours: 控制日志文件保留的最长时间,默认168小时(7天);log.delete.delay.ms:执行延迟时间,默认1分钟;
执行日志分段的删除任务时,会首先从Log对象中维护的日志分段的跳跃表中移除需要删除的日志分段,然后将日志分段所对应的数据文件和索引文件添加.deleted后缀。最后转交给名称为delete-file任务来删除以.deleted为后缀的文件,执行延迟时间可通过参数log.delete.delay.ms控制,默认为1分钟。
基于日志大小的删除策略
log.retention.bytes: 控制日志文件保留的最大大小;log.delete.delay.ms:执行延迟时间,默认1分钟;
该策略会依次检查每个日志中的日志分段是否超出指定的大小(log.retention.bytes),对超出指定大小的日志分段采取删除策略。
日志压缩
压缩方式
- 通过GZIP或Snappy压缩器压缩日志段;
- 通过删除不必要的元数据来减少日志的大小;
参数配置
# 对于segment log进行压缩
log.cleaner.enable=true
# 设置压缩后的日志保留的最长时间
log.retention.hours=168
# 设置日志清理进程的运行频率(以小时为单位)
log.cleanup.policy=compact
# 设置压缩后的日志文件保留的最大大小
log.retention.bytes=1073741824
# 设置segment文件的压缩类型
log.cleaner.io.buffer.size=524288
log.cleaner.io.max.bytes.per.second=1048576
log.cleaner.dedupe.buffer.size=134217728
log.cleaner.threads=2
log.cleaner.min.cleanable.ratio=0.5
压缩流程
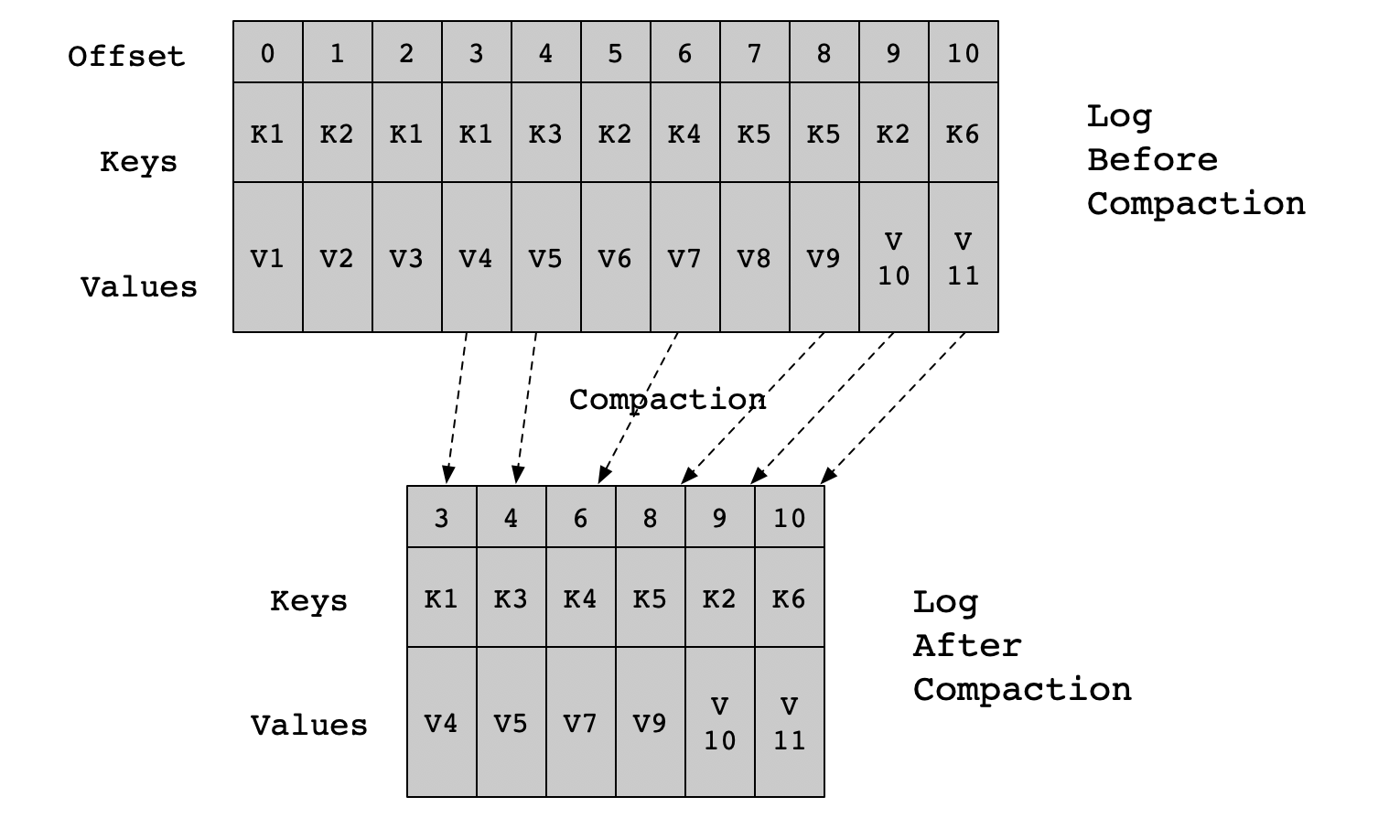
- Kafka的后台线程会定时将topic遍历两次,第一次将每个Key的哈希值最后一次出现的offset记录下来,第二次检查每个offset对应的Key是否在较为后面的日志中出现过,如果出现了就删除对应的日志;
- 日志压缩是针对Key的,在使用时应注意每个消息的Key值不为NULL;
- 压缩是在Kafka后台通过定时的重新打开Segment来完成的;
原文地址:https://blog.csdn.net/www_dong/article/details/137696179
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!