GobletNet:基于小波的高频融合网络用于电子显微镜图像的语义分割|文献速递-基于深度学习的病灶分割与数据超分辨率
Title
题目
GobletNet: Wavelet-Based High-FrequencyFusion Network for Semantic Segmentation of Electron Microscopy Images
GobletNet:基于小波的高频融合网络用于电子显微镜图像的语义分割
01
文献速递介绍
语义分割是计算机视觉中的一项基础任务,其目标是为每个像素分配一个类别标签。随着卷积神经网络(CNNs)的发展,自然图像的语义分割已经取得了卓越的成果。基于主干网络和分割头的架构已成为主流策略。此外,生物医学图像的语义分割也有了很大的进展,高效的编码器-解码器架构已经取得了优异的性能。最近,序列到序列的变换器(transformers)在语义分割中变得流行。一些研究尝试将CNN与变换器结合起来,使得模型能够同时利用CNN的低计算成本和变换器的全局感受野。
电子显微镜(EM)图像的语义分割可以看作是生物医学成像的一个分支,且其在很多领域中都具有重要意义。EM广泛用于纳米尺度的成像,研究组织、细胞、亚细胞结构和分子复合体[17]。随着更快的自动化成像技术的发展,一台电子显微镜在短时间内可以获取PB级别的数据[18],[19]。与费时且成本高昂的人工标注相比,自动化的EM语义分割方法显得尤为关键。许多研究探索了专门用于EM图像语义分割的模型,如残差去卷积网络(RDN)、深度上下文残差网络(DCR)、FusionNet[22]和DenseUNet[23]。
然而,目前专门针对EM图像的模型通常是自然图像或生物医学图像模型的扩展或改编。它们缺乏对EM图像内在特性的充分探索与利用。此外,它们往往仅为几个特定的分割对象设计,缺乏通用性。例如,[24]提出了一种基于改进的UNet的快速线粒体分割方法。[25]提出了一种结合亲和度预测和区域聚合的方法,用于从EM图像中分割神经元,这种方法可以减少管状和网络状分割对象的拓扑错误,但对其他目标(如线粒体和细胞核)可能效果较小。
在本研究中,我们通过小波变换定量分析了EM图像的特性。与自然图像和其他生物医学图像相比,EM图像的高频(HF)成分具有更丰富的纹理细节和更清晰的物体轮廓,但也包含更多噪声。将低频(LF)成分与高频成分按适当比例结合,可以减少噪声干扰。为了更好地利用这些特性,我们提出了一种基于小波的高频融合网络GobletNet。GobletNet利用小波变换生成高频图像作为额外输入,并使用额外的编码分支从高频图像中提取纹理和轮廓等信息,这相当于将额外的先验知识引入模型中。我们在编码过程的每个阶段引入了融合注意力模块(FAM),以促进原始图像和高频图像信息的更好吸收与融合。我们的模型在七个公共数据集上实现了最先进的性能,这些数据集涵盖了不同的分割对象、数据规模、成像区域和EM类型。
Aastract
摘要
Semantic segmentation of electronmicroscopy (EM) images is crucial for nanoscaleanalysis. With the development of deep neural networks(DNNs), semantic segmentation of EM images hasachieved remarkable success. However, current EMimage segmentation models are usually extensionsor adaptations of natural or biomedical models. Theylack the full exploration and utilization of the intrinsiccharacteristics of EM images. Furthermore, they are oftendesigned only for several specific segmentation objectsand lack versatility. In this study, we quantitatively analyzethe characteristics of EM images compared with thoseof natural and other biomedical images via the wavelettransform. To better utilize these characteristics, we designa high-frequency (HF) fusion network, GobletNet, whichoutperforms state-of-the-art models by a large margin in thesemantic segmentation of EM images. We use the wavelettransform to generate HF images as extra inputs anduse an extra encoding branch to extract HF information.Furthermore, we introduce a fusion-attention module (FAM)into GobletNet to facilitate better absorption and fusion ofinformation from raw images and HF images. Extensivebenchmarking on seven public EM datasets (EPFL, CREMI,SNEMI3D, UroCell, MitoEM, Nanowire and BetaSeg)demonstrates the effectiveness of our model.
电子显微镜(EM)图像的语义分割对纳米尺度分析至关重要。随着深度神经网络(DNNs)的发展,EM图像的语义分割已取得显著进展。然而,目前的EM图像分割模型通常是自然图像或生物医学图像模型的扩展或改编,未能充分探索和利用EM图像的内在特性。此外,这些模型往往仅针对某些特定的分割对象设计,缺乏通用性。在本研究中,我们通过小波变换定量分析了EM图像与自然图像及其他生物医学图像的特性。为了更好地利用这些特性,我们设计了一种高频(HF)融合网络GobletNet,该网络在EM图像的语义分割任务中,性能大幅超越了现有的最先进模型。我们使用小波变换生成高频图像作为额外输入,并使用额外的编码分支来提取高频信息。此外,我们在GobletNet中引入了融合注意力模块(FAM),以促进原始图像和高频图像信息的更好吸收与融合。在七个公共EM数据集(EPFL、CREMI、SNEMI3D、UroCell、MitoEM、Nanowire和BetaSeg)上的广泛基准测试验证了我们模型的有效性。
Method
方法
We analyze the characteristics of EM images via the wavelettransform in Section III-
A. We propose an HF fusion network,GobleNet, to fully exploit these characteristics in Section IIIB.A. Quantitative Analysis of EM Image CharacteristicsImages are essentially discrete non-stationary signals thatcontain different frequency ranges and spatial location information. The wavelet transform can effectively preserve thisinformation while decomposing images. Specifically, we usethe wavelet transform to decompose the raw image I intoLF, horizontal HF, vertical HF and diagonal HF components(LL(I), HL(I), LH(I) and HH(I), respectively). Theycontain LF and different HF information of the raw image.The wavelet transform results of various images are shown inFigure 1 (b), including natural, medical, microscopic and EMimages.
我们通过小波变换分析了EM图像的特性,在III-A节中进行了描述。在III-B节中,我们提出了一种高频融合网络——GobletNet,以充分利用这些特性。
A. EM图像特性的定量分析
图像本质上是离散的非平稳信号,包含不同频率范围和空间位置信息。小波变换可以有效地在分解图像的同时保留这些信息。具体而言,我们使用小波变换将原始图像 I 分解为低频(LF)、水平高频(HF)、垂直高频(HF)和对角高频(HF)成分(分别为 LL(I), HL(I), LH(I) 和 HH(I))。这些成分包含了原始图像的低频和不同的高频信息。各种图像的小波变换结果如图1(b)所示,包括自然图像、医学图像、显微图像和EM图像。
Conclusion
结论
In this work, we quantitatively analyzed the high-frequencycharacteristics of EM images via the wavelet transform andidentified Characteristic 1 and Characteristic 2. To betterutilize these characteristics, we propose a wavelet-based highfrequency image fusion network, GobletNet, which achievesstate-of-the-art semantic segmentation of EM images. It wasconstructed based on encoder-decoder architecture without acomplex design or complicated training process, which ensurespracticality while achieving superior performance. The resultsof extensive experiments on seven public datasets demonstratethe effectiveness of our proposed model.
在这项工作中,我们通过小波变换定量分析了电子显微镜(EM)图像的高频特征,并识别了特征 1 和特征 2。为了更好地利用这些特征,我们提出了一种基于小波的高频图像融合网络——GobletNet,它在EM图像的语义分割中取得了最先进的成果。该网络基于编码器-解码器架构构建,设计简洁,训练过程不复杂,确保了其在实现卓越性能的同时具备实用性。对七个公共数据集的广泛实验结果验证了我们提出模型的有效性。
Figure
图
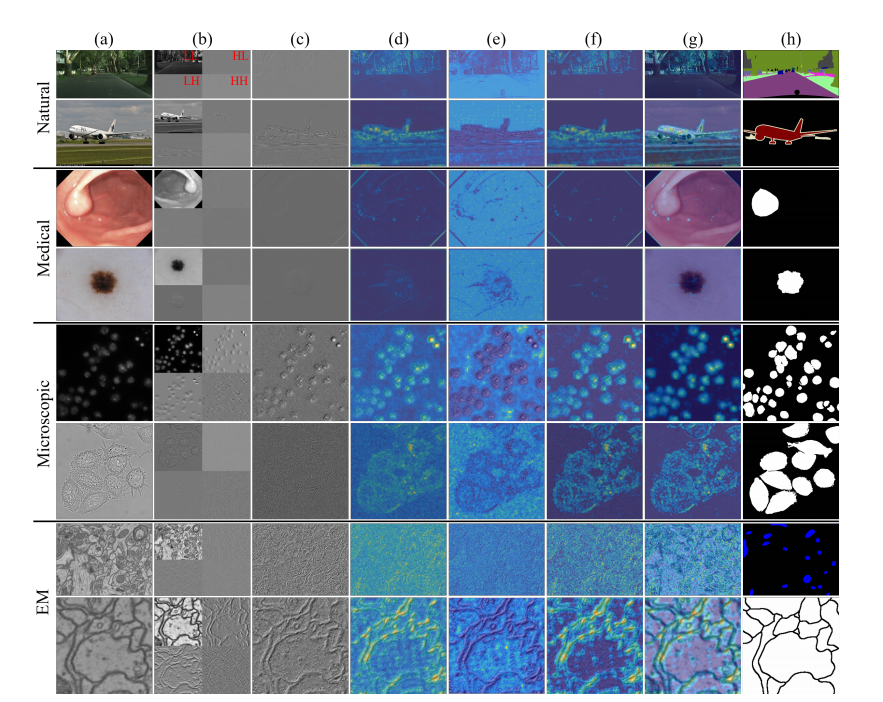
Fig. 1. Qualitative comparison of HF characteristics among natural, medical, microscopic and EM images. From top to bottom: Cityscapes [49],PASCAL VOC 2012 [50], Kvasir-SEG [51], ISIC-2017 [52], 2018 Data Science Bowl [53], DIC-C2DH-HeLa [54], EPFL [55] and CREMI [56]. Werandomly select images from each dataset for analysis and use Haar as the wavelet basis. We convert color images into grayscale images and thenapply the wavelet transform. (a) Raw images. (b) Wavelet transform results. (c) HF images. (d) Information richness heatmaps. (e) Noise intensityheatmaps. (f) Detailed distribution heatmaps. (g) Detailed distribution heatmaps (overlaid on raw images). (h) Ground truth
图1. 自然图像、医学图像、显微镜图像和电子显微镜(EM)图像中高频(HF)特性的定性比较。从上到下依次为:Cityscapes [49]、PASCAL VOC 2012 [50]、Kvasir-SEG [51]、ISIC-2017 [52]、2018 Data Science Bowl [53]、DIC-C2DH-HeLa [54]、EPFL [55]和CREMI [56]。我们从每个数据集中随机选择图像进行分析,并使用Haar小波作为小波基。我们将彩色图像转换为灰度图像,然后应用小波变换。(a)原始图像。(b)小波变换结果。(c)高频图像。(d)信息丰富度热图。(e)噪声强度热图。(f)详细分布热图。(g)详细分布热图(叠加在原始图像上)。(h)地面真值。

Fig. 2. Comparison of HF images with (λ = 0.4) and without (λ** =0.0) LF components on SNEMI3D [61]. (a) Raw image and wavelettransform results. (b) HF images. (c) Information richness heatmaps. (d)Noise intensity heatmaps. (e) Detailed distribution heatmaps. The redarrows highlight the difference in noise intensity.
图2. 带有(λ = 0.4)和不带有(λ = 0.0)低频(LF)成分的高频(HF)图像在SNEMI3D [61]上的比较。(a)原始图像和小波变换结果。(b)高频图像。(c)信息丰富度热图。(d)噪声强度热图。(e)详细分布热图。红色箭头突出显示噪声强度的差异。
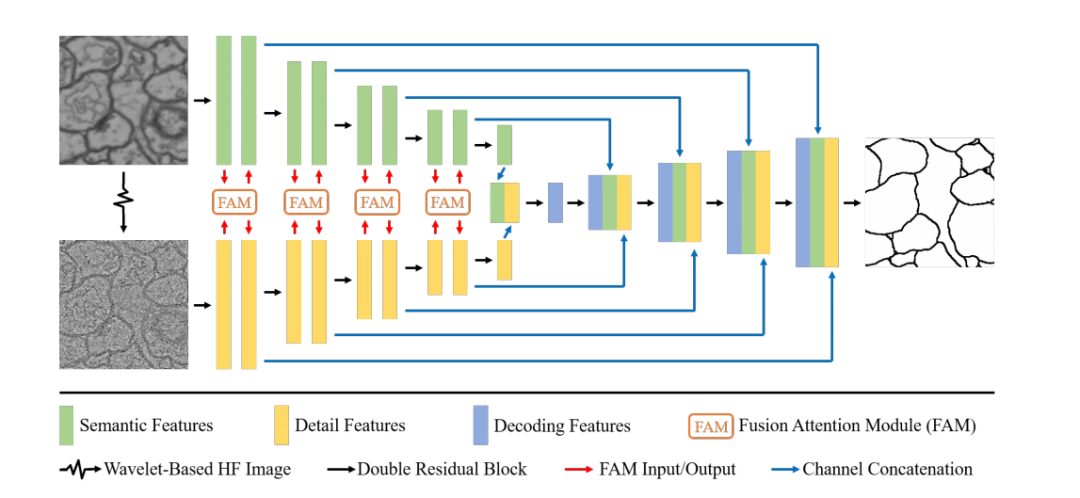
Fig. 3. Overview of GobletNet, which is composed of a semantic encoder, HF detail encoder, FAM and fusion decoder.
图3. GobletNet概览,包含语义编码器、高频(HF)细节编码器、融合注意力模块(FAM)和融合解码器。
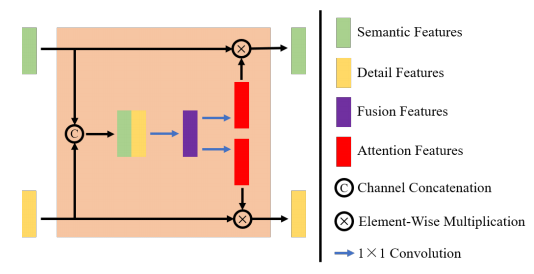
Fig. 4. Architecture of the FAM. The FAM is used for feature fusionbetween the semantic encoder and the HF detail encoder.
图4. 融合注意力模块(FAM)的架构。FAM用于语义编码器和高频(HF)细节编码器之间的特征融合。
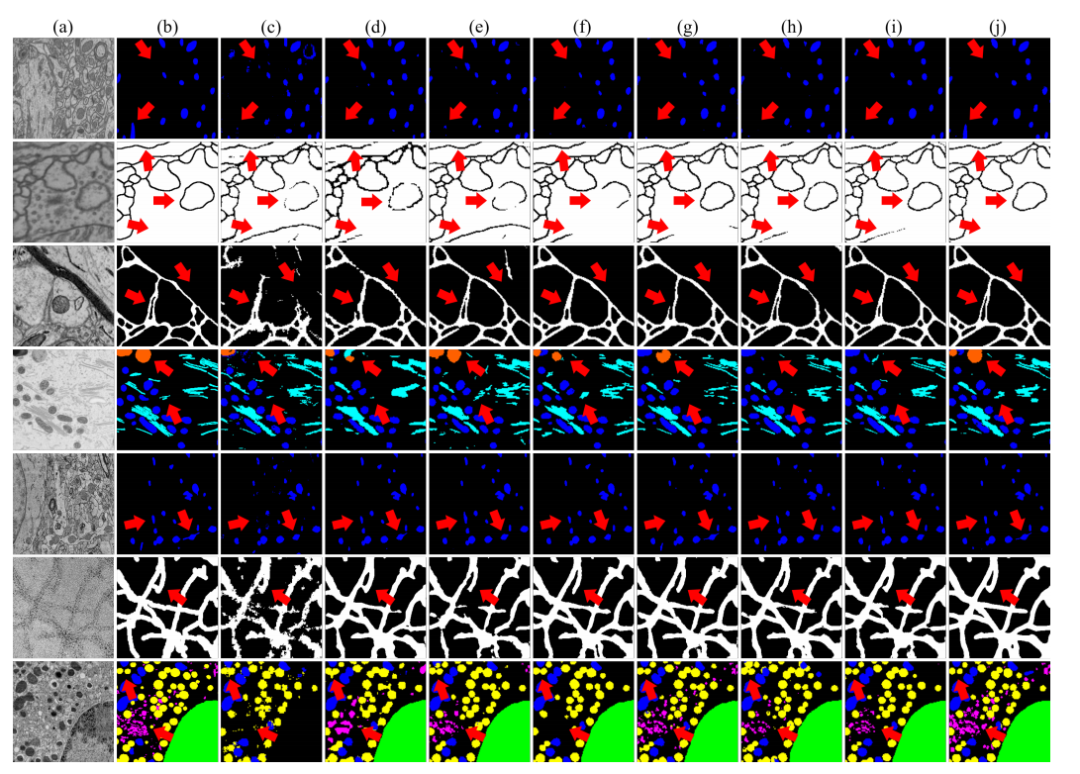
Fig. 5. Qualitative results of different models. From top to bottom: EPFL, CREMI, SNEMI3, UroCell, MitoEM, Nanowire and BetaSeg. (a) Rawimages. (b) Ground truth. (c) SAM. (d) Deeplab V3+. (e) UNet 3+. (f) FusionNet. (g) WaveSNet. (h) UNet. (i) nnUNet. (j) GobletNet. The red arrowshighlight the differences among the results.
图5. 不同模型的定性结果。从上到下:EPFL、CREMI、SNEMI3、UroCell、MitoEM、Nanowire和BetaSeg。(a)原始图像。(b)地面真值。(c)SAM。(d)DeepLab V3+。(e)UNet 3+。(f)FusionNet。(g)WaveSNet。(h)UNet。(i)nnUNet。(j)GobletNet。红色箭头突出显示结果之间的差异。
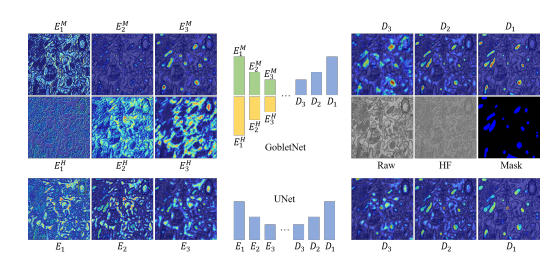
Fig. 6. Qualitative comparison of the class activation map of theencoders and decoders between UNet and GobletNet. We present thefirst three layers of encoders and the last three layers of decoders.For GobletNet, Ei M and Ei Hindicate the i-th layers of the semanticencoder and HF encoder, respectively. For UNet, Ei indicates the i-thlayer of the encoder. Di indicates the i-th layer of the decoder.
图 6:UNet 和 GobletNet 编码器和解码器的类别激活图的定性比较。我们展示了编码器的前三层和解码器的后三层。对于 GobletNet,EᵢM 和 EᵢH 分别表示语义编码器和高频编码器的第 i 层。对于 UNet,Eᵢ 表示编码器的第 i 层,Dᵢ 表示解码器的第 i 层。
Table
表
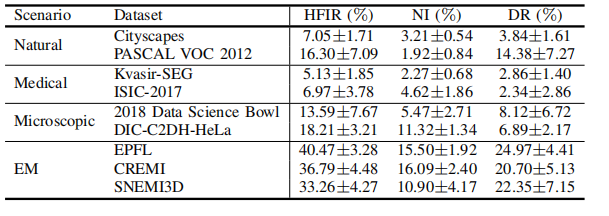
TABLE I quantitative comparison of hfir, ni and dr of datasets with different application scenarios.
表 I:具有不同应用场景的数据集的高频信息比率(HFIR)、噪声指数(NI)和分辨率(DR)的定量比较。
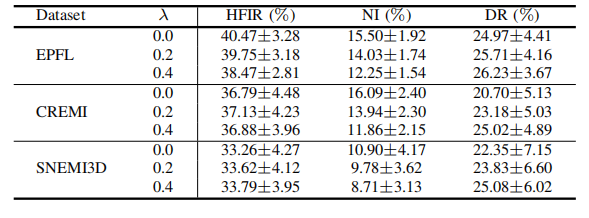
TABLE II quantitative comparison of hfir, ni and dr of em datasets with different lf weight λ values.
表 II:具有不同低频(LF)权重 λ 值的EM数据集的高频信息比率(HFIR)、噪声指数(NI)和分辨率(DR)的定量比较。

TABLE III imaging conditions and experimental setups of seven datasets. - indicates that the voxel size is not mentioned in the original paper. m - mitochondria, nm - neuronal membrane, e - endolysosome, f - fusiform vesicle, n - nanowire, g - golgi apparatus, cn - cell nucleus, and isg - insulin secretory granule.
表 III:七个数据集的成像条件和实验设置。表示原文中未提及体素大小。M-线粒体,NM-神经元膜,E-内溶酶体,F-梭形囊泡,N-纳米线,G-高尔基体,CN-细胞核,ISG-胰岛素分泌颗粒。
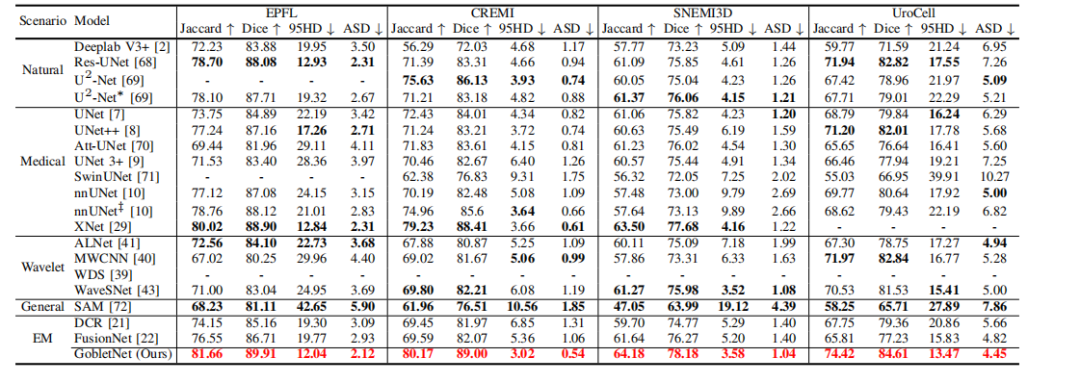
TABLE IV comparison with state-of-the-art models on the epfl, cremi, snemi3d, and urocell test sets. indicates a lightweight model. ‡ indicates training for 1000 epochs. - indicates that training failed. bold indicates the best performance in each scenario. red indicates the best performance among all models.
表 IV:与最先进模型在EPFL、CREMI、SNEMI3D和UROCELL测试集上的比较。表示轻量级模型。‡ 表示训练了1000个周期。表示训练失败。BOLD 表示每种场景中的最佳性能。RED 表示所有模型中的最佳性能。
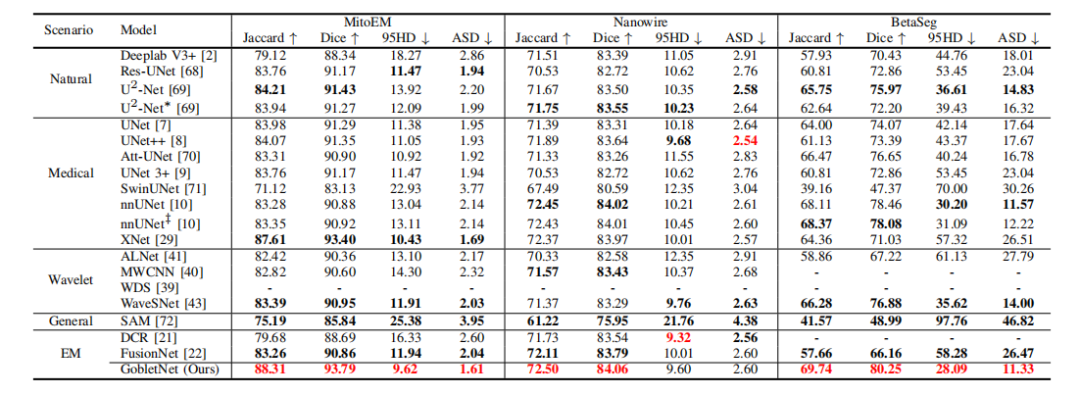
TABLE V comparison with state-of-the-art models on the mitoem, nanowire, and betaseg test sets. indicates a lightweight model. ‡ indicates training for 1000 epochs. - indicates that training failed. bold indicates the best performance in each scenario. red indicates the best performance among all models.
表 V:与最先进模型在MitoEM、Nanowire和BetaSeg测试集上的比较。表示轻量级模型。‡ 表示训练了1000个周期。表示训练失败。OLD 表示每种场景中的最佳性能。ED 表示所有模型中的最佳性能。

TABLE VI comparison of different values of the lf weight λ. the wavelet basis is db2.
表 VI:不同低频(LF)权重 λ 值的比较。小波基为DB2。

TABLE VII comparison of different wavelet bases.
表 VII:不同小波基的比较。

TABLE VIII comparison of different input strategies. l and h indicate the lf component and hf image, respectively, generated by the wavelet transform. h2 indicates using the second-level wavelet transform to generate the hf image. w/o indicates that no extra input is used. channel indicates using extra input as an extra channel of the raw images that are input into the model. branch indicates inputting the images into an extra encoding branch (i.e., an hf detail encoder) and using fam to fuse features.
表 VIII:不同输入策略的比较。L和 H 分别表示通过小波变换生成的低频(LF)成分和高频(HF)图像。H² 表示使用二级小波变换生成高频图像。W/O 表示没有使用额外输入。CHANNEL 表示将额外输入作为原始图像的额外通道输入到模型中。BRANCH 表示将图像输入到额外的编码分支(即高频细节编码器),并使用融合注意力模(FAM)来融合特征。
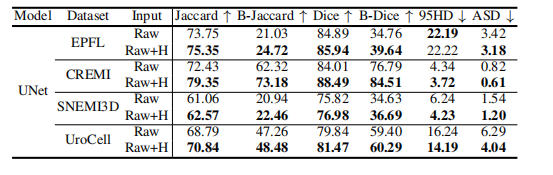
TABLE IX comparison of unet with and without hf images as extra input. raw indicates only using raw images as input. raw+h indicates using hf images as an extra channel of the raw images that are input into the model. b-jaccard and b-dice indicate the jaccard index and dice coefficient of the boundary pixels of segmentation objects.
表 IX:带有和不带有高频(HF)图像作为额外输入的UNet比较。RAW 表示仅使用原始图像作为输入。RAW+H 表示将高频(HF)图像作为原始图像的额外通道输入到模型中。B-JACCARD 和 B-DICE 分别表示分割对象边界像素的Jaccard指数和Dice系数。

TABLE Xcomparison of adding the fam into different layers. w/o indicates that the fam is not used in the model. shallow, middle, and deep indicate adding the fam into the shallow layer (first layer), middle layer (second and third layer), and deep layer (fourth layer), respectively, of the encoder. full indicates adding the fam into all layers of the encoder.
表 X:将FAM添加到不同层的比较。W/O 表示模型中未使用FAM。SHALLOW、MIDDLE 和 DEEP 分别表示将FAM添加到编码器的浅层(第一层)、中层(第层和第三层)和深层(第四层)。FULL 表示将FAM添加到编码器的所有层。
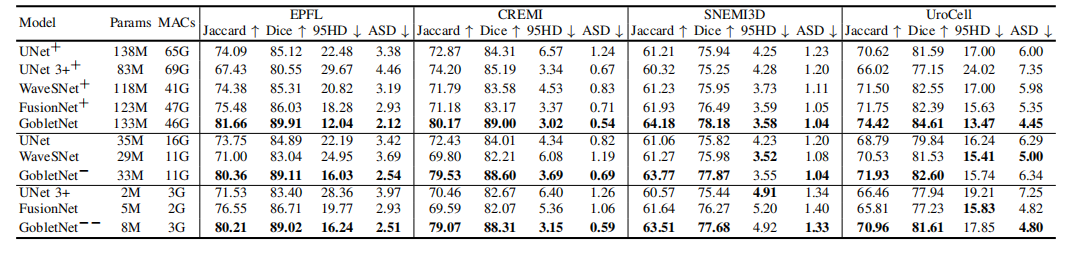
TABLE XI comparison of model size and computational cost. + indicates expanding the model size by increasing the number of feature channels. − and −− indicate reducing the model size by using half and a quarter of the feature channels, respectively.
表 XI:模型大小和计算成本的比较。+ 表示通过增加特征通道的数量来扩大模型大小。− 和 −− 分别表示通过使用一半和四分之一的特征通道来减少模型大小。

TABLE XII ablation of various components, including wavelet-based hf images, the extra coding branch of hf images and the fam.
表 XII:各组件的消融实验,包括基于小波的高频(HF)图像、高频图像的额外编码分支和FAM。
原文地址:https://blog.csdn.net/weixin_38594676/article/details/143747689
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!