项目/代码规范与Apifox介绍使用
目录
一、项目规范:
(一)项目结构:
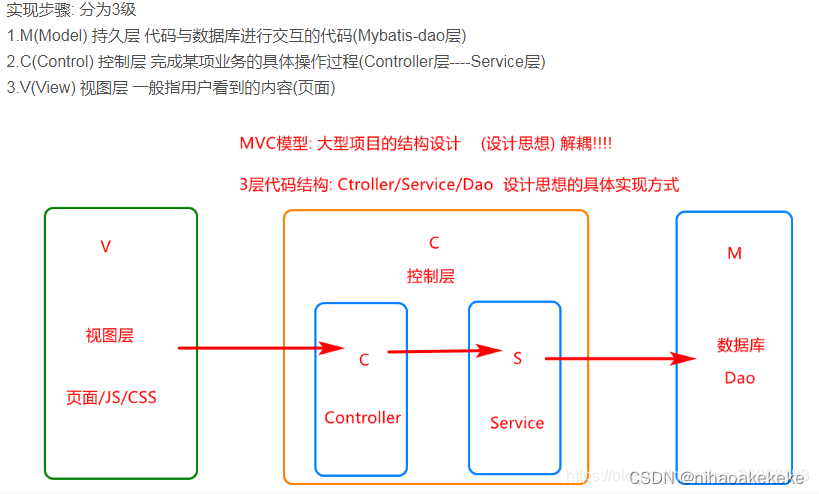
其中具体的:
(1)Entity层:实体层,就是存放具体的对象实体,与数据库中的对象相对应。
(2)DAO层:(可以细分两层(dao的接口层与dao的实现层))就是与数据库进行交互的层,涉及到一些数据库的增删改查操作。
(3)Service层(可以细分两层(service的接口层与service的实现层)):主要负责业务模块的逻辑应用设计。
(4)Controller层:Controller层负责具体的业务模块流程的控制,controller层负责前后端交互,接受前端请求,调用service层,接收service层返回的数据,最后返回具体的页面和数据到客户端。
(5)Util层:工具层,放置常用的工具类,比如可以把一些通用的方法写成一个util的函数,然后可以简化整体的代码。
(6)Exception层:可以写一下统一的返回异常层。
(7)Filter层:过滤层,比如统一过滤一下身份验证,如果没有过滤通过,则只是游客模式。
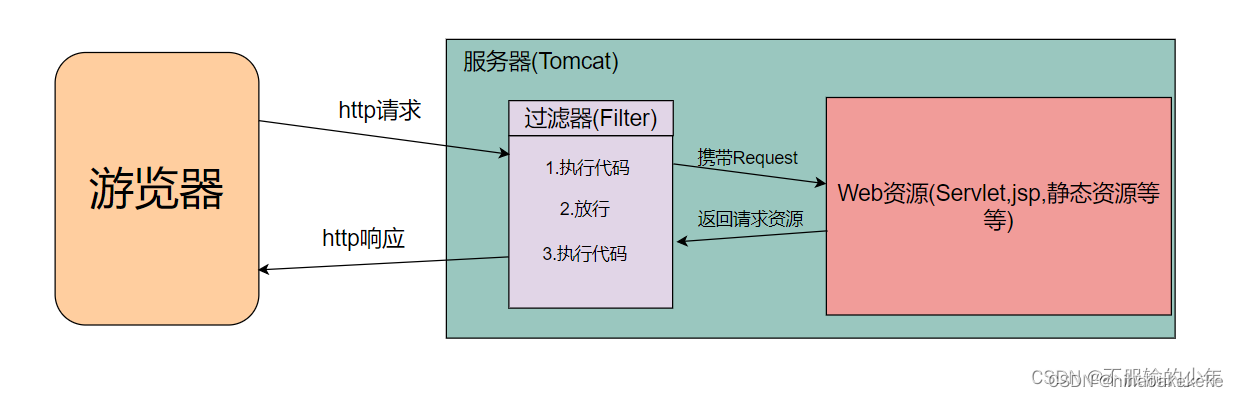
(二)传送的数据对象体
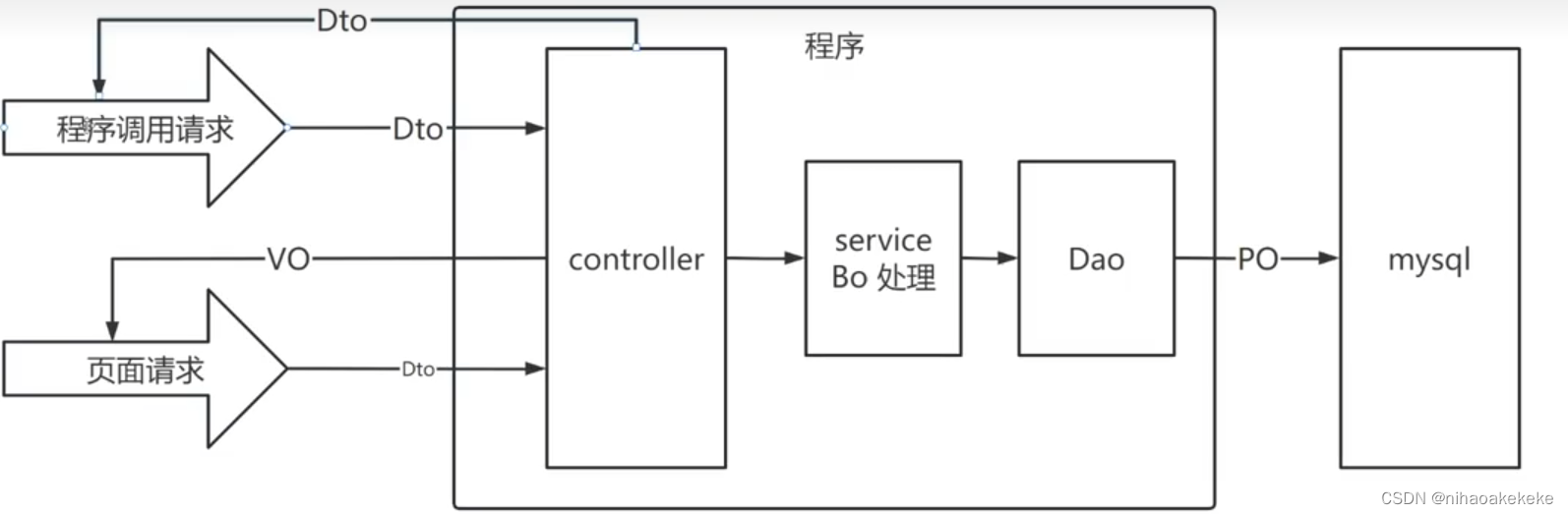
DTO就是前端发送请求传来的数据结构体。
VO就是后端针对前端发送的请求进行返回的响应。
PO就是对象实体和数据库对象这个表的实际对应关系。
BO就是在业务处理过程中的对象实体。
二、代码规范:
要英文命名,不要汉语拼音。
要通俗易懂,不要花里胡哨。
要驼峰命名,不要平平范范。
要间隔换行,不要大段书写。
要注释注解,不要个人主义。
不要用关键字、保留字等在java本身有特殊含义的 命名!!!
(一)数据库命名规范:
(1)表名是唯一的,不能多个表命名使用同一个名称。
(2)表名采用小写字母和下划线的组合形式,尽量避免使用大写字母或特殊字符,含义清晰,使用“user_info”类似这种,或者“tbl_user”,"tbl_user_info"这种。
(3)不要与关键字冲突,禁用保留字,如 like、desc、range、match、delayed 等,请参考 MySQL 官方保留字。
(4)数据库字段名:采用26个英文字母(区分大小写)加上下划线'_'组成,例如“user_id","user_name","user_password","user_register_time","user_login_time".
(5)主外键规范:
主键:pk_+表名
例如:pk_main
外键:fk_+从表名+_+主表名
例如:fk_sub_main
(二)注释规范:
(1)类注释:
类注释(Class)主要用来声明该类用来做什么,以及创建者、创建日期版本、包名等一些信息:
/**
* @version: V1.0
* @author: fendo
* @className: user
* @packageName: user
* @description: 这是用户类
* @data: 2024-07-01 12:20
**/
(2)方法注释(Constructor):
/**
* @author: fendo
* @methodsName: addUser
* @description: 添加一个用户
* @param: xxxx
* @return: String
* @throws:
*/
(3)代码块注释:解释你某一部分代码的用途
/**
* 实例化一个用户
* xxxxxxx
*/
User user=new User();
(4)单句注释:注释你单独的代码
User user=new User(); //实例化一个用户
(三)命名规范:
例如:UserController,FileController,BookService
例如:getUserName(),userLogin(),getMessage();
例如:MAX_STOCK_COUNT / CACHE_EXPIRED_TIME
1)获取单个对象的方法用 get 做前缀。2)获取多个对象的方法用 list 做前缀,复数结尾,如:listObjects3)获取统计值的方法用 count 做前缀。4)插入的方法用 save / insert 做前缀。5)删除的方法用 remove / delete 做前缀。6)修改的方法用 update 做前缀。
1)数据对象:xxxDO,xxx 即为数据表名。2)数据传输对象:xxxDTO,xxx 为业务领域相关的名称。3)展示对象:xxxVO,xxx 一般为网页名称。
用已有对象,这是一个大坑,推荐使用 equals 方法进行判断。
正例:(1)指定一个误差范围,两个浮点数的差值在此范围之内,则认为是相等的。float a = 1.0F - 0.9F ;float b = 0.9F - 0.8F ;float diff = 1e-6F ;if ( Math . abs ( a - b ) < diff ) {System . out . println ( "true" );}(2)使用 BigDecimal 来定义值,再进行浮点数的运算操作。BigDecimal a = new BigDecimal ( "1.0" );BigDecimal b = new BigDecimal ( "0.9" );BigDecimal c = new BigDecimal ( "0.8" );BigDecimal x = a . subtract ( b );BigDecimal y = b . subtract ( c );if ( x . compareTo ( y ) == 0) {System . out . println ( "true" );}
| 标识符类型 | 命名规则 | 例子 |
| 包(Packages) | 一个唯一包名的前缀总是全部小写的ASCII字母并且是一个顶级域名,通常是com,edu,gov,mil,net,org,或1981年ISO 3166标准所指定的标识国家的英文双字符代码。包名的后续部分根据不同机构各自内部的命名规范而不尽相同。这类命名规范可能以特定目录名的组成来区分部门(department),项目(project),机器(machine),或注册名(login names)。 | com.sun.eng com.apple.quicktime.v2 edu.cmu.cs.bovik.cheese |
| 类(Classes) | 命名规则:类名是个一名词,采用大小写混合的方式,每个单词的首字母大写。尽量使你的类名简洁而富于描述。使用完整单词,避免缩写词(除非该缩写词被更广泛使用,像URL,HTML) | class Raster; class ImageSprite; |
| 接口(Interfaces) | 命名规则:大小写规则与类名相似 | interface RasterDelegate; interface Storing; |
| 方法(Methods) | 方法名是一个动词,采用大小写混合的方式,第一个单词的首字母小写,其后单词的首字母大写。驼峰命名 | run(); runFast(); getBackground(); |
| 变量(Variables) | 除了变量名外,所有实例,包括类,类常量,均采用大小写混合的方式,第一个单词的首字母小写,其后单词的首字母大写。变量名不应以下划线或美元符号开头,尽管这在语法上是允许的。 变量名应简短且富于描述。变量名的选用应该易于记忆,即,能够指出其用途。 | List <User> userList; String userName; |
| 常量(Constants) | 类常量和ANSI常量的声明,应该全部大写,单词间用下划线隔开。(尽量避免ANSI常量,容易引起错误) | static final int MIN_WIDTH = 4; static final int MAX_WIDTH = 999; static final int GET_THE_CPU = 1; |
(四)前后端规范:
a)GET:从服务器取出资源。 (可以看作select操作)b)POST:在服务器新建一个资源。 (可以看作insert操作)c)PUT:在服务器更新资源。 (可以看作update操作)d)DELETE:从服务器删除资源。 (可以看作delete操作)
code:http的status code- 如果有自己定义的额外的错误,那么也可以考虑用自己定义的错误码
message:对应的文字描述信息- 如果是出错,则显示具体的错误信息
- 否则操作成功,一般简化处理都是返回OK
data- 对应数据的json字符串
- 如果是数组,则对应最外层是[]的
list - 如果是对象,则对应最外层是{}的
dict
- 如果是数组,则对应最外层是[]的
- 对应数据的json字符串
{
"code": 200,
"message": "new user has created",
"data": {
"id": "user-4d51faba-97ff-4adf-b256-40d7c9c68103",
"firstName": "crifan",
"lastName": "Li",
"password": "654321",
"phone": "13511112222",
"createdAt": "2016-10-24T20:39:46",
"updatedAt": "2016-10-24T20:39:46"
......
}
}(3)响应的状态码
出错问题:
- 1xx(信息性状态码):表示接收的请求正在处理。
- 2xx(成功状态码):表示请求正常处理完毕。 200就是请求返回成功。
- 3xx(重定向状态码):需要后续操作才能完成这一请求。
- 4xx(客户端错误状态码):表示请求包含语法错误或无法完成。 400 404 401 403 都是前端发送请求时候出的错误,前端先要查看问题,也有可能是后端写的出了错误。
- 5xx(服务器错误状态码):服务器在处理请求的过程中发生了错误。 后端问题,有可能抛出异常,服务器错误等等。
2XX 成功
200 ok(请求成功)
204 no content (请求成功,但是没有结果返回)
206 partial content (客户端请求一部分资源,服务端成功响应,返回一范围资源)
3XX 重定向
301 move permanently (永久性重定向)
302 found (临时性重定向)
303 see other (示由于请求对应的资源存在着另一个 URI,应使用 GET
方法定向获取请求的资源)
304 not modified (表示在客户端采用带条件的访问某资源时,服务端找到了资源,但是这个请求的条件不符合。跟重定向无关)
307 temporary redirect (跟302一个意思)
4XX 客户端错误
400 bad request (请求报文存在语法错误)
401 unauthorized (需要认证(第一次返回)或者认证失败(第二次返回))
403 forbidden (请求被服务器拒绝了)
404 not found (服务器上无法找到请求的资源)
5XX 服务器错误
500 internal server error (服务端执行请求时发生了错误)
503 service unavailable (服务器正在超负载或者停机维护,无法处理请求)
(五)其他规范:
说明: nginx 默认限制是 1MB,tomcat 默认限制为 2MB,当确实有业务需要传较大内容时,可以调大服务器端的限制。
说明: try 块中的 return 语句执行成功后,并不马上返回,而是继续执行 finally 块中的语句,如果此处存在 return 语句, 则会在此直接返回,无情丢弃掉 try 块中的返回点。
三、Apifox使用:
(一)下载与安装:
链接:点击链接,直接下载apifox(下载最新版就行)。Apifox - API 文档、调试、Mock、测试一体化协作平台。拥有接口文档管理、接口调试、Mock、自动化测试等功能,接口开发、测试、联调效率,提升 10 倍。最好用的接口文档管理工具,接口自动化测试工具。![]() https://apifox.com/
https://apifox.com/

(二)新建项目与邀请你的队友:
1.新建你的团队与新建项目:

邀请你的队友
2.新建接口与新建数据模型:
(1)确定好是什么请求(POST,GET,PUT,DELETE):
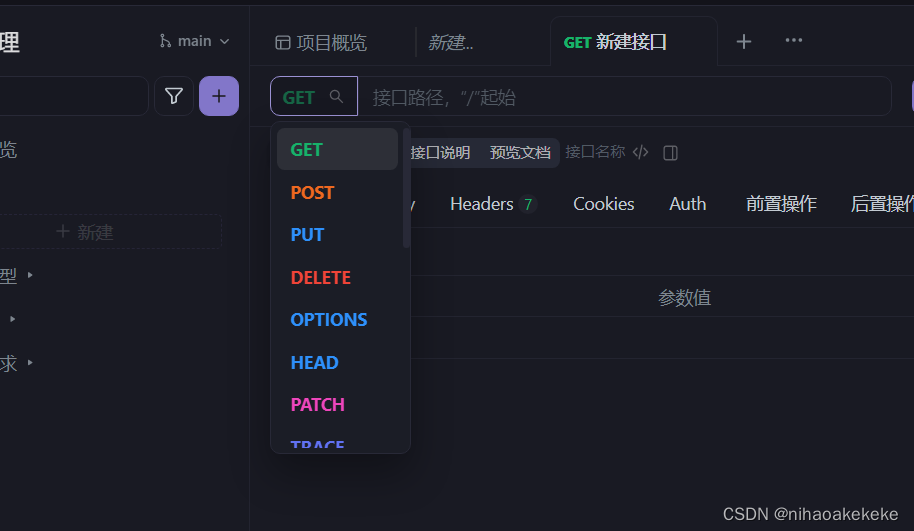
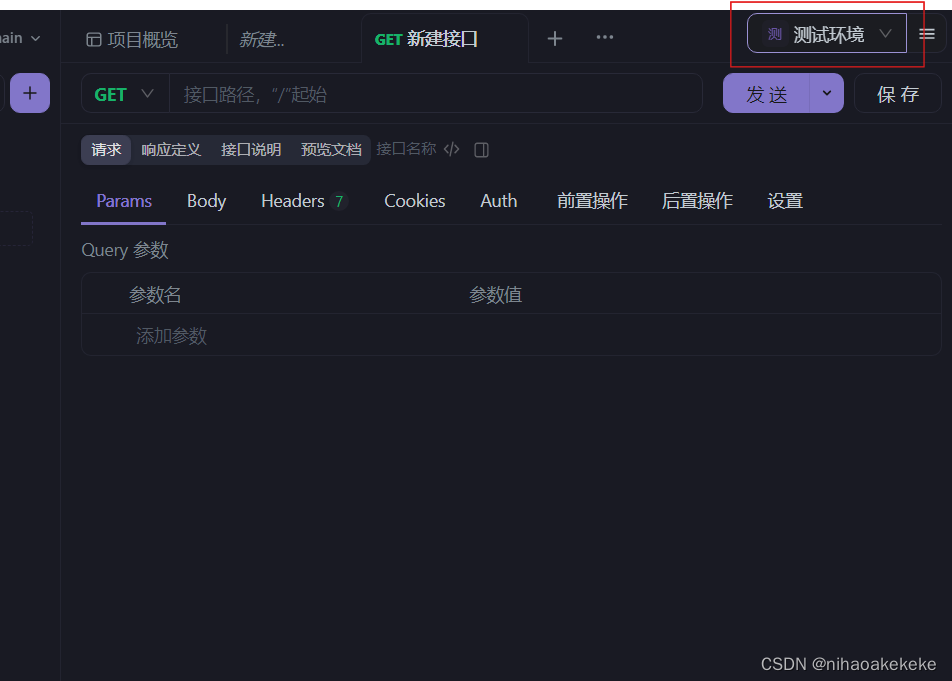
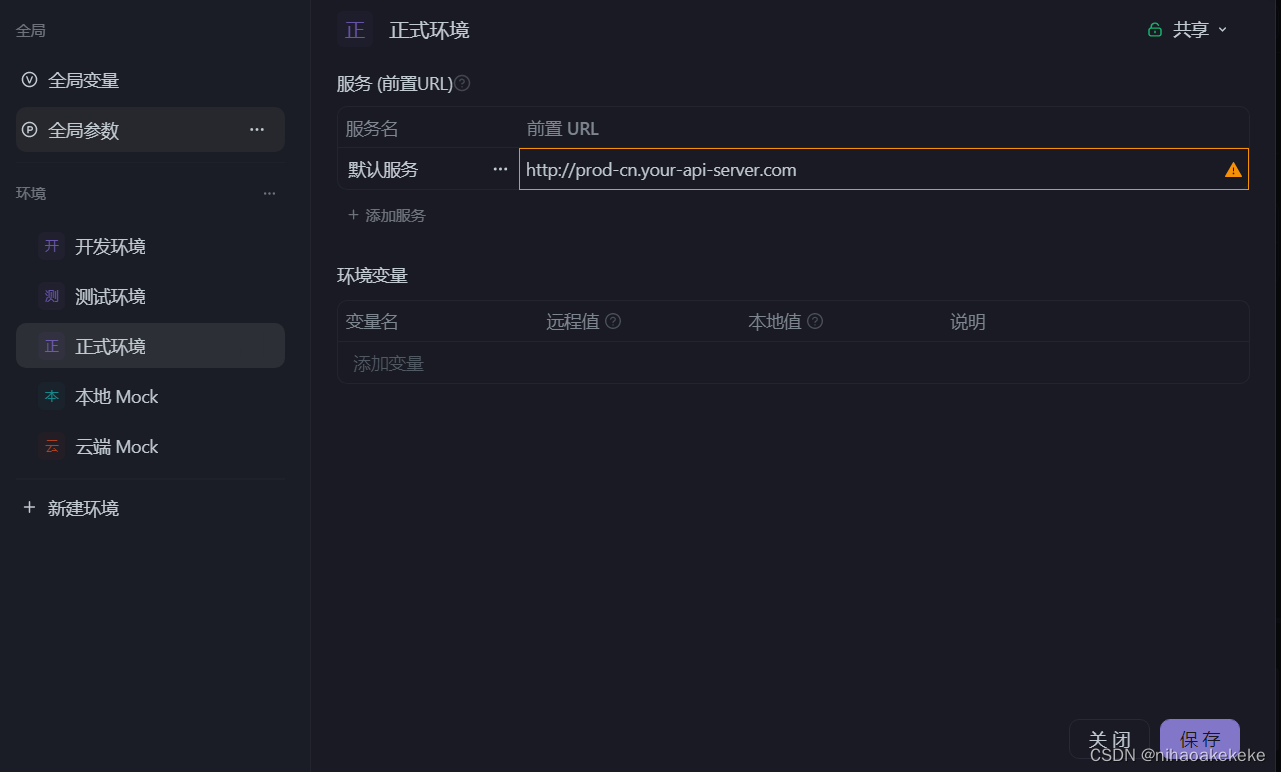
(2)测试环境一定统一好,不同的环境url不一样:
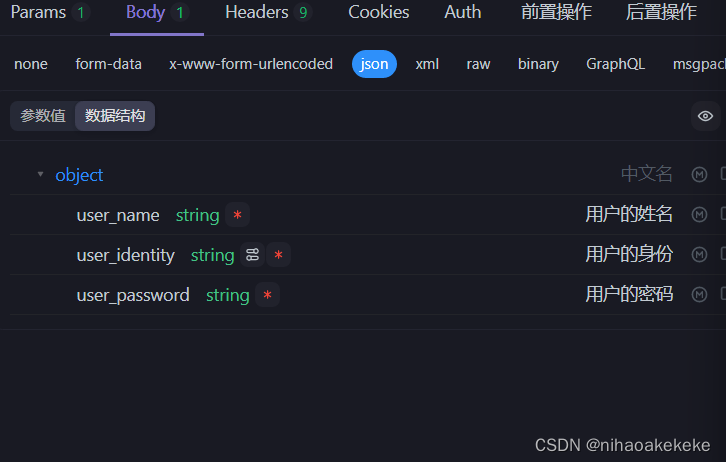
(3)请求参数配置好:
有什么参数配置什么参数,给出参数示例,中文名,参数说明要有。
(4)响应要配置好:
比如不同的状态下返回什么样子的信息要规定好,成功示例,异常示例要有(方便前端)。
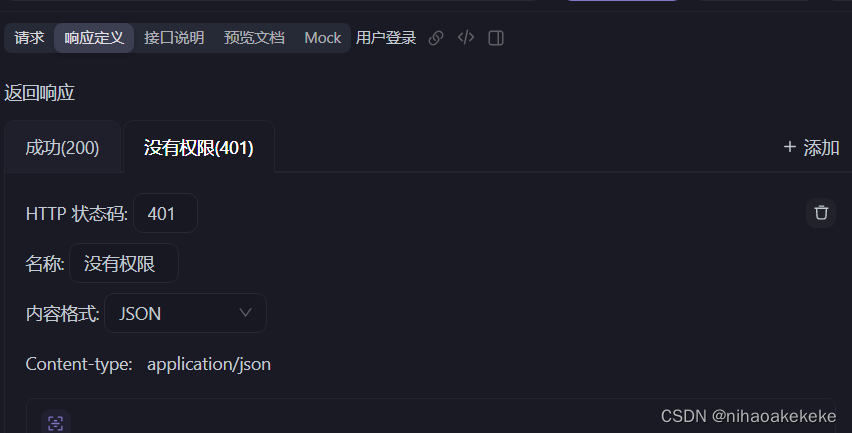
{
"code": 200,
"message": "登入成功",
"data": {
"user_id": 27,
"user_name": "孟霞",
"user_password": "123456",
"user_age": "15",
"user_photo": "http://dummyimage.com/400x400",
"user_last_time": "1996-12-11 09:03:49",
"user_indentity": "messager",
"user_birthday": "2024-02-23"
}
}(5)可以创建数据模型:
可以创建几个数据模型,在返回响应字段的适合很方便,也方便前端查看你的数据域东西。

(三)接口文档的书写规范
apifox的书写规范、与具体细节。
Apifox 快速入门 | Apifox 帮助文档![]() https://apifox.com/help/
https://apifox.com/help/
(1)在 API 接口文档的开头,应该有一部分介绍。这部分可以包括以下内容:
- API 接口的名称和版本号
- API 接口的功能和用途
- API 接口的设计目的和原则
- API 接口的适用范围和限制
这部分的目的是为了让读者了解该 API 接口的基本情况和背景信息。
(2)接口列表
接着,在 API 接口文档中,我们需要列出所有的接口。每个接口应该包含以下信息:
- 接口名称和描述
- 请求方法(GET、POST、PUT、DELETE 等)
- 请求路径(URL)
- 请求参数(包括 Query 参数和 Body 参数)
- 请求示例(可以包含请求头和请求体的完整示例)
- 响应状态码和描述
- 响应参数(包括 Header 参数和 Body 参数)
- 响应示例(可以包含响应头和响应体的完整示例)
这部分的目的是为了让读者能够快速了解每个接口的基本信息,并且能够根据文档中的示例来正确地使用接口。
(3) 请求参数和响应参数说明
在接口列表之后,我们需要详细说明每个接口的请求参数和响应参数。这部分应该包括以下信息:
- 参数名称和描述
- 参数类型和格式
- 是否必填和默认值
- 参数示例
对于参数类型和格式,可以使用标准的数据类型和格式,也可以根据具体情况定义自己的数据类型和格式。对于是否必填和默认值,需要根据实际情况来确定。
(4) 错误码说明
在使用 API 接口时,有时候会发生错误,此时需要返回一个错误码来说明错误的类型和原因。因此,在 API 接口文档中,我们需要详细说明所有可能的错误码。这部分应该包括以下信息:
- 错误码和描述
- 错误类型和原因
- 接口返回的错误码示例
这部分的目的是为了让读者了解所有可能的错误类型和原因,并且能够根据文档中的示例来正确地处理错误。

四、Debug功能(后端必须要会)
五、测试类
(1)具体的操作:
定义一个测试类
建议:
测试类名:被测试的类名Test CalculatorTest
包名:xx.xx.xx.test cn.itcast.test
定义测试方法:可以独立运行
建议:
方法名:test测试的方法名 testAdd()
返回值:void
参数列表:空参
给方法加 @Test
导入Junit依赖环境
判定结果:
红色:失败
绿色:成功
我们一般使用Assert类下的静态方法assertEquals(expected, actual)去处理我们的期望结果和输出结果
Assert.assertEquals(3, result);
两个参数分别是:期望值 程序结果值
为什么要使用Assert.assertEquals(expected, actual)去处理测试结果呢?
因为我们规定红色代表失败,绿色代表正确。当我们使用一个测试方法去测试一个计算机的加法方法时,最后只是输出这个结果(假如没有异常的发生)。如果我们输入1和3,我们期望得到结果4,但是我们输出的是2,我们期望得到的是4,这个时候得到的结果不符合我们的预期,但是运行结果仍然是绿色的(代表正确),是不是就不太正确,这个时候我们可以在最后使用Assert的assertEquals方法比较预期值和程序输出的结果值,如果相等,就会使绿色的,不相等就是红色的。这个时候是不是就符合我们对绿色和红色的定义了。
package cn.itcast.test;
import cn.itcast.junit.Calculator;
import org.junit.Assert;
import org.junit.Test;
public class CalculatorTest {
/**
* 测试add方法
*/
@Test
public void testAdd(){
Calculator c = new Calculator();
int a = 1, b = 2;
int result = c.add(1, 2);
Assert.assertEquals(3, result);
}
/**
* 测试sub方法
*/
@Test
public void testSub(){
Calculator c = new Calculator();
int a = 1, b = 2;
int result = c.sub(1, 2);
Assert.assertEquals(-1, 2);
}
}
@Before
在一个测试方法之前加上@Before它就成为了初始化方法,在所有测试方法执行之前都会自动先执行该方法,一般用于资源的申请
@After
在一个测试方法之前加上@After它就成为了释放资源方法,在所有测试方法执行之后都会自动执行该方法。
被@Before修饰的方法会在测试方法执行之前先被执行
被@After修饰的方法会在测试方法执行之后被执行
被@Before或被@After修饰的方法无论测试方法是否出一场都会执行
(2)自动生成Test类插件
Java 项目自动生成单元测试插件推荐-腾讯云开发者社区-腾讯云 (tencent.com)![]() https://cloud.tencent.com/developer/article/1910893
https://cloud.tencent.com/developer/article/1910893
原文地址:https://blog.csdn.net/nihaoakekeke/article/details/140095687
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!