Clip下游任务解读
相关代码链接见文末
1.DALL-1
(1)VQGAN
https://arxiv.org/pdf/2012.09841.pdf
VQGAN(Vector Quantized Generative Adversarial Networks)是一种基于向量化量化的生成对抗网络。这种技术首先将图像转换为一系列向量,每个向量代表图像中的一小块区域(或称为“patch”)。这些向量随后被量化,意味着它们的值被限制在一个预定义的代码本中的条目。通过这种方式,VQGAN能够在压缩图像信息的同时保留关键特征,这对于后续的图像生成任务至关重要。
在图像生成任务中,VQGAN和CLIP可以携手合作。VQGAN作为生成器,负责根据给定的条件或随机噪声生成图像。而CLIP则作为判断器,评估生成的图像是否与给定的文本描述相匹配。通过不断地迭代和优化,这个系统能够生成与文本描述高度一致的图像。
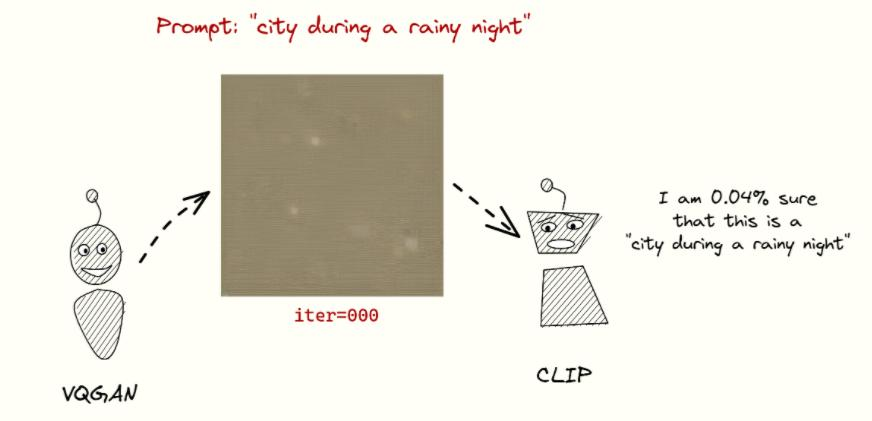
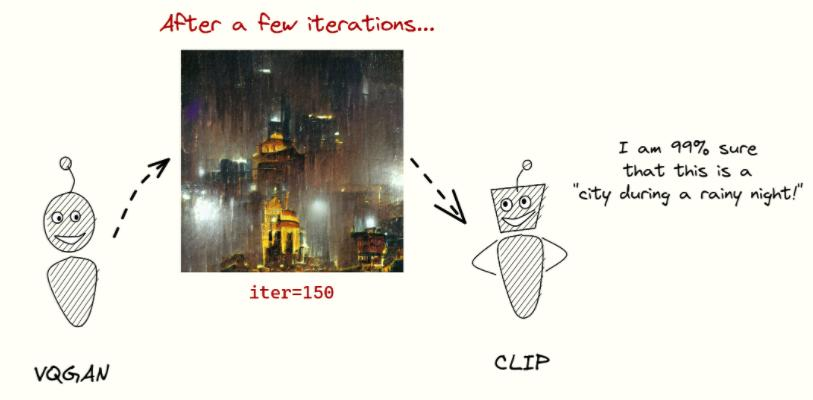
图像表示
我们尝试用语言去描述一个事物时,我们通常会先抓住其主要特征,然后尝试用准确且生动的语言进行表达。在你给出的例子中,“白色的”,“俩耳朵”,“瞅我呢”是描述这个“小家伙”的关键词。
原文地址:https://blog.csdn.net/qq_52053775/article/details/137711314
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!