Elasticsearch 检索优化:停用词的应用
Elasticsearch 检索优化:停用词的应用
场景描述
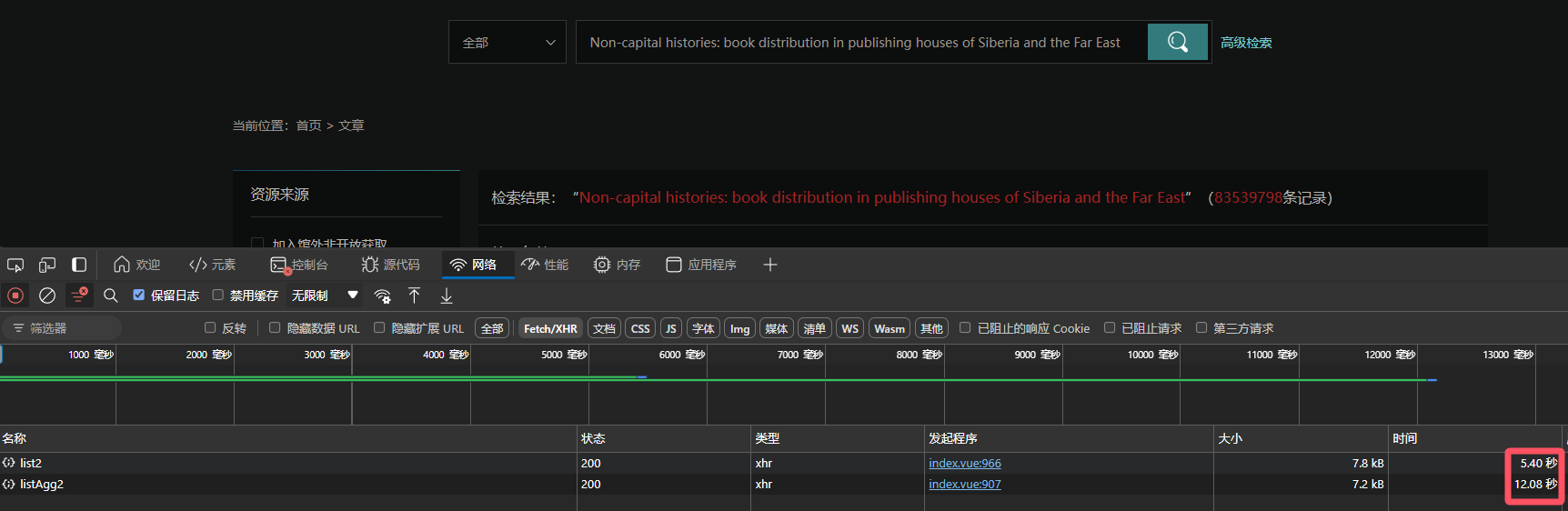
目前在 Elasticsearch 集群中存储约 1.5 亿篇文章数据,随着数据量的增加,检索性能问题逐渐显现。在列表检索和聚合操作中,CPU 消耗飙升至 100%,并且检索耗时较长:
- 列表检索耗时:5+ 秒
- 聚合检索耗时:12+ 秒
- 索引大小:623.40GB
实例
一个典型的检索词为:
Non-capital histories: book distribution in publishing houses of Siberia and the Far East
如果去除掉常见的无意义词(如 “the”、“in”、“of” 等),检索耗时从几秒缩短到毫秒级别。
优化前检索结果
优化后检索结果

问题分析
由于索引中没有设置停用词,导致检索词中的常见无意义词(如 “the”, “in”, “of”)被大量存储和匹配。这些词出现频率极高,却没有任何实质意义,导致大量不必要的 CPU 和内存消耗。通过启用停用词过滤,可以有效减少索引大小和检索时间。
测试停用词的使用
可以通过 /_analyze API 来测试停用词的效果,使用 stop 过滤器去除无意义词汇:
POST /_analyze
{
"tokenizer": "standard",
"filter": [
"stop"
],
"text": "in publishing houses of Siberia and the Far East"
}
返回结果(停用词被去除):
{
"tokens": [
"publishing",
"houses",
"Siberia",
"Far",
"East"
]
}
停用词的配置
官方停用词列表
Elasticsearch 内置了多种语言的停用词列表,Lucene 项目提供了详细的停用词集合,如以下英文停用词:
static {
final List<String> stopWords =
Arrays.asList(
"a", "an", "and", "are", "as", "at", "be", "but", "by", "for", "if", "in", "into", "is",
"it", "no", "not", "of", "on", "or", "such", "that", "the", "their", "then", "there",
"these", "they", "this", "to", "was", "will", "with");
final CharArraySet stopSet = new CharArraySet(stopWords, false);
ENGLISH_STOP_WORDS_SET = CharArraySet.unmodifiableSet(stopSet);
}
配置自定义分析器
在 Elasticsearch 中,可以通过修改索引的 settings 来定义自定义分析器,并为其添加停用词过滤器。
PUT /my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "whitespace",
"filter": [ "stop" ]
}
}
}
}
}
可以通过 stopwords 参数指定停用词列表,支持内置语言值或自定义停用词文件。
自定义停用词过滤器
如果内置的停用词列表不满足需求,可以自定义停用词过滤器。例如,以下配置定义了一个区分大小写的停用词过滤器:
PUT /my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"tokenizer": "whitespace",
"filter": [ "my_custom_stop_words_filter" ]
}
},
"filter": {
"my_custom_stop_words_filter": {
"type": "stop",
"ignore_case": true,
"stopwords": [ "and", "is", "the" ]
}
}
}
}
}
索引配置优化
在实际使用中,可以结合停用词过滤器调整索引配置。例如,下面的索引配置应用了自定义停用词过滤器,并且将 analyzer 设置为 cx_analyzer:
{
"settings": {
"number_of_shards": 30,
"number_of_replicas": 0,
"analysis": {
"filter": {
"stop_filter": {
"type": "stop",
"ignore_case": true,
"stopwords": "_english_"
}
},
"analyzer": {
"cx_analyzer": {
"tokenizer": "standard",
"filter": [ "stop_filter" ]
}
}
}
},
"mappings": {
"properties": {
"digest": {
"type": "text",
"analyzer": "cx_analyzer"
}
}
}
}
重建索引及数据迁移
由于 Elasticsearch 的索引是不可修改的(特别是分析器相关配置),因此需要通过以下步骤应用新配置:
- 创建新索引:使用新配置创建一个新索引。
- 迁移数据:使用 Reindex API 或编写脚本将数据从旧索引迁移到新索引。
使用 Reindex API 将旧索引的数据迁移至新索引:
POST _reindex?slices=20&refresh
{
"source": {
"index": "index_v1",
"size": 5000
},
"dest": {
"index": "index_v2"
}
}
优化后的检索性能
经过停用词配置后,数据检索性能得到了显著提升:
| 索引 | 索引大小 | 列表检索时间 | 聚合检索时间 |
|---|---|---|---|
| 原始索引 | 623.40GB | 5+ 秒 | 12+ 秒 |
| 停用词优化后的新索引 | 460.95GB | 1.06 秒 | 1.23 秒 |
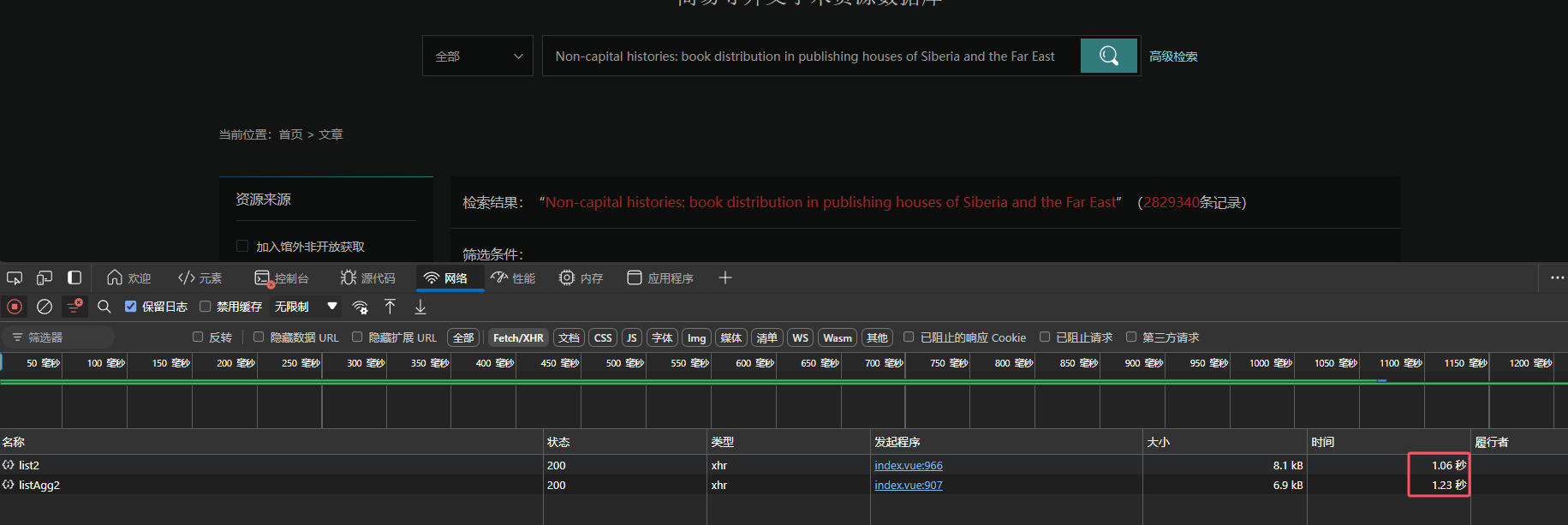
停用词对性能的提升
停用词是指那些在文本中出现频率较高、但对搜索意义较小的词汇,例如 “the”、“is”、“a” 等。在建立索引时,通过忽略这些词可以减少索引体积,并加快查询速度。
- 减少索引体积:外文数据中包含大量无关的停用词,这些词汇如果被索引,会产生大量冗余信息。排除停用词后,索引体积显著缩小。
- 减少倒排索引的计算:每次查询时,Elasticsearch 都会通过倒排索引查找相关文档。停用词的高频率出现会增加计算量。排除停用词后,查询时可以跳过这些无意义的文档筛选和打分操作,从而提高效率。
- 提高查询相关性:去除停用词后,查询集中在有意义的词汇上,结果更加相关。
- 减少聚合计算量:在聚合操作中,停用词如果被索引,可能导致无意义的分组和计算。移除它们后,聚合性能大幅提升。
原文地址:https://blog.csdn.net/qq_29864051/article/details/142410878
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!