SAM-Lightening: Lightweight Segment Anything Model with Dilated Flash Attention
SAM-Lightening: Lightweight Segment Anything Model with Dilated Flash Attention
PDF: https://arxiv.org/pdf/2403.09195.pdf
代码:https://anonymous.4open.science/r/SAM-LIGHTENING-BC25
通过将自注意力操作符蒸馏成具有动态层次蒸馏的Dilated Flash Attention,SAM-Lightening在图像上完成推理平均每张仅需7ms,实现了比SAM-ViT-H快30.1倍的速度提升。
1 概述
SAM-Lightening通过引入一种高效、轻量级的模型,实现了图像分割的革命性突破,该模型与 SAM 相比,处理速度提高了30倍。该模型采用新的Dilated Flash Attention机制,能够实现快速推理和最小化内存使用,非常适用于实时环境和资源受限设备的应用。
本文的主要贡献在于以下四个方面:
-
首先,创新性地引入了一种新型的SAM结构——SAM-Lightening,通过精简设计,显著降低了计算复杂性,为实时图像分割任务提供了高效支持。
-
其次,设计了一种独特的Dilated Flash Attention机制,以替代传统的自注意力机制,大幅提升了SAM-Lightening的效率和推理速度,使其在资源受限的环境中也能表现出色。
-
第三,为有效实现知识从普通SAM到SAM-Lightening的传递,本文提出了一种创新的动态分层蒸馏方法,既保证了知识传承的完整性,又未对性能产生任何负面影响。
-
最后,SAM-Lightening在实验中展现出令人瞩目的性能,每张图像处理速度仅需7毫秒,相比普通SAM,速度提升了惊人的30.1倍,充分验证了其在实际应用中的显著优势和潜力。
2 SAM-Lightening

2-1 Dilated Flash Attention
Segmentation and Sparsification:
为了降低注意力操作中的计算负担,SAM-Lightening采用了一种巧妙的策略:它将每个输入数据分成若干相等长度的部分,然后在每个部分的序列维度上实施稀疏化处理。这种稀疏化操作的关键在于,它仅在固定间隔的位置选择特定的行,从而显著减少了注意力机制所需处理的数据量:

其中,
X
~
i
\widetilde{X} _{i}
X
i代表采样的稀疏矩阵。
X
i
X_{i}
Xi代表变量
Q
Q
Q、
K
K
K或
V
V
V中的任意一个。
Parallel Processing With FlashAttention:
每个输入数据的稀疏化段都能以稠密矩阵的形式独立参与注意力计算,因此支持并行处理。这种并行处理机制在高效管理大规模图像数据集时,能够显著加速处理速度,提升模型在实时图像分割任务中的效率。
Output Recomposition:
在提出的Dilated Flash Attention框架中,并行处理稀疏化的段,实现对
Q
~
i
\widetilde{Q} _{i}
Q
i和
K
~
i
\widetilde{K} _{i}
K
i转置的乘积应用softmax函数,然后将其与
V
~
i
\widetilde{V} _{i}
V
i相乘,如下所示:

将这些输出重新组合成连贯的最终输出O.
Computation Efficiency:
通过提出的Dilated Flash Attention机制,效率在数量上提高了一个因子
N
w
r
2
\frac{N}{wr^2}
wr2N ,其中N表示输入的总大小,
w
w
w表示每个分割的长度,
r
r
r表示稀疏化的间隔。
2-2 Dynamic Layer-Wise Distillation (DLD)
Dynamic Layer-Wise Weights:
当前面的层次未能得到充分的蒸馏时,后续层次的性能可能会受到从前面层次提取的低质量特征的不良影响。为了克服这一问题,本文引入了动态加权机制,该机制在训练过程中给予初始层更大的权重,确保它们受到更多的关注。通过这种方式,可以更好地将学生模型与教师模型在初始阶段对齐,从而提升整个模型的性能。
在深度神经网络中,每一层都与一个特定的时间权重相关联。这一机制灵活调整每一层在不同训练阶段中的重要性。具体来说,初始层始终保持最大的关注度,而后续层则遵循动态加权方案,根据训练进展逐渐调整其权重。这种动态加权方案在数学上可以用分段函数来表示,它允许我们精确地控制每一层在训练过程中的贡献,从而优化整个模型的性能。

Decoupled Feature Distillation:
在蒸馏过程中,我们特别选择了距离输出最近的N层进行特征蒸馏。由于这些深层次的特征直接与模型的输出紧密相关,蒸馏它们能够更高效地传递关键信息,从而优化预测结果的准确性。基于这一考量,这些层被特别指定为“焦点层”,以确保在蒸馏过程中得到充分的关注和利用。

对于最接近输入的i层。随着训练的进行,逐层加权动态地转移。与后续层相关的损失被逐渐放大。在这个过程中,损失函数演变为吸收来自后续层的表示.
Align Decoder:
通过解耦蒸馏得到的轻量级图像编码器与冻结的解码器之间往往存在对齐问题,尤其是在执行基于点的提示分割任务时。为了解决这一问题,我们采取了一项关键步骤:在SA-1B数据集上对点提示和框提示进行采样,并对解码器进行微调,以确保其与图像编码器实现良好的对齐。在微调过程中,我们定义了一个损失函数,该函数综合考虑了编码器与解码器之间的匹配程度,以及它们对于分割任务的性能贡献,从而实现了两者的有效对齐。通过这一方法,我们显著提升了模型的性能,使其在图像分割任务中能够展现出更加精准和可靠的结果。
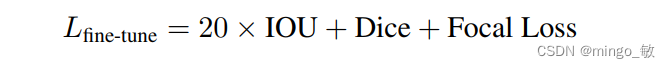
3 Experiment


原文地址:https://blog.csdn.net/shanglianlm/article/details/136797042
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!