动物识别系统Python+卷积神经网络算法+TensorFlow+人工智能+图像识别+计算机毕业设计项目
一、介绍
动物识别系统。本项目以Python作为主要编程语言,并基于TensorFlow搭建ResNet50卷积神经网络算法模型,通过收集4种常见的动物图像数据集(猫、狗、鸡、马)然后进行模型训练,得到一个识别精度较高的模型文件,然后保存为本地格式的H5格式文件。再基于Django开发Web网页端操作界面,实现用户上传一张动物图片,识别其名称。
在本项目中,旨在通过人工智能技术实现常见动物的自动识别。该系统以Python作为主要编程语言,使用TensorFlow框架构建了ResNet50卷积神经网络模型,主要用于动物图像分类任务。项目中选择了四种常见的动物类别——猫、狗、鸡和马,作为识别的目标。通过收集这些动物的大量图像数据集,经过数据预处理后,模型在训练过程中通过卷积层提取图像特征,最终生成一个能够有效识别动物类别的高精度模型。
在模型训练完成后,识别准确率较高的模型文件被保存为H5格式,用于后续的推理和应用。为了使该系统更加实用,本项目在Django框架的基础上开发了一个用户友好的网页端操作界面。用户可以通过该界面上传一张包含动物的图片,系统将自动对其进行分析并识别出动物的类别。整个流程从用户交互到模型推理均可在Web端实现,极大地方便了普通用户使用这一动物识别系统。
该项目不仅展现了卷积神经网络在图像识别中的强大能力,也为学习者提供了实践机器学习和深度学习技术的机会,同时利用Django框架开发了一个功能完备的Web应用,使得人工智能技术更加贴近现实应用。
二、系统效果图片展示
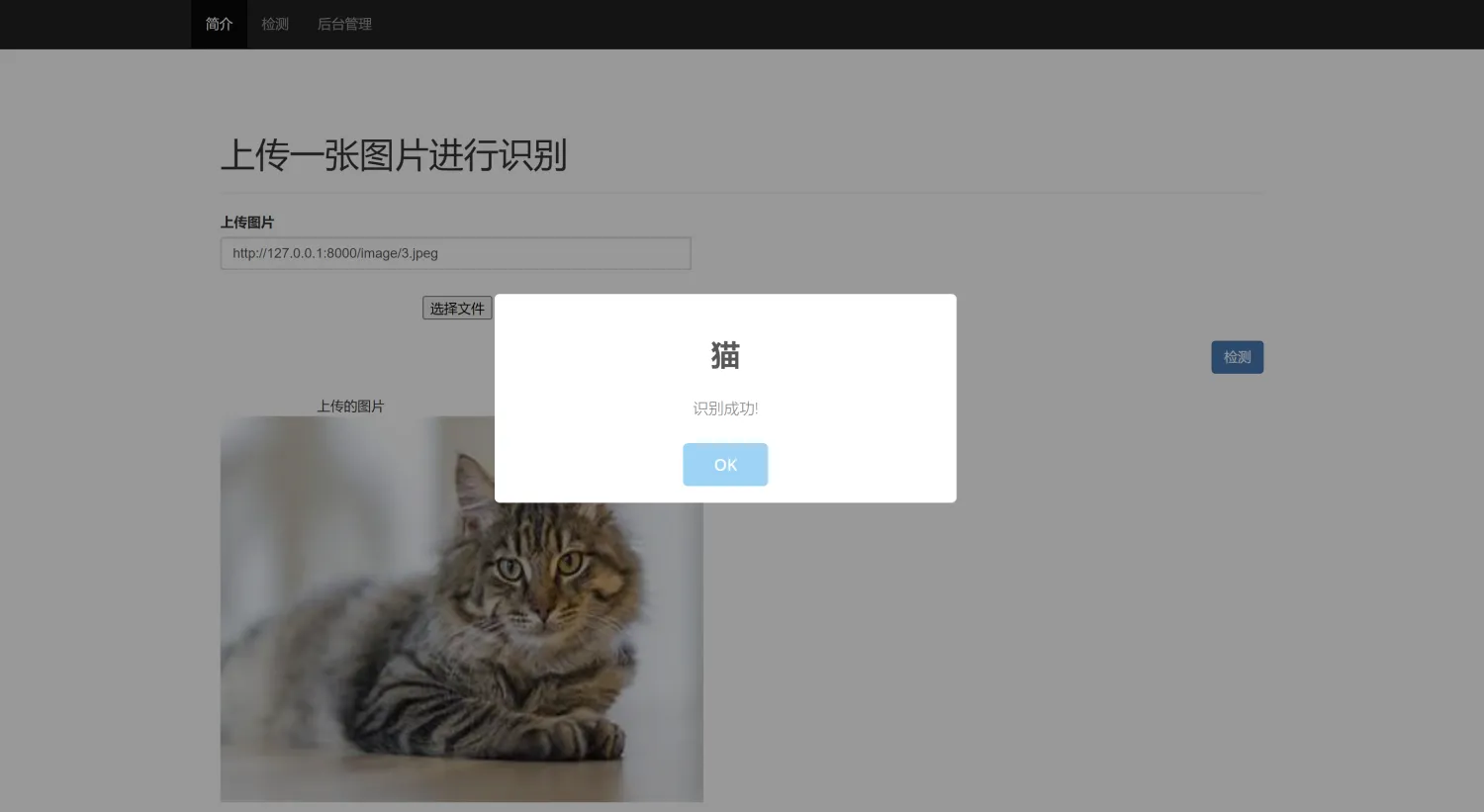
三、演示视频 and 完整代码 and 安装
地址:https://www.yuque.com/ziwu/yygu3z/ohtysy62ob1glubc
四、TensorFlow介绍
TensorFlow是由谷歌开发的一个开源机器学习框架,广泛应用于深度学习和神经网络的研究与开发。其核心是一个灵活的计算图结构,能够在不同硬件平台(如CPU、GPU和TPU)上高效运行,从而满足从研究到生产环境中的各种需求。TensorFlow支持各种机器学习算法,特别是神经网络算法,涵盖了从图像处理、自然语言处理到时间序列分析等多个领域。
TensorFlow的优势在于其模块化设计和强大的扩展性。开发者可以利用其内置的高级API,如Keras,快速构建和训练深度学习模型。此外,TensorFlow还提供了低级API,以满足开发者对模型和算法细节进行精细控制的需求。通过这些API,开发者可以定义任意复杂的神经网络结构,如卷积神经网络(CNN)、循环神经网络(RNN)等。
在图像识别领域,TensorFlow的卷积神经网络(CNN)技术尤为强大。CNN通过卷积层、池化层和全连接层对图像进行特征提取和分类,可以有效识别图像中的物体类别。典型的应用场景包括自动驾驶中的道路障碍物检测、医疗影像分析中的疾病诊断、以及安防监控中的人脸识别等。
以下是一个基于TensorFlow和Keras实现的简单手写数字识别案例代码,使用的是经典的MNIST数据集。该代码演示了如何构建卷积神经网络(CNN)来识别手写数字。
# 导入必要的库
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
# 加载MNIST数据集
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
# 数据预处理,将图像归一化到0到1之间,并调整输入的形状以适应CNN的输入格式
train_images = train_images.reshape((train_images.shape[0], 28, 28, 1)).astype('float32') / 255
test_images = test_images.reshape((test_images.shape[0], 28, 28, 1)).astype('float32') / 255
# 构建卷积神经网络模型
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax') # 10个输出节点,对应0-9的数字分类
])
# 查看模型的结构
model.summary()
# 编译模型,使用Adam优化器,损失函数为稀疏分类交叉熵
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
history = model.fit(train_images, train_labels, epochs=5, validation_data=(test_images, test_labels))
# 可视化训练过程中的损失和准确率变化
plt.plot(history.history['accuracy'], label='训练准确率')
plt.plot(history.history['val_accuracy'], label='验证准确率')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()
# 评估模型在测试集上的表现
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print(f"在测试集上的准确率为: {test_acc:.4f}")
# 进行预测,展示测试集中前几张图片的预测结果
predictions = model.predict(test_images)
# 显示预测结果与真实标签的对比
def plot_image(i, predictions_array, true_label, img):
predictions_array, true_label, img = predictions_array[i], true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img[:, :, 0], cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
color = 'blue' if predicted_label == true_label else 'red'
plt.xlabel(f"{predicted_label} ({true_label})", color=color)
# 展示前5张测试图片和预测结果
num_rows = 1
num_cols = 5
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(5):
plt.subplot(num_rows, num_cols, i+1)
plot_image(i, predictions, test_labels, test_images)
plt.show()
代码说明:
- 数据预处理:MNIST数据集包含28x28像素的手写数字图像,首先将其调整为CNN需要的输入格式(四维张量:
(样本数, 宽度, 高度, 通道数))并归一化到0到1之间。 - 模型构建:使用了三层卷积层,每层后跟一个最大池化层,最后使用全连接层和Softmax输出层进行分类。
- 模型训练:使用
Adam优化器进行5轮训练,并通过训练和验证集的准确率绘制训练过程曲线。 - 模型评估:在测试集上评估模型性能,并对一些测试图片进行预测,显示预测的标签与真实标签的对比。
这个案例展示了如何用TensorFlow和Keras进行图像识别任务,特别是手写数字识别。
原文地址:https://blog.csdn.net/meridian002/article/details/142362504
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!