AI网络爬虫006:从当当网批量获取图书信息
一、目标
用户输入一个图书名称,然后程序自动从当当网批量获取图书信息
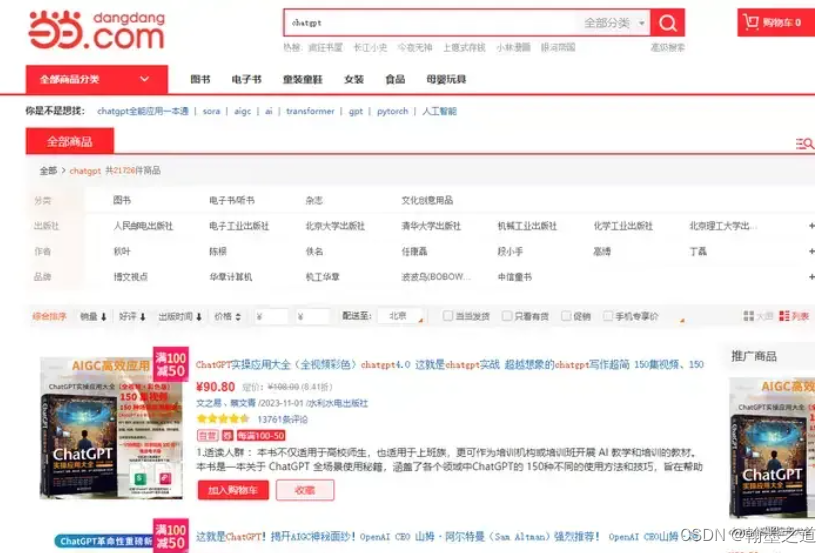
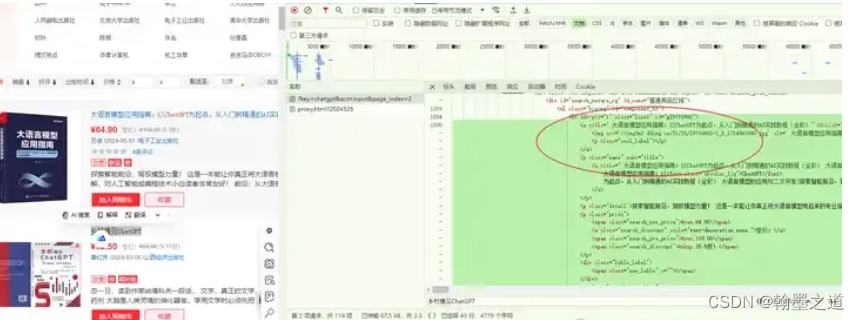
查看相关元素在源代码中的位置:
二、输入内容
第一步:在deepseek中输入提示词:
你是一个Python爬虫专家,一步步的思考,完成以下网页爬取的Python脚本任务:
用户输入一个关键词,接受这个关键词,保存为变量{
book};
在F:\aivideo文件夹里面新建一个Excel文件:{
book}.xlsx
打开网页:https://search.dangdang.com/?key={book}原文地址:https://blog.csdn.net/LuckyHanMo/article/details/140141452
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!