智源十大行业高质量数据集开放申请,经验证可显著提升模型行业能力!
近日,智源研究院非开源、高质量行业预训练数据集开放申请。该数据集覆盖医疗、教育、文学、金融、旅游、法律、体育、汽车、新闻、农业十大行业,总量达597GB。
智源研究院对较难获取的非开源高质量数据、合作伙伴贡献的数据、有行业特征的开源数据进行了基于规则及模型的过滤、数据去重等加工处理,并针对中文数据标注了字母数字比例、平均行长度、语言的置信度得分、最大行长度、困惑度等12种标签,使得行业数据集领域特征密度明显高于通用训练数据,适合特定行业业务问题下模型的前置继续训练或混合数据训练。
其中,医疗行业数据的价值和效果,已在智源研究院医疗语言模型Aquila-Med的训练过程中得到了验证。
Aquila-Med是针对医疗领域的复杂性场景的解决方案,基于Aquila的大规模双语医疗语言模型,在持续预训练阶段,Aquila-Med使用了高质量行业数据集中的医疗数据,实验结果表明:持续预训练阶段,Aquila-Med在多个基准测试上表现良好,特别是在MMLU上的表现显著提升(见图1)。
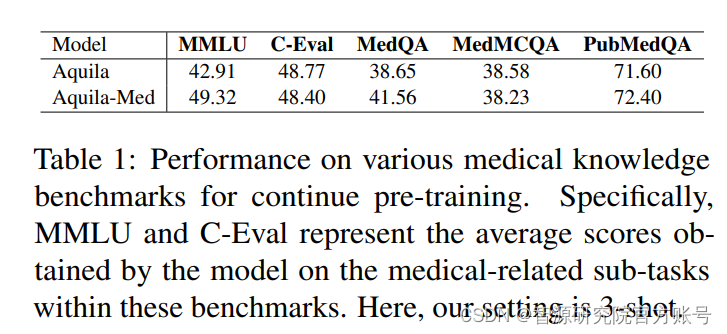
图1
模型对齐阶段,智源从医学主题问题和医生-患者咨询两个方面进行评估,Aquila-Med-Chat在指令跟随能力方面表现出色。Aquila-Med-Chat (RL)在C-Eval上以及单轮多轮对话能力的表现尤为突出(见图2-图5)。因此,Aquila-Med在多个基准测试上的强大表现验证了医疗行业数据集的质量和训练方法的有效性。
 图2
图2
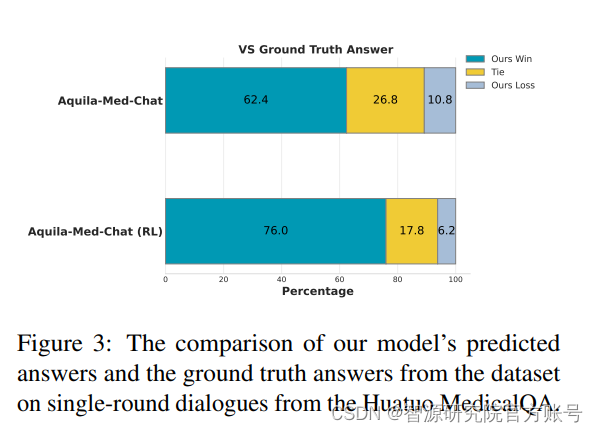
图3
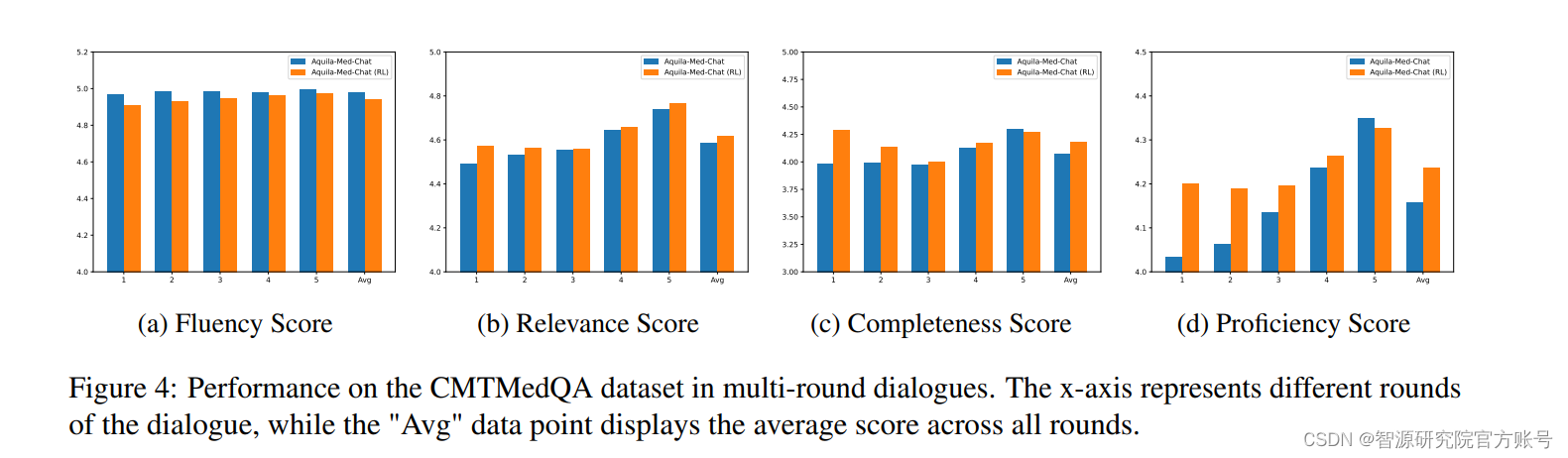
图4

图5
目前,加入智源研究院“行业数据集-场景应用创新计划”即有机会获得行业数据集资源,助力大模型企业的行业模型训练和应用场景落地。
立即参与请点击:https://jwolpxeehx.feishu.cn/share/base/form/shrcnoftHAXa9CZJ9los8PaeUPg
同时,欢迎加入智源数据群,探讨数据集和模型落地:

原文地址:https://blog.csdn.net/eagleofstar/article/details/140179329
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!