ABtest假设检验知识|配对检验|比率检验|单向表-列联表检验
1 假设检验基础
根据Fisher提出的方法,如果我们想检验关于概率函数p(y)或密度函数f(y)的唯一参数
θ
\theta
θ的假设,令
L
L
L表示样本的似然函数,那么为了检验原假设
H
0
:
θ
=
θ
0
H_0:\theta=\theta_0
H0:θ=θ0,Fisher似然比检验统计量为:
λ
=
假定
θ
=
θ
0
时的似然函数
假定
θ
=
θ
^
时的似然函数
=
L
(
θ
0
)
L
(
θ
^
)
\lambda = \frac{假定\theta=\theta_0时的似然函数}{假定\theta=\hat \theta时的似然函数} = \frac{L(\theta_0)}{L(\hat \theta)}
λ=假定θ=θ^时的似然函数假定θ=θ0时的似然函数=L(θ^)L(θ0)
其中
θ
^
\hat \theta
θ^是
θ
\theta
θ的极大似然估计。Fisher分析指出,若实际参数值
θ
\theta
θ与假设参数值
θ
0
\theta_0
θ0不同,那么通过极大似然估计出来的
L
(
θ
^
)
L(\hat \theta)
L(θ^)将远大于
L
(
θ
0
)
L(\theta_0)
L(θ0)。这也就说明如果按照如上关系构造检验统计量,该检验统计量的拒绝域应当由较小的
λ
\lambda
λ构成
所幸的是,我们直观选取的检验统计量多数都是相应似然比统计量
λ
\lambda
λ的函数,他们同时也都是构造置信区间的枢轴统计量
因此,这也就能够说明为什么我们使用假设检验时构造的枢轴统计量与置信区间所使用的枢轴统计量同质
2 一般假设检验
我们常做两个分布的均值检验,在这个范畴下,我们常接触到的假设检验分别是
- 分布方差相同的均值差假设检验
- 分布方差不同的均值差假设检验
由于两个不同分布的方差决定不同的假设检验模型,我们在进行假设检验之前需要提前对方差进行估计
常见的方差估计模型有Levene(没有正态性假设)检验和Bartlett(相互独立且正态假设)检验
接下来,我们直接对两个分布进行均值差的假设检验
2.1 假设检验包
- 方差齐性检验包位于scipy.stats 包下,我们常使用Levene进行检验
- 均值差检验包位于scipy.stats 包下,
如果我们在方差齐性检验中得到方差齐性,使用ttest_rel;
如果是方差非齐性,使用ttest_ind
2.2 sample - 点击转化率
2.2.1 问题描述
某社交APP希望增加直播频道的点击转化率
数据是连续5天点击率
2.2.2 实验设计
- 产品方案如下:在直播频道的选项卡上增加红点提示
- 实验设计方法如下:
混淆变量:相同用户行为特征的两组用户,主要控制的变量有
视频的观看习惯:观看时长|观看互动水平,显示为留言量和弹幕量
app的使用习惯:使用app的时间段|用户生命周期处于同一水平
用户的社会学特征:年龄和地域分层抽样,保证AB两组中用户比例与总体一致
干预:直播频道选项卡上是否出现红点
目标变量:直播频道点击转化率
- 样本量选取
- 实验周期: 5个连续日历天
- 构造假设
H 0 H_0 H0 = AB两组在直播频道点击转化率上没有本质差异
H 1 H_1 H1 = AB两组在直播频道点击转化率上有本质差异
- 检验分布: 由于样本量只有5,因此我们使用t分布进行检验函数的构造
2.2.3 数据处理
import numpy as np
import pandas as pd
import warnings
import os
warnings.filterwarnings('ignore')
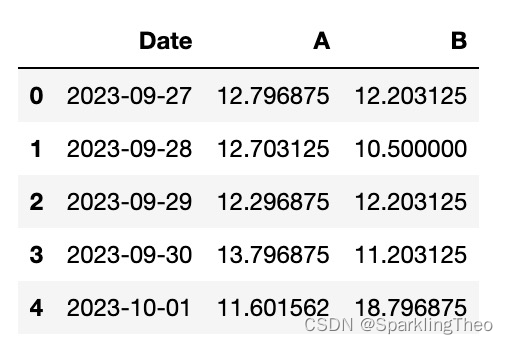
test_res = pd.DataFrame({"Date": pd.date_range(start='2023-09-27',end='2023-10-01',freq='D'),
"A":np.array([12.8,12.7,12.3,13.8,11.6],dtype=np.float16),
"B":np.array([12.2,10.5,12.2,11.2,18.8],dtype=np.float16)
})
test_res.head(5)
2.2.4 方差齐性检验
采用Levene方差齐性检验,构造的检验统计量本质上是一个组间方差和组内方差的F检验
返回值w即为F检验的实际分布值,p即为显著性变量
from scipy.stats import levene
w,p = levene(test_res["A"],test_res["B"],center="mean")
print("w-value:{}\np:{}".format(w,p))
$w-value:3.414548215849387
$p:0.10181205725676695
由于p> α = 0.05 \alpha=0.05 α=0.05,我们认为支持原假设,即实验组和对照组方差是相同的
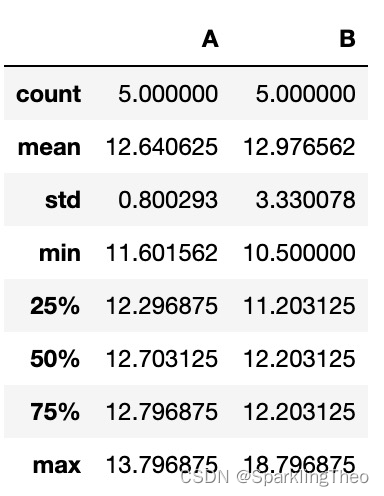
test_res.describe()
2.2.5 假设检验
from scipy.stats import ttest_ind, ttest_rel
t,p = ttest_ind(test_res["A"],test_res["B"],equal_var=True)
print("t-value:{}\np:{}".format(t,p))
$t-value:-0.22446175163718796
$p:0.8280247967287839
2.2.6 结果分析
结果表明,p值远大于
α
=
0.05
\alpha=0.05
α=0.05,我们没有充分的理由拒绝原假设
H
0
H_0
H0,也就是说明AB两个实验不存在显著差异,
因此我们可以得出结论,该产品的优化没有达到预期
我们不能认为红点方案对于提升直播频道点击转化率有促进作用
3 检验两个均值的差:配对
对同一组实验对象,控制混淆变量后,我们只改变目标变量,此时将会得到两个实验统计总体
由于两个实验总体是相关的,因此我们做假设检验的总体思想是将两个总体样本间的差值作为假设检验统计量
3.1 大样本检验
当样本容量 n > 30 n>30 n>30时,我们可以采用Z检验
3.1.1 单侧检验
H
0
:
(
μ
1
−
μ
2
)
=
D
0
H
1
:
(
μ
1
−
μ
2
)
>
D
0
;
[
H
1
:
(
μ
1
−
μ
2
)
<
D
0
]
H_0: (\mu_1-\mu_2) = D_0 \\ H_1: (\mu_1-\mu_2) > D_0 ;\\ [H_1: (\mu_1-\mu_2) < D_0]
H0:(μ1−μ2)=D0H1:(μ1−μ2)>D0;[H1:(μ1−μ2)<D0]
检验统计量:
Z
=
d
ˉ
−
D
0
σ
d
/
n
≈
d
ˉ
−
D
0
s
d
/
n
Z = \frac{\bar d - D_0}{\sigma_d/\sqrt{n}} \approx \frac{\bar d - D_0}{s_d/\sqrt{n}}
Z=σd/ndˉ−D0≈sd/ndˉ−D0
其中
d
ˉ
\bar d
dˉ和
s
d
s_d
sd分别表示样本的均值和标准差
拒绝域:
Z
>
z
α
;
[
Z
<
−
z
α
]
p
=
P
{
Z
>
z
c
}
<
α
;
[
p
=
P
{
Z
<
z
c
}
<
α
]
Z > z_\alpha ; \\ [Z < -z_\alpha]\\ p = P\{Z>z_c\} < \alpha;\\ [p = P\{Z<z_c\} < \alpha]
Z>zα;[Z<−zα]p=P{Z>zc}<α;[p=P{Z<zc}<α]
其中,
z
c
z_c
zc是检验统计量的计算值
3.1.2 双侧检验
原假设与备择假设:
H
0
:
(
μ
1
−
μ
2
)
=
D
0
H
1
:
(
μ
1
−
μ
2
)
≠
D
0
H_0: (\mu_1-\mu_2) = D_0 \\ H_1: (\mu_1-\mu_2) \ne D_0
H0:(μ1−μ2)=D0H1:(μ1−μ2)=D0
检验统计量:
Z
=
d
ˉ
−
D
0
σ
d
/
n
≈
d
ˉ
−
D
0
s
d
/
n
Z = \frac{\bar d - D_0}{\sigma_d/\sqrt{n}} \approx \frac{\bar d - D_0}{s_d/\sqrt{n}}
Z=σd/ndˉ−D0≈sd/ndˉ−D0
其中
d
ˉ
\bar d
dˉ和
s
d
s_d
sd分别表示样本的均值和标准差
拒绝域:
Z
>
∣
z
α
/
2
∣
p
=
2
P
{
Z
>
z
c
}
<
α
Z > |z_{\alpha/2}| \\ p = 2P\{Z>z_c\} < \alpha
Z>∣zα/2∣p=2P{Z>zc}<α
其中,
z
c
z_c
zc是检验统计量的计算值
注意,双侧检验的显著性变量p应为单侧检验的2倍,因为我们要关注的“小概率事件”实际上是Z正太分布的上尾和下尾
3.2 小样本检验
由于实际情况中我们很少能够对数据进行大样本的假设,因此我们一般使用对尾分布更加平滑的t分布
3.2.1 单侧检验
原假设与备择假设:
H
0
:
(
μ
1
−
μ
2
)
=
D
0
H
1
:
(
μ
1
−
μ
2
)
>
D
0
;
[
H
1
:
(
μ
1
−
μ
2
)
<
D
0
]
H_0: (\mu_1-\mu_2) = D_0 \\ H_1: (\mu_1-\mu_2) > D_0;\\ [H_1: (\mu_1-\mu_2) < D_0]
H0:(μ1−μ2)=D0H1:(μ1−μ2)>D0;[H1:(μ1−μ2)<D0]
检验统计量:
T
=
d
ˉ
−
D
0
σ
d
/
n
≈
d
ˉ
−
D
0
s
d
/
n
T = \frac{\bar d - D_0}{\sigma_d/\sqrt{n}} \approx \frac{\bar d - D_0}{s_d/\sqrt{n}}
T=σd/ndˉ−D0≈sd/ndˉ−D0
其中
d
ˉ
\bar d
dˉ和
s
d
s_d
sd分别表示样本的均值和标准差
拒绝域:
T
>
t
α
;
[
T
<
−
t
α
]
p
=
P
{
T
>
t
c
}
<
α
;
[
p
=
P
{
T
<
t
c
}
<
α
]
T > t_\alpha ; \\ [T < -t_\alpha]\\ p = P\{T>t_c\} < \alpha;\\ [p = P\{T<t_c\} < \alpha]
T>tα;[T<−tα]p=P{T>tc}<α;[p=P{T<tc}<α]
其中,
t
c
t_c
tc是检验统计量的计算值
3.2.2 双侧检验
原假设与备择假设:
H
0
:
(
μ
1
−
μ
2
)
=
D
0
H
1
:
(
μ
1
−
μ
2
)
≠
D
0
H_0: (\mu_1-\mu_2) = D_0 \\ H_1: (\mu_1-\mu_2) \ne D_0
H0:(μ1−μ2)=D0H1:(μ1−μ2)=D0
检验统计量:
T
=
d
ˉ
−
D
0
σ
d
/
n
≈
d
ˉ
−
D
0
s
d
/
n
T = \frac{\bar d - D_0}{\sigma_d/\sqrt{n}} \approx \frac{\bar d - D_0}{s_d/\sqrt{n}}
T=σd/ndˉ−D0≈sd/ndˉ−D0
其中
d
ˉ
\bar d
dˉ和
s
d
s_d
sd分别表示样本的均值和标准差
拒绝域:
T
>
∣
t
α
/
2
∣
p
=
2
P
{
T
>
t
c
}
<
α
T > |t_{\alpha/2}| \\ p = 2P\{T>t_c\} < \alpha
T>∣tα/2∣p=2P{T>tc}<α
其中,
t
c
t_c
tc是检验统计量的计算值
注意,双侧检验的显著性变量p应为单侧检验的2倍,因为我们要关注的“小概率事件”实际上是T分布的上尾和下尾
3.3 t检验实例
3.3.1 假设检验包
scipy.stats 包中提供多种假设检验的工具
对于假设检验来说,最为重要的计算机优化点实际上在于样本均值和方差的计算,
与此同时,计算机还需要根据自由度存储相应统计分布的分位值数据,除此之外我们完全可以手动完成如上计算工作
3.3.2 sample - 人工降雨
人工降雨:考虑人工降雨试验,比较5个耕作地区的使用催化求雨技术与否的月降水量,
在这个实验中,目标变量时对该地区使用催化,观察对象是5个耕作地区
import numpy as np
import pandas as pd
import warnings
from scipy.stats import ttest_1samp
warnings.filterwarnings("ignore")
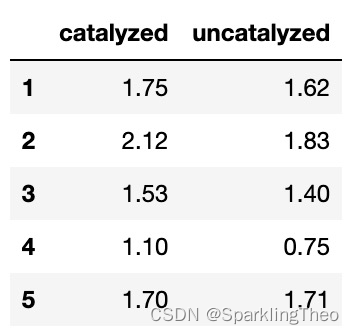
decipitation = np.array([[1.75,2.12,1.53,1.10,1.70],
[1.62,1.83,1.40,0.75,1.71]])
df_decipitation = pd.DataFrame(columns=np.arange(1,6,1),
index=["catalyzed","uncatalyzed"],
data=decipitation).transpose()
df_decipitation
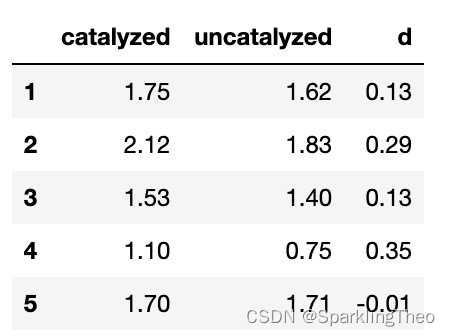
df_decipitation["d"] = df_decipitation.catalyzed - df_decipitation.uncatalyzed
df_decipitation
t,p = ttest_1samp(df_decipitation.d,0)
print("t={},p={}".format(t,p))
$t=2.778537907692358,
$p=0.04989306151921203
由于scipy.stats尝试做双边t检验,因此得出的p结果如果应用到单侧,应当做对半处理,
同时我们发现t值处于t分布右半曲线,因此原假设的确应当是右侧(即>)单边检验
由于我们在假设时将催化分布样本减去为催化分布样本,因此我们的原假设和备择假设实际上是:
H
0
:
(
μ
1
−
μ
2
)
=
0
H
1
:
(
μ
1
−
μ
2
)
>
0
H_0: (\mu_1-\mu_2) = 0 \\ H_1: (\mu_1-\mu_2) > 0
H0:(μ1−μ2)=0H1:(μ1−μ2)>0
即当我们得到单侧检验p值为0.025左右时,可以拒绝原假设而得出催化地区平均月降水量大于未催化地区的结论
4 检验两个比值的差
由于二项分布当满足
n
p
q
≥
4
npq \ge 4
npq≥4的条件时能够被近似视为服从
N
(
n
p
,
n
p
q
)
N~(np,npq)
N (np,npq)的正态分布,
因此我们也能够通过大样本比率构造假设检验的枢轴统计量Z;
不同于两个样本之间均值的比较,两个样本比率的比较更关心的是某个实验结果出现比率之间的比较
4.1 单侧检验
原假设和备择假设:
H
0
:
(
p
1
−
p
2
)
=
D
0
H
1
:
(
p
1
−
p
2
)
>
D
0
;
[
H
1
:
(
p
1
−
p
2
)
<
D
0
]
H_0: (p_1 - p_2) = D_0 \\ H_1: (p_1 - p_2) > D_0; \\ [H_1: (p_1 - p_2 ) < D_0]
H0:(p1−p2)=D0H1:(p1−p2)>D0;[H1:(p1−p2)<D0]
检验统计量:
T
=
(
p
^
1
−
p
^
2
)
−
D
0
σ
(
p
^
1
−
p
^
2
)
T = \frac{(\hat p_1 - \hat p_2) - D_0}{\sigma_{(\hat p_1 - \hat p_2)}}
T=σ(p^1−p^2)(p^1−p^2)−D0
{
σ
(
p
^
1
−
p
^
2
)
=
p
^
1
q
^
1
n
1
+
p
^
2
q
^
2
n
2
,
D
0
≠
0
σ
(
p
^
1
−
p
^
2
)
=
p
^
q
^
(
1
n
1
+
1
n
2
)
,
D
0
=
0
p
^
=
y
1
+
y
2
n
1
+
n
2
\left \{ \begin{array}{ll} \sigma_{(\hat p_1 - \hat p_2)} & = & \sqrt{\frac{\hat p_1 \hat q_1}{n_1}+\frac{\hat p_2 \hat q_2}{n_2}}, D_0 \ne 0 \\ \sigma_{(\hat p_1 - \hat p_2)} & = & \sqrt{\hat p \hat q(\frac{1}{n_1}+\frac{1}{n_2})}, D_0 = 0 \\ \hat p & = & \frac{y_1 + y_2}{n_1+n_2} \\ \end{array} \right .
⎩
⎨
⎧σ(p^1−p^2)σ(p^1−p^2)p^===n1p^1q^1+n2p^2q^2,D0=0p^q^(n11+n21),D0=0n1+n2y1+y2
其中
p
^
1
\hat p_1
p^1和
p
^
2
\hat p_2
p^2分别表示两个分布期望发生事件的比率,而
q
^
1
=
1
−
p
^
1
\hat q_1 = 1- \hat p_1
q^1=1−p^1,
q
^
2
=
1
−
p
^
2
\hat q_2 = 1- \hat p_2
q^2=1−p^2
当
D
0
=
0
D_0 = 0
D0=0时,
y
1
,
y
2
y_1,y_2
y1,y2分别是两个总体中关注事件的发生频次,
n
1
,
n
2
n_1,n_2
n1,n2是两个总体的样本容量
拒绝域:
Z
>
z
α
;
[
Z
<
−
z
α
]
p
=
P
{
Z
>
z
c
}
<
α
;
[
p
=
P
{
Z
<
z
c
}
<
α
]
Z > z_\alpha ; \\ [Z < -z_\alpha]\\ p = P\{Z>z_c\} < \alpha;\\ [p = P\{Z<z_c\} < \alpha]
Z>zα;[Z<−zα]p=P{Z>zc}<α;[p=P{Z<zc}<α]
其中,
z
c
z_c
zc是检验统计量的计算值
4.2 双侧检验
原假设和备择假设:
H
0
:
(
p
1
−
p
2
)
=
D
0
H
1
:
(
p
1
−
p
2
)
≠
D
0
H_0: (p_1 - p_2) = D_0 \\ H_1: (p_1 - p_2) \ne D_0
H0:(p1−p2)=D0H1:(p1−p2)=D0
检验统计量:
T
=
(
p
^
1
−
p
^
2
)
−
D
0
σ
(
p
^
1
−
p
^
2
)
T = \frac{(\hat p_1 - \hat p_2) - D_0}{\sigma_{(\hat p_1 - \hat p_2)}}
T=σ(p^1−p^2)(p^1−p^2)−D0
{
σ
(
p
^
1
−
p
^
2
)
=
p
^
1
q
^
1
n
1
+
p
^
2
q
^
2
n
2
,
D
0
≠
0
σ
(
p
^
1
−
p
^
2
)
=
p
^
q
^
(
1
n
1
+
1
n
2
)
,
D
0
=
0
p
^
=
y
1
+
y
2
n
1
+
n
2
\left \{ \begin{array}{ll} \sigma_{(\hat p_1 - \hat p_2)} & = & \sqrt{\frac{\hat p_1 \hat q_1}{n_1}+\frac{\hat p_2 \hat q_2}{n_2}}, D_0 \ne 0 \\ \sigma_{(\hat p_1 - \hat p_2)} & = & \sqrt{\hat p \hat q(\frac{1}{n_1}+\frac{1}{n_2})}, D_0 = 0 \\ \hat p & = & \frac{y_1 + y_2}{n_1+n_2} \\ \end{array} \right .
⎩
⎨
⎧σ(p^1−p^2)σ(p^1−p^2)p^===n1p^1q^1+n2p^2q^2,D0=0p^q^(n11+n21),D0=0n1+n2y1+y2
其中
p
^
1
\hat p_1
p^1和
p
^
2
\hat p_2
p^2分别表示两个分布期望发生事件的比率,而
q
^
1
=
1
−
p
^
1
\hat q_1 = 1- \hat p_1
q^1=1−p^1,
q
^
2
=
1
−
p
^
2
\hat q_2 = 1- \hat p_2
q^2=1−p^2
当
D
0
=
0
D_0 = 0
D0=0时,
y
1
,
y
2
y_1,y_2
y1,y2分别是两个总体中关注事件的发生频次,
n
1
,
n
2
n_1,n_2
n1,n2是两个总体的样本容量
拒绝域:
Z
>
z
α
/
2
p
=
2
P
{
Z
>
|
z
c
|
}
<
α
Z > z_\alpha/2 \\ p = 2P\{Z>|z_c|\} < \alpha
Z>zα/2p=2P{Z>|zc|}<α
其中,
z
c
z_c
zc是检验统计量的计算值
4.3 比率检验实例
由于比率检验较为简单,我们可以通过手动的方式进行计算
4.3.1 sample - 拼车研究
进来正兴起一场运动,鼓励人们合伙拼车上班以节约能源,计划是指定某些高速公路只能由拼车使用
某一城市的收费站工作人员分别在拼车专用公路上与计划实施前后随机选取了2000辆和1500辆汽车,
调查结果为:
建立拼车道前
n
1
=
2000
n_1=2000
n1=2000, 拼车数
y
1
=
652
y_1=652
y1=652
建立拼车道后
n
1
=
1500
n_1=1500
n1=1500, 拼车数
y
1
=
576
y_1=576
y1=576
试问这些数据能否证明计划实施后合乘汽车比率有所提高?
α
=
0.05
\alpha=0.05
α=0.05
import numpy as np
import warnings
import math
from scipy.stats import norm
warnings.filterwarnings("ignore")
p1 = 652/2000
p2 = 576/1500
p = (652+576)/(2000+1500)
q = 1-p
sigma = math.sqrt(p*q*(1/2000+1/1500))
Z = (p1-p2-0)/sigma
print("p:{},\nsigma:{}, \nZc:{}".format(p,sigma,Z))
alpha = 0.05
z = -norm.ppf(1-alpha)
print("Z:{}".format(z))
$p:0.35085714285714287,
$sigma:0.016300791683958468,
$Zc:-3.558109392752839
$Z:-1.6448536269514722
由于我们一开始做单边检验,
H
0
:
(
p
1
−
p
2
)
=
D
0
H
1
:
(
p
1
−
p
2
)
<
D
0
H_0: (p_1 - p_2) = D_0 \\ H_1: (p_1 - p_2 ) < D_0
H0:(p1−p2)=D0H1:(p1−p2)<D0
故当
Z
c
<
z
α
Z_c<z_\alpha
Zc<zα时我们选择拒绝原假设,认定采取措施后拼车率的确有所提高
5 检验多个比值的差 - 单向表检验
5.1 概念
当我们关注的事件不再是01事件而是分立的几个时,每一个事件都会拥有一个比率,
此时我们希望每一个事件发生的比率是某一组数值,这也就是我们进行单向表检验的原假设
在这个假设检验中,我们将要借助卡方分布
卡方分布这一枢轴统计量的构造数学逻辑也十分清晰,
我们只需要保证观测和期望比率的离差加权平方和最小即可,该统计量的构造也是完全符合Fisher假设的
5.2 卡方检验
假定:
为了卡方近似的有效性,对所有
n
i
n_i
ni都有
E
(
n
i
)
≥
5
E(n_i)\ge 5
E(ni)≥5
原假设和备择假设
H
0
:
p
1
=
p
1
,
0
,
p
2
=
p
2
,
0
,
⋯
,
p
k
=
p
k
,
0
H
1
:
至少有一个多项概率不等于假设值
\begin{array}{ll} H_0: p_1= p_{1,0},p_2= p_{2,0},\cdots,p_k= p_{k,0} \\ H_1: 至少有一个多项概率不等于假设值 \end{array}
H0:p1=p1,0,p2=p2,0,⋯,pk=pk,0H1:至少有一个多项概率不等于假设值
其中,
p
k
,
0
p_{k,0}
pk,0代表多项概率的假设值
检验统计量:
χ
c
2
=
∑
i
=
1
k
[
n
i
−
E
(
n
i
)
]
2
E
(
n
i
)
=
(
∑
i
=
1
k
n
i
2
n
p
i
)
−
n
\chi_c^2 = \sum_{i=1}^k \frac{{[n_i -E(n_i)]}^2}{E(n_i)} = (\sum_{i=1}^k \frac{{n_i}^2}{np_i})-n
χc2=i=1∑kE(ni)[ni−E(ni)]2=(i=1∑knpini2)−n
其中,
E
(
n
i
)
=
n
p
i
,
0
E(n_i)=np_{i,0}
E(ni)=npi,0是在
H
0
H_0
H0成立的条件下得到类型i的期望个数,总样本大小为n
拒绝域:
χ
c
2
>
χ
α
2
p
=
P
{
χ
2
>
χ
c
2
}
\chi_c^2 > \chi_\alpha^2 \\ p=P\{\chi^2>\chi_c^2\}
χc2>χα2p=P{χ2>χc2}
注意,这里
χ
α
2
\chi_\alpha^2
χα2有
(
k
−
1
)
(k-1)
(k−1)个自由度
5.3 单向表检验实例
5.3.1 sample - 车间不合格样品比率
一共有
n
=
103
n=103
n=103个不合格样品,分别来自5条生产线,
下面需要检验5条生产线生产出的不合格样品比率是否相等
生产线1:15 生产线2:27 生产线3:31 生产线4:19 生产线5:11
import numpy as np
import math
import warnings
from scipy.stats import chi2
warnings.filterwarnings("ignore")
alpha = 0.05
n = 5
mean = (15+27+31+19+11)/5
chi2_c= (math.pow((15-mean),2)+math.pow((27-mean),2) \
+math.pow((31-mean),2)+math.pow((19-mean),2) \
+math.pow((11-mean),2))/mean
chi2_a = chi2(n-1).ppf(1-alpha)
print("mean:{}\nchi2_c:{}".format(mean,chi2_c))
print(chi2_a)
$mean:20.6
$chi2_c:13.359223300970873
$9.487729036781154
由于我们的原假设是每一个比率都是相同的,即
H
0
:
p
1
=
0.2
,
p
2
=
0.2
,
⋯
,
p
5
=
0.2
H
1
:
至少有一个多项概率不等于假设值
\begin{array}{ll} H_0: p_1= 0.2,p_2= 0.2,\cdots,p_5= 0.2 \\ H_1: 至少有一个多项概率不等于假设值 \end{array}
H0:p1=0.2,p2=0.2,⋯,p5=0.2H1:至少有一个多项概率不等于假设值
结果通过计算我们发觉$ \chi_c^2 > \chi_\alpha^2$,因此我们选择拒绝原假设
即至少有一条生产线比其他生产线对较高的不合格率富有责任
6 检验类型的两个方向是否相关 - 列联表检验
原文地址:https://blog.csdn.net/weixin_41429931/article/details/139187161
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!