MIT 6.5840(6.824) Lab 5:Sharded Key/Value Service 设计实现
文章目录
1 实验要求
1.1 介绍
本实验要求构建一个键 / 值存储系统,该系统能够将键 “分片” 或分区到一组副本组上。分片是键 / 值对的子集,例如所有以“a”开头的键可能是一个分片等,通过分片可提高系统性能,因为每个副本组仅处理几个分片的放置和获取,并且这些组并行操作。
系统有两个主要组件:一组副本组和分片控制器。每个副本组使用 Raft 复制负责部分分片的操作,分片控制器决定每个分片应由哪个副本组服务,其配置会随时间变化。客户端和副本组都需咨询分片控制器来找到对应关系。系统必须能在副本组间转移分片,以平衡负载或应对副本组的加入和离开。
主要挑战在于处理重新配置,即分片到组的分配变化,且要确保任何时候每个分片只有一个副本组在处理请求,同时重新配置还需要副本组间的交互(分片移动)。本实验只允许通过 RPC 进行客户端和服务器间的交互。实验架构与许多其他系统类似,但相对简单。实验需使用相同的 Raft 实现,完成后需通过相关测试。
1.2 lab5A:控制器和静态分片
-
实现分片控制器
- 在
shardctrler/server.go和client.go中实现。需支持Join、Leave、Move和Query四种 RPC 接口。 JoinRPC:管理员用于添加新副本组,参数是从唯一、非零副本组标识符(GIDs)到服务器名称列表的映射集。分片控制器创建新配置,尽可能均匀地分配分片并尽量少移动分片。若 GID 不在当前配置中可重复使用。LeaveRPC:参数是已加入组的 GIDs 列表,分片控制器创建新配置,排除这些组并将其分片分配给剩余组,且尽可能均匀分配并少移动分片。MoveRPC:参数是分片编号和 GID,分片控制器创建新配置将分片分配给指定组,主要用于测试。QueryRPC:参数是配置编号,分片控制器回复对应编号的配置,若编号为 - 1 或大于最大已知配置编号,则回复最新配置。第一个配置编号为 0,无组且所有分片分配给无效 GID 0,后续配置编号依次递增。通常,分片的数量明显多于组(即,每一组将服务多个分片),以便可以以相当细的粒度转移负载。
- 从
- 实现时要注意去重客户端请求,代码需具有确定性,注意 Go 中 map 的特性,可使用
Go test --race查找漏洞。
- 在
-
实现分片键 / 值服务器(处理静态配置)
- 在
shardkv/目录下实现,可从现有的kvraft服务器复制代码。 - 对于第一个测试,无需特别处理分片即可通过。
- 对于第二个测试,键 / 值副本组必须拒绝处理不属于其负责分片的键请求,服务器需定期向控制器获取最新配置,并在每次收到客户端
Get/Put/AppendRPC 时检查配置,对不负责分片的键请求返回ErrWrongGroup错误,且服务器不应调用分片控制器的Join()处理程序,由测试程序在适当时候调用。
- 在
Hint
- 从 kvraft 服务器的精简副本开始。
- 实现时要注意去重客户端请求。
- 状态机中执行分片重新平衡的代码必须是确定性的。在Go中,map的迭代顺序是不确定的
- Go map是引用。如果将map类型的一个变量分配给另一个变量,则这两个变量都引用同一个map。因此,如果你想创建一个新的
Config基于前一个,您需要创建一个新的地图对象(使用make())并单独复制键和值。- Go竞争detector(
go test --race)可以帮助您发现错误。
1.3 lab5B:碎片移动
当控制器改变分片时在副本组间移动分片,并确保键 / 值客户端操作的线性化。每个分片仅在其 Raft 副本组中多数服务器存活且能相互通信,以及能与多数分片控制器服务器通信时才能进行操作。系统在某些副本组中的少数服务器出现故障、暂时不可用或速度慢的情况下仍需运行。
一个shardkv服务器只属于一个副本组,且组内服务器集合不会改变。
服务器需监测配置变化,检测到变化时启动分片迁移过程。若副本组丢失分片,需立即停止处理该分片的请求并迁移数据给接管的副本组;若副本组获得分片,需等待前所有者发送旧分片数据后再接受请求。实现配置更改期间的分片迁移,确保副本组中的所有服务器在操作执行顺序中的同一点进行迁移,以统一处理并发客户端请求。
Hint
- 服务器需周期性(约每 100 毫秒)轮询分片控制器获取新配置,配置更改时服务器间需通过 RPC 传输分片,使用
make_end()函数将服务器名称转换为labrpc.ClientEnd来发送 RPC。- 按顺序处理重新配置,处理跨分片移动的客户端请求时需提供最多一次语义(去重检测)。
- 考虑
shardkv客户端和服务器如何处理ErrWrongGroup错误,包括客户端是否更改序列号,服务器执行Get/Put请求返回该错误时是否更新客户端状态等。- 服务器迁移到新配置后可继续存储不再拥有的分片,但在实际系统中应避免。
- 考虑在配置更改过程中,一个组从另一个组获取分片时,发送分片的时间点是否重要。
- 可在 RPC 请求或回复中发送整个map来简化分片转移代码,但要注意可能导致的竞态问题,处理方法是在 RPC 处理程序的回复中包含map的副本,以及在将映射 / 切片放入 Raft 日志条目并保存到键 / 值服务器状态时也要复制以避免竞态。
- 配置更改时,两组之间可能需要双向移动分片,注意避免死锁。
1.4 挑战任务
- 状态垃圾回收
- 当副本组失去一个分片的所有权时,应从其数据库中删除该分片的键,避免浪费空间,但这给迁移带来问题。
- 解决方法是让副本组在必要时保留旧分片,且在副本组崩溃后重新启动时仍能正常工作,通过
TestChallenge1Delete测试即完成此挑战。
- 配置更改期间的客户端请求处理
- 基本优化:修改解决方案,使在配置更改期间,不受影响分片的客户端操作能够继续执行,通过
TestChallenge2Unaffected测试即完成此部分挑战。 - 进一步优化:修改解决方案,使副本组在能够处理分片时立即开始服务,即使配置更改仍在进行中,通过
TestChallenge2Partial测试即完成此挑战。
- 基本优化:修改解决方案,使在配置更改期间,不受影响分片的客户端操作能够继续执行,通过
2 实验设计
2.1 整体架构
Shardedkv服务整体架构如下图所示,主要由shardctrler(分片控制器)和shardkv(分片键值存储)两个核心组件构成,基于Raft一致性协议。
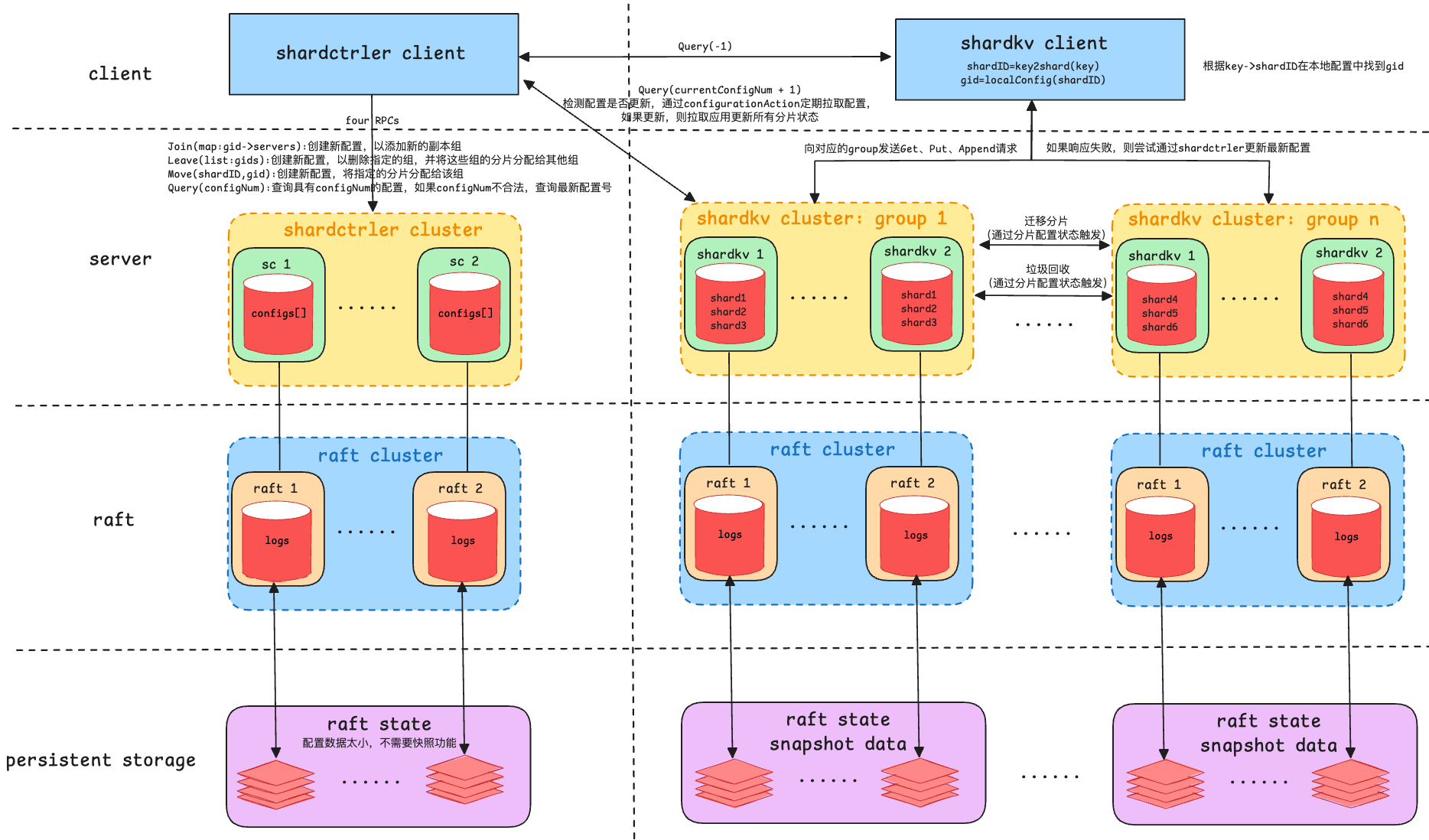
- 客户端层
- shardctrler客户端:主要用于与shardctrler集群进行交互,执行分片配置的管理操作。通过4个主要的RPC接口,客户端可以请求
Join(加入新分片组)、Leave(离开分片组)、Move(迁移分片)和Query(查询分片配置)。 - shardkv客户端:负责向shardkv集群发送具体的键值操作请求。客户端通过分片ID(
shardID)查找目标分片所在的集群组(通过本地配置中的映射关系),并将请求发送到正确的shardkv服务器。如果该shardkv服务器无法提供服务(如分片迁移导致服务不可用),客户端会向shardctrler请求最新的配置,并重新定向请求。
- shardctrler客户端:主要用于与shardctrler集群进行交互,执行分片配置的管理操作。通过4个主要的RPC接口,客户端可以请求
- 服务器层:分为两个主要的集群:shardctrler集群和shardkv集群,它们分别处理配置管理和数据存储。
- Shardctrler集群:Shardctrler是负责管理分片配置的服务器集群。该集群的每个节点保存一个
configs[]数组,记录系统中每个分片的最新及历史配置,包括configNum,map:shard->gid,map:gid->servers。该集群通过RPC接口处理客户端发起的配置变更请求,包括Join、Leave、Move和Query。每当shardctrler接收到配置变更请求时,它会生成一个新的配置,将分片重新分配给不同的shardkv集群组。 - Shardkv集群:Shardkv集群是处理实际键值存储和数据操作的核心部分。整个Shardkv系统被划分为多个分片组(Group),每个组负责管理一部分分片。一个组通常包含多个shardkv服务器,每个服务器保存其负责的分片数据。客户端的
Get、Put和Append请求会根据分片ID路由到对应的服务器,服务器根据当前配置中的分片分配情况进行操作。如果服务器收到的请求涉及的分片已经迁移或重新分配,它会通过向shardctrler请求最新配置来处理这一变化。具体来说,当分片被重新分配时,shardkv集群会将原先分配给某个组的分片数据传输到新的分片组。每个分片在迁移过程中,需要通过状态追踪保证只有新的分片组接管该分片的数据写入与查询。当分片完成迁移后,原先拥有该分片的shardkv服务器需要清理掉旧的分片数据,以释放存储资源。
- Shardctrler集群:Shardctrler是负责管理分片配置的服务器集群。该集群的每个节点保存一个
- Raft层:Shardctrler集群和Shardkv集群都依赖于Raft一致性协议来实现分布式日志的一致性复制。
- 持久化存储层:Raft协议的实现要求系统能够将Raft状态和日志数据持久化,以便在节点宕机或重启时恢复状态。其中由于shardctrler的配置数据比较小,所以不太需要快照功能。
2.2 shardctrler
shardctrler本质上跟kvraft没什么区别,只是存储的是配置项信息,包含每个分片由哪个副本组负责以及副本组ID到对应服务器的endPoint这两个映射。所以在代码实现上完全可以按照kvraft的实现,并且由于配置项数据一般比较少,所以不需要实现日志快照功能。
具体在于四个RPC请求:Join、Leave、Move、Query的实现。
-
我们根据
Join请求的副本组 ID 和服务器列表,更新最新配置中的副本组列表,将新副本组添加进去。并且根据新的副本组数量,重新分配分片(使用简单的负载均衡算法:尽量让所有副本组处理的分片数量相等)。// Join adds new groups to the configuration. func (cf *MemoryConfigStateMachine) Join(groups map[int][]string) Err { lastConfig := cf.Configs[len(cf.Configs)-1] // create a new configuration based on the last configuration newConfig := Config{ len(cf.Configs), lastConfig.Shards, deepCopy(lastConfig.Groups), } for gid, servers := range groups { // if the group does not exist in the new configuration, add it if _, ok := newConfig.Groups[gid]; !ok { newServers := make([]string, len(servers)) copy(newServers, servers) newConfig.Groups[gid] = newServers } } group2Shards := Group2Shards(newConfig) for { // load balance the shards among the groups source, target := GetGIDWithMaximumShards(group2Shards), GetGIDWithMinimumShards(group2Shards) if source != 0 && len(group2Shards[source])-len(group2Shards[target]) <= 1 { break } group2Shards[target] = append(group2Shards[target], group2Shards[source][0]) group2Shards[source] = group2Shards[source][1:] } // update the shard assignment in the new configuration var newShards [NShards]int for gid, shards := range group2Shards { for _, shard := range shards { newShards[shard] = gid } } newConfig.Shards = newShards cf.Configs = append(cf.Configs, newConfig) return OK } -
Leave:根据需要移除的副本组ID,从配置中删除这些组的信息。将它们负责的分片重新分配给现存的副本组,保证分片的平衡。// Leave removes specified groups from the configuration. func (cf *MemoryConfigStateMachine) Leave(gids []int) Err { lastConifg := cf.Configs[len(cf.Configs)-1] // create a new configuration based on the last configuration newConfig := Config{ len(cf.Configs), lastConifg.Shards, deepCopy(lastConifg.Groups), } group2Shards := Group2Shards(newConfig) // used to store the orphan shards (i.e., shards owned by orphanShards := make([]int, 0) for _, gid := range gids { // if the group exists in the new configuration, remove it if _, ok := newConfig.Groups[gid]; ok { delete(newConfig.Groups, gid) } // if the group owns any shards, remove them and add them to the orphan shards if shards, ok := group2Shards[gid]; ok { delete(group2Shards, gid) orphanShards = append(orphanShards, shards...) } } var newShards [NShards]int if len(newConfig.Groups) > 0 { // re-allocate orphan shards to the remaining groups for _, shard := range orphanShards { gid := GetGIDWithMinimumShards(group2Shards) newShards[shard] = gid group2Shards[gid] = append(group2Shards[gid], shard) } // update the shard assignment in the new configuration for gid, shards := range group2Shards { for _, shard := range shards { newShards[shard] = gid } } } newConfig.Shards = newShards cf.Configs = append(cf.Configs, newConfig) return OK } -
Move:更新当前的配置,将该分片从旧的副本组重新分配到指定的新副本组。// Move moves a specified shard to a specified group. func (cf *MemoryConfigStateMachine) Move(shard, gid int) Err { lastConfig := cf.Configs[len(cf.Configs)-1] // create a new configuration based on the last configuration newConfig := Config{ len(cf.Configs), lastConfig.Shards, deepCopy(lastConfig.Groups), } // update the shard assignment in the new configuration newConfig.Shards[shard] = gid cf.Configs = append(cf.Configs, newConfig) return OK } -
Query:根据Query请求中的参数(版本号),返回对应版本的配置。如果请求的版本号为 -1,则返回最新的配置。// Query queries a specified configuration. func (cf *MemoryConfigStateMachine) Query(num int) (Config, Err) { // if the configuration number is not valid, return the latest configuration if num < 0 || num >= len(cf.Configs) { return cf.Configs[len(cf.Configs)-1], OK } return cf.Configs[num], OK } // Group2Shards assigns each shard to the corresponding group. func Group2Shards(config Config) map[int][]int { group2Shards := make(map[int][]int) for gid := range config.Groups { group2Shards[gid] = make([]int, 0) } for shard, gid := range config.Shards { group2Shards[gid] = append(group2Shards[gid], shard) } return group2Shards }
2.3 shardkv server
2.3.1 结构
ShardKV的结构体代码如下,其中
stateMachine用于存储实际的键值数据。它是一个分片映射,键为分片 ID,值为存储该分片数据的Shard结构体,每个Shard结构体由哈希表和状态变量构成,有以下四种状态:Serving:表示该分片正在正常地为客户端提供读写服务。这意味着客户端对该分片内键值对的Get、Put、Append等操作都可以得到及时处理。Pulling:表明该分片正在从其他服务器拉取数据。这种情况通常发生在配置变更后,分片需要从原来所属的服务器迁移到当前服务器时,当前服务器会将该分片标记为Pulling状态。BePulling:BePulling状态意味着该分片的数据正在被其他服务器拉取。与Pulling状态不同,BePulling状态是从数据提供方的角度来看的,即本服务器上的该分片数据正在被其他服务器获取。GCing:GCing即垃圾回收(Garbage Collection)状态。当一个分片服务器已经完成了迁移操作,会将进入GCing状态,以便清理拉取服务器上的分片数据(即BePulling状态)。
- 根据不同状态和当前
raft组的配置,决定是否提供读写服务以及进行相应的数据迁移和清理操作。 notifyChans: 用于通知客户端操作的完成情况。每次当 Raft 提交某个操作时,通过notifyChans唤醒等待的客户端。lastOperations:用于去重记录,保存每个客户端最后一次请求的commandId和操作结果,避免重复操作。
此外,ShardKV 还通过 applyCh 接收 Raft 提交的日志条目,并通过定时任务监控配置更新、分片迁移、垃圾回收以及空日志检测。
type ShardKV struct {
mu sync.RWMutex // mutex for synchronizing access to shared resources
dead int32 // set by Kill(), indicates if the server is killed
rf *raft.Raft // raft instance for consensus
applyCh chan raft.ApplyMsg // channel for applying raft messages
makeEnd func(string) *labrpc.ClientEnd // function to create a client end to communicate with other groups
gid int // group id of the server
sc *shardctrler.Clerk // client to communicate with the shardctrler
maxRaftState int // snapshot if log grows this big
lastApplied int // index of the last applied log entry to prevent stateMachine from rolling back
lastConfig shardctrler.Config // the last configuration received from the shardctrler
currentConfig shardctrler.Config // the current configuration of the cluster
stateMachine map[int]*Shard // KV State Machines
lastOperations map[int64]OperationContext // determine whether log is duplicated by (clientId, commandId)
notifyChans map[int]chan *CommandReply // notify the client when the command is applied
}
func StartServer(servers []*labrpc.ClientEnd, me int, persister *raft.Persister, maxraftstate int, gid int, ctrlers []*labrpc.ClientEnd, makeEnd func(string) *labrpc.ClientEnd) *ShardKV {
// call labgob.Register on structures you want
// Go's RPC library to marshall/unmarshall.
labgob.Register(Command{})
labgob.Register(CommandArgs{})
labgob.Register(shardctrler.Config{})
labgob.Register(ShardOperationArgs{})
labgob.Register(ShardOperationReply{})
// Create a channel to receive messages applied by Raft.
applyCh := make(chan raft.ApplyMsg)
kv := &ShardKV{
dead: 0,
rf: raft.Make(servers, me, persister, applyCh),
applyCh: applyCh,
makeEnd: makeEnd,
gid: gid,
sc: shardctrler.MakeClerk(ctrlers),
maxRaftState: maxraftstate,
lastApplied: 0,
lastConfig: shardctrler.DefaultConfig(),
currentConfig: shardctrler.DefaultConfig(),
stateMachine: make(map[int]*Shard),
lastOperations: make(map[int64]OperationContext),
notifyChans: make(map[int]chan *CommandReply),
}
// Restore any snapshot data stored in persister to recover the state.
kv.restoreSnapshot(persister.ReadSnapshot())
go kv.applier()
// Start several monitoring routines that periodically perform specific actions:
go kv.Monitor(kv.configurationAction, ConfigurationMonitorTimeout) // Monitor configuration changes.
go kv.Monitor(kv.migrationAction, MigrationMonitorTimeout) // Monitor shard migration.
go kv.Monitor(kv.gcAction, GCMonitorTimeout) // Monitor garbage collection of old shard data.
go kv.Monitor(kv.checkEntryInCurrentTermAction, EmptyEntryDetectorTimeout) // Monitor Raft log entries in the current term.
return kv
}
Execute函数用于处理命令并返回结果,非领导者返回ErrWrongLeader,领导者获取通知通道等待结果或超时处理,最后异步释放通道;applier协程从Raft日志获取消息应用到状态机,对有效命令消息检查是否应用并按类型处理,可能通知客户端和进行快照,对有效快照消息安装快照恢复状态机,对无效消息抛异常。
// Execute processes a command and returns the result via the reply parameter.
func (kv *ShardKV) Execute(command Command, reply *CommandReply) {
// do not hold lock to improve throughput
// when KVServer holds the lock to take snapshot, underlying raft can still commit raft logs
index, _, isLeader := kv.rf.Start(command)
if !isLeader {
reply.Err = ErrWrongLeader
return
}
kv.mu.Lock()
notifyChan := kv.getNotifyChan(index)
kv.mu.Unlock()
// wait for the result or timeout.
select {
case result := <-notifyChan:
reply.Value, reply.Err = result.Value, result.Err
case <-time.After(ExecuteTimeout):
reply.Err = ErrTimeout
}
// release notifyChan to reduce memory footprint
// why asynchronously? to improve throughput, here is no need to block client request
go func() {
kv.mu.Lock()
kv.removeOutdatedNotifyChan(index)
kv.mu.Unlock()
}()
}
// applier continuously applies commands from the Raft log to the state machine.
func (kv *ShardKV) applier() {
for !kv.killed() {
select {
// wait for a new message in the apply channel
case message := <-kv.applyCh:
if message.CommandValid {
kv.mu.Lock()
// check if the command has already been applied.
if message.CommandIndex <= kv.lastApplied {
kv.mu.Unlock()
continue
}
// update the last applied index
kv.lastApplied = message.CommandIndex
reply := new(CommandReply)
// type assert the command from the message.
command := message.Command.(Command)
switch command.CommandType {
case Operation:
// extract the operation data and apply the operation to the state machine
operation := command.Data.(CommandArgs)
reply = kv.applyOperation(&operation)
case Configuration:
// extract the configuration data and apply the configuration to the state machine
nextConfig := command.Data.(shardctrler.Config)
reply = kv.applyConfiguration(&nextConfig)
case InsertShards:
// extract the shard insertion data and apply the insertion to the state machine
shardsInfo := command.Data.(ShardOperationReply)
reply = kv.applyInsertShards(&shardsInfo)
case DeleteShards:
// extract the shard deletion data and apply the deletion to the state machine
shardsInfo := command.Data.(ShardOperationArgs)
reply = kv.applyDeleteShards(&shardsInfo)
case EmptyShards:
// apply empty shards to the state machine, to prevent the state machine from rolling back
reply = kv.applyEmptyShards()
}
// only notify the related channel for currentTerm's log when node is Leader
if currentTerm, isLeader := kv.rf.GetState(); isLeader && message.CommandTerm == currentTerm {
notifyChan := kv.getNotifyChan(message.CommandIndex)
notifyChan <- reply
}
// take snapshot if needed
if kv.needSnapshot() {
kv.takeSnapshot(message.CommandIndex)
}
kv.mu.Unlock()
} else if message.SnapshotValid {
// restore the state machine from the snapshot
kv.mu.Lock()
if kv.rf.CondInstallSnapshot(message.SnapshotTerm, message.SnapshotIndex, message.Snapshot) {
kv.restoreSnapshot(message.Snapshot)
kv.lastApplied = message.SnapshotIndex
}
kv.mu.Unlock()
} else {
panic(fmt.Sprintf("{Node %v}{Group %v} invalid apply message %v", kv.rf.GetId(), kv.gid, message))
}
}
}
}
2.3.2 日志类型
在 ShardKV 系统中,Raft 日志包含了以下几种不同类型的操作:
- 客户端命令 (
Command): 包含对键值存储的Put、Append、Get等操作,这些操作会通过 Raft 日志提交来保证多副本的一致性。 - 配置变更 (
Config): 当从shardctrler获取到新的分片配置时,会通过 Raft 日志来记录配置的变化。所有副本组通过 Raft 日志共享同一配置,确保分片的一致分配。 - 分片操作 (
ShardOperation): 当进行分片迁移时,涉及到的操作也会记录在 Raft 日志中,保证分片迁移过程的顺序和一致性。 - 空日志条目: Raft 有时会生成空日志条目以保持领导者的状态和活动性,避免在某些情况下集群处于无操作状态。
const (
Operation CommandType = iota // Generic operation command
Configuration // Configuration change command
InsertShards // Command to insert shards
DeleteShards // Command to delete shards
EmptyShards // Command to empty shards
)
type Command struct {
CommandType CommandType
Data interface{}
}
type ShardOperationArgs struct {
ConfigNum int
ShardIDs []int
}
type ShardOperationReply struct {
Err Err
ConfigNum int
Shards map[int]map[string]string
LastOperations map[int64]OperationContext
}
// NewOperationCommand creates a new operation command from CommandArgs
func NewOperationCommand(args *CommandArgs) Command {
return Command{Operation, *args}
}
// NewConfigurationCommand creates a new configuration command
func NewConfigurationCommand(config *shardctrler.Config) Command {
return Command{Configuration, *config}
}
// NewInsertShardsCommand creates a new command to insert shards
func NewInsertShardsCommand(reply *ShardOperationReply) Command {
return Command{InsertShards, *reply}
}
// NewDeleteShardsCommand creates a new command to delete shards
func NewDeleteShardsCommand(args *ShardOperationArgs) Command {
return Command{DeleteShards, *args}
}
// NewEmptyShardsCommand creates a new command indicating no shards
func NewEmptyShardsCommand() Command {
return Command{EmptyShards, nil}
}
2.3.3 读写服务
这段代码主要实现了与shardkv服务相关的操作逻辑。其中canServe函数用于判断服务器是否能服务指定分片,依据是当前配置下分片所属组与服务器组 ID 是否一致以及分片状态。Command函数先检查是否为重复请求,若是非Get操作的重复请求则直接返回结果,同时也检查服务器能否服务对应分片,不能则返回ErrWrongGroup,否则调用Execute。applyOperation函数在处理操作时,先检查服务器能否服务分片,对于非Get操作的重复请求返回上次结果,否则将操作应用到状态机,并在非Get操作时更新客户端操作相关信息,通过在多处进行相关判断和检查来保障操作的正确性和线性化语义。
// canServe checks if the server can serve the shard.
func (kv *ShardKV) canServe(shardID int) bool {
return kv.currentConfig.Shards[shardID] == kv.gid && (kv.stateMachine[shardID].Status == Serving || kv.stateMachine[shardID].Status == GCing)
}
func (kv *ShardKV) Command(args *CommandArgs, reply *CommandReply) {
kv.mu.RLock()
// if the command is the duplicated, return result directly without raft layer's participation
if args.Op != Get && kv.isDuplicateRequest(args.ClientId, args.CommandId) {
lastReply := kv.lastOperations[args.ClientId].LastReply
reply.Value, reply.Err = lastReply.Value, lastReply.Err
kv.mu.RUnlock()
return
}
// check if the server can serve the requested shard.
if !kv.canServe(key2shard(args.Key)) {
reply.Err = ErrWrongGroup
kv.mu.RUnlock()
return
}
kv.mu.RUnlock()
kv.Execute(NewOperationCommand(args), reply)
}
// applyOperation applies a given operation to the KV state machine.
func (kv *ShardKV) applyOperation(operation *CommandArgs) *CommandReply {
reply := new(CommandReply)
shardID := key2shard(operation.Key)
// check if the server can serve the requested shard.
if !kv.canServe(shardID) {
reply.Err = ErrWrongGroup
} else {
// check if the operation is duplicated(only for non-Get operations)
if operation.Op != Get && kv.isDuplicateRequest(operation.ClientId, operation.CommandId) {
lastReply := kv.lastOperations[operation.ClientId].LastReply
reply.Value, reply.Err = lastReply.Value, lastReply.Err
} else {
// apply the operation to the state machine
reply = kv.applyLogToStateMachine(operation, shardID)
// update the last operation context for the client if the operation is not a Get operation
if operation.Op != Get {
kv.lastOperations[operation.ClientId] = OperationContext{
operation.CommandId,
reply,
}
}
}
}
return reply
}
2.3.4 配置更新检测
首先,配置更新协程负责定时监测配置是否更新,即configNum是否增加(currentConfigNum+1==nextConfig.Num)。但检测前提是需要检查分片的状态是否都为Serving,如果不是,则意味着其他协程仍然没有完成任务,故需要阻塞新配置的拉取和提取。
// Checks if the next configuration can be performed.
// If all shards are in Serving status, it queries and applies the next configuration.
func (kv *ShardKV) configurationAction() {
canPerformNextConfig := true
kv.mu.RLock()
// If any shard is not in the Serving status, the next configuration cannot be applied
for _, shard := range kv.stateMachine {
if shard.Status != Serving {
canPerformNextConfig = false
break
}
}
currentConfigNum := kv.currentConfig.Num
kv.mu.RUnlock()
// Query and apply the next configuration if allowed
if canPerformNextConfig {
nextConfig := kv.sc.Query(currentConfigNum + 1)
// Ensure the queried configuration is the next one
if nextConfig.Num == currentConfigNum+1 {
kv.Execute(NewConfigurationCommand(&nextConfig), new(CommandReply))
}
}
}
// applyConfiguration applies a new configuration to the shard.
func (kv *ShardKV) applyConfiguration(nextConfig *shardctrler.Config) *CommandReply {
reply := new(CommandReply)
// check if the new configuration is the next in line.
if nextConfig.Num == kv.currentConfig.Num+1 {
// update the shard status based on the new configuration.
kv.updateShardStatus(nextConfig)
// save the last configuration.
kv.lastConfig = kv.currentConfig
// update the current configuration.
kv.currentConfig = *nextConfig
reply.Err = OK
} else {
reply.Err = ErrOutDated
}
return reply
}
2.3.5 分片迁移
分片迁移协程会定时检测分片的 Pulling 状态。它依据 lastConfig 算出对应 raft 组的 gid 和待拉取的分片,随后并行拉取数据。这里采用 waitGroup 确保所有独立任务完成后再开始下一轮任务。
// Executes the migration task to pull shard data from other groups.
func (kv *ShardKV) migrationAction() {
kv.mu.RLock()
gid2Shards := kv.getShardIDsByStatus(Pulling)
var wg sync.WaitGroup
// Create pull tasks for each group (GID)
for gid, shardIDs := range gid2Shards {
wg.Add(1)
go func(servers []string, configNum int, shardIDs []int) {
defer wg.Done()
pullTaskArgs := ShardOperationArgs{configNum, shardIDs}
// Try to pull shard data from each server in the group
for _, server := range servers {
pullTaskReply := new(ShardOperationReply)
srv := kv.makeEnd(server)
if srv.Call("ShardKV.GetShardsData", &pullTaskArgs, pullTaskReply) && pullTaskReply.Err == OK {
//Pulling data from these servers
kv.Execute(NewInsertShardsCommand(pullTaskReply), new(CommandReply))
}
}
}(kv.lastConfig.Groups[gid], kv.currentConfig.Num, shardIDs)
}
kv.mu.RUnlock()
wg.Wait() // Wait for all pull tasks to complete
}
// applyInsertShards applies the insertion of shard data.
func (kv *ShardKV) applyInsertShards(shardsInfo *ShardOperationReply) *CommandReply {
reply := new(CommandReply)
// check if the configuration number matches the current one.
if shardsInfo.ConfigNum == kv.currentConfig.Num {
for shardID, shardData := range shardsInfo.Shards {
shard := kv.stateMachine[shardID]
// only pull if the shard is in the Pulling state.
if shard.Status == Pulling {
for key, value := range shardData {
shard.Put(key, value)
}
// update the shard status to Garbage Collecting.
shard.Status = GCing
} else {
break
}
}
// update last operations with the provided contexts.
for clientId, operationContext := range shardsInfo.LastOperations {
if lastOperation, ok := kv.lastOperations[clientId]; !ok || lastOperation.MaxAppliedCommandId < operationContext.MaxAppliedCommandId {
kv.lastOperations[clientId] = operationContext
}
}
} else {
reply.Err = ErrOutDated
}
return reply
}
2.3.6 垃圾回收
分片清理协程负责定时检测分片的 GCing 状态,利用lastConfig 计算出对应 raft 组的 gid 和要拉取的分片,然后并行地去删除分片。
// Executes garbage collection (GC) tasks to delete shard data from other groups.
func (kv *ShardKV) gcAction() {
kv.mu.RLock()
// Get the group that was previously responsible for these shards and clean up the shards that are no longer responsible.
gid2Shards := kv.getShardIDsByStatus(GCing)
var wg sync.WaitGroup
// Create GC tasks for each group (GID)
for gid, shardIDs := range gid2Shards {
wg.Add(1)
go func(servers []string, configNum int, shardIDs []int) {
defer wg.Done()
gcTaskArgs := ShardOperationArgs{configNum, shardIDs}
// Try to delete shard data from each server in the group
for _, server := range servers {
gcTaskReply := new(ShardOperationReply)
srv := kv.makeEnd(server)
if srv.Call("ShardKV.DeleteShardsData", &gcTaskArgs, gcTaskReply) && gcTaskReply.Err == OK {
kv.Execute(NewDeleteShardsCommand(&gcTaskArgs), new(CommandReply))
}
}
}(kv.lastConfig.Groups[gid], kv.currentConfig.Num, shardIDs)
}
kv.mu.RUnlock()
wg.Wait() // Wait for all GC tasks to complete
}
// applyInsertShards applies the insertion of shard data.
func (kv *ShardKV) applyInsertShards(shardsInfo *ShardOperationReply) *CommandReply {
reply := new(CommandReply)
// check if the configuration number matches the current one.
if shardsInfo.ConfigNum == kv.currentConfig.Num {
for shardID, shardData := range shardsInfo.Shards {
shard := kv.stateMachine[shardID]
// only pull if the shard is in the Pulling state.
if shard.Status == Pulling {
for key, value := range shardData {
shard.Put(key, value)
}
// update the shard status to Garbage Collecting.
shard.Status = GCing
} else {
break
}
}
// update last operations with the provided contexts.
for clientId, operationContext := range shardsInfo.LastOperations {
if lastOperation, ok := kv.lastOperations[clientId]; !ok || lastOperation.MaxAppliedCommandId < operationContext.MaxAppliedCommandId {
kv.lastOperations[clientId] = operationContext
}
}
} else {
reply.Err = ErrOutDated
}
return reply
}
2.3.7 空日志检测
根据 raft 论文 5.4.2 节,新 leader 提交之前 term 的日志存在风险。若要提交这类日志,需等新 leader 在自身任期产生新日志,新日志提交时,之前 term 的日志才能随之提交。这意味着若当前 term 迟迟无日志生成并提交,之前 term 的部分日志将一直无法提交,进而可能导致活锁,使日志无法推进。
所以空日志检测协程会定时检测 raft 层的 leader 是否拥有当前 term 的日志,如果没有则提交一条空日志,这使得新 leader 的状态机能够迅速达到最新状态,从而避免多 raft 组间的活锁状态。
// Ensures that a log entry is present in the current term to keep the log active.
func (kv *ShardKV) checkEntryInCurrentTermAction() {
// If no log entry exists in the current term, execute an empty command
if !kv.rf.HasLogInCurrentTerm() {
kv.Execute(NewEmptyShardsCommand(), new(CommandReply))
}
}
// applyEmptyShards handles the case for empty shards. This is to prevent the state machine from rolling back.
func (kv *ShardKV) applyEmptyShards() *CommandReply {
return &CommandReply{Err: OK}
}
2.4 shardkv clerk
clerk结构体:
sm:用于和shardctrler交互获取集群最新配置(分片 - 组映射)。config:当前集群配置,决定请求发送的依据。makeEnd:创建与服务器的 RPC 连接。leaderIds:记录组 ID 对应的领导服务器 ID,便于请求发送。clientId和commandId:用于唯一确定客户端操作,保证操作的可识别性和顺序性。
这里将四种命令封装成一个command函数,其具体逻辑如下:
- 先将操作参数
args中的ClientId和CommandId设置为Clerk结构体中的对应值。 - 根据操作键确定分片所属组 ID。
- 组内leader查找与请求发送:
- 若组存在,获取组内服务器列表,确定领导 ID(若未记录则默认为 0)。
- 尝试向领导服务器发送请求,若请求成功且回复正常(
Err为OK或ErrNoKey),则更新commandId并返回结果;若回复ErrWrongGroup,则跳出当前组内循环重新获取配置;若请求失败或回复错误码不符,尝试下一个服务器,若遍历完组内服务器都不行,则跳出组内循环。
- 配置更新:
- 若不存在对应组或组内无合适服务器处理请求,等待 100 毫秒后从
shardctrler获取最新配置,重新开始循环处理请求。
- 若不存在对应组或组内无合适服务器处理请求,等待 100 毫秒后从
type Clerk struct {
sm *shardctrler.Clerk // Client that communicates with the shardctrler to get the latest configuration data (mapping of shards to groups)
config shardctrler.Config // The current cluster configuration, including the shard-to-group mapping, based on which Clerk sends requests.
makeEnd func(string) *labrpc.ClientEnd // Generates an RPC connection to a server, each of which is identified by a unique address.
// You will have to modify this struct.
leaderIds map[int]int // gid -> leaderId, gid is the group id, leaderId is the leader server id
clientId int64 // generated by nrand(), it would be better to use some distributed ID generation algorithm that guarantees no conflicts
commandId int64 // (clientId, commandId) defines a operation uniquely
}
func (ck *Clerk) Command(args *CommandArgs) string {
args.ClientId, args.CommandId = ck.clientId, ck.commandId
for {
shard := key2shard(args.Key)
gid := ck.config.Shards[shard]
if servers, ok := ck.config.Groups[gid]; ok {
// if not set, set the default leader id to 0
if _, ok = ck.leaderIds[gid]; !ok {
ck.leaderIds[gid] = 0
}
oldLeaderId := ck.leaderIds[gid]
newLeader := oldLeaderId
for {
reply := new(CommandReply)
// send the request to the leader server
ok := ck.makeEnd(servers[newLeader]).Call("ShardKV.Command", args, reply)
if ok && (reply.Err == OK || reply.Err == ErrNoKey) {
ck.commandId++
return reply.Value
} else if ok && reply.Err == ErrWrongGroup {
break
} else {
// try the next server
newLeader = (newLeader + 1) % len(servers)
// check if all servers have been tried
if newLeader == oldLeaderId {
break
}
}
}
}
time.Sleep(100 * time.Millisecond)
// Query the latest configuration from the shardctrler
ck.config = ck.sm.Query(-1)
}
}
3 总结
这个实验难度还是非常大的,基本上不是自己独立完成,借鉴了Github OneSizeFitsQuorum的很多代码,其讲解也非常详细。最后也是成功通过了实验测试。
从这个实验中也学到了很多:
- 可以将多个操作封装成一个操作接口去处理,能让代码变得更简洁且易于理解,从kvraft->shardkv,这种设计理想还是非常不错的。
- 要注意在分片迁移和垃圾回收中,并不是由被拉取的服务器来主动拉取和回收的,而都是由拉取服务器进行RPC操作通知。这样的好处是能够使这两个操作同步,因为被拉取服务器不知道该什么时候回收数据的。
- leader不能先更新分片状态,它只能先进行检测,更新还是需要通过raft共识协议,等日志落地后通过apply协程来进行更新,且总是需要去判断leader的身份。
- 可以通过读写锁来优化并发性能,但需要注意的是何时采用读锁很关键。如果不确定,可以一把大锁保平安。
4 参考
原文地址:https://blog.csdn.net/hzf0701/article/details/143091312
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!