2023 年值得一读的技术文章 | NebulaGraph 技术社区

在之前的产品篇,我们了解到了 NebulaGraph 内核及周边工具在 2023 年经历了什么样的变化。伴随着这些特性的变更和上线,在【文章】博客分类中,一篇篇的博文记录下了这些功能背后的设计思考和研发实践。当中,既有对内存管理 Memory Tracker 的原理讲解,也有对 NebulaGraph 的安装选择指引。
而 LLM 作为 2023 年技术圈的一大热点,NebulaGraph 也凭借 Graph + RAG 的契机,让社区用户了解到了在图、知识图谱、大模型这一新的三元组。无独有偶,社区小伙伴 @heikeladi 的《利用 ChatGLM 构建知识图谱》也开启了 GPT 构建知识图谱的新章节,让知识图谱的构建更加 easy。
不只是 LLM、图数据库 NebulaGraph,今年也是 DDIA(design data-intensive application)系列在 NebulaGraph 技术社区连载的第一年,从底层数据结构到顶层架构设计,带你更全面地了解分布式系统。
下面,来看看今年 NebulaGraph 技术社区有哪些博文值得你读一读。如果你觉得某篇文章不错,不要吝啬你的 ❤︎,你的评论和点赞是对作者们最好的赞赏 ❤︎。
LLM + GRAPH
自 2023.05,Wey 在 LlamaIndex 的 pr#2581 中第一次将图数据库、知识图谱和 LLM 放在一起,从此揭开了 Graph + RAG 的面纱。
利用 ChatGLM 构建知识图谱

这是一名东方财富算法工程师陈卓见的大模型实践,在经历 1.0 时代,会利用大量的规则和人力去提取和校验相应的数据,到 2.0 时代去构建相应的深度学习模型辅助完成 NER、实体链接,到现在大模型时代,利用大模型去清晰数据、标注和训练数据。本文给出了这位工程师的 Demo 分享;
LLM + NebulaGraph 三部曲
在 《图技术在 LLM 下的应用:知识图谱驱动的大语言模型 Llama Index》 中,Wey 详细地讲解了何为 LLM 范式,Llama Index 是如何同模型交互的,以及在 Embedding 和向量对搜索结果效果不佳的情况下,知识图谱是如何辅助增加搜索结果的。
作为上篇,它讲述了知识图谱同 LLM 的关系。在随后的《Text2Cypher:大语言模型驱动的图查询生成》和《Graph RAG: 知识图谱结合 LLM 的检索增强》,分别讲述了自然语言到查询语言的转化:
- 将任务拆解成从自然语言中理解意图
- 找出实体
- 从意图和实体构造查询语句
以及 Graph RAG 与 Vector RAG 的结果对比,相比单独的向量搜索,有了知识图谱的 RAG 会更加精准。
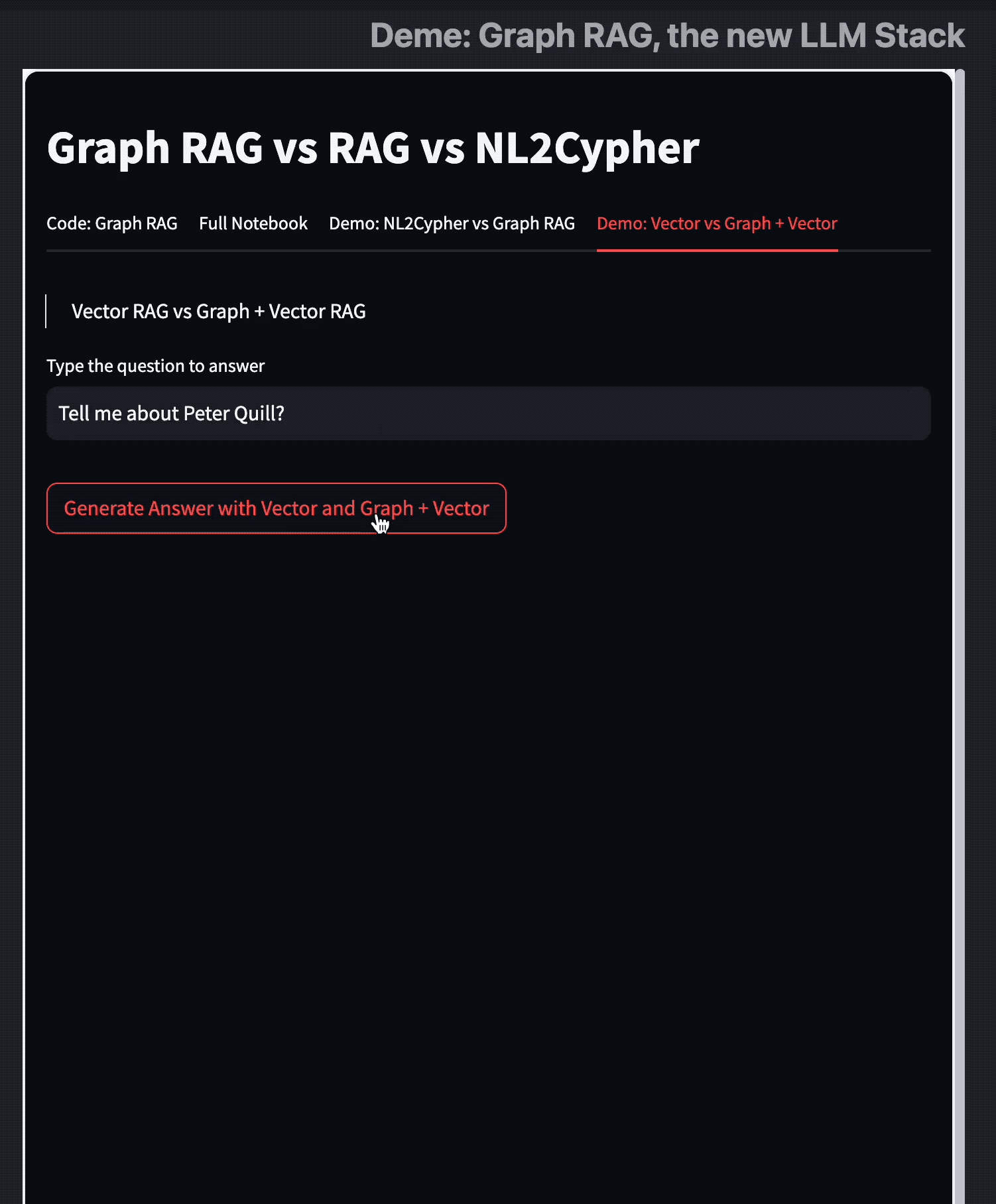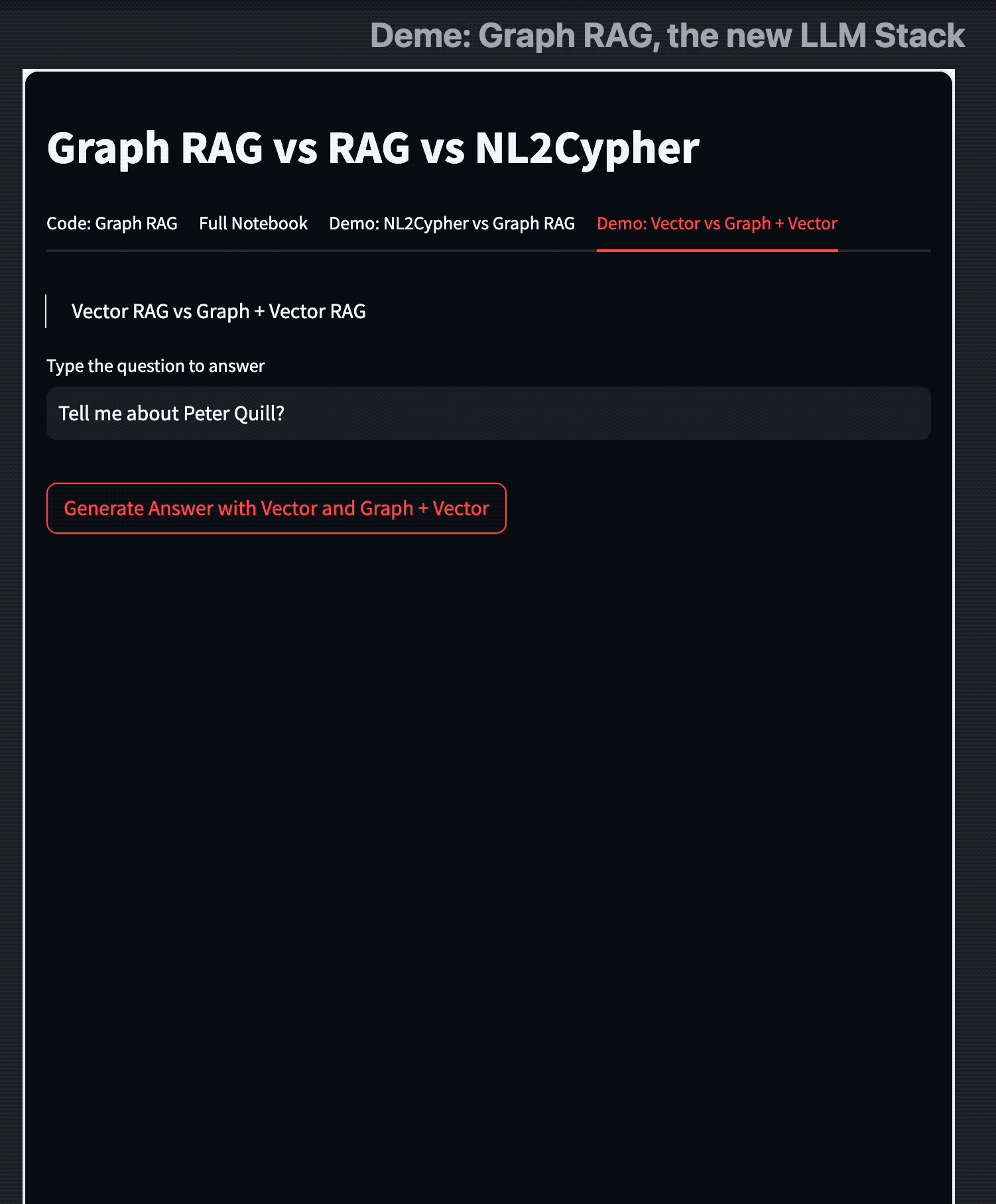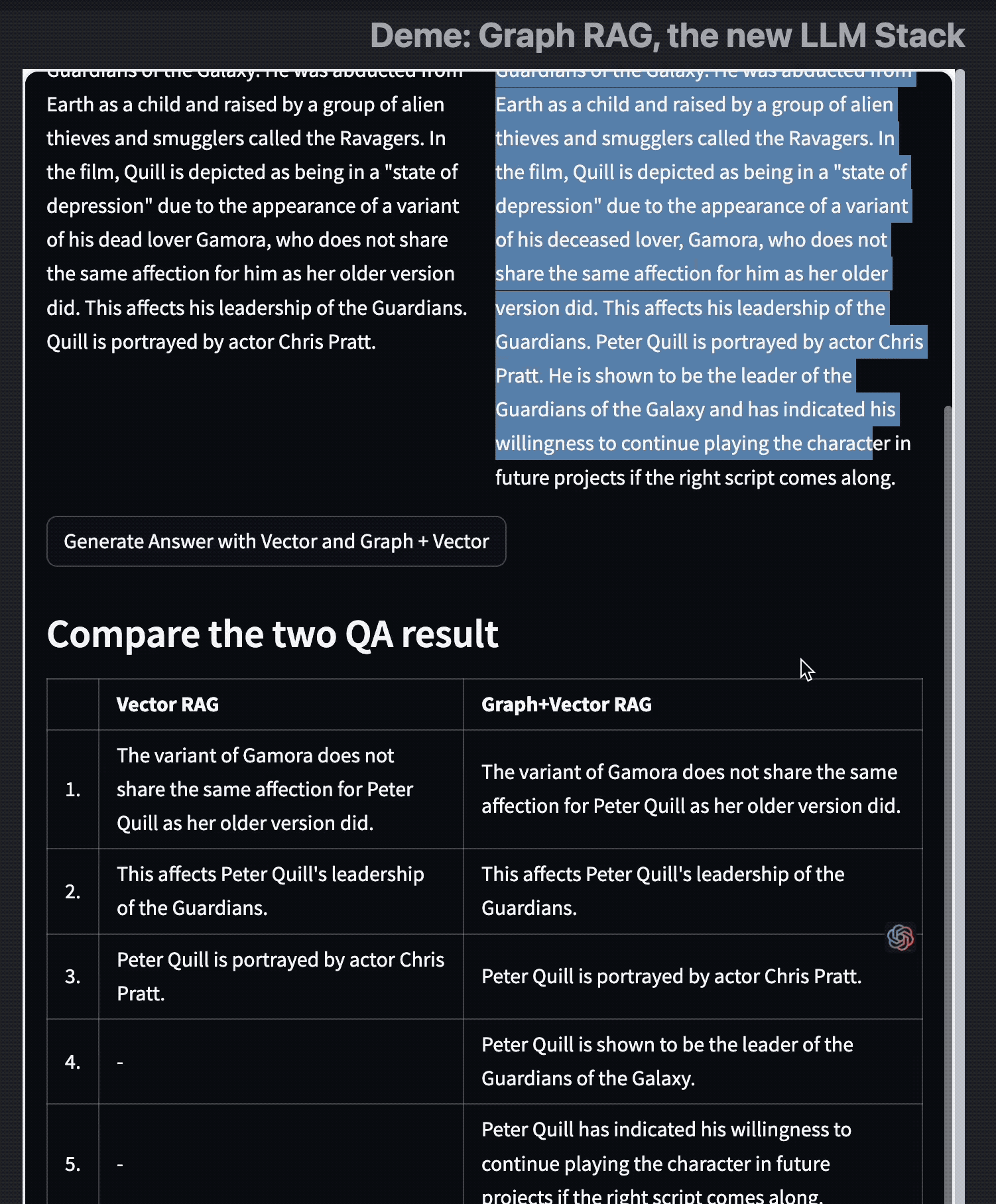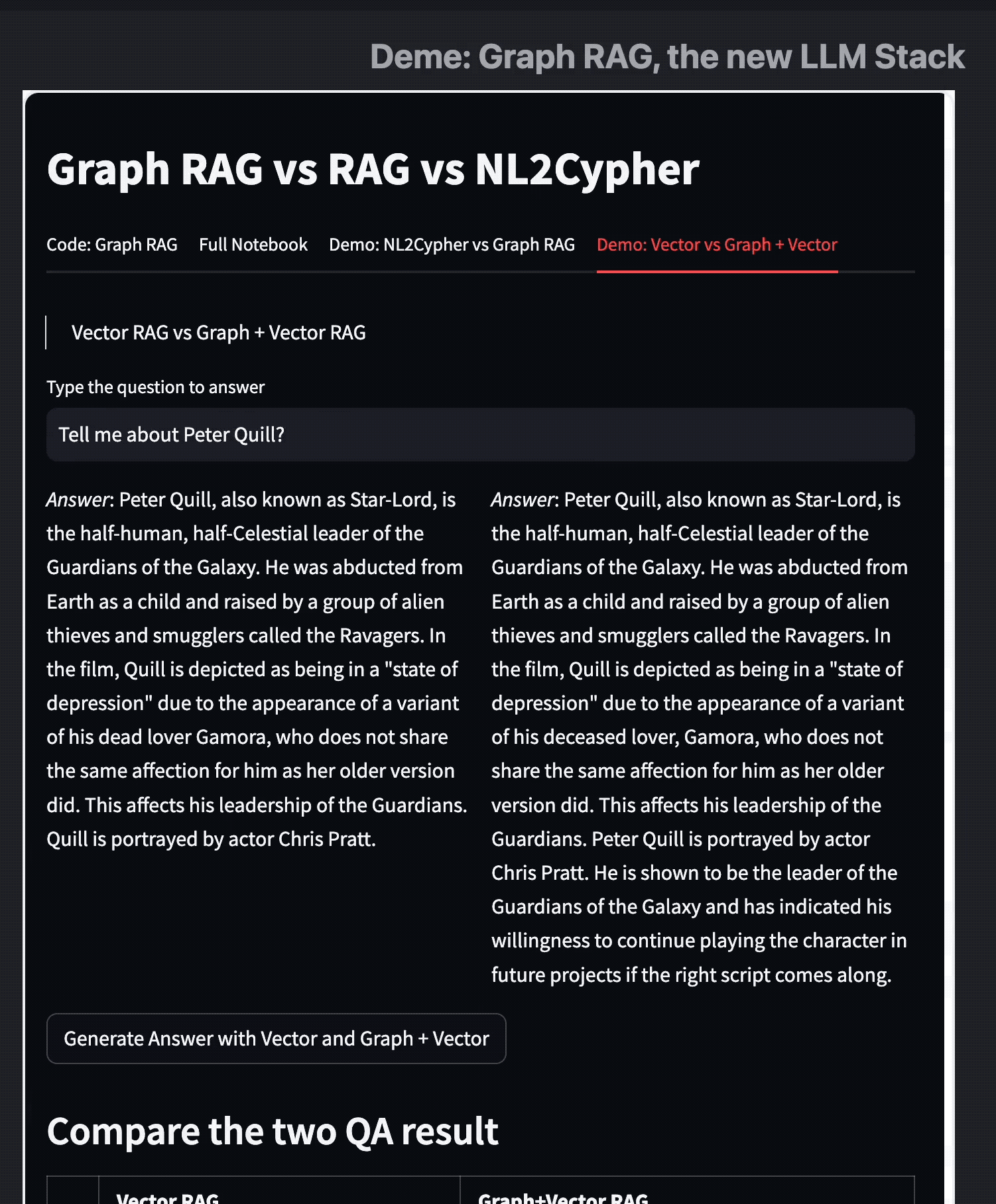
向量检索 vs 关键词检索 vs 混合检索怎么选?
基于 Wey 在 Llama Index 以及 LangChain 的 Graph + RAG 贡献,海外工程师 Wenqi Glantz 对所有 Graph + LLM、RAG 方法进行了全面的实验、评估、综述、总结和分析。《7 种查询策略教你用好 Llama Index 和 NebulaGraph 探索知识图谱》 便是本次实验测评的中文译文:

哪个查询引擎最适合,将取决于你的特定使用情况。
- 如果你的数据源中的知识片段是分散和细粒度的,并且你需要对你的数据源进行复杂的推理,如提取实体和它们在网格中的关系,如在欺诈检测、社交网络、供应链管理,那么知识图谱查询引擎是一个更好的选择。当你的 Embedding 生成假相关性,导致幻觉时,KG 查询引擎也很有帮助。
- 如果你需要相似性搜索,如找到所有与给定节点相似的节点,或找到在向量空间中最接近给定节点的所有节点,那么向量查询引擎可能是你的最佳选择;
- 如果你需要一个能快速响应的查询引擎,那么向量查询引擎可能是一个更好的选择,因为它们通常比 KG 查询引擎更快。即使没有 Embedding,任务的提取(运行在 NebulaGraph 单个 storage 服务上的子任务)也可能是 KG 查询引擎延迟高的主要原因;
- 如果你需要高质量的回答,那么自定义组合查询引擎,它结合了 KG 查询引擎和向量查询引擎的优势,是你最好的选择。
新手友好
使用 NebulaGraph 的第一步便是安装部署,如何提供保姆级的安装教程,让新用户 Step By Step 按照教程完成一开始的部署安装呢?想必没有比 @堕落飞鸟 更合适回答这个问题的人了。
用上 NebulaGraph
在 NebulaGraph 技术社区年度征文活动中,飞鸟以一己之力更新了 5 篇极度新手友好的部署安装相关文章:
《NebulaGraph 安装方式选择》中不只是给出了 7 种安装方式:编译、Docker 编译、单机部署、集群部署、Docker-Compose 安装、K8s 安装和 Docker 集群部署,还给出了这 7 种方式的优劣。下图仅供参考:
| 编译安装 | Docker 编译安装 | 单机安装 | 集群安装 | Docker-Compose 安装 | K8s 安装 | Docker 集群 | |
|---|---|---|---|---|---|---|---|
| 部署维护难度 | ★★ | ★★ | ★ | ★★★ | ★★ | ★★★ | ★★ |
| 所需资源 | ★ | ★ | ★ | ★★★ | ★★ | ★★★ | ★★★ |
| 高可用,高性能 | ★ | ★ | ★ | ★★★ | ★★ | ★★★ | ★★★ |
而随后飞鸟更新的 《NebulaGraph 的备份管理》 则详细地记录了使用备份工具 BR 的过程。不同于 Linux 之类的本地环境,容器化部署的备份方式也是部分社区小伙伴关心的话题。《NebulaGraph 使用 Docker-Compose 部署方式如何备份还原》 便是一个详细到没朋友的容器化部署备份文。
无独有偶,《使用 RKE 方式搭建 K8s 集群并部署 NebulaGraph》 则从 K8s 入手,用一文留下了他是如何使用 RKE 来搭建 NebulaGraph 的过程。《构建 Nebula Graph 3.3.0 和 Nebula Studio 3.7.0 在 ARM 架构上的指南》 则为 ARM 用户带来了一丝暖意,无痛地在 ARM 上用上 NebulaGraph 和 NebulaGraph Studio。
等你有了良好的 NebulaGraph 运行环境,下面就可以试试《使用 NebulaGraph Exchange 通过 Hadoop 导入 OwnThink 数据》,领略一下千亿知识图谱 OwnThink 导入 NebulaGraph 的全过程,以及用这个知识图谱搭建你自己的智能机器人。而《可视化探讨 NebulaGraph 开源社区中的贡献关系》在提供数据集的基础之上,手把手教你如何用可视化探索工具进行导数、查询,观察到数据之间的关系。
上面讲到的用上 NebulaGraph 的 case 都是从零到一,搭建一个空的图数据库,但是如果你已经拥有了成百亿上千亿的数据,如何无缝切换到 NebulaGraph 模式呢?《图数据库系统重构之路》 给那些时间紧、对已有技术栈不了的社区小伙伴指明了方向,重构应该这样做:
- 对外接口梳理:梳理系统所有对外接口,包括接口名、接口用途、请求量 QPS、平均耗时,调用方(服务和 IP);
- 老系统核心流程梳理:输出老系统整理架构图,重要的接口(大概 10 个)输出流程图;
- 环境梳理:涉及到的需要改造的项目有哪些,应用部署、MySQL、Redis、HBase 集群 IP,及目前线上部署分支整理;
- 触发场景:接口都是如何触发的,从业务使用场景出发,每个接口至少一个场景覆盖到,方便后期功能验证;
- 改造方案:可行性分析,针对每一个接口,如何改造(OrientDB 语句改为 NebulaGraph 查询语句),入图(写流程)如何改造;
- 新系统设计方案: 输出整理架构图,核心流程图。
用好 NebulaGraph
当你有了良好的运行环境,面临的就是如何将你的业务 NebulaGraph 化的问题。也许你是从 MySQL 之类关系型数据库来一探图数据库的奇妙,也许你是从 Neo4j、JanusGraph 来想看看 NebulaGraph 的高性能。这时候有一份贴心的进阶使用指南,就非常完美了。
说到进阶用法,有什么比同广大用户频繁交流,获得他们使用姿势,进而总结出的一份产品最佳实践更合适的呢?《使用秘籍|如何实现图数据库 NebulaGraph 的高效建模、快速导入、性能优化》 由 NebulaGraph 产品总监出品,它收录了从图建模开始的各类优化指南,没想到你的 VID 大小也和性能息息相关,更别提多块硬盘竟然能左右写速率。文中收录了各种获取高性能的技巧,如果是新手的话,读一读必有收获。
除了产品的最佳实践,NebulaGraph 的资深研发和布道师也从执行计划角度,让大家了解查询语句生命周期之余,读明白那些执行算子的作用,以及语句执行的耗时点在何处:
说完官方出品的使用指北,再来看看其他小伙伴是咋用好 NebulaGraph 的。在今年开启的 Happy Office Hour 便是一个官方对话用户的活动,在活动中 NebulaGraph 的资深用户会和大家交流他们的使用姿势,而相关的会议纪要你将了解到更多的 NebulaGraph 实用技能。正如第一期会议纪要《如何提升 meta 性能?提高 TTL 删除速率?主备集群怎么做…Happy Office Hour 第一期会议纪要告诉你》 所记录的那样,你可以了解到大企业他们面临的业务问题,以及如何更好地解决、规避这个问题。
内存管控
资源的使用,尤其是内存的使用,是社区用户关心的一大重点。而到底 NebulaGraph 有哪些地方需要使用内存?这是 @肖小可爱乐乐 在文章《NebulaGraph 的内存探查》 中所要探讨的主题。
NebulaGraph 内存初探
一般来说数据库会在多个方面使用到内存,比如:线程池、缓冲区、索引等等。在《NebulaGraph 的内存探查》 中,作者先从一般数据库的内存消耗点讲起,再娓娓道来 NebulaGraph 的工作流程,最后通过实验数据查看在数据导入之后,nebula-storage 的内存使用量变化。
虽然文章并未提及到查询时内存的消耗情况,但是通过本文你将了解一些 nebula-storage 存储方面的内存使用点。下面摘录了部分结论:
- 面对重复插入的数据,nebula 采用忽略掉的机制。假使数据长度不符合不能写入 nebula-storage,将会都写入 nebula-storage 的 err 日志上,不会占用内存。
- 当 CPU 个数较少,Compact 落盘释放内存资源的速度慢于写入数据的速度,内存会持续上升。
- 读操作统计 Tag 和 Edge 个数,假设个数太多将耗费 nebula-storage 大量的内存,如果 nebula-storage 有写入操作,很容易令 nebula 进入崩溃状态。
如果你想了解 nebula-storage 这块的内存消耗,不妨读一读此文参考下。此外,在《NebulaGraph 内存分析》 中,浅析了下三大服务——metad、graphd、storaged 的内存消耗点,可作为理论输入,再结合你具体的业务场景再探内存用量。
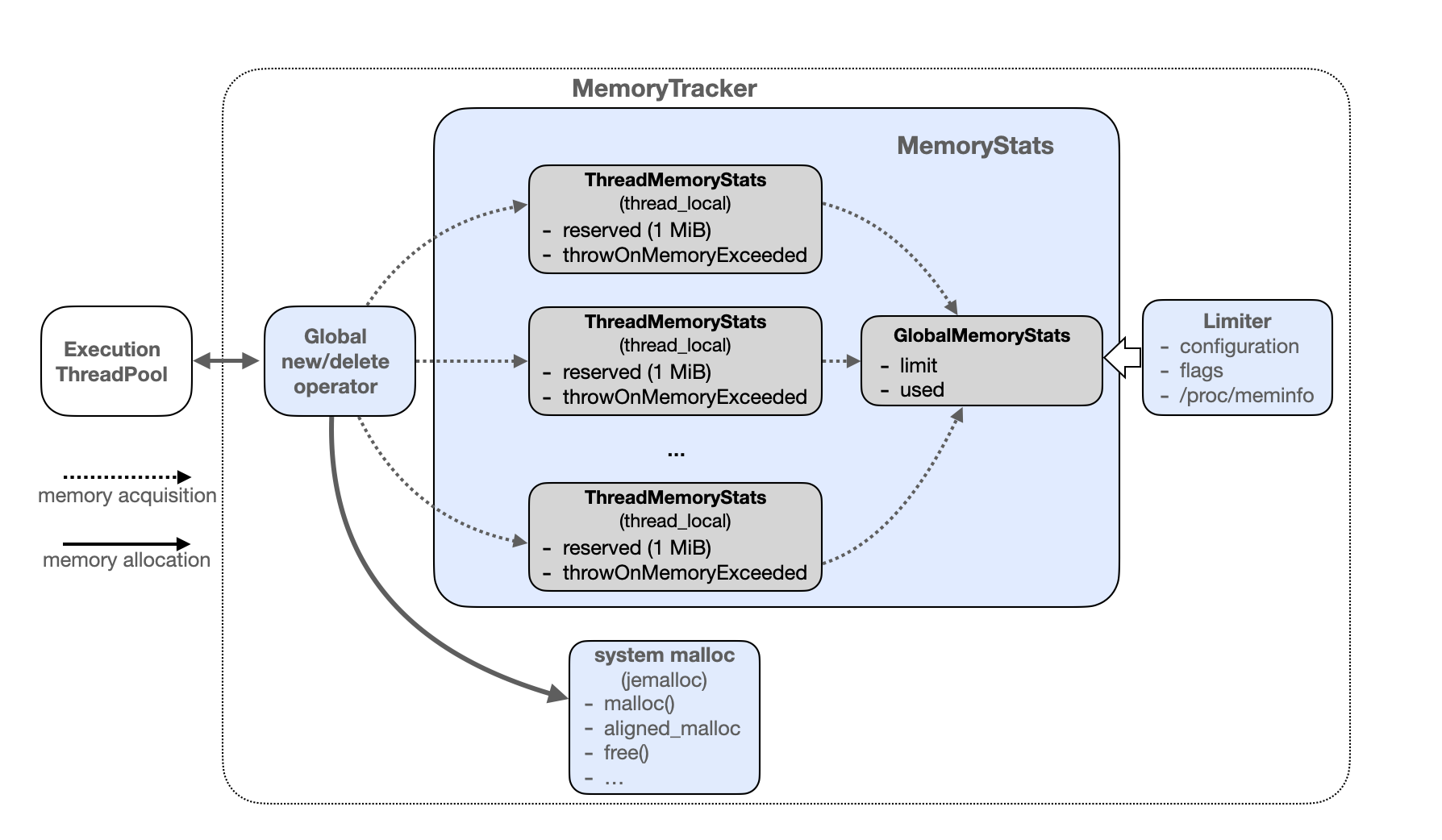
Memory Tracker
数据库的内存管理是数据库内核设计中的重要模块,内存的可度量、可管控是数据库稳定性的重要保障。图数据库的多度关联查询特性,往往使图数据库执行层对内存的需求量巨大。
《内存管理实践之 Memory Tracker》主要介绍 NebulaGraph v3.4 版本中引入的新特性 Memory Tracker,希望通过 Memory Tracker 模块的引入,实现细粒度的内存使用量管控,降低 graphd 和 storaged 发生被系统 OOM kill 的风险,提升 NebulaGraph 图数据库的内核稳定性。
另类实践
大多数的用户都是使用官方提供的周边工具,例如:nebula-java 客户端来操作图数据,而 auhusy 则对 nebula-python 在《python 简单封装CRUD》进行了封装,CurvusY 用 Dart 对 NebulaGraph 进行了移动端适配,开发出来了nebula_dart_gdbc,在手机端也可能查询图数据,《使用 GraphQL 语法查询 NebulaGraph 中的数据》则记下了 Dragonchu 对 GraphQL 的适配,让前端自由地选择想要的数据。
聊聊数据库和分布式
除了 NebulaGraph 使用相关的文章之外,本年度还有同分布式系统相关的 DDIA 系列,以及 RocksDB 的讲解文。
DDIA 系列由数据库研发人员从自身的开发经验出发,结合原书传授的数据系统的设计理念,深入浅出地道明数据系统中的精妙之处。
《一文科普 RocksDB 工作原理》 全方位讲解 kv 嵌入数据库 RocksDB 的核心概念 LSM-Tree、MemTable 和 SSTables,《RocksDB Iterator Internal, part 1》 从工程师角度,以源码阅读的形式带你深入了解 RocksDB 的组件。
2023 年的文章介绍告一段落,感谢你的阅读 (///▽///) 。你可以前往论坛-文章区,阅读本年度所有的文章。
如果你有什么想看,但是社区并没有安排上,来和星云小姐姐 说道说道。
{kind=link}
原文地址:https://blog.csdn.net/weixin_44324814/article/details/135695038
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!